目标检测 —— YOLOv1论文精读
YOLOv1论文下载
YOLOv1代码下载 darknet版、tensorflow版、caffe版
官方博客
文章目录
- 论文
-
- Abstract (摘要)
- 1、Introduction(介绍)
- 2、Unified Detection(统一检测)
-
- 2.1 Network Design (网络架构)
- 2.2 Training(训练)
- 2.3 Inference (推论)
- 2.4 Limitations of YOLO(局限性)
- 3、 Comparison to Other Detection Systems
- 4、 Experiments (实验)
- 5、Real-Time Detection In The Wild (现实中的实时检测)
- 6、Conclusion(结论)
论文
Abstract (摘要)

- 本文提出一种新的物体检测的方法:You Only Look Once(YOLO) 它的名字也侧面说明了YOLO算法的优点在于检测速度快。
- 原先的物体检测算法如R-CNN, fast R-CNN, 将检测算法转换为分类问题(classify); YOLO算法将检测问题转换为回归问题(regression),包括检测框(Bouding boxes)位置和检测框中物体所属类别(Class)。
- YOLO检测的过程只有一个CNN网络,直接输出检测框的位置和所属的类别,因此也称为端到端(end-to-end)或单阶段(one-stage)的检测方法。
- 与之对应的是两阶段(two-stage)的检测方法,如Faster-rcnn Mask-Rcnn系列。其中第一阶段得到预选框(proposal),第二阶段输出结果,如下图所示。


- 这一段就是先夸YOLO的检测速度非常快。举例:标准版(base yolo)可以每秒处理45帧图片(45FPS),精简版的(fast yolo)检测速度可以达到155 FPS, 检测精度是同类实时检测算法的两倍。
- 相较于其他的先进的物体检测系统,YOLO在物体定位(location)时更容易出错,但是在背景上错误预测出正例(false positives)的情况会少一些。【通俗的说就是:YOLO可以较为准确的判断有没有目标物体,但是对于预测目标物体的具体位置会有一定的偏差】
- YOLO比DPM、R-CNN等物体检测系统能够学到更加抽象的物体的特征。
1、Introduction(介绍)

- 第一段主要讲了人类视觉的三大功能:what(分类),where(定位),how(场景),然后介绍计算机视觉在自动驾驶上的应用。

- 目前的检测算法将检测问题转化为分类问题。即在图像中找到不同位置(location)和尺寸(scale)的检测框,然后在检测框内的物体进行分类(classfy)。
- 例如DPM算法采用滑动窗口(sliding window)在整张图像上均匀滑动,然后用分类器来评估滑窗内是否有物体。

- R-CNN方法使用region proposal(区域建议)来生成整张图像中可能包含待检测物体的可能的 bounding boxes。然后在这些所建议的检测框(proposed boxes)执行分类器。
- 在分类结束后,对bouding boxes 进行后加工(post-processing)使之更加精确:包括消除重复的检测框、并基于整个场景中的其他物体重新对boxes进行打分。
- 但是缺点在于这个优化过程执行起来很慢且困难,因为每一个环节都是分开训练的。

- 这段很重要,点明了YOLO的核心思想。YOLO算法将目标检测问题转化为单一的回归问题(regression problem)。给卷积网络输入的是图像的像素(image pixels), 直接输出的是检测框的位置坐标(bounding box coordinates)和类别概率(class probability)。
- 通过YOLO算法可以预测出这个物体是什么(what),在哪里(where)


- YOLO算法很简洁:如上图,将一张图像输出卷积网络(convolutional network) 就可以同时预测出多个检测框和每个检测框所属的类别概率。
- YOLO用整张图片进行训练,并且可以直接优化检测的性能(optimize detection performance)
- 下面就是分条介绍这种统一模型较传统模型的优点。

- 第一个优点就是速度快: YOLO 可以以小于 25 毫秒延迟的处理速度处理实时视频;准确度高:其mAP值(mean average presition)是其他实时检测算法的两倍。
![]()

