基于FPGA的图像处理1--图像处理基础IP设计
Github代码地址:https://github.com/zgw598243565/MapTec4
1.1 图像行列计数 Module
图像行列计数在图像处理中非常常见。大部分算法都需要做到精准的像素定位,行列计数法是像素定位的基本方法。另外一个方法是像素计数,通常不会这样做,因为它将会给调试工作带来不便(庞大的像素计数当然没有较小的行列计数来得直观些)。
行列计数的最简单的方法是通过输入场行同步信号和像素有效信号进行计数。设计原则如下:
(1)每一场信号到来时清空行列计数。
(2)每一个行同步信号到来时行计数加1,同时清空列计数。
(3)像素有效信号有效时列计数加1。
具体实现如下,通过像素有效信号进行有效像素区域的行列计数。仿真结果如图1和图2所示。输入的测试图像分辨率是640x480大小,关于如何产生各种分辨率的图像信号,将在(基于FPGA的图像处理2--图像时序产生IP)讲述。

图 1

图 2
module ImageCounter #
(
parameter IW = 640,
parameter IH = 480,
parameter DW = 8,
parameter IW_DW = 12, /* Width of the column counter */
parameter IH_DW = 12 /* Width of the line counter */
)
(clk,arstn,vsync,hsync,dvalid,line_counter,column_counter);
input clk;
input arstn;
input vsync;
input hsync;
input dvalid;
output reg [IH_DW-1:0]line_counter;
output reg [IW_DW-1:0]column_counter;
reg rst_all; /* reset signal for line_counter and column_counter when vsync valid*/
always@(posedge clk or negedge arstn)
begin
if(~arstn)
rst_all <= 1'b1;
else
begin
if(vsync == 1'b1)
rst_all <= 1'b1;
else
rst_all <= 1'b0;
end
end
wire dvalid_rise; /* dvalid rise edge */
reg dvalid_r;
always@(posedge clk or negedge arstn)
begin
if(~arstn)
dvalid_r <= 1'b0;
else
dvalid_r <= dvalid;
end
assign dvalid_rise = (~dvalid_r) & dvalid;
/* line counter */
always@(posedge clk)
begin
if(rst_all)
line_counter[IH_DW-1:0] <= {IH_DW{1'b0}};
else
if(dvalid_rise)
begin
line_counter[IH_DW-1:0] <= line_counter[IH_DW-1:0] + {{IH_DW-1{1'b0}},1'b1};
end
end
/* column counter */
always@(posedge clk)
begin
if(rst_all)
line_counter[IW_DW-1:0]<= {IW_DW{1'b0}};
else
begin
if(dvalid_rise)
column_counter[IW_DW-1:0] <= {{IW_DW-1{1'b0}},1'b1};
else
begin
if(dvalid)
column_counter[IW_DW-1:0] <= column_counter[IW_DW-1:0] + {{IW_DW-1{1'b0}},1'b1};
end
end
end
endmodule1.2 行缓存Linebuffer Module
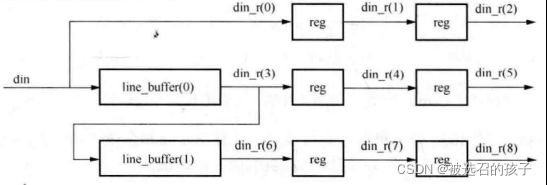
图 3
如图3所示是一个典型的二维的3x3卷积运算的结构图。二维卷积通常会对图像进行开窗,以3x3的窗口为例,至少需要得到当前窗口的9个像素值,卷积操作的流水线性质决定了一个时刻只能得到一个像素值。如果要得到前两行的像素,就必须要对前两行的像素值进行缓存。
行缓存通常会放在FPGA片内,这是由于行缓存通常不会很大,对于一个确定的算法,窗口尺寸往往已经确定。实际上,对于一个窗口尺寸为3x3的二维卷积算法,我们至少需要2个行缓存。这里为了设计的简单,我采用了3个行缓存,进行时序对齐后,进行移位开窗。采用3个行缓存是因为,在对图像进行滤波是,图像下边界和右边界会出现边界越界的问题,使用3个行缓存,便在行列对齐中解决了图像下边界越界的问题。图像右边界越界的问题由后续的滤波算法取数据时来解决。
