用scikit-learn估计器分类
2.1、scikit-learn估计器
主要用于分类任务,主要包括以下两个参数:
fit():训练算法,设置内部参数。该函数接受训练集及其类别的两个参数。
predict():参数为测试集。预测测试集类别,并返回一个包含测试集各条数据类别的数组。
2.1.1 近邻算法
近邻算法可能是标准数据挖掘算法中最为直观的一种。为了对新个体进行分类,查找训练集,找到与新个体最相似的那些个体,查看这些个体大多属于哪个类别,就把新个体分到哪个类别。
2.1.2 距离度量
欧式距离:两个点之间的直线距离,为两个特征向量长度平方和的平方根。
曼哈顿距离:两个特征在标准坐标系中绝对轴距之和。
余弦距离:特征向量夹脚的余弦值。
2.2 加载数据
# -*- coding: UTF-8
import numpy as np
import csv
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
# 文件数据路径,数据从http://archive.ics.uci.edu/ml/datasets/Ionosphere下载
data_filename = r"E:\PycharmProjects\WebCrawler\ionosphere.data"
# 数据集为351行34列,最后一列的值表示数据好坏,创建零元数组
X = np.zeros((351,34),dtype='float')
Y = np.zeros((351,),dtype='bool')
with open(data_filename,'r') as input_file:
reader = csv.reader(input_file)
for i ,row in enumerate(reader):
data = [float(datum) for datum in row[:-1]]
X[i] = data
Y[i] = row[-1]=='g'
# 创建训练集和测试集
X_train,X_test,Y_train,Y_test = train_test_split(X,Y,random_state=14)
# 初始化一个K近邻分类器的实例
estimator = KNeighborsClassifier()
estimator.fit(X_train,Y_train)
Y_predicted = estimator.predict(X_test)
accuracy = np.mean(Y_test == Y_predicted)*100
print(accuracy)正确率为86.4%。
2.3 交叉检验
算法描述如下:
(1)将整个大数据集分为几个部分
(2)对于每一部分执行以下操作:①将其中一部分作为当前测试集②用剩余部分训练算法③在当前测试集上测试算法
(3)记录每次得分及平均得分
(4)在上述过程中,每条数据只能在测试集中出现一次,以减少(但不能完全规避)运气成分
scikit-learn提供了几种交叉检验方法。有个辅助函数实现了上述交叉检验步骤:
from sklearn.model_selection import cross_val_score将完整的数据集和类别值传递给它
scores = cross_val_score(estimator,X,Y,scoring='accuracy')
average_accuracy = np.mean(scores)*100
print(average_accuracy)结果为82.3%。
2.4 设置参数
# -*- coding: UTF-8
import numpy as np
import csv
from sklearn.model_selection import train_test_split
from sklearn.model_selection import cross_val_score
from sklearn.neighbors import KNeighborsClassifier
from matplotlib import pyplot as plt
# 文件数据路径,数据从http://archive.ics.uci.edu/ml/datasets/Ionosphere下载
data_filename = r"E:\PycharmProjects\WebCrawler\ionosphere.data"
# 数据集为351行34列,最后一列的值表示数据好坏,创建零元数组
X = np.zeros((351,34),dtype='float')
Y = np.zeros((351,),dtype='bool')
with open(data_filename,'r') as input_file:
reader = csv.reader(input_file)
for i ,row in enumerate(reader):
data = [float(datum) for datum in row[:-1]]
X[i] = data
Y[i] = row[-1]=='g'
avg_scores = []
all_scores = []
parameter_values = list(range(1,21))
for n_neighbors in parameter_values:
estimator = KNeighborsClassifier(n_neighbors=n_neighbors)
scores = cross_val_score(estimator,X,Y,scoring='accuracy')
avg_scores.append(np.mean(scores))
all_scores.append(scores)
plt.plot(parameter_values,avg_scores,'-o')
plt.show()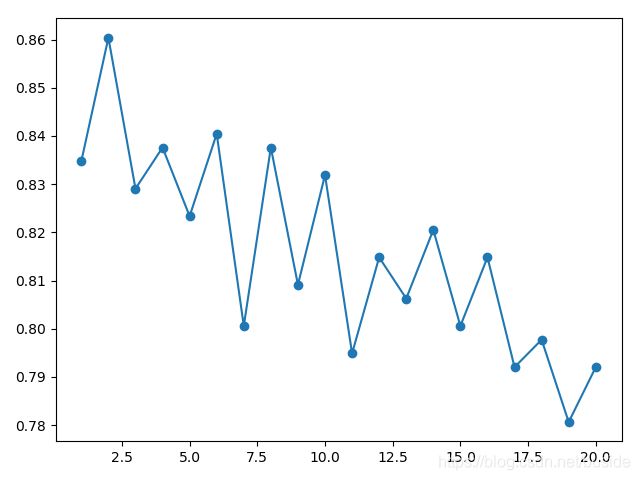
从结果可以看到,虽然有很多曲折变化,但整体趋势是随着近邻数的增加,正确率下降。