原文链接
我们已经从前几篇博客中看到Clojure's persisten vectors 是如何工作的。在第三部分persistent vector tail是如何提升性能的。然而,在性能关键的代码中,这些优化是不够的:在许多情况下,内存分配是非常耗费资源的。你必须分配内存,垃圾回收可能经常停止运行。这是Clojure's transients被设计的原因-允许不可变数据结构在那些需要高效运行的代码内可变来提前移除内存占用。这不等同于可变数据结构,尽管他们很相似
什么时候可变是可以的?
做一个简短的回顾,记住在不可变数据上改变内容是不会修改当前存在的结点的:相反的,我们通过路径拷贝来创建新的结点。下面的图片展示了这个操作,带有竖条纹的persistent vectror已经拷贝了元素"3"的路径,并且将“3”替换成了“F”
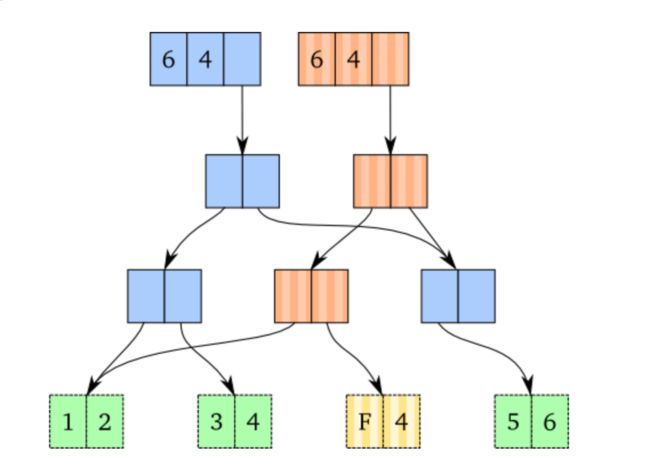
现在,我们想要改变结点,而不是拷贝,仅仅当这个操作不影响其他引用才可以。所以,这种情况在满足以下条件时:
- 仅仅可以通过原来的vector拿到,并且
- 旧的vector在更新后永远不会被用到
这是说的通的:因为旧的vector在之后并不会被用到,所以改变那些仅能通过这个vector访问到的结点是可以的
如下图所示,假定没有条纹的vector在更新之后将永远不会被用到,并且它的所有的结点都只能通过它访问到。叶子结点(有虚线边框的)与其他的persisten vector共享

我们可以改变这个vector的结点,因为这样做是安全的。竖条纹的区域显示了我们走过的路径,和改变的区域一样??不能改变包含“3”和“4”的叶子结点,因为它可能会被其他的vector引用。相反的,我们拷贝它,就和之前的路径拷贝中的做法一样。当然,如果在更新后并且抛弃到旧的vector,想要再改变"F"或“4”,可以直接改变叶子结点,因为只有这个vector可以获取到这个结点。
因为就的vector将不会被再次用到,我们也不需要再产生一个新的vector头部。我们仅仅是改变旧的vector head来避免内存分配。
这听起来很简单,但是我们必须知道这些结点仅仅可以通过原始的vector访问到。可以分成两步:
- 检查一个结点是否是在改变这个vendor的过程中创建的
- 确保没有其他已经创建的vendor
为什么这样就够了?如果我们正在改变的结点是在vendor创建时被创建的,以前的vectors都不指向它。除了这个,没有其他的vector被创建,那么很显然这些结点只能通过这个vector访问到。
标识
为了找到这个vendor创建的结点,我们为每个新的vector创建了一个唯一id,并且用我们创建的这个id标识拷贝/创建的结点。通过这种方法,我们知道哪些结点是通过正在操作的这个vector创建的。If we additionally know that this vector satisfies 2. (No other vector created out of the original),那么在这个结点上改变是安全的。We will see how we can ensure 2. later, but for now, assume that 2. is true for this section.
