Paper Information
Title:《Improved Deep Embedded Clustering with Local Structure Preservation》
Authors:Xifeng Guo, Long Gao, Xinwang Liu, Jianping Yin
Sources:2017, IJCAI
Other:69 Citations, 71 References
Paper:Download
Code:Download
Abstract
本文解决的问题:先前根据不同情况设计聚类损失函数的工作可能破坏了特征空间,产生无意义的特征表示从而降低了聚类性能。
本文解决的思路:
-
- 使用聚类损失函数指导代表特征空间的 points 分布;
- 采用 under-complete autoencoder 维护数据的局部结构;
- 联合 聚类损失 和 AE 损失 来训练。
1 Introduction
聚类任务的划时代杰作:
-
- 1967 MacQueen 的 k-means ;
- 2006 Bishop 的 gaussian mixture model ;
- 2007 Von Luxburg 的 spectral clustering ;
由于输入数据的维度很大,通常会有很多不可靠的特征数据,这严重影响力聚类效果。所以一个被普遍接受的想法是:将高维空间的输入数据映射到低维空间,然后再进行聚类。
Q1:为什么传统降维方法如 PCA 、LDA等学习表示的能力有限?
A1:知道的可以再评论区抒发见解。
由于深度学习的发展,DNN model 能很好的实现 feature transformation ,学到有用的表示。
然后介绍 DEC ,可以参考《论文解读(DEC)Unsupervised Deep Embedding for Clustering Analysis》。
本文贡献:
-
- 提出了一种深度聚类算法,可以联合进行聚类和学习具有局部结构保存的代表性特征。
- 通过实证证明了局部结构保存在深度聚类中的重要性。
- IDEC 在很大的优势上优于最新的对手。
2 Related Work
2.1 Deep Clustering
目前阶段的聚类算法:
-
- Two-stage work that applies clustering after having learned a representation;[ 该方法基于良好的表示 ]
- Approaches that jointly optimize the feature learning and clustering;[ 特征学习的时候同时进行聚类 ]
对于 1 举例:
-
- Tian et al., 2014 :先使用 AE 学到低维有用表示,然后使用 k-means 进行聚类;
- Chen, 2015 :层级训练深度信念网络(DBN),然后将 non-parametric maximum-margin 聚类应用于学习到的中间表示;
- Peng et al., 2016 : 使用稀疏自编码器,同时自适应学习局部和全局结构信息的表示,再采用传统的聚类算法进行聚类;
对于 2 举例:
-
- Yang et al., 2016 :proposes a recurrent framework in deep representations and image clusters, which integrates two processes into a single model with a unified weighted triplet loss and optimizes it end-to-end.
- Xie et al.,2016 :DEC 通过深度神经网络学习从观测空间到低维潜在空间的映射,可以同时获得特征表示和聚类分配;
2.2 Autoencoder
AE 有两个部分:
-
- Encoder:编码器函数为 $z=f_{W}(x)$ ,输出表示 $z$ 。
-
- Decoder:解码器函数为 $x^{\prime}=g_{W^{\prime}}(z) $,根据表示 $z$ 重构原始输入 $x$ 。
$x^{\prime}=g_{W^{\prime}}(z)$
两种常见的自编码器:
-
- 欠完备自编码器( Under-complete autoencoder):$z$ 的维度要小于原始输入的维度。
- 去噪自编码器( Denoising autoencoder):$L=\left\|x-g_{W^{\prime}}\left(f_{W}(\tilde{x})\right)\right\|_{2}^{2} \quad \quad \quad (1)$
Reference:
-
- 欠完备自编码器:从自编码器获得有用特征的一种方法是限制 $h$ 的维度比 $x$ 小,这种编码维度小于输入维度的自编码器称为欠完备(undercomplete)自编码器。学习欠完备的表示将强制自编码器捕捉训练数据中最显著的特征。
- 去噪自编码器(denoising autoencoder,DAE)是一类接受损坏数据作为输入,并训练来预测原始未被损坏数据作为输入的自编码器。
2.3 Deep Embedded Clustering
深度嵌入式聚类(DEC) [Xieetal.,2016] 首先对自动编码器进行预训练,然后删除解码器。其余的编码器通过优化以下目标进行微调:
$L=K L(P \| Q)=\sum\limits_{i} \sum\limits_{j} p_{i j} \log \frac{p_{i j}}{q_{i j}}\quad \quad \quad (2)$
其中:
-
- $q_{i j}$ 是表示 $z_{i}$ 和聚类中心 $\mu_{j}$ 之间的相似度。定义为:
${\large q_{i j}=\frac{\left(1+\left\|z_{i}-\mu_{j}\right\|^{2}\right)^{-1}}{\sum_{j}\left(1+\left\|z_{i}-\mu_{j}\right\|^{2}\right)^{-1}}}\quad \quad \quad (3) $
-
- Eq.2 中的 $p_{ij}$ 是目标分布,定义为:
${\large p_{i j}=\frac{q_{i j}^{2} / \sum_{i} q_{i j}}{\sum_{j}\left(q_{i j}^{2} / \sum_{i} q_{i j}\right)}}\quad \quad\quad(4) $
DEC算法:
-
- 首先,对原始数据集 $X$ ,跑一遍 AE ,获得 Encoder 生成的表示 $z_{i}=f_{W}\left(x_{i}\right)$ ;
- 其次,基于 ${z_i}$ ,使用传统的 $k-means$ ,获得若干聚类中心 ${\mu _j}$;
- 然后,根据 Eq.3 和 Eq.4 计算得的 $q_{ij}$ 和 $p_{ij}$ 去计算 Eq.2 中的 $L$;
- 最后,根据 $q_{ij}$ 进行 $label$ 分配。
3 Improved Deep Embedded Clustering
- Consider a dataset $X$ with $n$ samples and each sample $x_{i} \in \mathbb{R}^{d}$ where $d$ is the dimension.
- The number of clusters $K$ is a priori knowledge and the $j$ th cluster center is represented by $\mu_{j} \in \mathbb{R}^{d}$ . Let the value of $s_{i} \in\{1,2, \ldots, K\}$ represent the cluster index assigned to sample $x_{i}$ .
- Define nonlinear mapping $f_{W}: x_{i} \rightarrow z_{i}$ and $g_{W^{\prime}}: z_{i} \rightarrow x_{i}^{\prime}$ where $z_{i}$ is the embedded point of $x_{i}$ in the low dimensional feature space and $x_{i}^{\prime}$ is the reconstructed sample for $x_{i}$ .
目标:寻找最佳的 $f_{W}$ 来获得更好的 $\left\{z_{i}\right\}_{i=1}^{n}$ ,以便更好的做聚类任务。
本文 model 有两个必不可少的部分:
-
- Autoencoder;
- clustering loss;
模型架构如 Fig.1. 所示:

目标函数定义为:
$L=L_{r}+\gamma L_{c}\quad\quad \quad (6)$
其中:
-
- $L_{r} $ 是重构损失;
- $L_{c}$ 是聚类损失;
- $ \gamma>0$ 是控制 the degree of distorting embedded space 的系数,当 $\gamma=1$ 或 $L_{r} \equiv 0$ 即是DEC的目标函数;
Q2:$ \gamma$ 这个系数为什么这么加,看过很多文章这么写,但是不知道为什么一定加这?
A2:知道的可以再评论区抒发见解。
3.1 Clustering loss and Initialization
回顾 DEC 聚类损失函数(参考前面提到的 Eq.2. 、Eq.3.、Eq.4.):
$L_{c}=K L(P \| Q)=\sum\limits_{i} \sum\limits _{j} p_{i j} \log \frac{p_{i j}}{q_{i j}}\quad\quad \quad (7)$
通过 DEC model 给的启发:
-
- 预训练:使用堆叠降噪自编码器(stacked denoising autoencoder)。
- 然后基于预训练生成的有效表示 $\left\{z_{i}=f_{W}\left(x_{i}\right)\right\}_{i=1}^{n}$ 使用 $k-means $ 获得聚类中心 $\left\{\mu_{j}\right\}_{j=1}^{K}$ 。
3.2 Local structure preservation
由于 DEC 直接丢弃 Decoder 并通过聚类损失 $L_{c}$ 直接微调编码器,可能造成嵌入空间的扭曲。[ 说白了就是研究 Decoder 的影响 ]
所以本文提出保持解码器不变,直接将聚类损失加到嵌入空间中去。
本文将堆叠降噪自编码器替换为欠完备自编码器 [ 理由是聚类需要干净的数据,个人感觉就是那个实验效果好选那个 ],重构损失 [ Mean Squared Error ] :
$L_{r}=\sum\limits _{i=1}^{n}\left\|x_{i}-g_{W^{\prime}}\left(z_{i}\right)\right\|_{2}^{2}\quad \quad \quad (8)$
这里建议 $ \gamma$ 最好小于 $1$ ,这将在在 4.3 节通过实验证明。
3.3 Optimization
Eq.6 采用小批量随机梯度下降法优化,有三个参数需要优化,分别是:
-
- 自编码器的权重参数
- 聚类中心 $u_j$
- 目标分布 $P$
首先阐述:更新自编码器权重参数和聚类中心
固定目标分布 $P$ ,优化
$\frac{\partial L_{c}}{\partial z_{i}}=2 \sum\limits _{j=1}^{K}\left(1+\left\|z_{i}-\mu_{j}\right\|^{2}\right)^{-1}\left(p_{i j}-q_{i j}\right)\left(z_{i}-\mu_{j}\right)\quad\quad\quad (9)$
$\frac{\partial L_{c}}{\partial \mu_{j}}=2 \sum\limits _{i=1}^{n}\left(1+\left\|z_{i}-\mu_{j}\right\|^{2}\right)^{-1}\left(q_{i j}-p_{i j}\right)\left(z_{i}-\mu_{j}\right)\quad\quad\quad (10)$
-
- 聚类中心更新公式:
-
- 解码器权重参数更新公式:
- 编码器权重更新公式为:
${\large W=W-\frac{\lambda}{m} \sum\limits _{i=1}^{m}\left(\frac{\partial L_{r}}{\partial W}+\gamma \frac{\partial L_{c}}{\partial W}\right)}\quad \quad \quad (13)$ $
由于目标分布 $P$ 是基于 soft label [ $p_{ij}$ 依托于 $q_{ij}$ ] ,频繁更新容易造成不稳定,所以 $P$ 的更新并没有在每个 iter 中更新,而是在每个 batch 中更新。但是实际上,本文是在 每 T iterations 进行更新。label 分配方法如下:
这里当连续两次分配的百分比小于 $\delta$ 将停止训练。