- 第二个优点是YOLO算法可以更好的“看到”全局的信息。它通过结合局部的特征和上下文信息来进行检测。
- 因此,与R-CNN相比较,YOLO犯背景错误【background error: 将背景错误的认成是物体】的数量更少。

- 第三个优点:YOLO学到物体更泛化的特征表示。 在这里作者举了个例子,让YOLO在自然景观的图片上训练然后在抽像的艺术图片上去测试,YOLO 的表现要优于 DPM、R-CNN。
- 因此,YOLO算法的适应性更强,当其应用到一个新的领域或者有非法的输入,也很很难导致网络的崩溃。

- 这里提及了YOLO的两个缺点:准确性仍然落后于最先进的检测系统,对于小目标的检测效果不好。
2、Unified Detection(统一检测)

- 我们将目标检测的不同环节统一为一个神经网络。通过网络对整张图片提取的特征来同时预测所有的检测框的位置和类别。
- 这种端到端的训练方式可以很好的平衡检测的速度和精度。

- 我们的检测系统将输入的图片划分成S*S的网格,如果一个物体的中心落在某个网格单元(grid cell)内,则该网格单元负责检测该物体。

- 每个检测框负责预测
B个检测框(Bounding Box),和每个检测框的置信度得分(confidence score)。这个置信度得分反应了在该检测框内含有物体和物体预测类别的把握有多大。 - 置信度定义为 C o n f i d e n c e = P r ( O b j e c t ) ∗ I O U p r e d t r u t h Confidence=Pr(Object)*IOU_{pred}^{truth} Confidence=Pr(Object)∗IOUpredtruth。 其中, P r ( O b j e c t ) Pr(Object) Pr(Object)包含物体时取值为1,否则为0。 I O U p r e d t r u t h IOU_{pred}^{truth} IOUpredtruth计算的是预测框(predicted box)和真实框(ground truth)之间的交并比。 I O U = S i n t e r s e c t i o n S u n i o n I O U=\frac{S_{ {intersection}}}{S_{{union }}} IOU=SunionSintersection


- 每一个检测框包含5个预测值: x , y , w , h , c o n f i d e n c e x,y,w,h,confidence x,y,w,h,confidence
(x,y)表示检测框的中心点相对于网格单元的位置坐标。
w,h分别表示检测框相对于整幅图片的宽和高
confidence表示预测框和真实框之间的交并比(IOU)


- 每个网格单元要预测
C个条件类别概率(conditional class probability)。用条件概率表示为 P r ( C l a s s i ∣ O b j e c t ) Pr(Class_i|Object) Pr(Classi∣Object):在这个网格单元包含物体的情况下,该物体属于类别 i i i 的概率。 - 每个网格单元只预测一组类别概率,每组包含
C个类别,而不考虑检测框的数量B。 - 在测试阶段,将条件类别概率【 P r ( C l a s s i ∣ O b j e c t ) Pr(Class_i|Object) Pr(Classi∣Object)】和检测框的置信度【 C o n f i d e n c e = P r ( O b j e c t ) ∗ I O U p r e d t r u t h Confidence=Pr(Object)*IOU_{pred}^{truth} Confidence=Pr(Object)∗IOUpredtruth】相乘。得到对于某个检测框属于某种类别的可信度得分。
- 这个得分既反应了反映了bounding box是否含有该类别的Object和bounding box坐标的准确度。
Pr ( Class i ∣ Object ) ∗ Pr ( Object ) ∗ I O U pred truth = Pr ( Class i ) ∗ I O U pred truth \operatorname{Pr}\left(\text { Class }_{i} \mid \text { Object }\right) * \operatorname{Pr}(\text { Object }) * \mathrm{IOU}_{\text {pred }}^{\text {truth }}=\operatorname{Pr}\left(\text { Class }_{i}\right) * \mathrm{IOU}_{\text {pred }}^{\text {truth }} Pr( Class i∣ Object )∗Pr( Object )∗IOUpred truth =Pr( Class i)∗IOUpred truth


