机器学习从零开始-Kaggle数据用PurePython实战
数据集链接
链接:https://pan.baidu.com/s/1hK-eTBgkLL7ZQuWCKqyvNA
提取码:fz74
线性回归
纯Python构建的经典算法实战Kaggle真实项目:红酒质量分析预测
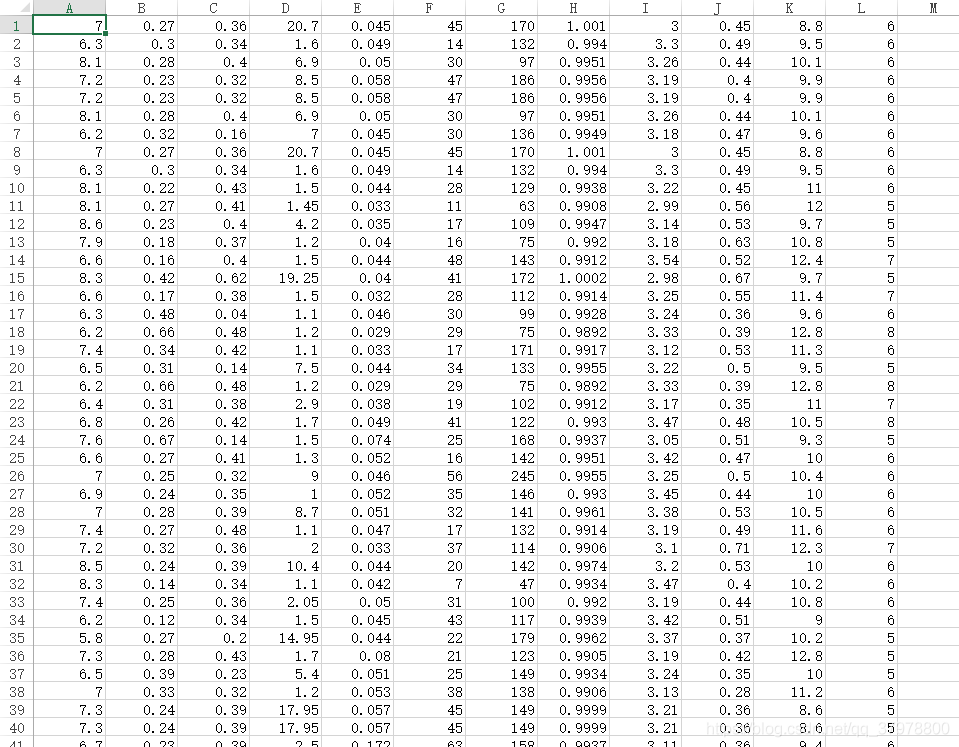
# 1.load csv
# 2.convert string to float
# 3.normalization
# 4.cross validation
# 5.evaluate our algo(RMSE)
# 1 . Import standard Lib
from csv import reader
from math import sqrt
from random import randrange
from random import seed
# 2. Load our csv file
def csv_loader(filename):
dataset = list()
with open(filename, 'r') as file:
csv_reader = reader(file)
for row in csv_reader:
if not row:
continue
dataset.append(row)
return dataset
# dataset_list = csv_loader('winequality-white.csv')
#
# print(dataset_list)
# 3.Convert our datatype
def string_to_float_converter(dataset, column):
for row in dataset:
row[column] = float(row[column].strip())
# 4.find the min and max of our dataset
def find_the_min_and_max_of_our_dataset(dateset):
min_max_list = list()
for i in range(len(dateset[0])):
col_value = [row[i] for row in dateset]
max_value = max(col_value)
min_value = min(col_value)
min_max_list.append([min_value, max_value])
return min_max_list
# 5.normalization our data
def normalization(dataset, min_max_list):
for row in dataset:
for i in range(len(row)):
row[i] = (row[i] - min_max_list[i][0]) / (min_max_list[i][1] - min_max_list[i][0])
# 6.splitting our data
def k_fold_cross_validation_split(dataset, n_folds):
split_dataset = list()
copy_dataset = list(dataset)
every_fold_size = int(len(dataset) / n_folds)
for i in range(n_folds):
fold = list()
while len(fold) < every_fold_size:
index = randrange(len(copy_dataset))
fold.append(copy_dataset.pop(index))
split_dataset.append(fold)
return split_dataset
# 7.using root mean squared error method to calculate our model
def rmse_method(actual_data, predicted_data):
sum_of_error = 0.0
for i in range(len(actual_data)):
predicted_error = predicted_data[i] - actual_data[i]
sum_of_error += (predicted_error ** 2)
mean_error = sum_of_error / float(len(actual_data))
rmse = sqrt(mean_error)
return rmse
# 8. how good is our algo by using cross validation
def how_good_is_our_algo(dataset, algo, n_folds, *args):
folds = k_fold_cross_validation_split(dataset, n_folds)
scores = list()
for fold in folds:
train_set = list(folds)
train_set.remove(fold)
train_set = sum(train_set, [])
test_set = list()
for row in fold:
row_copy = list(row)
test_set.append(row_copy)
row_copy[-1] = None
predicted = algo(train_set, test_set, *args)
actual = [row[-1] for row in fold]
rmse = rmse_method(actual, predicted)
scores.append(rmse)
return scores
# 9.make prediction
def predict(row, coefficients):
yhat = coefficients[0]
for i in range(len(row) - 1):
yhat += coefficients[i + 1] * row[i]
return yhat
# 10. using stochastic gradient descent method to calculate the coefficient
def sgd_method_to_calculate_coefficient(training_data, learning_rate, n_epoch):
coefficients_list = [0.0 for i in range(len(training_data[0]))]
for epoch in range(n_epoch):
for row in training_data:
yhat = predict(row, coefficients_list)
# typo
error = yhat - row[-1]
coefficients_list[0] = coefficients_list[0] - learning_rate * error
for i in range(len(row) - 1):
coefficients_list[i + 1] = coefficients_list[i + 1] - learning_rate * error * row[i]
print(learning_rate, n_epoch, error)
return coefficients_list
# 11. using linear regression algo
def using_sgd_method_to_calculate_linear_regression(training_data, testing_data, learning_rate, n_epoch):
predictions = list()
coefficients_list = sgd_method_to_calculate_coefficient(training_data, learning_rate, n_epoch)
for row in testing_data:
yhat = predict(row, coefficients_list)
predictions.append(yhat)
return (predictions)
# 12. Using our real wine quality data
seed(1)
wine_quality_data_name = 'winequality-white.csv'
dataset = csv_loader(wine_quality_data_name)
for i in range(len(dataset[0])):
string_to_float_converter(dataset, i)
# 13.Normalization
min_and_max = find_the_min_and_max_of_our_dataset(dataset)
normalization(dataset, min_and_max)
# 14.How good is our algo
n_folds = 5
learning_rate = 0.1
n_epoch = 50
algo_score = how_good_is_our_algo(dataset, using_sgd_method_to_calculate_linear_regression, n_folds, learning_rate,
n_epoch)
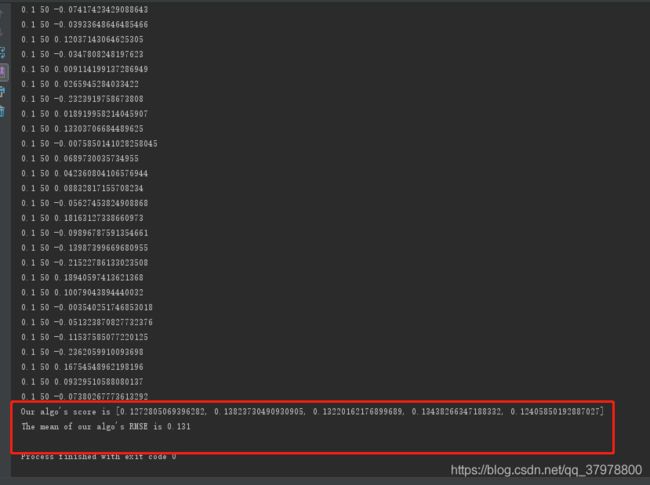
print("Our algo's score is %s" % algo_score)
print("The mean of our algo's RMSE is %.3f" % (sum(algo_score) / float(len(algo_score))))
纯Python构建的经典算法实战Kaggle真实项目:车险赔付建模预测

from csv import reader
from math import sqrt
from random import randrange, seed
# 1.Load our csv data
# 1.读取csv文件
def load_csv(data_file):
data_set = list()
with open(data_file, 'r') as file:
csv_reader = reader(file)
for row in csv_reader:
if not row:
continue
data_set.append(row)
return data_set
# print(load_csv('insurance.csv'))
# 发现数据均为字符串,我们接下来对字符串进行转化
# 最终要转换成float
# 2.数据类型转换
def string_converter(data_set, column):
for row in data_set:
"""
Return a copy of the string with leading and trailing whitespace removed.
