TCP/IP协议簇之应用层
文章目录
- 应用层
- 再谈 "协议"
-
- 网络版计算器
- HTTP协议
-
- 认识URL
- urlencode和urldecode
- HTTP三大特点
- HTTP协议格式
- HTTP的方法
- HTTP的状态码
- HTTP常见Header
- 最简单的HTTP服务器
- http与https
-
- 对称加密与非对称加密
- 混合加密
应用层
我们程序员写的一个个解决我们实际问题, 满足我们日常需求的网络程序, 都是在应用层.
再谈 “协议”
协议是一种 “约定”. socket api的接口, 在读写数据时, 都是按 “字符串”(字符串描述不准确) 的方式来发送接收的. 如果我们要传输一些"结构化的数据" 怎么办呢?
通过序列化与反序列化实现,我们发送数据至网络要进行序列化,将“结构化的数据”合为一个整体,网络发送数据给另一端接收时,要进行反序列化,将整体数据又转化为“结构化数据”。进行序列化的工具有json,xml
网络版计算器
例如, 我们需要实现一个服务器版的加法器. 我们需要客户端把要计算的两个加数发过去, 然后由服务器进行计算, 最后再把结果返回给客户端.
约定方案一:
- 客户端发送一个形如"1+1"的字符串;
- 这个字符串中有两个操作数, 都是整形;
- 两个数字之间会有一个字符是运算符, 运算符只能是 + ;
- 数字和运算符之间没有空格;
- …
约定方案二:
- 定义结构体来表示我们需要交互的信息;
- 发送数据时将这个结构体按照一个规则转换成字符串, 接收到数据的时候再按照相同的规则把字符串转化回结构体;
- 这个过程叫做 “序列化” 和 “反序列化”
protocol.hpp
// protocol.hpp 定义通信的结构体
#pragma once
typedef struct request{
int x;
int y;
char op;//操作符
}request_t;
typedef struct response{
//code为0:运算正常
//code为1:/的除数为0
//code为2:%的除数为0
//code为3:操作符不合法
int code;//退出码
int result;//结果
}response_t;
// client.hpp
#pragma once
#includeserver.hpp
#pragma once
#include无论我们采用方案一, 还是方案二, 还是其他的方案, 只要保证, 一端发送时构造的数据, 在另一端能够正确的进行解析, 就是ok的,比如输入顺序。这种约定, 就是 应用层协议
我们对上述计算进行抓包:sudo tcpdump -i any -nn tcp port 8080
三次握手,四次挥手

HTTP协议
虽然我们说, 应用层协议是我们程序猿自己定的.
但实际上, 已经有大佬们定义了一些现成的, 又非常好用的应用层协议, 供我们直接参考使用. HTTP(超文本传输协议)就是其中之一.
认识URL
平时我们俗称的 “网址” 其实就是说的 URL

互联网行为
- 把服务器的数据拿下来
- 把自己的数据传上服务器
urlencode和urldecode
像 / ? : 等这样的字符, 已经被url当做特殊意义理解了. 因此这些字符不能随意出现.
比如, 某个参数中需要带有这些特殊字符, 就必须先对特殊字符进行转义.
转义的规则如下:
将需要转码的字符转为16进制,然后从右到左,取4位(不足4位直接处理),每2位做一位,前面加上%,编码成%XY格式
例如:

“+” 被转义成了 “%2B”
urldecode就是urlencode的逆过程
urlencode工具
HTTP三大特点
-
无连接。前面我们知道,TCP是要连接的,但TCP建立连接和http无关,http直接向服务器发送http request即可
-
无状态。我们用一个例子来理解无状态:当我们访问一个网站时,需要登陆,如果我们此次登陆了,下一次再访问时,由于http的无状态特性,我们需要再次输入账号密码才能登陆。这就是http的无状态。而我们实际登陆时,其实是登陆一次后之后再访问就不用输入账号密码了,这是由cookie和session实现的
-
简单快速。短链接进行文本(html、img、css、js…)传输,这是早期的http/1.0的传输方式
http/1.0支持长连接
HTTP协议格式
HTTP构成:

可以通过Fiddler进行抓包。
原理:正常上网时,我们直接通过网络发送请求给服务器即可。而Fiddler抓包是我们先给Filddler进行代理,Fiddler再通过网路发送请求给服务器,并接收响应
HTTP请求