4 Experiments
4.1 DataSets
- MNIST [图像数据集]:70000张手写数字图
- USPS [图像数据集]:9298张灰度手写数字图
- REUTERS-10K [文本数据集]:810000篇有标签新闻报道,这边采样10000篇报道。

4.2 Results
实验1:实验结果如 Table 2 所示:

结论:
-
- 深度聚类方法: AE+k-means, DEC和 IDEC 表现明显优于传统方法,但这三种方法之间仍存在很大的差距。
- AE+k-means 和 DEC 相比证明了聚类损失的指导意义,DEC 和 IDEC 相比证明了自编码器可以提高聚类性能。
实验2:DEC 和 IDEC 对比实验:

结论:
-
- IDEC 聚类精度高于 DEC ;
- IDEC 收敛慢于 DEC ;
- IDEC 聚类损失高于 DEC ;
- 最后几次迭代重构损失和初始迭代损失相差不大;
实验3:DEC 和 IDEC 可视化对比实验:

上下行分别是 IDEC 和 DEC 的 t-SNE 可视化结果。
实验4:DEC 和 IDEC 参数 $\lambda$ 和 $ \gamma$ 的对比实验:
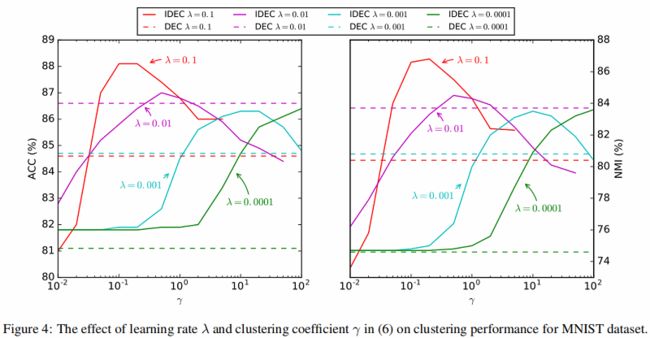
结论:
-
- IDEC在最佳学习率 $\lambda=0.1$ 的情况下优于 DEC 在最佳学习率 $\lambda=0.01$ 当 $ \gamma \in [0.05,1.0]$ ;
- 对于较大的 $\lambda$ 需要搭配较小的 $\lambda$ ;
5 Conclusion
本文提出了改进的深度嵌入式聚类(IDEC)算法,该算法联合进行了聚类,并学习了适合于聚类的嵌入式特征,并保留了数据生成分布的局部结构。IDEC通过优化基于KL散度的聚类损失来操纵特征空间来散射数据。它通过合并一个自动编码器来维护局部结构。实验实验表明,结构保存对深度聚类算法至关重要,有利于聚类性能。未来的工作包括:在IDEC框架中添加更多的先验知识(如稀疏性),并为图像数据集合并卷积层。
Last modify :2022-02-13 17:54:31
『总结不易,加个关注呗!』