因为很可能出现这样的数据" 99.9 "
If chars is given and not None, remove characters in chars instead.
"""
row[column] = float(row[column].strip())
# 模型预测的准确性基本判断方法RMSE(衡量模型的标尺)
# 3.root mean squared error
def calculate_RMSE(actual_data, predicted_data):
sum_error = 0.0
for i in range(len(actual_data)):
predicted_error = predicted_data[i] - actual_data[i]
sum_error += (predicted_error ** 2)
mean_error = sum_error / float(len((actual_data)))
return sqrt(mean_error)
# 4.测试集、训练集切分train/test split
def train_test_split(data_set, split):
train = list()
train_size = split * len(data_set)
data_set_copy = list(data_set)
while len(train) < train_size:
index = randrange(len(data_set_copy))
train.append(data_set_copy.pop(index))
return train, data_set_copy
# 5.模型到底如何(train/test split)通过在训练集,测试集切分后,用RMSE进行衡量模型好坏
def how_good_is_our_algo(data_set, algo, split, *args):
train, test = train_test_split(data_set, split)
test_set = list()
for row in test:
row_copy = list(row)
row_copy[-1] = None
test_set.append(row_copy)
# 伪代码思想,先用algo统一代替具体算法
predicted = algo(train, test_set, *args)
actual = [row[-1] for row in test]
rmse = calculate_RMSE(actual, predicted)
return rmse
# 6.为了实现简单线形回归的小玩意儿
def mean(values):
return sum(values) / float(len(values))
def covariance(x, the_mean_of_x, y, the_mean_of_y):
covar = 0.0
for i in range(len(x)):
covar += (x[i] - the_mean_of_x) * (y[i] - the_mean_of_y)
return covar
def variance(values, mean):
return sum([(x - mean) ** 2 for x in values])
def coefficients(data_set):
x = [row[0] for row in data_set]
y = [row[1] for row in data_set]
the_mean_of_x = mean(x)
the_mean_of_y = mean(y)
# y=b1*x+b0
b1 = covariance(x, the_mean_of_x, y, the_mean_of_y) / variance(x, the_mean_of_x)
b0 = the_mean_of_y - b1 * the_mean_of_x
return [b0, b1]
# 7.这里写简单线性回归的具体预测
def using_simple_linear_regression(train, test):
# 套路:先弄一个空的容器出来,然后逐一处理放入
predictions = list()
b0, b1 = coefficients(train)
for row in test:
y_hat = b1 * row[0] + b0
predictions.append(y_hat)
return predictions
# 8.带入真实数据
# 可调项,避免"魔法数字"
seed(4)
split = 0.6
# 读取数据
data_set = load_csv('F:/py/算法学习/X.Kaggle数据用PurePython实战/insurance.csv')
# 数据准备
for i in range(len(data_set[0])):
string_converter(data_set, i)
rmse = how_good_is_our_algo(data_set, using_simple_linear_regression, split)
print("RMSE of our algo is : %.3f" % (rmse))
![]()
逻辑回归
纯Python构建的经典算法实战Kaggle真实项目:糖尿病建模预测

from random import seed
from random import randrange
from csv import reader
from math import exp
# 1.Load our data using csv reader
def load_data_from_csv_file(file_name):
# 通过一个list容器去装数据
dataset = list()
with open(file_name, 'r') as file:
csv_reader = reader(file)
for row in csv_reader:
if not row:
continue
dataset.append(row)
return dataset
# print(load_data_from_csv_file('diabetes.csv'))
# 2. convert string in list of lists to float(data type change)
def change_string_to_float(dataset, column):
for row in dataset:
# 把前后对空格去掉
row[column] = float(row[column].strip())
# ret_data = load_data_from_csv_file('diabetes.csv')
#
# change_string_to_float(ret_data, 1)
#
# print(ret_data)
# 3.Find the min and max value of our data
def find_the_min_and_max_of_our_data(dataset):
min_max_list = list()
for i in range(len(dataset[0])):
values_in_every_column = [row[i] for row in dataset]
the_min_value = min(values_in_every_column)
the_max_value = max(values_in_every_column)
min_max_list.append([the_min_value, the_max_value])
return min_max_list
# 4.rescale our data so it fits to range 0 ~ 1
def rescale_our_data(dataset, min_max_list):
for row in dataset:
for i in range(len(row)):
row[i] = (row[i] - min_max_list[i][0]) / (min_max_list[i][1] - min_max_list[i][0])
# 5.k fold train and test split
def k_fold_cross_validation(dataset, how_many_fold_do_you_want):
splited_dataset = list()
# 对原数据进行处理的时候,尽量不要改动源数据(可以通过创建copy的方式对copy数据进行处理)
copy_dataset = list(dataset)
how_big_is_every_fold = int(len(dataset) / how_many_fold_do_you_want)
# 创建一个空的盒子,然后逐一随机选取数据放入盒子中
for i in range(how_many_fold_do_you_want):
box_for_my_fold = list()
while len(box_for_my_fold) < how_big_is_every_fold:
some_random_index_in_the_fold = randrange(len(copy_dataset))
box_for_my_fold.append(copy_dataset.pop(some_random_index_in_the_fold))
splited_dataset.append(box_for_my_fold)
return splited_dataset
# 6.Calculate the accuracy of our model
def calculate_the_accuracy_of_our_model(actual_data, predicted_data):
counter_of_correct_prediction = 0
for i in range(len(actual_data)):
if actual_data[i] == predicted_data[i]:
