文本分析主要应用于问答系统的开发,如基于知识的问答系统(Knowledge-based QA),基于文档的问答系统(Documen-based QA),以及基于FAQ的问答系统(Community-QA)等。无论哪一种问答系统的开发,都离不开自然语言的理解,而文档相似度的判断对这个方面有着重要影响。
1. BM25算法(非语义匹配)
bm25 是一种用来评价搜索词和文档之间相关性的算法,它是一种基于概率检索模型提出的算法,再用简单的话来描述下bm25算法:我们有一个query和一批文档Ds,现在要计算query和每篇文档D之间的相关性分数。

算法核心:
BM25算法是一种常见用来做相关度打分的公式,思路比较简单,主要就是计算一个query里面所有词q1,q2...qn和文档的相关度,然后再把分数做累加操作。公式如下:
其中R(qi,d)是查询语句query中每个词qi和文档d的相关度值,Wi是该词的权重,最后将所有词的Wi∗R(qi,d)相加。
Wi一般情况下为IDF(InverseDocumentFrequency)值,即逆向文档频率,公式如下:
其中N是文档总数,n(qi)是包含该词的文档书,0.5是调教系数,避免n(qi)=0的情况。log函数是为了让IDF的值受N和n(qi)的影响更加平滑。
从公式中显然能看出IDF值的含义:即总文档数越大,包含词qi的文档数越小,则qi的IDF值越大。
白话举例就是:比如我们有1万篇文档,而单词basketball,Kobe Bryant几乎只在和体育运动有关的文档中出现,说明这两个词的IDF值比较大,而单词is, are, what几乎在所有文档中都有出现,那么这几个单词的IDF值就非常小。
解决了Wi,现在再来解决R(qi,d)。R(qi,d)公式如下:
其中k1,k2,b都是调节因子,一般k1=1,k2=1,b=0.75。
式中qfi为词qi在查询语句query中的出现频率,fi为qi在文档d中的出现频率。由于绝大多数情况下一条简短的查询语句query中,词qi只会出现一次,即qfi=1,因此公式可化简为:
dl为文档d的长度,avgdl为所有文档的平均长度。意即该文档d的长度和平均长度比越大,则K越大,则相关度R(qi,d)越小,b为调节因子,b越大,则文档长度所占的影响因素越大,反之则越小。
白话举例就是:一个query为:诸葛亮在哪里去世的?
document1的内容为:诸葛亮在五丈原积劳成疾,最终去世;
document2的内容为:司马懿与诸葛亮多次在五丈原交锋;
而document3为一整本中国历史书的内容。
显然document3中肯定包含了大量[诸葛亮]、[哪里]、[去世]这些词语,可是由于document3文档长度太大,所以K非常大,所以和query中每个词qi的相关度R(qi,d)非常小。
综上所述,可将BM25相关度打分算法的公式整理为:
优缺点:
适用于:在文档包含查询词的情况下,或者说查询词精确命中文档的前提下,如何计算相似度,如何对内容进行排序。
不适用于:基于传统检索模型的方法会存在一个固有缺陷,就是检索模型只能处理 Query 与 Document 有重合词的情况,传统检索模型无法处理词语的语义相关性。
白话举例:提出一个query:当下最火的女网红是谁?