假定给没个vector添加id,包括那些不可改变的。在上个例子中,没做改变之前,添加id后如下所示:
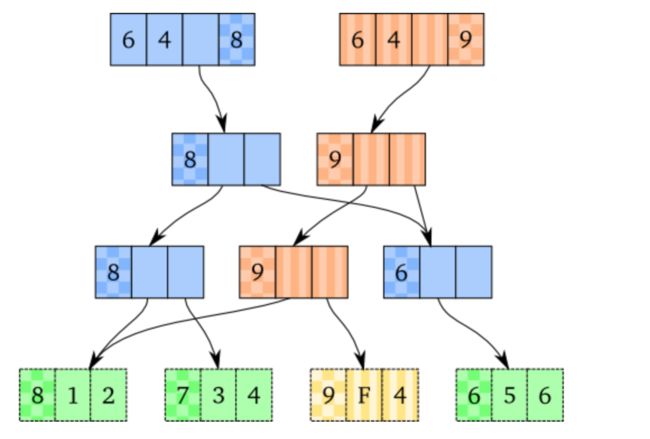
为了能说明用整型表示id,其他任何能保证唯一性的类型都行。这些新的用方格填充的格子,包含vector的Id。原来的vector的id是8,在它创建时保证了这些结点也是8。新的vector的id是9,那它创建的结点的id也是9.其他有不同id的结点,6和7,是id为8的vector的前一个版本的结点。
现在,假定id为8的vector将不会被用到,这个vector的下一版本是id为9的vector。那么直接改变id为8的vector的结点是安全的,如下:
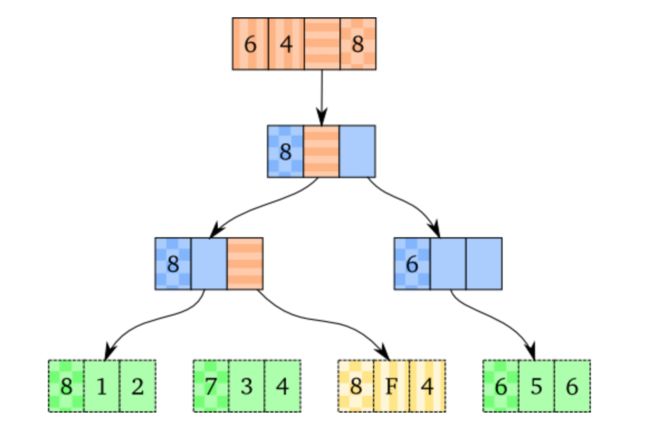
注意到,我们已经重用了head和id。这样做是可行的,因为旧的vector不会在被用到了。
更新
现在,结点上的id很容已理解也很容易实现。更复杂的问题是,如何保证其他的vector没有被创建。更多的,we want to ensure that the transients aren't used after they have been updated-否则当从不同位置找同一个元素时,可能会得到不通的结果,这是非常危险的。
你可以想象有一个高效并且聪明的编辑器可以帮助判断transient优化是否是安全的。不幸的是,通过这种方法还有很多问题。首先,需要一个高效的编辑器,但是很可能它无法覆盖到所有的例子;第二,将这个优化放在首位,是因为我们想在我们工作的系统上有更高的性能优化:那意味着我们必须保证这个优化发生。
鉴于这些原因,为了用transient优化,你必须再明确创建一个transient vector,在conjur实现这个,需要用到transient函数。transient vector的改变将不会在原来的vector中反应,原来的vector仍然是不可变的。
现在看来,保证已经更新的vector不被使用是简单的。当transient更新后,再对它做任何事情都是不合法的。在transient vector上更新是无效的:一旦开始transient vector更新,在原来vector上的操作(other updates, lookups)都是无效的。
那看起来是很好的,那如何保证已经更新的transient不被引用呢?如果创建一个vector头部,我们会在内存分配上浪费时间。另一方面,如果我们重用头部,如果旧的transient被引用,则无法抛出异常。在Clojure,我们必须信任开发者不会用到无效到transient。你可以在一些语言中用类型检查来避免这些问题,但是现在还没有完美适合transient的解决方案。
所有在transient vector上的更新返回一个transient用来保持性能,也可以将transient转换成persistent vector
Creating Transients
通过persistent vector创建一个transient是简单的:拷贝vector头部,并且创建一个新的唯一id。
如果vector有尾部数据,我们也拷贝它,并且扩展至最大容量。为什么?尾部数据通常是紧凑的,向它添加数据需要拷贝整个数据。最坏情况下,将意味着在32个数据容量下,需要拷贝31个数据,这显然是不好的。一个较好的方式是扩展至最大容量并且直接修改它。
下面的例子展示了创建transient,4-分支。它们仍有相同的root。因为transient head的id与root的id不同-在这个例子中,0或者null-