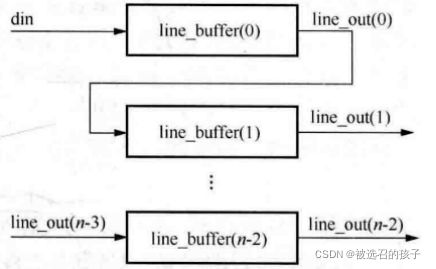
图 4
对于多行图像的对齐,一个简单的方法就是将行缓存连接成菊花链式,即将前一个行缓存的输出接入下一个行缓存的输入,如图4所示。行缓存Linebuffer Module类似于一个同步FIFO,但是因为COLOR_DEPTH关系,FIFO的数据位宽不一定是8的整数位。因此,我们首先完成一个同步FIFO Module的设计,然后通过例化这个同步FIFO Module来设计行缓存Linebuffer Module。尽管FIFO这种IP都是已经有设计好的,但是为了理解设计细节,我用编译约束,来使得设计的FIFO Module中的存储单元采用BRAM而不是使用寄存器(FF)。
1.2.1 同步FIFO Module的设计

图 5
图5所示为同步FIFO Module的电路结构引脚图。其输入信号分别为clk(同步时钟信号),arstn(异步复位信号-低电平有效),data_in(输入数据),wr_req(写请求-高有效),rd_req(读请求-高有效),data_out(输出数据),usedw(FIFO中被写入了多少个数据的计数值),empty(FIFO空标志-高为空),full(FIFO满标志-高为满)。其具体实现代码如下所示,设计思路是采用了循环数组的设计思想,循环数组使用空递增的方式。
module SynFifo #
(
parameter DATA_WIDTH = 8,
parameter FIFO_DEPTH = 256
)
(clk,arstn,data_in,wrreq,rdreq,data_out,usedw,empty,full);
function integer clogb2 (input integer bit_depth);
begin
for(clogb2=0;bit_depth>0;clogb2=clogb2+1)
bit_depth=bit_depth>>1;
end
endfunction
localparam clog2_FIFO_DEPTH=clogb2(FIFO_DEPTH-1);
input clk;
input arstn;
input [DATA_WIDTH-1:0]data_in;
input wrreq;
input rdreq;
output [DATA_WIDTH-1:0]data_out;
output reg [clog2_FIFO_DEPTH:0]usedw;
output empty;
output full;
(* ram_style = "bram" *) reg [DATA_WIDTH-1:0]mem[FIFO_DEPTH-1:0];
reg [clog2_FIFO_DEPTH-1:0]w_pointer;
reg w_phase;
reg [clog2_FIFO_DEPTH-1:0]r_pointer;
reg r_phase;
wire wr_en;
wire rd_en;
assign wr_en = wrreq & (~full);
assign rd_en = rdreq & (~empty);
/* Write Data */
always@(posedge clk or negedge arstn)
begin
if(~arstn)
begin
w_phase <= 1'b0;
w_pointer <= 0;
end
else
begin
if(wr_en)
begin
if(w_pointer == FIFO_DEPTH - 1'b1)
begin
w_pointer <= 'd0;
w_phase <= ~w_phase;
end
else
w_pointer<= w_pointer + 1'b1;
end
end
end
always@(posedge clk)
begin
if(wr_en)
mem[w_pointer]<=data_in;
end
/* read data */
always@(posedge clk or negedge arstn)
begin
if(~arstn)
begin
r_pointer <= 0;
r_phase <= 1'b0;
end
else
begin
if(rd_en)
begin
if(r_pointer == FIFO_DEPTH - 1'b1)
begin
r_pointer <= 'd0;
r_phase <= ~r_phase;
end
else
r_pointer <= r_pointer + 1'b1;
end
end
end
assign data_out = mem[r_pointer];