在Document集合中document1的内容为:[当下最火的男明星为鹿晗];
document2的内容为:[女网红能火的只是一小部分]。
显然document1和document2中都包含[火]、[当下]、[网红]等词语。但是document3的内容可能是:[如今最众所周知的网络女主播是周二柯]。很显然与当前Query能最好匹配的应该是document3,可是document3中却没有一个词是与query中的词相同的(即上文所说的没有“精确命中”),此时就无法应用BM25检索模型。
代码:
BM25代码(未完待续) -
2. WMD算法(语义匹配)
WMD(word mover's distance) 算法是文本语义相似度计算的一种方法,其语义表示可以基于word2vec得到的embedding向量。当然,其他word embedding 方法也可以,如果你的embedidng 方法有语义的特性,anyway is ok ! 这里我们就以比较简单的word2vec方法为例说明。
Word2Vec将词映射为一个词向量,在这个向量空间中,语义相似的词之间距离会比较小,而词移距离(WMD)正是基于word2vec的这一特性开发出来的。Word2Vec得到的词向量可以反映词与词之间的语义差别,那么如果我们希望有一个距离能够反映文档和文档之间的相似度,应该怎么做呢?一个想法是将文档距离建模成两个文档中词的语义距离的一个组合,比如说对两个文档中的任意两个词所对应的词向量求欧氏距离然后再加权求和,大概是这样的形式:
其中c(i,j)为i,j两个词所对应的词向量的欧氏距离。
那我们怎样得到这个加权矩阵T呢?又或者说这个加权矩阵T代表什么含义呢?在我看来,这个加权矩阵T有些类似于HMM中的状态转移矩阵,只不过其中的概率转换为权重了而已。我们再来看下面这个图:
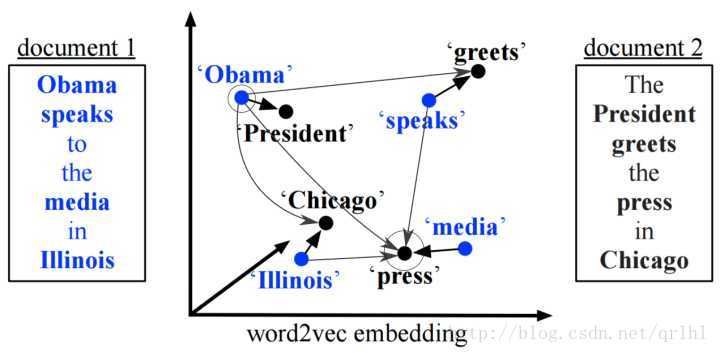
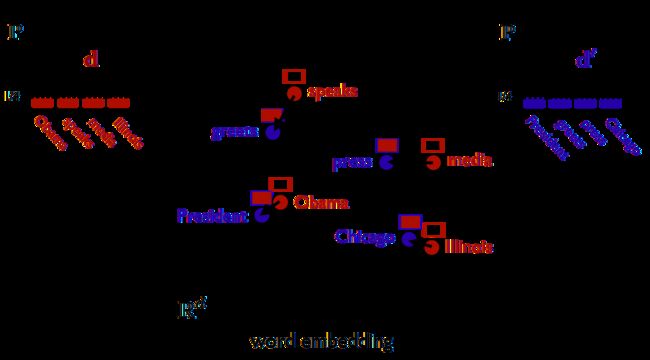
这里有两个文档,去除停用词后,每篇文档仅剩下4个词,我们就是要用这四个词来比较两个文档之间的相似度。在这里,我们假设’Obama’这个词在文档1中的的权重为0.5(可以简单地用词频或者TFIDF进行计算),那么由于’Obama’和’president’的相似度很高,那么我们可以给由’Obama’移动到’president’很高的权重,这里假设为0.4,文档2中其他的词由于和’Obama’的距离比较远,所以会分到更小的权重。这里的约束是,由文档1中的某个词i移动到文档2中的各个词的权重之和应该与文档1中的这个词i的权重相等,即’Obama’要把自己的权重(0.5)分给文档2中的各个词。同样,文档2中的某个词j所接受到由文档1中的各个词所流入的权重之和应该等于词j在文档2中的权重。
代码:
gensim/WMD_tutorial.ipynb at c971411c09773488dbdd899754537c0d1a9fce50 · RaRe-Technologies/gensim · GitHub
word-movers-distance-in-python
参考:
经典检索算法:BM25原理 -
自然语言处理-BM25相关度打分 - 537云起云落 - CSDN博客
基于word2vec与Word Mover Distance的文档相似度计算 - qq_36446111的博客 - CSDN博客
From Word Embeddings To Document Distances
大连理工大学信息检索研究室(DUTIR)-搜人搜物搜信息,重情重义重认知
Supervised Word Mover's Distance (可监督的词移距离)
supervised-word-movers-distance
唐诗掠影:基于词移距离(Word Mover's Distance)的唐诗诗句匹配实践 - 梳下鱼 - 博客园
Navigating themes in restaurant reviews with Word Mover’s Distance
Word Mover’s Distance in Python