Hadoop大数据平台入门——HDFS和MapReduce
https://blog.csdn.net/a60782885/article/details/71304913
背景
随着硬件水平的不断提高,需要处理数据的大小也越来越大,21世纪是大数据的世纪。
随着数据的不断变大,数据的处理就出现了瓶颈:存储容量,读写速率,计算效率等等。为了处理大数据,google提出了大数据技术,MapReduce,BigTable和GFS。
这些技术给大数据处理带来了巨大的变革:
1.降低了大数据处理的成本,用PC机就可以处理大数据,而不需要采用大型机和高端设备进行存储。
2.将硬件故障视为常态的基础上,采用了软件容错的方法,保证软件的可靠性。
3.简化并行分布式计算,不需要控制节点的同步和数据的交换,降低了大数据处理的门槛。
模仿谷歌的大数据技术出现了,Hadoop!
什么是Hadoop
Hadoop主要完成两件事,分布式存储和分布式计算。
Hadoop主要由两个核心部分组成:
1.HDFS:分布式文件系统,用来存储海量数据。
2.MapReduce:并行处理框架,实现任务分解和调度。
Hadoop能做什么
Hadoop能完成大数据的存储,处理,分析,统计等业务,在数据挖掘等方面应用广泛。
Hadoop的优势
1.高扩展性。简单的增加硬件就可以达到效果的提高。
2.低成本,用PC机就能做到。
3.Hadoop具有成熟的生态圈,比如Hive,Hbase,zookeeper等,让Hadoop用起来更方便。
Hadoop的两个核心组成:HDFS和MapReduce
(1)HDFS是什么?
HDFS是一个分布式文件系统,用来存储和读取数据的。
文件系统都有最小处理单元,而HDFS的处理单元是块。HDFS保存的文件被分成块进行存储,默认的块大小是64MB。
在HDFS中有两类节点:NameNode和DataNode。
NameNode:
NameNode是管理节点,存放文件元数据。也就是存放着文件和数据块的映射表,数据块和数据节点的映射表。
也就是说,通过NameNode,我们就可以找到文件存放的地方,找到存放的数据。
DataNode:
DataNode是工作节点,用来存放数据块,也就是文件实际存储的地方。
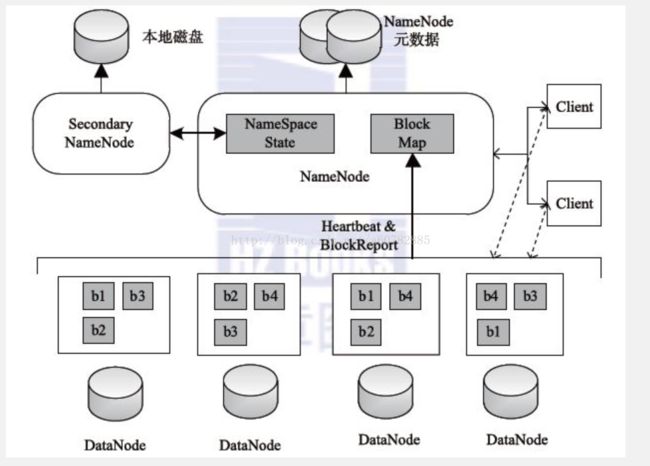
客户端向NameNode发起读取元数据的消息,NameNode就会查询它的Block Map,找到对应的数据节点。然后客户端就可以去对应的数据节点中找到数据块,拼接成文件就可以了。这就是读写的流程。
作为分布式应用,为了达到软件的可靠性,如图上所示,每个数据块都有三个副本,并且分布在两个机架上。
这样一来,如果某个数据块坏了,能够从别的数据块中读取,而当如果一个机架都坏了,还可以从另一个机架上读取,从而实现高可靠。
我们从上图还可以看到,因为数据块具有多个副本,NameNode要知道那些节点是存活的吧,他们之间的联系是依靠心跳检测来实现的。这也是很多分布式应用使用的方法了。
我们还可以看到,NameNode也有一个Secondary NameNode,万一NameNode出故障了,Secondary就会成替补,保证了软件的可靠性。
HDFS具有什么特点呢?