counter_of_correct_prediction += 1
return counter_of_correct_prediction / float(len(actual_data)) * 100.0
# 7. how good is our algo ?
def how_good_is_our_algo(dataset, algo, how_many_fold_do_you_want, *args):
folds = k_fold_cross_validation(dataset, how_many_fold_do_you_want)
scores = list()
for fold in folds:
training_data_set = list(folds)
training_data_set.remove(fold)
training_data_set = sum(training_data_set, [])
testing_data_set = list()
# 保险操作,去除真实数据,避免影响模型的学习结果
for row in fold:
row_copy = list(row)
testing_data_set.append(row_copy)
row_copy[-1] = None
predicted = algo(training_data_set, testing_data_set, *args)
actual = [row[-1] for row in fold]
accuracy = calculate_the_accuracy_of_our_model(actual, predicted)
scores.append(accuracy)
return scores
# 8. make prediction by using the coef
def prediction(row, coefficients):
yhat = coefficients[0]
for i in range(len(row) - 1):
yhat += coefficients[i + 1] * row[i]
return 1 / (1.0 + exp(-yhat))
# 9. using stochastic gradient descent to estimate our coef of logistic regression
def estimate_coef_lr_using_sgd_method(training_data, learning_rate, how_many_epoch_do_you_want):
coef = [0.0 for i in range(len(training_data[0]))]
for epoch in range(how_many_epoch_do_you_want):
for row in training_data:
yhat = prediction(row, coef)
error = row[-1] - yhat
coef[0] = coef[0] + learning_rate * error * yhat * (1.0 - yhat)
for i in range(len(row) - 1):
coef[i + 1] = coef[i + 1] + learning_rate * error * yhat * (1.0 - yhat) * row[i]
return coef
# 10. Logistic Regression's prediction in a our func
def logistic_regression(training_data, testing_data, learning_rate, how_many_epoch_do_you_want):
predictions = list()
coef = estimate_coef_lr_using_sgd_method(training_data, learning_rate, how_many_epoch_do_you_want)
for row in testing_data:
yhat = prediction(row, coef)
yhat = round(yhat)
predictions.append(yhat)
return predictions
# Using Kaggle diabetes dataset to test our model
seed(1)
dataset = load_data_from_csv_file('diabetes.csv')
for i in range(len(dataset[0])):
change_string_to_float(dataset, i)
min_max_value = find_the_min_and_max_of_our_data(dataset)
# make data range form 0 to 1
rescale_our_data(dataset, min_max_value)
how_many_fold_do_you_want = 10
learning_rate = 0.1
how_many_epoch_do_you_want = 1000
scores = how_good_is_our_algo(dataset, logistic_regression, how_many_fold_do_you_want, learning_rate,
how_many_epoch_do_you_want)
print("The scores of our model are %s" % scores)
print("The average accuracy of our model is %.3f" % (sum(scores) / float(len(scores))))
![]()
感知器
纯Python构建的经典算法实战Kaggle真实项目:声纳探测+物体判断

# 1. import lib
from random import seed
from random import randrange
from csv import reader
# 2.write a csv/data reader
def read_csv(filename):
dataset = list()
with open(filename, 'r') as file:
csv_reader = reader(file)
for row in csv_reader:
if not row:
continue
dataset.append(row)
return dataset
# 3.change string datatype
def change_string_to_float(dataset, column):
for row in dataset:
row[column] = float(row[column].strip())
# filename = 'sonar.all-data.csv'
# dataset = read_csv(filename)
# for i in range(len(dataset[0]) - 1):
# change_string_to_float(dataset, i)
# print(dataset)
# 4.change string column(class) to int
# 重点关注,核心思想在于通过i进行每一列的数据类型转换(i)
def change_str_column_to_int(dataset, column):
class_value = [row[column] for row in dataset]
unique_value = set(class_value)
search_tool = dict()
for i, value in enumerate(unique_value):
search_tool[value] = i
for row in dataset:
row[column] = search_tool[row[column]]
return search_tool
# 5. using k_folds cross validation
def k_folds_cross_validation(dataset, n_folds):
dataset_split = list()
# 对数据进行操作的时候,最好不要损坏原数据
dataset_copy = list(dataset)
fold_size = int(len(dataset) / n_folds)
for i in range(n_folds):
fold = list()
while len(fold) < fold_size:
index = randrange(len(dataset_copy))
fold.append(dataset_copy.pop(index))
dataset_split.append(fold)
return dataset_split
# 6.calculate the accuracy of our model
def calculate_accuracy(actual, predicted):
correct = 0
for i in range(len(actual)):
if actual[i] == predicted[i]:
correct += 1
return correct / float(len(actual)) * 100.0
# 7. whether the algo is good or not ?
def whether_the_algo_is_good_or_not(dataset, algo, n_folds, *args):
folds = k_folds_cross_validation(dataset, n_folds)
scores = list()
for fold in folds:
train_set = list(folds)
train_set.remove(fold)
train_set = sum(train_set, [])
test_set = list()
for row in fold:
row_copy = list(row)
test_set.append(row_copy)
row_copy[-1] = None
predicted = algo(train_set, test_set, *args)
actual = [row[-1] for row in fold]
accuracy = calculate_accuracy(actual, predicted)
scores.append(accuracy)
return scores
# 8.make prediction
def predict(row, weights):
activation = weights[0]
for i in range(len(row) - 1):
activation += weights[i + 1] * row[i]
return 1.0 if activation >= 0.0 else 0
# 9.using sgd(stochastic gradient descent) method to estimate weights
def estimate_our_weight_using_sgd_method(training_data, learning_rate, n_epoch):
weights = [0.0 for i in range(len(training_data[0]))]
for epoch in range(n_epoch):
for row in training_data:
prediction = predict(row, weights)
error = row[-1] - prediction
weights[0] = weights[0] + learning_rate * error
for i in range(len(row) - 1):
weights[i + 1] = weights[i + 1] + learning_rate * error * row[i]
return weights
# 10. using sgd method to make perceptron algo's prediction
def perceptron(training_data, testing_data, learning_rate, n_epoch):
predictions = list()
weights = estimate_our_weight_using_sgd_method(training_data, learning_rate, n_epoch)
for row in testing_data:
prediction = predict(row, weights)
predictions.append(prediction)
return predictions
# 11.using real sonar dataset
seed(1)
filename = 'sonar.all-data.csv'
dataset = read_csv(filename)
for i in range(len(dataset[0]) - 1):
change_string_to_float(dataset, i)
change_str_column_to_int(dataset, len(dataset[0]) - 1)
n_folds = 3
learning_rate = 0.01
n_epoch = 500
scores = whether_the_algo_is_good_or_not(dataset, perceptron, n_folds, learning_rate, n_epoch)
print("The score of our model is : %s " % scores)
print("The average accuracy is : %3.f%% , The baseline is 50%%" % (sum(scores) / float(len(scores))))

决策树CART
纯Python构建的经典算法实战Kaggle真实项目:自动验钞真伪

# 1. 导入相关库
# http://archive.ics.uci.edu/ml/datasets/banknote+authentication
from random import seed
from random import randrange
from csv import reader
# 2.读取数据
def csv_loader(filename):
dataset = list()
with open(filename, 'r') as file:
csv_reader = reader(file)
for row in csv_reader:
if not row:
continue
dataset.append(row)
return dataset
# print(csv_loader('data_banknote_authentication.csv'))
# 3.数据类型转换
def str_to_float_converter(dataset, column):
for row in dataset:
row[column] = float(row[column].strip())
# 4. 交叉检验
def k_fold_cross_validation_and_split(dataset, n_folds):
dataset_split = list()
dataset_copy = list(dataset)
fold_size = int(len(dataset) / n_folds)
for i in range(n_folds):
fold = list()
while len(fold) < fold_size:
index = randrange(len(dataset_copy))
fold.append(dataset_copy.pop(index))
dataset_split.append(fold)
return dataset_split
# 5.计算模型的准确性
def calculate_the_accuracy(actual, predicted):
correct_num = 0
for i in range(len(actual)):
if actual[i] == predicted[i]:
correct_num += 1
return correct_num / float(len(actual)) * 100.0
# 6.通过应用k-fold交叉检验检验模型的准确性
def how_good_is_our_algo(dataset, algorithm, n_folds, *args):
folds = k_fold_cross_validation_and_split(dataset, n_folds)
scores = list()
for fold in folds:
train_set = list(folds)
train_set.remove(fold)
train_set = sum(train_set, [])
test_set = list()
for row in fold:
row_copy = list(row)
test_set.append(row_copy)
row_copy[-1] = None
predicted = algorithm(train_set, test_set, *args)
actual = [row[-1] for row in fold]
accuracy = calculate_the_accuracy(actual, predicted)
scores.append(accuracy)
return scores
# 7. 把数据切分成左边与右边(split the data to left and right)
def test_split(index, value, dataset):
left, right = list(), list()
for row in dataset:
if row[index] < value:
left.append(row)
else:
right.append(row)
return left, right
# 8.计算gini index
def gini_index(groups, classes):
# 计算有多少个实例(有多少个样本在split的)
n_instances = float(sum([len(group) for group in groups]))
# 计算每一组(group)的gini
gini = 0.0
for group in groups:
size = float(len(group))
# 避免size为0的情况
if size == 0:
continue
score = 0.0
for class_val in classes:
p = [row[-1] for row in group].count(class_val) / size
score += p * p
# 计算gini并做加权调整
gini += (1.0 - score) * (size / n_instances)
return gini
# 9.利用gini index算出最好的split
def get_split(dataset):
class_value = list(set(row[-1] for row in dataset))
posi_index, posi_value, posi_score, posi_groups = 888, 888, 888, None
for index in range(len(dataset[0]) - 1):
for row in dataset:
groups = test_split(index, row[index], dataset)
gini = gini_index(groups, class_value)
if gini < posi_score:
posi_index, posi_value, posi_score, posi_groups = index, row[index], gini, groups
return {'index': posi_index, 'value': posi_value, 'groups': posi_groups}
# 10.直接到决策树末端结束
def determine_the_terminal_node(group):
outcomes = [row[-1] for row in group]
return max(set(outcomes), key=outcomes.count)
# 11.去创建决策树
def split(node, max_depth, min_size, depth):
left, right = node['groups']
del (node['groups'])
# 查看是否已经没有切分了
if not left or not right:
node['left'] = node['right'] = determine_the_terminal_node(left + right)
return
# 查看是否目前的分类深度超过最大深度
if depth >= max_depth:
node['left'], node['right'] = determine_the_terminal_node(left), determine_the_terminal_node(right)
return
# 左边的分类
if len(left) <= min_size:
node['left'] = determine_the_terminal_node(left)
else:
node['left'] = get_split(left)
split(node['left'], max_depth, min_size, depth + 1)
# 右边的分类
if len(right) <= min_size:
node['right'] = determine_the_terminal_node(right)
else:
node['right'] = get_split(right)
split(node['right'], max_depth, min_size, depth + 1)
# 12.形成tree
def build_tree(train, max_depth, min_size):
root = get_split(train)
split(root, max_depth, min_size, 1)
return root
# 13.实现预测功能
def predict(node, row):
if row[node['index']] < node['value']:
if isinstance(node['left'], dict):
return predict(node['left'], row)
else:
return node['left']
else:
if isinstance(node['right'], dict):
