前言
这个知识点计划分3篇文章来讲解。
1、java注解是什么?
注解是jdk1.5引入的一个新特性;
可以把它理解为一种能够跟代码绑定并且能够存储数据的技术;
【与代码绑定】指的是它直接依附在代码上,然后【能够存储数据】是指注解里存放着能够描述它所依附的代码的信息;
所以简单点理解注解就是被造出来存储数据的,而它所存储的数据又是用于描述它所依附的代码元素的,它依附在哪里,描述的就是哪个代码元素。
而我们用专业点的叫法的话,注解所存储的那些数据我们称之为java代码元素的元数据。
2、Java的代码元素是什么呢?
这个元素只是我自己命的名。
例如java的类、接口、枚举、方法、属性、参数都属于java的代码元素。
3、什么是元数据?
元数据解释起来呢就是用来描述某种事物的数据,这样解释可能会挺抽象的,那咱们换一种方式,直接举个例子说明吧:
我们应该都操作过文件吧,不管是linux系统还是windows系统的文件,文件的作用就是用来存储数据,那我们操作的时候如何分辨文件的"身份"呢,要怎样把每个不同的文件区分开呢?可以给文件起个唯一的名字吧,这样通过文件名我是不是就可以知道要操作的是哪个文件了;
再者我想要知道某个文件存储的数据的字节大小是多少,那我该怎么办呢?是不是要重新对文件从头到尾读一遍,然后计算出文件的字节数;当然不需要这样做,我们可以在一开始写文件的同时就对文件的大小进行统计,写入完成后就把统计得到的文件的大小存储起来,后续要拿文件的大小的时候,我们就直接获取这个存储起来的文件字节数就行了...
像文件名就是用来描述文件的"身份"的,用于区分不同的文件;文件的大小用来描述文件存储的数据的大小;文件的修改时间用来描述文件最近一次修改发生在什么时候...
文件名、文件大小、文件的修改时间等都是一些数据,而且是用来描述一个文件的数据,那我们就会把这些数据称做文件的元数据--即用于描述文件的一些数据。
简单的说就是在某个东西已经存在的情况下,我们还需要其他的一些附加信息来对它加以描述或者说对它进行标记,那么这些数据都可以称为元数据。
3、java代码为什么会需要元数据?java代码有什么元数据?
至于它为什么需要元数据,想要解答好这个问题的话,需要一些恰当的场景来辅助描述才好解析。
例如拿类继承的例子来说,子类在继承父类时,可以选择重写父类的方法,后续我们通过子类对象调用方法时,需要调用的是跟父类方法名一样的方法,但是因为子类重写了逻辑,所以虽然方法名相同,但是逻辑却不一样了;
在这种情况下,当代码在编译时,我们希望编译器能够帮助我们对这种继承的代码校验一下,看看这个方法是不是重写的父类方法(检查它的方法名、参数、返回值、权限修饰符等);
因为我们在定义一个子类继承一个父类时,子类也是可以定义自己的方法的,那编译器是如何知道子类的哪些方法是需要进行校验它是否是重写的父类方法的呢?