- 将图片划分成
S*S的网格,对于每个网格单元预测B个检测框,每个检测框有5个值:x,y,h,w,confidence。每个网格单元预测C种类别。因此最终的预测值是S*S*(B*5+C)维度的张量(Tensor)
❗️❗️❗️ 特别注意
- 由于输出层是全连接层,因此检测和训练时图像输入的分辨率大小应该一致。
- 从每个网格单元预测
B个检测框中选择IOU最高的检测框作为输出。因此在一个网格单元包含多个物体或者有重叠时,只能检测出一个物体。
2.1 Network Design (网络架构)

-
作者采用PASCAL VOC数据集来对该模型进行评估。网络的初始卷积层(convolutional layers)用来提取特征(extract feature),而全连接层(fully connected layers)输出预测的概率和坐标。
-
FAST YOLO比YOLO有更少的卷积层和更小的滤波器(filter),但是训练和预测时的参数是相同的。
-
YOLO网络结构借鉴了 GoogLeNet 。YOLO检测网络包括24个卷积层和2个全连接层,如下图所示。
GoogLeNet架构如下:
YOLO架构如下:
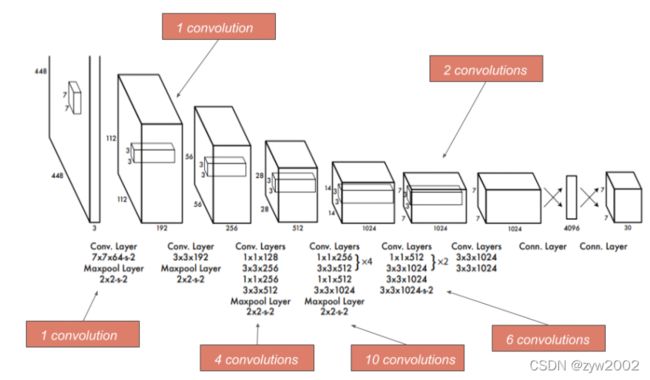
-
最终得到
7*7*30的张量。划分的网格为7*7, 每个网格对应有2个检测框,每个检测框有5个预测值:x,y,w,h,confidence。一共有20个类别,因此每个网格共有30=(5*2+20)个预测值。
动图展示:地址

2.2 Training(训练)

- 预训练分类网络:在1000分类的数据集上进行预训练。这个网络的结构为:Figure3中的前20个卷积网络+平均池化层(average-pooling layer)+全连接层( fully connected layer)

- 训练检测网络:根据前人的经验,为预训练添加卷积层和全连接层可以提升检测的性能。因此在原先的基础上添加4个卷积层和2个全连接层,并随机初始化权重。检测要求细粒度的视觉信息,所以把网络输入把224224变成448448。

- 网络的最后一层输出的是类被概率和检测框的坐标。将检测框的宽高分别除以图像的宽和高,使之取值范围位于[0,1],从而进行归一化; 将检测框的位置坐标用相对于网格单元的偏移量来表示,来进行归一化(normalize)。

- 最后使用一个线性激活函数(linear activation function),公式如上图所示,称为Leaky RELU。与RELU 函数唯一的区别在于,当x小于0时,取值为0.1x 而不是0。这样可以解决梯度消失的问题。
![]()

- 如果采用平方和误差(sum-squared error)来对模型进行优化,它并不完全符合我们最大化平均精度(average precision)的目标。
- 问题1:因为计算平方和误差时,定位和分类的误差权重相等,但是这样做是不符合理想情况的。因为定位的只有8维,而分类的有20维度,让两者同等重要是不合理的。
- 问题2:在一张图像中,许多网格单元不包含任何的对象,其置信度为0,并且它的数量占比很多,从而加大了它对于整个模型梯度更新的贡献比。导致模型不稳定(instability)且训练的早期就容易发散(diverge)。