return predict(node['right'], row)
else:
return node['right']
# 14.Classification And Regression Tree
def decision_tree(train, test, max_depth, min_size):
tree = build_tree(train, max_depth, min_size)
predictions = list()
for row in test:
prediction = predict(tree, row)
predictions.append(prediction)
return predictions
# 16.实际数据演练:数据读取与预处理
seed(1)
filename = 'F:/py/算法学习/X.Kaggle数据用PurePython实战/data_banknote_authentication.csv'
dataset = csv_loader(filename)
for i in range(len(dataset[0])):
str_to_float_converter(dataset, i)
# print(dataset)
n_folds = 10
max_depth = 10
min_size = 5
scores = how_good_is_our_algo(dataset, decision_tree, n_folds, max_depth, min_size)
print('Score is %s' % scores)
print('Average Accuracy is : %.3f%%' % (sum(scores) / float(len(scores))))
![]()
朴素贝叶斯
纯Python构建的经典算法实战Kaggle真实项目:经典项目鸢尾花分类

from csv import reader
from random import randrange
from math import sqrt
from math import exp
from math import pi
# csv reader helper function
def load_csv(filename):
dataset = list()
with open(filename, 'r') as file:
csv_reader = reader(file)
for row in csv_reader:
if not row:
continue
dataset.append(row)
return dataset
# dataset = load_csv('iris.csv')
# print(dataset)
def convert_str_to_float(dataset, column):
for row in dataset:
row[column] = float(row[column].strip())
def convert_str_to_int(dataset, column):
class_values = [row[column] for row in dataset]
unique_value = set(class_values)
look_up = dict()
for i, value in enumerate(unique_value):
look_up[value] = i
for row in dataset:
row[column] = look_up[row[column]]
return look_up
def n_fold_cross_validation_split(dataset, n_folds):
dataset_split = list()
dataset_copy = list(dataset)
fold_size = int(len(dataset) / n_folds)
for i in range(n_folds):
fold = list()
while len(fold) < fold_size:
index = randrange(len(dataset_copy))
fold.append(dataset_copy.pop(index))
dataset_split.append(fold)
return dataset_split
def calculate_our_model_accuracy(actual, predicted):
correct_count = 0
for i in range(len(actual)):
if actual[i] == predicted[i]:
correct_count += 1
return correct_count / float(len(actual)) * 100.0
def whether_our_model_is_good_or_not(dataset, algo, n_folds, *args):
folds = n_fold_cross_validation_split(dataset, n_folds)
scores = list()
for fold in folds:
train_set = list(folds)
train_set.remove(fold)
train_set = sum(train_set, [])
test_set = list()
for row in fold:
row_copy = list(row)
test_set.append(row_copy)
row_copy[-1] = None
predicted = algo(train_set, test_set, *args)
actual = [row[-1] for row in fold]
accuracy = calculate_our_model_accuracy(actual, predicted)
scores.append(accuracy)
return scores
def split_our_data_by_class(dataset):
splited = dict()
for i in range(len(dataset)):
vector = dataset[i]
class_value = vector[-1]
if (class_value not in splited):
splited[class_value] = list()
splited[class_value].append(vector)
return splited
def mean(a_list_of_numbers):
return sum(a_list_of_numbers) / float(len(a_list_of_numbers))
def stdev(a_list_of_numbers):
the_mean_of_a_list_numbers = mean(a_list_of_numbers)
variance = sum([(x - the_mean_of_a_list_numbers) ** 2 for x in a_list_of_numbers]) / float(
len(a_list_of_numbers) - 1)
return sqrt(variance)
def describe_our_data(dataset):
description = [(mean(column), stdev(column), len(column)) for column in zip(*dataset)]
del (description[-1])
return description
def describe_our_data_by_class(dataset):
data_split = split_our_data_by_class(dataset)
description = dict()
for class_value, rows in data_split.items():
description[class_value] = describe_our_data(rows)
return description
def calculate_the_probability(x, mean, stdev):
exponent = exp(-((x - mean) ** 2 / (2 * stdev ** 2)))
result = (1 / (sqrt(2 * pi) * stdev)) * exponent
return result
def calculate_the_probability_by_class(description, row):
total_rows = sum([description[label][0][2] for label in description])
probabilities = dict()
for class_value, class_description, in description.items():
probabilities[class_value] = description[class_value][0][2] / float(total_rows)
for i in range(len(class_description)):
mean, stdev, count = class_description[i]
probabilities[class_value] *= calculate_the_probability(row[i], mean, stdev)
return probabilities
def predict(description, row):
probabilities = calculate_the_probability_by_class(description, row)
best_label, best_prob = None, -1
for class_value, probability in probabilities.items():
if best_label is None or probability > best_prob:
best_prob = probability
best_label = class_value
return best_label
def naive_bayes(train, test):
description = describe_our_data_by_class(train)
predictions = list()
for row in test:
prediction = predict(description, row)
predictions.append(prediction)
return predictions
dataset = load_csv('iris.csv')
print(dataset)
print('--------------------')
for i in range(len(dataset[0]) - 1):
convert_str_to_float(dataset, i)
print(dataset)
convert_str_to_int(dataset, len(dataset[0]) - 1)
print('--------------------')
print(dataset)
n_folds = 5
scores = whether_our_model_is_good_or_not(dataset, naive_bayes, n_folds)
print("The score of our model is : 【 %s 】" % scores)
print('The accuracy of our model is : %.6f%% ' % (sum(scores) / float(len(scores))))

KNN
纯Python构建的经典算法实战Kaggle真实项目:水产种类与年龄判断
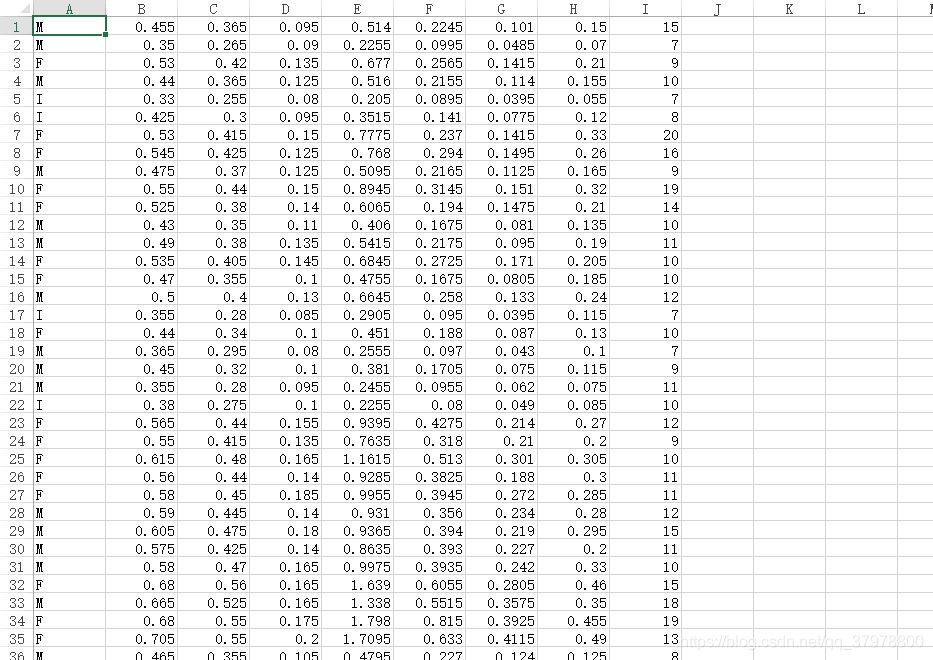
from random import seed
from random import randrange
from csv import reader
from math import sqrt
# 1.读取数据 csv
def read_our_csv_file(filename):
dataset = list()
with open(filename, 'r') as file:
csv_reader = reader(file)
for row in csv_reader:
if not row:
continue
dataset.append(row)
return dataset
# 2.数据类型转换(str to float)
def change_string_to_float(dataset, column):
for row in dataset:
row[column] = float(row[column].strip())
# 3.数据类型转换(str to int)
def change_string_to_int(dataset, column):
class_value = [row[column] for row in dataset]
find_the_unique_class = set(class_value)
lookup = dict()
for i, value in enumerate(find_the_unique_class):
lookup[value] = i
for row in dataset:
row[column] = lookup[row[column]]
return lookup
# 4.正则化
def find_the_min_and_max_of_our_data(dataset):
min_and_max_list = list()
for i in range(len(dataset[0])):