wire empty=(w_pointer==r_pointer)&&(w_phase^~r_phase);
wire full=(w_pointer==r_pointer)&&(w_phase^r_phase);
always@(*)
begin
if(w_phase == r_phase)
begin
usedw = w_pointer - r_pointer;
end
else
begin
usedw = FIFO_DEPTH - r_pointer + w_pointer;
end
end
endmodule1.2.2 行缓存Linebuffer Module的设计
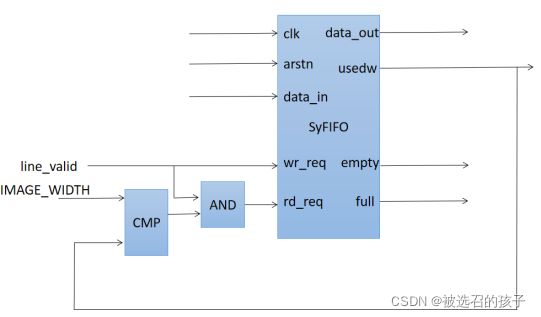
图 6
图6所示是一个行缓存LineBuffer Module的电路结构图,图中只画出了一个同步FIFO,因为在设计时,我将FIFO的大小固定为8位位宽,因此,如果LineBuffer的pixel_data的位宽为14位,则需要进行(14+8-1)/8 = 2的向上取整运算,计算实现一个LineBuffer所需要的FIFO的个数,然后这些FIFO并连,即以8 bit位为基本总线位宽,将输入的pixel_data的数据进行分割。这里要注意行缓存模块的读有效条件,很自然的,我们可以设置为一行数据的IMAGE_WIDTH的大小,当缓存了一行数据大小后,就可以读出数据了。依据这种思想设计的出的行缓存LineBuffer的具体代码如下所示。
module LineBuffer #
(
parameter DATA_WIDTH = 14,
parameter BUFFER_DEPTH = 256,
parameter FIFO_WIDTH = 8
)
(clk,arstn,data_in,wrreq,data_out,rdreq,usedw,empty,full);
function integer clogb2(input integer bit_depth);
begin
for(clogb2 = 0;bit_depth > 0;clogb2 = clogb2 + 1)
bit_depth = bit_depth >> 1;
end
endfunction
localparam clog2_BUFFER_DEPTH = clogb2(BUFFER_DEPTH - 1);
localparam clog2_FIFO_WIDTH = clogb2(FIFO_WIDTH - 1);
localparam FIFO_NUM = ((DATA_WIDTH + FIFO_WIDTH -1)>>clog2_FIFO_WIDTH);
input clk;
input arstn;
input [DATA_WIDTH-1:0]data_in;
output [DATA_WIDTH-1:0]data_out;
input wrreq;
input rdreq;
output [clog2_BUFFER_DEPTH:0]usedw;
output empty;
output full;
wire [FIFO_WIDTH-1:0]din_temp[FIFO_NUM-1:0];
wire [FIFO_WIDTH*FIFO_NUM-1:0]dout_temp;
assign data_out[DATA_WIDTH-1:0] = dout_temp[DATA_WIDTH-1:0];
/* Generate the first FIFO */
assign din_temp[0] = data_in[FIFO_WIDTH-1:0];
SynFifo #
(
.DATA_WIDTH(FIFO_WIDTH),
.FIFO_DEPTH(BUFFER_DEPTH)
)Fifo_inst_0(
.clk(clk),
.arstn(arstn),
.data_in(din_temp[0]),
.wrreq(wrreq),
.rdreq(rdreq),
.data_out(dout_temp[FIFO_WIDTH-1:0]),
.usedw(usedw),
.empty(empty),
.full(full)
);
generate
begin:fifo_generate
genvar i;
if(FIFO_NUM > 1)
begin
for(i=1;i1.3 行列对齐LineAlign Module
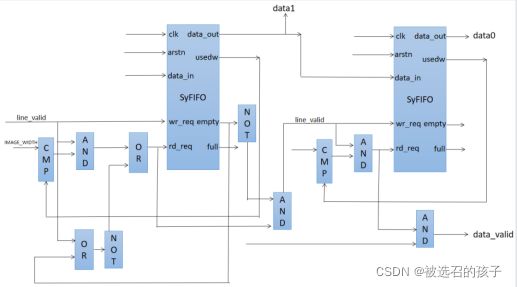
图 7