在root上的第一次更行将会是一个普通路径拷贝更新。
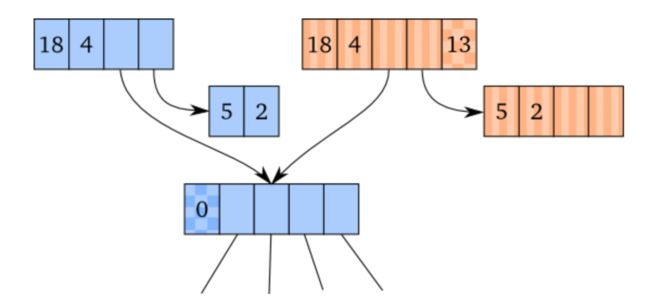
可以看到,原来的persistent vector头部不包含任何id字段。这样做的原因是persistent vector的实现并不需要id。id也可能是null(或者0),它们一般会出现在persistent vector上。只要transient有非null的id,就不会有问题。
总之,创建一个transient需要我们创建一个唯一id、一个transiant vector头部、扩展尾部数据。很显然,时间复杂度是(O(1)).
immutable 用_ownerID来表示唯一id,当是一个不可变数据时,值为undefined,否则每个transiant的_ownerId都是一个新的对象
function OwnerID() {}
Now With More Complexity
Clojure里的实现会和上面讲的有些区别,但思想是一致的。下面看下区别在哪。
首先,id不存储在vector头部,而是存储在vector的root结点中。那意味着这个跟结点也需要拷贝。
第二,id不是整型,是一个AtomicReference,包含tread id,这个值在persistent vector中是null。所以在clojur中创建transient,会像下面一样:

From Transients to Persistent
转换回 persistent vector也不是很复杂。需要拷贝vector head(去掉id)、压缩尾部数据。也需要将transients的id置为nul(0)
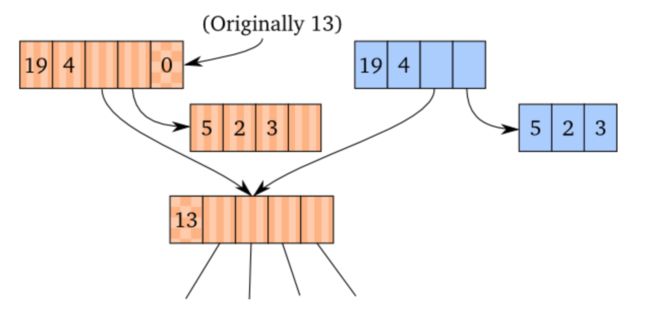
拷贝vector头部和压缩尾部数据是有意义的,为什么要将transient里的id字段置为null呢?While we cannot ensure that the transient is used correctly while it's updated, we know that the user cannot use the transient after it is converted to a persistent variant.我们知道persistent vectors用null作为id,所以transients不允许用null作为id。
这意味着当transient的id不为null时,任何引用操作都是不合法的,因为我们知道它必须被转换成persistent vector。我们可以检查id,如果是null,就抛出异常。
和将persistent vecotor转为transient一样,转换回来也只是耗费了常数时间(O(1)).
It's All in the Details
当然,clojure版本的实现和上面有些不同,但都是遵循同一个规则:拷贝vector head, 压缩尾部数据,将id置为空. 因为id保持在root里,就把root中的id置为空。

总结
transient是对不可变结构的一种优化,降低了内存分配的数量。这对对于性能要求的代码有很大的影响
一个有价值的点是,和persistent有部分相同的api。那意味着在更新数据时(比如添加一个“!”)你可以用同样的查询和更新方法。
在性能要求高的代码上将persistent data转化成transient不是困难的事,唯一需要考虑的就是不要用一个已经更新过的transient