1.数据冗余,软件容错很高。
2.流失数据访问,也就是HDFS一次写入,多次读写,并且没办法进行修改,只能删除之后重新创建
3.适合存储大文件。如果是小文件,而且是很多小文件,连一个块都装不满,并且还需要很多块,就会极大浪费空间。
HDFS的适用性和局限性:
1.数据批量读写,吞吐量高。
2.不适合交互式应用,延迟较高。
3.适合一次写入多次读取,顺序读取。
4.不支持多用户并发读写文件。
hdfs(分布式文件系统)
优点
支持超大文件
支持超大文件。超大文件在这里指的是几百M,几百GB,甚至几TB大小的文件。一般来说hadoop的文件系统会存储TB级别或者PB级别的数据。所以在企业的应用中,数据节点有可能有上千个。
检测和快速应对硬件故障
在集群的环境中,硬件故障是常见的问题。因为有上千台服务器连接在一起,这样会导致高故障率。因此故障检测和自动恢复是hdfs文件系统的一个设计目标。
流式数据访问
Hdfs的数据处理规模比较大,应用一次需要访问大量的数据,同时这些应用一般都是批量处理,而不是用户交互式处理。应用程序能以流的形式访问数据集。主要的是数据的吞吐量,而不是访问速度。
简化的一致性模型
大部分hdfs操作文件时,需要一次写入,多次读取。在hdfs中,一个文件一旦经过创建、写入、关闭后,一般就不需要修改了。这样简单的一致性模型,有利于提高吞吐量。
缺点
低延迟数据访问
低延迟数据。如和用户进行交互的应用,需要数据在毫秒或秒的范围内得到响应。由于hadoop针对高数据吞吐量做了优化,牺牲了获取数据的延迟,所以对于低延迟来说,不适合用hadoop来做。
大量的小文件
Hdfs支持超大的文件,是通过数据分布在数据节点,数据的元数据保存在名字节点上。名字节点的内存大小,决定了hdfs文件系统可保存的文件数量。虽然现在的系统内存都比较大,但大量的小文件还是会影响名字节点的性能。
多用户写入文件、修改文件
Hdfs的文件只能有一次写入,不支持写入,也不支持修改。只有这样数据的吞吐量才能大。
不支持超强的事务
没有像关系型数据库那样,对事务有强有力的支持。
(2)MapReduce是什么?
MapReduce是并行处理框架,实现任务分解和调度。
其实原理说通俗一点就是分而治之的思想,将一个大任务分解成多个小任务(map),小任务执行完了之后,合并计算结果(reduce)。
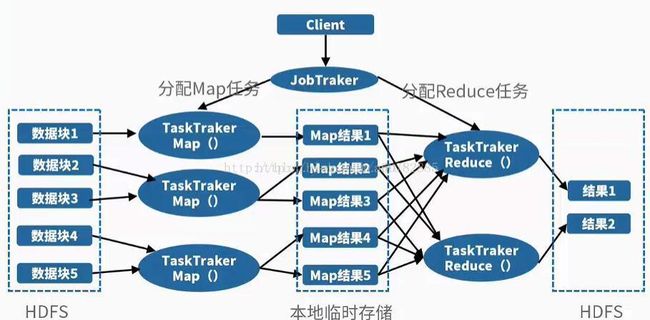
MapReduce的整个工作过程如上图所示,它包含如下4个独立的实体:
实体一:客户端,用来提交MapReduce作业。
实体二:JobTracker,用来协调作业的运行。
实体三:TaskTracker,用来处理作业划分后的任务。
实体四:HDFS,用来在其它实体间共享作业文件。
首先我们需要先知道几个小概念:
job:在Hadoop内部,用Job来表示运行的MapReduce程序所需要用到的所有jar文件和类的集合,这些文件最终都被整合到一个jar文件中,将此jar文件提交给JobTraker,MapReduce程序就会执行。
task:job会分成多个task。分为MapTask和ReduceTask。
jobTracker:管理节点。将job分解为多个map任务和reduce任务。
作用:
(1)作业调度
(2)分配任务,监控任务执行进度
(3)监控TaskTracker状态
taskTracker:任务节点。一般和dataNode为同一个节点,这样计算可以跟着数据走,开销最小化。
作用:
(1)执行任务
(2)汇报任务状态
也就是说,JobTracker拿到job之后,会把job分成很多个maptask和reducetask,交给他们执行。 MapTask、ReduceTask函数的输入、输出都是
HDFS存储的输入数据经过解析后,以键值对的形式,输入到MapReduce()函数中进行处理,输出一系列键值对作为中间结果,在Reduce阶段,对拥有同样Key值的中间数据进行合并形成最后结果。
这样,我们就大致了解了Hadoop其中的原理,主要了解HDFS文件系统的存储过程和MapReduce的作业调度分配过程。