这个时候应该怎么办?我们是不是得对重写父类的方法标记一下,到时候编译阶段好让编译器知道:噢,你就检查那些做了标记的方法是不是重写的父类方法就行,没做标记的不用检查了,它是子类自己定义的。
那这个标记就是用于对代码元素(Method)进行描述的,它就是这个代码元素的元数据,而存储这个标记信息的就是注解;
java内置了标记方法是否重写的注解,它就是@Override,这个注解我们应该经常能够看到。
在编译的时候,编译器获会判断这个方法上是否使用了@Override这个注解,如果使用了这个注解,那么就检查它是不是重写的父类方法:主要是检查父类中是不是也存在这么一个方法名、参数、返回值类型、权限修饰符等与它一样的方法,如果是,则说明是重写的父类方法,否则,它用了注解,但是父类中却不存在这个方法,那就是代码有问题,编译就无法通过;如果方法没有使用@Override这个注解,那编译器就会认为它是子类自己定义的方法,不是重写的父类方法,那父类中不存在肯定是正常的。
也就是说我们强烈建议,开发人员在重写父类方法时一定要加上@Override这个注解(现在idea这些开发工具可能都会自动加的),让编译器能够对这个方法进行校验,避免出现如下的问题:
我们分明是想重写父类的saying()方法的,但是因为不细心而把方法名写错了,写成了sayign(),而父类中又没有toStrign()这个方法,并且因为开发者没有加@Override注解,所以编译器就认为sayign()这个方法是子类自己定义的方法了,所以也不会报错;
而这就会导致我们后期调用方法时可能会出现调用错的问题,很明显,我们重写方法,肯定是希望沿用父类定义的这个saying()方法的,只是实现逻辑不一样而已,所以我们在重写方法的时候,实际上实现的是sayign()的逻辑,但是我们潜意识里不知道自己把方法名写错了,一直认为自己修改的是saying()方法,所以最后调用的时候,调用的很大可能是saying()方法,但是这个方法依然还是父类的实现逻辑,没有执行到子类重写的逻辑,根本不会达到我们的预期效果。
所以,这就是为什么我们强烈建议在重写父类方法时为方法加上@Override注解,就是为了让编译器给我们的程序多加一层保障,有什么问题尽早在编译阶段就暴露出来(@Override标记的重写父类方法的检查是在编译阶段执行的),而不是等到程序跑起来了,在运行期间再暴露出问题,这样增加了排查难度甚至也增加修改的工作量,吃力不讨好。
加了@Override注解,就是为了避免开发者们自己潜意识里也不知道方法名写错了的问题,实际上自己以为的正在重写的方法却不是我们期望重写的方法,方法名都不一样了。
加个例子描述下上面的场景吧:
/**
* 父类
*/
public class Parent {
public void saying(){
System.out.println("我是父类");
}
}
/**
* 子类
*/
public class Child extends Parent {
public void sayign() {
System.out.println("我是子类");
}
public static void main(String[] args) {
new Child().saying();
}
}
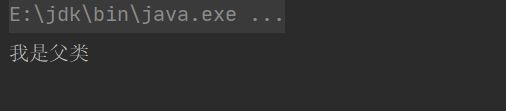
我在子类中是想重写父类的saying()方法的,但是却写错了名字,写成了sayign(),又没有加@Override注解,编译器把它认为是子类自己定义的了,编译阶段没报错,开发者也没发现错了,到最后调用的时候new Child().saying(),果然调用了saying(),结果打出来的是:我是父类,但是我预期的结果应该是:我是子类。所以这样就造成结果跟预期不一致。
但是如果我加了@Override注解,因为父类中sayign()这个方法,既然父类没有这个方法,自然重写的说法也不成立,所以在编译期会报错:

所以java代码某些情况下需要元数据,这样代码的处理器才能够对代码进行正确的处理。
而代码元素有什么元数据,这个得根据实际的场景来确定,比如这个在编译阶段校验子类方法是否重写了方法,就需要指定的方法包含【重写了父类方法标记】的元数据。
4、为什么要引入java注解呢?
如前面所说的,引入java注解的目的是为了用于存储java代码元素的元数据信息。
是的,这个说了那么多遍,相信大家都记住了,都了解了它就是用于存储信息的,但是我们还得知道我们什么时候需要用注解来存储这些元数据信息吧,注解存储的元数据信息最终又会被谁使用?