- 首行: [方法] + [url] + [版本]
- Header: 请求的属性, 冒号分割的键值对;每组属性之间使用\n分隔;遇到空行表示Header部分结束
- Body: 空行后面的内容都是Body. Body允许为空字符串. 如果Body存在, 则在Header中会有一个Content-Length属性来标识Body的长度;
HTTP响应
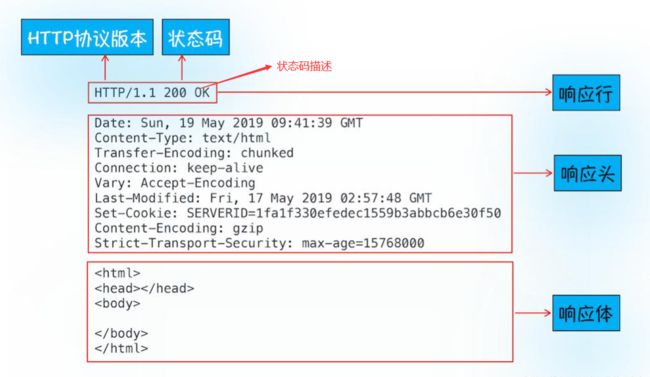
- 首行: [版本号] + [状态码] + [状态码解释]
- Header: 请求的属性, 冒号分割的键值对;每组属性之间使用\n分隔;遇到空行表示Header部分结束
- Body: 空行后面的内容都是Body. Body允许为空字符串. 如果Body存在, 则在Header中会有一个Content-Length属性来标识Body的长度; 如果服务器返回了一个html页面, 那么html页面内容就是在body中
HTTP的方法
| 方法 | 说明 | 支持的HTTP协议版本 |
|---|---|---|
| GET | 获取资源 | 1.0、1.1 |
| POST | 传输实体主体 | 1.0、1.1 |
| PUT | 传输文件 | 1.0、1.1 |
| HEAD | 获得报文首部 | 1.0、1.1 |
| DELETE | 删除文件 | 1.0、1.1 |
| OPTIONS | 询问支持的方法 | 1.1 |
| TRACE | 追踪路径 | 1.1 |
| CONNECT | 要求用隧道协议连接代理 | 1.1 |
| LINK | 建立和资源之间的联系 | 1.0 |
| UNLINE | 断开连接关系 | 1.0 |
其中最常用的就是GET方法和POST方法.
Head不获取正文信息,只获取前三个信息(请求/响应行、报头、空行)
HTTP的状态码

最常见的状态码, 比如 200(OK), 404(Not Found), 403(Forbidden), 302(Redirect, 重定向), 504(Bad Gateway)
HTTP常见Header
- Content-Type: 数据类型(text/html等)
- Content-Length: Body的长度
- Host: 客户端告知服务器, 所请求的资源是在哪个主机的哪个端口上;
- User-Agent: 声明用户的操作系统和浏览器版本信息;
- referer: 当前页面是从哪个页面跳转过来的;
- location: 搭配3xx状态码使用, 告诉客户端接下来要去哪里访问;
- Cookie: 用于在客户端存储少量信息. 通常用于实现会话(session)的功能;
User-Agent里的历史故事
Cookie的介绍:之前我们了解了http的无状态特性,这样会给用户带来很差的体验,而cookie就是来解决这个问题的。
原理:同样以网站的登录为例来理解,我们在网站上第一次登录时,服务器端就保存了用户名和密码的信息,服务器进行响应时,会在response中包含set-cookie:用户名、密码…的信息,客户端收到后,浏览器就在cookie这个文件中保存了这个信息。下一次进入这个网站,浏览器对网站发送请求时,就会携带这个cookie文件与request一起发送给服务器,服务器进行核对,核对正确后,就不再需要我们手动输入密码了。
cookie的本质是浏览器的一个文件,它分为内存级的和磁盘级的。内存级的cookie只在当前浏览器打开时间内有效,关闭浏览器下次再打开时,我们再次进入网站,还是需要输入账号密码进行登录。磁盘级的cookie则是保存在本地的,这样就不受浏览器打开这一条件限制,可以保存较长的时间。
但实际上,这样也是有风险的,万一我们被黑客入侵,获取到了本地的cookie,他就可以通过这个cookie访问我们同样访问过的信息。
Session就是与Cookie配套使用的。我们第一次登录后,服务器不再将用户名和密码response回来,而是在服务器上用一个session文件保存我们的私密信息,然后生成一个唯一的sid来标识它,之后同样在response里,由set-cookie:sid,此时是将sid返回,本地的cookie中保存sid。下一次访问网站时,浏览器携带cookie发送请求,服务器通过sid找到客户的信息,然后允许客户访问。
cookie和session是相对安全的,但还是有可能会被盗取。此时盗取的只是sid,而不是我们的用户名和密码了。而且他也不知道sid对应的是哪个网站。而要改密码是要原密码的,除非我们密码太简单被别人识破,否则他就不能修改我们的密码然后让我们永远地失去这个账号,除非把后台服务器攻破,拿到密码。
最简单的HTTP服务器
实现一个最简单的HTTP服务器, 只在网页上输出 “hello world”; 只要我们按照HTTP协议的要求构造数据, 就很容易能做到;
#includeysj \
\
\
Welcome
\
Hello World !
\
\
\r\n";
send(sock, response.c_str(), response.size(), 0);
}
close(sock);
}
void start()
{
while (1)
{
//建立连接
sockaddr_in peer;
socklen_t len = sizeof(peer);
bzero(&peer, len);
int sock = accept(_lsock, (struct sockaddr*)&peer, &len);
if (sock < 0)
{
cerr << "accept error !" << endl;
continue;
}
cout << "get a link..." << endl;
//创建子进程处理任务
pid_t id = fork();
if (id == 0)//子进程
{
//父进程忽略子进程发送的SIGCHLD信号
close(_lsock);
EchoHttp(sock);
exit(0);
}
close(sock);
}
}
};
编译, 启动服务. 在浏览器中输入 http://[ip]:[port], 就能看到显示的结果 “Hello World”