column_value = [row[i] for row in dataset]
the_min_value = min(column_value)
the_max_value = max(column_value)
min_and_max_list.append([the_min_value, the_max_value])
return min_and_max_list
def normalize_our_data(dataset, min_and_max_list):
for row in dataset:
for i in range(len(row)):
row[i] = (row[i] - min_and_max_list[i][0]) / (min_and_max_list[i][1] - min_and_max_list[i][0])
# 5. k fold切分数据,
# 注意:不改变原数据
def k_fold_cross_validation(dataset, n_folds):
dataset_split = list()
dataset_copy = list(dataset)
every_fold_size = int(len(dataset) / n_folds)
for i in range(n_folds):
fold = list()
while len(fold) < every_fold_size:
index = randrange(len(dataset_copy))
fold.append(dataset_copy.pop(index))
dataset_split.append(fold)
return dataset_split
# 6.判断准确性(accuracy)
def calculate_our_model_accuracy(actual, predicted):
correct_counter = 0
for i in range(len(actual)):
if actual[i] == predicted[i]:
correct_counter += 1
return correct_counter / float(len(actual)) * 100.0
# 7.给我们的算法进行评估(打分)
def how_good_is_our_algo(dataset, algo, n_folds, *args):
folds = k_fold_cross_validation(dataset, n_folds)
scores = list()
for fold in folds:
train_dataset = list(folds)
train_dataset.remove(fold)
train_dataset = sum(train_dataset, [])
test_dataset = list()
for row in fold:
row_copy = list(row)
test_dataset.append(row_copy)
row_copy[-1] = None
predicted = algo(train_dataset, test_dataset, *args)
actual = [row[-1] for row in fold]
accuracy = calculate_our_model_accuracy(actual, predicted)
scores.append(accuracy)
return scores
# 8.计算欧几里德举例
def calculate_euclidiean_distance(row1, row2):
distance = 0.0
for i in range(len(row1) - 1):
distance += (row1[i] - row2[i]) ** 2
return sqrt(distance)
# 9.找到最近的k个点
def get_our_neighbors(train_dataset, test_row, num_of_neighbors):
distances = list()
for train_dataset_row in train_dataset:
dist = calculate_euclidiean_distance(test_row, train_dataset_row)
distances.append((train_dataset_row, dist))
distances.sort(key=lambda every_tuple: every_tuple[1])
neighbors = list()
for i in range(num_of_neighbors):
neighbors.append(distances[i][0])
return neighbors
# 10.做预测
def make_prediction(train_dataset, test_row, num_of_neighbors):
neighbors = get_our_neighbors(train_dataset, test_row, num_of_neighbors)
output = [row[-1] for row in neighbors]
our_prediction = max(set(output), key=output.count)
return our_prediction
# 11.运用KNN算法
def get_our_prediction_using_knn_algo(train_dataset, test_dataset, num_of_neighbors):
predictions = list()
for test_row in test_dataset:
our_prediction = make_prediction(train_dataset, test_row, num_of_neighbors)
predictions.append(our_prediction)
return predictions
seed(1)
dataset = read_our_csv_file('abalone.csv')
for i in range(1, len(dataset[0])):
change_string_to_float(dataset, i)
change_string_to_int(dataset, 0)
# print(dataset)
n_folds = 10
num_neighbors = 7
scores = how_good_is_our_algo(dataset, get_our_prediction_using_knn_algo, n_folds, num_neighbors)
print('Our model\'s scores are : %s' % scores)
print('The mean accuracy is :%.3f%%' % (sum(scores) / float(len(scores))))
![]()
LVQ学习向量
纯Python构建的经典算法实战Kaggle真实项目:雷达电离层探测项目
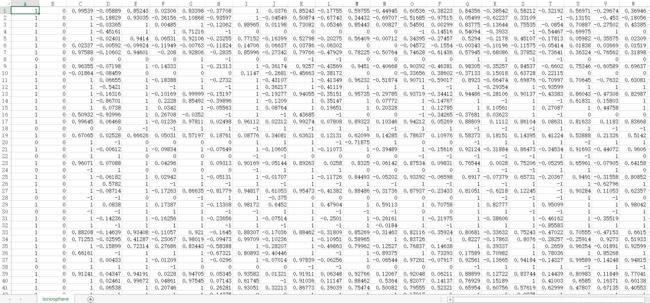
# 1.导入必备库
from random import seed
from random import randrange
from csv import reader
from math import sqrt
# 2.读取csv数据
def read_our_csv_file(filename):
dataset = list()
with open(filename, 'r') as file:
csv_reader = reader(file)
for row in csv_reader:
if not row:
continue
dataset.append(row)
return dataset
# dataset=read_our_csv_file("ionosphere.csv")
#
# print(dataset)
# 3.数据类型转换(string to float)
def convert_string_to_float(dataset, column):
for row in dataset:
row[column] = float(row[column].strip())
# 4.类别数据转换为int数据(class string to int)
def convert_string_to_int(dataset, column):
class_value = [row[column] for row in dataset]
unique_class = set(class_value)
look_up = dict()
for i, value in enumerate(unique_class):
look_up[value] = i
for row in dataset:
row[column] = look_up[row[column]]
return look_up
# 5.为了让预测更加稳定,要对数据进行处理
def k_fold_cross_validation_split(dataset, n_folds):
dataset_split = list()
dataset_copy = list(dataset)
fold_size = int(len(dataset) / n_folds)
for i in range(n_folds):
fold = list()
while len(fold) < fold_size:
index = randrange(len(dataset_copy))
fold.append(dataset_copy.pop(index))
dataset_split.append(fold)
return dataset_split
# 6.计算一下准确性
def calculate_our_accuracy(actual, predicted):
correct = 0
for i in range(len(actual)):
if actual[i] == predicted[i]:
correct += 1
return correct / float(len(actual)) * 100.0
# 7.评估算法
def whether_our_algo_is_good_or_not(dataset, algo, n_folds, *args):
folds = k_fold_cross_validation_split(dataset, n_folds)
scores = list()
for fold in folds:
train_set = list(folds)
train_set.remove(fold)
train_set = sum(train_set, [])
test_set = list()
for row in fold:
row_copy = list(row)
test_set.append(row_copy)
row_copy[-1] = None
predicted = algo(train_set, test_set, *args)
actual = [row[-1] for row in fold]
accuracy = calculate_our_accuracy(actual, predicted)
scores.append(accuracy)
return scores
# 8.计算欧氏距离
def calculate_euclidean_distance(row1, row2):
distance = 0.0
for i in range(len(row1) - 1):
distance += (row1[i] - row2[i]) ** 2
return sqrt(distance)
# 9.计算BMU
def calculate_BMU(codebooks, test_row):
distances = list()
for codebook in codebooks:
dist = calculate_euclidean_distance(codebook, test_row)
distances.append((codebook, dist))
distances.sort(key=lambda every_tuple: every_tuple[1])
return distances[0][0]
# 10.预测以及生成随机codebook
def predict(codebooks, test_row):
bmu = calculate_BMU(codebooks, test_row)
return bmu[-1]
def random_codebook(train):
train_index = len(train)
n_features = len(train[0])
codebook = [train[randrange(train_index)][i] for i in range(n_features)]
return codebook
# 11.对codebook进行训练
def train_our_codebooks(train, n_codebooks, learning_rate, epochs):
codebooks = [random_codebook(train) for i in range(n_codebooks)]
for epoch in range(epochs):
rate = learning_rate * (1.0 - (epoch / float(epochs)))
for row in train:
bmu = calculate_BMU(codebooks, row)
for i in range(len(row) - 1):
error = row[i] - bmu[i]
if bmu[-1] == row[-1]:
bmu[i] += rate * error