- 为了解决上述两种问题,首先增大了检测框位置坐标的权重。其系数为 λ coord = 5 \lambda_{\text {coord }}=5 λcoord =5 (数值大于1,因此是扩大)
- 其次是减少那些不包含物体的网格单元的权重。其系数为 λ noobj = 0.5 \lambda_{\text {noobj }}=0.5 λnoobj =0.5 (数值小于1,因此是缩小)

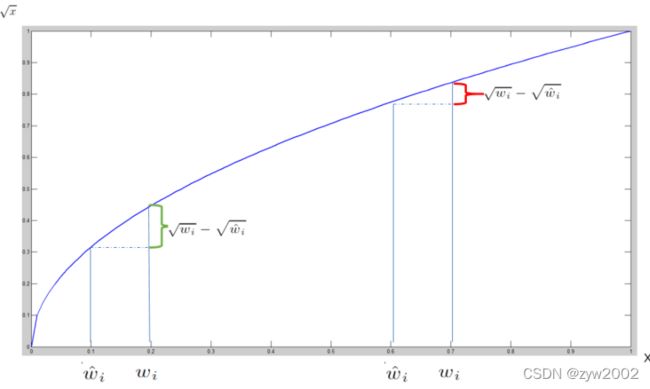
- 问题3:平方和误差模型使得不同大小的检测框的权重也相同。但是实际上来说,相同大小的误差在大的检测框上的相对误差会更小,因此其权重在大的检测框上也理应更小。
- 为了解决上述问题3,
我们采用检测框长宽的平方根(square root)来取代长宽。如下图:小的检测框(靠左边)的横轴值较小,发生偏移时,反应到y轴上的loss(下图绿色)比大的检测框(下图红色)要大。

- 一个网格单元会预测多个检测框,但是在训练时,一个检测框只负责预测一个物体。
- 如何挑选呢?我们选择检测框和真实框的IOU最大的检测框。
- 这种做法的好处就是每个预测器会对特定大小,类别的物体预测的更好,从而提升总体的召回率(overall recall)

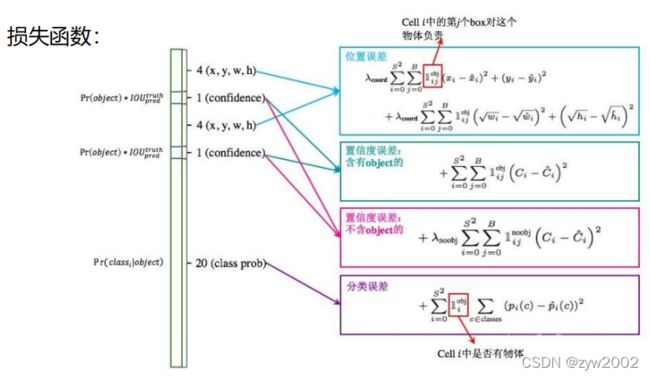

- 损失函数(loss function)的具体定义如上 ,逐项的解释如下:
1️⃣ 位置坐标(x,y)的损失: λ coord \lambda_{\text {coord }} λcoord 是权重系数为5,为了增大位置信息的影响。两个求和公式分别对网格单元 i i i(取值范围0~S*S) 和每个网格单元的检测框数量 j j j(取值范围0~B) 的位置偏移量求平方和。
2️⃣ 检测框宽和高w,h的损失:同样有系数 λ coord \lambda_{\text {coord }} λcoord ,为了增大位置信息的影响。对其宽高的平方根求偏移误差的平方和
3️⃣ 网格单元有无物体的损失
4️⃣ 网格单元没有无物体的损失:前面有系数 λ n o o b j \lambda_{noobj} λnoobj为0.5,使得没有物体的单元格权重减少。
5️⃣ 网格单元物体类别判断的损失

- 对上述的公式做两点补充说明:一、 分类误差(上述第5项)支当网格单元内有物体时才计算;二、位置坐标的误差(第一项和第二项)只针对该网格单元中IOU最大的检测框进行计算。