备注:
此处我们使用 8080 端口号启动了HTTP服务器. 虽然HTTP服务器一般使用80端口,但这只是一个通用的习惯. 并不是说HTTP服务器就不能使用其他的端口号.
使用chrome测试我们的服务器时, 可以看到服务器打出的请求中还有一个 GET /favicon.ico HTTP/1.1 这favicon.ico_百度百科 (baidu.com)
如果我们把状态码设置成404会不会显示经典的Not Found页面?
答案是:不会的,页面的显示是要靠html来设置的,不是由状态码决定的
临时重定向和永久重定向
配合状态码3xx使用。浏览器在接收到重定向响应的时候,会采用该响应提供的新的 URL ,并立即进行加载;大多数情况下,除了会有一小部分性能损失之外,重定向操作对于用户来说是不可见的。
将上面的服务器改造,设置成重定向:
响应报头中设置:location: http://baidu.com\r\n
不需要正文。
//响应行
string response = "HTTP/1.0 302 Found\r\n";
//响应报头
response += "Content-type: text/html\r\n";//发送的类型是html,网页类型
response += "location: https://www.baidu.com\r\n";//发送的类型是html,网页类型
//响应空行
response += "\r\n";
输入云服务器公网ip加端口号后,就会跳转到百度了
http与https
https是在http与传输层直接再加了一层SSL/TLS(TLS是SSL的标准化版本):对数据进行加密/解密。
大部分情况下都是使用对称加密。
对称加密与非对称加密
对称加密:只有一个密钥,按同一个密钥进行加密和解密。客户端将数据按照密钥进行加密,服务器按照密钥对数据进行解密。密钥只有客户端和服务器双方知道。即将密钥也发送给服务器,但是这有可能会被黑客劫持,所以单纯的对称加密是不安全的。
于是就有了非对称加密:
非对称加密:通过公钥和私钥的方式来进行加密和解密。通常情况下,公钥用来加密,私钥用来解密。
下图展示了非对称加密发送密钥的过程:
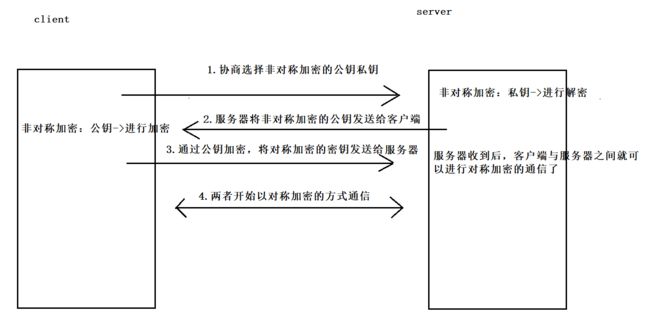
服务器有很多种公钥私钥的算法,客户端与服务器协商使用哪种算法,协商好后,各自会生成一对公钥私钥。服务器将自己的公钥发送给客户端,私钥留给自己,这样,客户端就可以用服务器的公钥对发送的数据加密,而加密的数据只能用服务器的私钥来解密。然后客户端也将自己的公钥发送给服务器,服务器得到客户端的公钥后,就可以将数据按照公钥加密发送给客户端,同样,只有客户端的私钥才能对其解密。
现在我们虽然可以对数据进行加密,但是我们还不清楚对方是否是我们想要沟通的对象,服务端需要申请SSL证书来证明它的身份,要让SSL证书生效就要向CA(Certificate Authority证书授权中心,大家都信任这个机构颁发的证书)申请,证书表明了域名是属于谁的等等信息。
在客户端和服务器完成三次握手后,双方会协商加密方法,然后服务器会发送证书给客户端以示自己的身份。
混合加密
虽然我们可以用非对称加密来进行通信,但每次通信都用非对称加密,加密解密的时间就要花费很多时间,影响效率。所以实际上采用的是两者混合的方式进行加密,即先通过非对称加密获取双方的公钥后,服务器再通过非对称加密方式发送对称密钥,这样客户端收到后,两者就可以按照对称加密的方式进行通信了。
为什么要使用对称加密?
非对称加密:效率比较低
对称加密:效率较高