else:
bmu[i] -= rate * error
return codebooks
# 12.LVQ
def LVQ(train, test, n_codebooks, learning_rate, epochs):
codebooks = train_our_codebooks(train, n_codebooks, learning_rate, epochs)
predictions = list()
for row in test:
output = predict(codebooks, row)
predictions.append(output)
return predictions
seed(1)
dataset = read_our_csv_file("ionosphere.csv")
for i in range(len(dataset[0]) - 1):
convert_string_to_float(dataset, i)
convert_string_to_int(dataset, len(dataset[0]) - 1)
#
# print(dataset)
n_folds = 5
learning_rate = 0.3
n_epochs = 50
n_codebooks = 50
scores = whether_our_algo_is_good_or_not(dataset, LVQ, n_folds, n_codebooks, learning_rate, n_epochs)
print("Our LVQ algo's scores are : %s " % scores)
print("Our LVQ's mean accracy is %.3f%%" % (sum(scores) / float(len(scores))))

神经网络
纯Python构建的经典算法实战Kaggle真实项目:小麦品种判断项目
# 1.import lib
from random import seed
from random import randrange
from random import random
from csv import reader
from math import exp
# 2. read our data
def load_csv(filename):
dataset = list()
with open(filename, 'r') as file:
csv_reader = reader(file)
for row in csv_reader:
if not row:
continue
dataset.append(row)
return dataset
# a= load_csv('seeds_dataset.csv')
# print(a)
# 3.change string date type to float
def str_to_float(dataset, column):
for row in dataset:
row[column] = float(row[column].strip())
# 4.change class string to int
def str_column_to_int(dataset, column):
class_value = [row[column] for row in dataset]
# using set to make int unique
unique = set(class_value)
lookup = dict()
for i, value in enumerate(unique):
lookup[value] = i
for row in dataset:
row[column] = lookup[row[column]]
return lookup
# 5.normalize our data
def dataset_minmax(dataset):
minmax = list()
stats = [[min(column), max(column)] for column in zip(*dataset)]
return stats
def normalize_dataset(dataset, minmax):
for row in dataset:
for i in range(len(row) - 1):
row[i] = (row[i] - minmax[i][0]) / (minmax[i][1] - minmax[i][0])
# 6. k_fold cross-validation
def cross_validation_split(dataset, n_folds):
dataset_split = list()
dataset_copy = list(dataset)
fold_size = int(len(dataset) / n_folds)
for i in range(n_folds):
fold = list()
while len(fold) < fold_size:
index = randrange(len(dataset_copy))
fold.append(dataset_copy.pop(index))
dataset_split.append(fold)
return dataset_split
# 7.calculate accuracy
def accuracy_metric(actual, predicted):
correct = 0
for i in range(len(actual)):
if actual[i] == predicted[i]:
correct += 1
return correct / float(len(actual)) * 100.0
# 8.score our algo
def evaluate_our_algorithm(dataset, algorithm, n_folds, *args):
folds = cross_validation_split(dataset, n_folds)
scores = list()
for fold in folds:
train_set = list(folds)
train_set.remove(fold)
train_set = sum(train_set, [])
test_set = list()
for row in fold:
row_copy = list(row)
test_set.append(row_copy)
row_copy[-1] = None
predicted = algorithm(train_set, test_set, *args)
actual = [row[-1] for row in fold]
accuracy = accuracy_metric(actual, predicted)
scores.append(accuracy)
return scores
# 9. activation
def activate(weights, inputs):
activation = weights[-1]
for i in range(len(weights) - 1):
activation += weights[i] * inputs[i]
return activation
# 10. transfer our neuron activation
def transfer(activation):
return 1.0 / (1.0 + exp(-activation))
# 11.forward propagate our network to get our output
def forward_propagate(network, row):
inputs = row
for layer in network:
new_inputs = []
for neuron in layer:
activation = activate(neuron['weights'], inputs)
neuron['output'] = transfer(activation)
new_inputs.append(neuron['output'])
inputs = new_inputs
return inputs
# 12.calculate the derivative of a output
def transfer_derivative(output):
return output * (1.0 - output)
# 13.calculate backpropagation error
def backward_propagate_error(network, expected):
for i in reversed(range(len(network))):
layer = network[i]
errors = list()
if i != len(network) - 1:
for j in range(len(layer)):
error = 0.0
for neuron in network[i + 1]:
error += (neuron['weights'][j] * neuron['delta'])
errors.append(error)
else:
for j in range(len(layer)):
neuron = layer[j]
errors.append(expected[j] - neuron['output'])
for j in range(len(layer)):
neuron = layer[j]
neuron['delta'] = errors[j] * transfer_derivative(neuron['output'])
# 14. update our weight
def update_weights(network, row, learning_rate):
for i in range(len(network)):
inputs = row[:-1]
if i != 0:
inputs = [neuron['output'] for neuron in network[i - 1]]
for neuron in network[i]:
for j in range(len(inputs)):
neuron['weights'][j] += learning_rate * neuron['delta'] * inputs[j]
neuron['weights'][-1] += learning_rate * neuron['delta']
# 15. epoch
def train_network(network, train, learning_rate, n_epoch, n_outputs):
for epoch in range(n_epoch):
for row in train:
outputs = forward_propagate(network, row)
expected = [0 for i in range(n_outputs)]
expected[row[-1]] = 1
backward_propagate_error(network, expected)
update_weights(network, row, learning_rate)
# 16. initialization
def initialize_network(n_inputs, n_hidden, n_outputs):
network = list()
hidden_layer = [{'weights': [random() for i in range(n_inputs + 1)]} for i in range(n_hidden)]
network.append(hidden_layer)
output_layer = [{'weights': [random() for i in range(n_hidden + 1)]} for i in range(n_outputs)]
network.append(output_layer)
return network
# 17. make prediction
def predict(network, row):
outputs = forward_propagate(network, row)
return outputs.index(max(outputs))
# 18. using backpropagation&SGD
def back_propagation(train, test, learning_rate, n_epoch, n_hidden):
n_inputs = len(train[0]) - 1
n_outputs = len(set([row[-1] for row in train]))
network = initialize_network(n_inputs, n_hidden, n_outputs)
train_network(network, train, learning_rate, n_epoch, n_outputs)
predictions = list()
for row in test:
prediction = predict(network, row)
predictions.append(prediction)
return (predictions)
seed(1)
dataset = load_csv('seeds_dataset.csv')
for i in range(len(dataset[0]) - 1):
str_to_float(dataset, i)
str_column_to_int(dataset, len(dataset[0]) - 1)
minmax = dataset_minmax(dataset)
normalize_dataset(dataset, minmax)
n_folds = 5
learning_rate = 0.1