一句话,注解最终的使用者是注解处理器,注解处理器就是获取依附在代码元素上的注解并解析出注解中存储的信息的java工具(我下一章会写一个注解处理器的案例协助理解,揭示注解处理器的面目)。
而什么时候会使用注解,总结下来大概有这3大类情况吧:
1、编译器编译代码时需要对某些代码进行特殊检查或特殊处理的,这种情况下需要对代码做标识,以变编译器能够识别哪些代码是需要特殊检查或处理的代码是哪些,这时候就可以用注解来存储这些标记信息;
这类注解只会在源码阶段(.java文件)保留,编译后的.class文件中不会存在这些注解的信息了。
2、在jvm加载java的.class文件到内存中时可能需要对某些字节码文件动态地做处理,如修改字节码文件的内容,这种场景下也需要标记好哪些代码元素是需要被修改的,可以通过注解来存储这个标记;
因为jvm加载类信息是通过加载字节码流的形式进行的,所以注解处理器要获取注解的信息的话,那么.class文件中必然得保留注解信息才行,也就是说这类注解在经过编译之后,它会存在于字节码文件中。
3、在程序运行期间,某些情况下我们可能也需要对代码元素进行标记,举个例子,大家应该开发过数据库处理相关的程序,就是crud那套流程,我们要操作数据库的话,首先是不是得先建表,那我们在java代码层面是不是需要定义一个与数据库表对应的java类,然后如果要全部在java代码中实现表的创建、表的增删改查操作的话,我们有什么方法可供选择:
1)每一个javaBean类的建表、数据的增删改查操作的sql语句都事先定义好,相当于直接维护一个常量类,里面定义的sql语句表示javaBean类与数据库表之间的关系,每一个操作的sql语句都事先定义好;
public class SqlMap {
private static final String createUserSql = "create table user(" +
"id int PRIMARY KEY AUTO_INCREMENT," +
"name varchar(255) not null," +
"age int not null)" +
"ENGINE=InnoDB DEFAULT CHARSET=utf8;";
/**
* ...
*/
}
2)另外的选择就是我不想额外维护一个类来表示表的操作,希望通过注解的方式来为javaBean类的代码元素添加信息,然后通过注解处理器解析注解并生成这些建表以及增删改查语句等。
@Table("user")
public class User {
/**
* 比如通过注解存储了描述类属性的信息:
* 这个属性在数据库表中的对应的字段类型是int,
* 再者这个属性对应的表字段的约束是PRIMARY KEY AUTO_INCREMENT,主键且id自增长;
* 这些信息都是对一个类的属性进行描述,后面通过注解处理器创建表时就可以从注解中知道这个类属性对应的表字段的名称是什么,
* 类型是什么,对这个字段的约束又是什么等等。
*
*/
@Attribute("attr=id,type=int,constraint=PRIMARY KEY AUTO_INCREMENT")
private int id;
@Attribute("attr=name,type=varchar(255),constraint=NOT NULL")
private String name;
@Attribute("attr=age,type=int,constraint=NOT NULL")
private int age;
}
所以你看,我们通过注解标注了类以及属性的元数据,后面我们就可以实现一个注解处理器来解析这些注解最后生成我们预期的sql语句,由于这是发生在程序运行期间的,也就是说要在jvm运行期间解析注解的信息的话,那么注解的信息必然是被加载到jvm的内存中了。
为什么描述java代码的元数据就要引入注解呢?不能用其他的方式吗?
当然不是非得使用注解,也还有其他的方式,如使用xml文件来描述代码元素的元数据,比如用过mybatis的人都知道,mybatis就是使用xml文件来存储javaBean类与数据库表的映射关系的,这个xml文件存储的映射关系就是javaBean的元数据。
那为什么有xml这种方式还要引入注解呢?关于这个问题,我查阅了很多资料,众说纷纭,一方觉得xml是单独拎出来一个文件描述元数据,不跟代码掺杂在一块xml,这是降低了代码的耦合度,这是好事;另一方又有人觉得代码的元数据直接体现在代码上,这样代码的可读性更好,更利于理解。
总之,我觉得吧,xml和注解没有绝对的好坏,主要是看具体的应用场景中选择哪种开发起来更方便,后续维护起来更容易,那么这种技术在这种场景下就是最合适的。