- 训练阶段(train):从VOC中选取训练集(training)和验证集(validation)
- 测试阶段:测试阶段的参数配置 b a t c h s i z e = 64 , m o m e n t u m = 0.9 , d e c a y = 0.0005 batchsize=64, momentum=0.9,decay=0.0005 batchsize=64,momentum=0.9,decay=0.0005

- 学习率(learning)的调整策略:分阶段的逐步上升。因为如果一开始就有较高的学习率,不稳定的梯度导致模型容易发散(diverge),即难以收敛。

- 避免过拟合(overfitting):采用两种方法,丢弃(dropout)和扩充数据集(data augmentation)
- 丢弃(dropout): 在第一个连接层后添加了一个丢弃率为0.5的dropout layer, 从而避免了层与层之间的协同适应(co-adaptation)
- 扩充数据集(data augmentation):引入了高达原始图像大小20%的随机缩放和平移。我们还随机调整曝光和饱和度的图像高达1.5倍的HSV颜色空间。
2.3 Inference (推论)


- 较基于分类器的检测方法,YOLO只需要单个网络,检测速度快
- 当图像中的物体较大,或者处于网格边界的物体,可能在多个网格单元中被定位出来。可以用非极大值抑制(NMS,Non-Maximal Suppression, 即选取IOU最大的检测框) 进行去除重复检测的物体。
2.4 Limitations of YOLO(局限性)

- 局限性一:空间局限性。因为一个网格单元只能预测两个检测框,且只能有一种类别。如果物体比较小且相互间靠近,如鸟群,在一个单元网格中只能检测出一只鸟,造成漏检。

- 局限性二:尺度泛化能力弱。对于新物体或者不寻常的纵横比(unusual aspect ratios)检测效果不好。并且只能识别出比较粗的特征(coarse feature),因为在网络中有许多的下采样层(downsampling layer),导致图像信息的丢失。

- 局限性三:损失函数不精确。一般来说,相同大小误差对于小的检测框的影响会偏小,而对于大的检测框影响会相对较小。而我们的模型对于两个却等同看待。
3、 Comparison to Other Detection Systems
下图给出了YOLO与其他物体检测方法,在检测速度和准确性方面的比较结果。