n_epoch = 1000
n_hidden = 5
scores = evaluate_our_algorithm(dataset, back_propagation, n_folds, learning_rate, n_epoch, n_hidden)
print("Our algo's score is [%s]" % scores)
results = sum(scores) / float(len(scores))
print("The mean accuracy is [%.3f%%] " % results)
![]()
随机森林
# CART->非常容易收到极端值(high variance)的影响
# bagging->通过建立多个模型(通过subsample的方式),通过多个模型与做预测,平均
# 通过bagging方式生成的树,相互之间高度相关
# random forest
# num_feature_to_use_when_doing_a_split = sqrt(num_input feature)
from random import seed
from random import randrange
from random import random
from csv import reader
from math import sqrt
# 1.load our data
def load_csv(filename):
dataset = list()
with open(filename, 'r') as file:
csv_reader = reader(file)
for row in csv_reader:
if not row:
continue
dataset.append(row)
return dataset
# 2.datatype conversion
def str_to_float(dataset, column):
for row in dataset:
row[column] = float(row[column].strip())
def str_to_int(dataset, column):
class_value = [row[column] for row in dataset]
unique = set(class_value)
look_up = dict()
for i, value in enumerate(unique):
look_up[value] = i
for row in dataset:
row[column] = look_up[row[column]]
return look_up
# 3.k_fold cross validation
def cross_validation_split(dataset, n_folds):
dataset_split = list()
dataset_copy = list(dataset)
fold_size = int(len(dataset) / n_folds)
for i in range(n_folds):
fold = list()
while len(fold) < fold_size:
index = randrange(len(dataset_copy))
fold.append(dataset_copy.pop(index))
dataset_split.append(fold)
return dataset_split
# 4.calculate model accuracy
def calculate_accuracy(actual, predicted):
correct = 0
for i in range(len(actual)):
if actual[i] == predicted[i]:
correct += 1
return correct / float(len(actual)) * 100.0
# 5.how good is our algo
def evaluate_our_algo(dataset, algo, n_folds, *args):
folds = cross_validation_split(dataset, n_folds)
scores = list()
for fold in folds:
train_set = list(folds)
train_set.remove(fold)
train_set = sum(train_set, [])
test_set = list()
for row in fold:
row_copy = list(row)
test_set.append(row_copy)
row_copy[-1] = None
predicted = algo(train_set, test_set, *args)
actual = [row[-1] for row in fold]
accuracy = calculate_accuracy(actual, predicted)
scores.append(accuracy)
return scores
# 6.left and right split
def test_split(index, value, dataset):
left, right = list(), list()
for row in dataset:
if row[index] < value:
left.append(row)
else:
right.append(row)
return left, right
# 7.calculate gini index
def gini_index(groups, classes):
n_instances = float(sum([len(group) for group in groups]))
gini = 0.0
for group in groups:
size = float(len(group))
if size == 0:
continue
score = 0.0
for class_val in classes:
p = [row[-1] for row in group].count(class_val) / size
score += p * p
gini += (1 - score) * (size / n_instances)
return gini
# 8.calculate the best split
def get_split(dataset, n_features):
class_values = list(set(row[-1] for row in dataset))
posi_index, posi_value, posi_score, posi_groups = 888, 888, 888, None
features = list()
while len(features) < n_features:
index = randrange(len(dataset[0]) - 1)
if index not in features:
features.append(index)
for index in features:
for row in dataset:
groups = test_split(index, row[index], dataset)
gini = gini_index(groups, class_values)
if gini < posi_score:
posi_index, posi_value, posi_score, posi_groups = index, row[index], gini, groups
return {'index': posi_index, 'value': posi_value, 'groups': posi_groups}
# 9. to terminal
def determine_the_terminal(group):
outcomes = [row[-1] for row in group]
return max(set(outcomes), key=outcomes.count)
# 10.
# 1.split our data into left and right
# 2.delete the original data
# 3.check if the data is none/max depth/min size
# 4.to terminal
def split(node, max_depth, min_size, n_features, depth):
left, right = node['groups']
del (node['groups'])
if not left or not right:
node['left'] = node['right'] = determine_the_terminal(left + right)
return
if depth >= max_depth:
node['left'], node['right'] = determine_the_terminal(left), determine_the_terminal(right)
if len(left) <= min_size:
node['left'] = determine_the_terminal(left)
else:
node['left'] = get_split(left, n_features)
split(node['left'], max_depth, min_size, n_features, depth + 1)
if len(right) <= min_size:
node['right'] = determine_the_terminal(right)
else:
node['right'] = get_split(right, n_features)
split(node['right'], max_depth, min_size, n_features, depth + 1)
# 11.make our decision tree
def build_tree(train, max_depth, min_zise, n_features):
root = get_split(train, n_features)
split(root, max_depth, min_zise, n_features, 1)
return root
# 12.make prediction
def predict(node, row):
if row[node['index']] < node['value']:
if isinstance(node['left'], dict):
return predict(node['left'], row)
else:
return node['left']
else:
if isinstance(node['right'], dict):
return predict(node['right'], row)
else:
return node['right']
# 13. subsample
def subsample(dataset, ratio):
sample = list()
n_sample = round(len(dataset) * ratio)
while len(sample) < n_sample:
index = randrange(len(dataset))
sample.append(dataset[index])
return sample
# 14.make prediction using bagging
def bagging_predict(trees, row):
predictions = [predict(tree, row) for tree in trees]
return max(set(predictions), key=predictions.count)
# 15.random_forest
def random_forest(train, test, max_depth, min_size, sample_size, n_trees, n_features):
trees = list()
for i in range(n_trees):
sample = subsample(train, sample_size)
tree = build_tree(sample, max_depth, min_size, n_features)
trees.append(tree)
predictions = [bagging_predict(trees, row) for row in test]
return (predictions)
seed(1)
dataset = load_csv('sonar.all-data.csv')
for i in range(len(dataset[0]) - 1):
str_to_float(dataset, i)
str_to_int(dataset, len(dataset[0]) - 1)
n_folds = 5
max_depth = 10
min_size = 1
sample_size = 1
n_features = int(sqrt(len(dataset[0]) - 1))
for n_trees in [1, 5, 10]:
scores = evaluate_our_algo(dataset, random_forest, n_folds, max_depth, min_size, sample_size, n_trees, n_features)
print('We are using [%d] trees' % n_trees)
print('The scores are : [%s]' % scores)
print('The mean accuracy is [%.3f]' % (sum(scores) / float(len(scores))))