现在,我们完成了LineBuffer Module的设计,这是我们只需要按照图4所示的菊花链式结构进行设计行列对齐LineAlign模块,行列对齐LineAlign模块的电路结构图如图7所示。图7所示是实现的两行对齐的结构图,将两个行缓存模块进行了菊花链式的连接。对于行列对齐模块,我们需要注意的是首行的读出条件,第一个条件是:当LineBuffer缓存好一行后,后续输入的数据是有效图像像素数据,那么是可以读出的;第二个条件是:之前提到过,图像滤波操作时,会出现图像右边界和下边界出现越界的情况,如图8所示,用一个半径为radiu的core去滤波大小为IH*IW大小图像,会有一个大小为radius的boarder,图8显示了上,下,左,右四个边界,因为行列对齐中的数据有效信号的作用,解决了上边界和左边界的问题,而对于下边界,则是当最后一行数据全部滤波完成后,就达到了滤波运算的下边界。这就是在图7结构中首行读出的第二个条件:当首个LineBuffer中有数据(即FIFO不空)且后续图像数据无效时读出,一直到将首个LineBuffer中的数据全部读出为止。
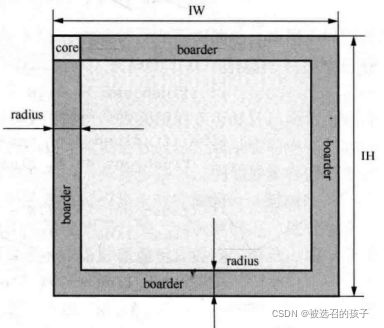
图 8
如下所示为行列对齐LineAlign模块的具体实现代码。
module LineAlign #(
parameter DATA_WIDTH = 14,
parameter BUFFER_DEPTH = 256,
parameter FIFO_WIDTH = 8,
parameter LINE_NUM = 3,
parameter IMAGE_WIDTH = 128
)(clk,arstn,data_in,datain_valid,data_out,dataout_valid);
function integer clogb2(input integer bit_depth);
begin
for(clogb2 = 0;bit_depth >0; clogb2 = clogb2+1)
bit_depth = bit_depth >> 1;
end
endfunction
localparam DATAOUT_WIDTH = DATA_WIDTH*LINE_NUM;
localparam clog2_BUFFER_DEPTH = clogb2(BUFFER_DEPTH - 1);
input clk;
input arstn;
input [DATA_WIDTH - 1:0]data_in;
input datain_valid;
output [DATAOUT_WIDTH-1:0]data_out;
output dataout_valid;
wire [DATA_WIDTH-1:0]temp_dout[LINE_NUM-1:0];
wire [clog2_BUFFER_DEPTH:0]temp_usedw[LINE_NUM-1:0];
wire [LINE_NUM-1:0]temp_rd_req;
wire [LINE_NUM-1:0]temp_wr_req;
wire [LINE_NUM-1:0]temp_empty;
wire [LINE_NUM-1:0]temp_valid;
wire [LINE_NUM-2:0]temp_dout_valid;
wire temp_rd_req0;
wire temp_rd_req1;
/* The First Line Buffer */
assign data_out[DATA_WIDTH-1:0] = temp_dout[0];
LineBuffer #(
.DATA_WIDTH(DATA_WIDTH),
.BUFFER_DEPTH(BUFFER_DEPTH),
.FIFO_WIDTH(FIFO_WIDTH)
)Inst_LineBuffer_first(
.clk(clk),
.arstn(arstn),
.data_in(data_in),
.wrreq(temp_wr_req[0]),
.data_out(temp_dout[0]),
.rdreq(temp_rd_req[0]),
.usedw(temp_usedw[0]),
.empty(temp_empty[0]),
.full()
);
assign temp_rd_req0 = temp_valid[0] & temp_wr_req[0];
assign temp_rd_req1 = ~(datain_valid | temp_empty[0]);
assign temp_wr_req[0] = datain_valid;
assign temp_valid[0] = (IMAGE_WIDTH == temp_usedw[0]) ? 1:0;
assign temp_rd_req[0] = temp_rd_req0 | temp_rd_req1;
/* generate Other Line Buffer */
generate
begin
genvar i;
for(i=1;i图9所示为进行3行行列对齐LineAlign模块的仿真波形图。测试输入的图像IMAGE_WIDTH=240,每行数据都是从1到240,因此图9所示的3行对齐输出数据波形数据正确。

图 9