-
Deformable parts models ( DPM )
DMP 是使用滑窗的方法来进行物件侦测。DPM 利用几个独立的流程来进行侦测: 1. 特征提取2. 对区域做分类3. 利用区域分数来进行边界框预测
YOLO 则利用单一个CNN 结构来取代上述的全部过程。这一个CNN 会进行特征提取、边界框预测、NMS 并同时进行上下文推理。跟DPM 萃取的静态特征不同,这个CNN 结构可以对特征进行动态的持续性的训练,并且在这个侦测任务中进行优化。YOLO 这个统一的结构不论就速度或是准确度而言都胜过DPM。 -
R-CNN
R-CNN 及其变体都使用了region proposals 来取代滑窗侦测。Selective Search ( SS )生成出许多潜在的边界框,其次使用CNN 进行特征萃取,用SVM 进行边界框的评估,一个线性模型来调整边界框,最后再使用NMS 来消除重复的预测。这复杂流程中的每一个阶段都必须要独立进行精准的参数调整,导致最后的侦测系统速度缓慢,再测试阶段侦测每一张图像都要超过40 秒的时间。
YOLO 跟R-CNN 有跟R-CNN 有一些相似性,每一个网格利用卷积结构提出潜在边界框并且给予分数。然而YOLO 在每一个网格中加上了空间限制,这有助于处理同一个物件重复侦测的问题。此外, YOLO 提出的边界框数目每张图像最多仅98 个边界框,远小于R-CNN 利用SS 所提出的将近2000个边界框。
最后,YOLO 结合了这些单独的流程到一个单一的、共同优化的模型。 -
Other Fast Detectors
Fast R-CNN 与Faster R-CNN 把重点放在利用运算共享以及利用神经网路来代替SS 找出region proposals 加速R-CNN 上。虽然它们在速度与准确度的表现都胜过R-CNN,但在即时的表现上仍显不足。
许多的研究试图要利用HOG 的加速、使用级联并且在GPU 上推进运算来加速DPM 的侦测流程,然而只有30Hz DPM 可以进行即时侦测。
YOLO 试图在结构设计上加速侦测,并不在各个独立的侦测流程进行优化。
侦测器在单一类别上(人脸、人) 是可以被高度优化的,因为需要处理的变化相对少得多。YOLO 就是一个学习怎么同时侦测多种物件的通用侦测器。 -
Deep MultiBox
论文: Scalable object detection using deep neural networks.
MultiBox 利用CNN 来提出region proposals,与R-CNN 使用SS 来提出region proposal 不同。MultiBox 使用单一分类预测机率来取代信赖指数预测,可以针对单一分类进行物件侦测,但,MultiBox 无法进行广泛的物件侦测。而且这些都还只是庞大的侦测流程中的一小部分,后续还需要更多图像的patch (怎么翻译都怪怪的XD) 分类。
YOLO 跟MultiBox 都是使用CNN 来进行边界框的预测,但YOLO 是一个更完整的侦测系统。 -
OverFast
论文: Overfeat: Integrated recognition, localization and detection using convolutional networks.
OverFast 利用一个CNN 来进行定位并藉由此定位来侦测物件。它虽然使用有效率的滑窗侦测,但是一个独立的系统。OverFast 在定位上取得优化,但这样的优化却没有在侦测表现上。就如同DPM ,定位器在预测时只看到局部的资讯,无法总结上下文资讯,因此需要特别的后处理来进行一连串的侦测。 -
MultiGrasp
论文: Real-time grasp detection using convolutional neural networks.
YOLO 在做的其实类似于上述论文中的侦测方式,方法就是利用MultiGrasp 系统来进行回归分析以达到边界框的抓取。
然而这种抓取侦测任务比物件侦测来的简单,只需要为单一物件图像预测单一个可抓取区域,不用估算物件尺寸、定位、边界或其分类,只要找到可以抓取的区域即可。而YOLO 则是要在多分类物件上进行边界框及分类机率。
4、 Experiments (实验)
YOLO 的确在准确度上不如R-CNN 的相关变体,但是却大大降低背景误判的机率,牺牲一点准确率换得背景误判降低以及速度提升,在一些现实的考量上的确非常划算。

5、Real-Time Detection In The Wild (现实中的实时检测)
YOLO 是一个快速、准确的物件侦测系统,因此是电脑视觉应用上的理想选择。可以将YOLO 接上视讯镜头验证其即时侦测的表现,包含了撷取图像的时间以及展示这些侦测。
最后产生的系统是具互动性且迷人的。虽然YOLO 是一个独立的图像处理系统,但连接上视讯镜头后,它的功能会类似于一个追踪系统,随着物件移动或改变行为表现来进行物件侦测。
这样的系统已经开源,可以于下列网址中找到: http://pjreddie.com/yolo/.
6、Conclusion(结论)
研究团队提出YOLO 这样一个统一的物件侦测模型。YOLO 本身非常容易打造并且可以直接在整张图像上训练。不像其他以分类器为基础的方法,YOLO 直接使用检测性能来对Loss function 做训练,而且整个模型是一起训练的。
Fast YOLO 是目前文献中( 在当时) 最快的通用检测系统,而YOLO 则推进了即时物件侦测的发展。且YOLO 也可以在新的领域上泛化得很好,使得YOLO 可以成为快速、强健的物件侦测系统的理想选择。
参考
https://blog.csdn.net/shuiyixin/article/details/82533849
https://blog.csdn.net/m0_37192554/article/details/81092761
https://blog.csdn.net/guleileo/article/details/80581858
https://blog.csdn.net/c20081052/article/details/80236015
Allen Tzeng的论文讲解