申请评分卡(A卡)建模-python实现-Step By Step
不同于互联网金融机构,传统银行主要使用专家规则以及申请评分卡做授信申请决策,主要依赖于人行征信进行专家规则建模和评分卡建模,而专家规则主要依赖于业务经验以及领域专家经验。
- 征信部分报文:

- 专家规则&评分卡:

评分卡的意义在于可以根据分数划分成不同档位,从而划分不同客群,进而针对不同客群有不同的授信策略以及定价、额度策略。
通用的信用评分模型如图1-1所示 ,本图片来源于“智能风控:原理、算法与工程实践”一书,信用风险评级模型的主要开发流程如下:
 图1-1
图1-1
流程说明:
(1) 业务需求:解决信贷领域的信用风险、欺诈风险问题
(2) 抽象数学问题:回归、分类
(3) 数据准备:数据多来自数据仓库、业务数据库、CSV等
(4) 探索性数据分析:该步骤主要是获取样本总体的大概情况,描述样本总体情况的指标主要有直方图、箱形图等。
(5) 数据预处理:主要工作包括数据清洗、缺失值处理、异常值处理
(6) 特征工程:该步骤主要是通过统计学的方法,筛选出对违约状态影响最显著的指标,主要有单变量特征选择方法和基于机器学习模型的方法 。
(7) 模型开发:该步骤主要包括变量分段、变量的WOE(证据权重)变换和逻辑回归估算三部分。
(8) 模型评价:该步骤主要是评估模型的区分能力、预测能力、稳定性,并形成模型评估报告,得出模型是否可以使用的结论。
(9) 信用评分转换:根据逻辑回归的系数和WOE等确定信用评分的方法。将Logistic模型转换为标准评分的形式。
(10) 建立评分系统,根据信用评分方法,建立自动信用评分系统。
根据模型实际应用效果反馈,2-10需要不停迭代。
某AI平台可视化建模展示:

评分卡模型主要有以下几个概念:
什么是评分卡(信贷场景中)
- 以分数的形式来衡量风险几率的一种手段
- 对未来一段时间内违约/逾期/失联概率的预测
- 通常评分越高越安全
- 根据使用场景分为反欺诈评分卡、申请评分卡、行为评分卡、催收评分卡
- 划分客群
为什么要开发评分卡
- 风险控制的一个环节,根据已有数据提供逾期概率指标参考
- 相比强控规则,可用性更强
评分卡的特性
- 稳定性
- 预测能力
- 等价于逾期概率
- 以分数的形式来衡量,这个分数主要根据客户的好坏比来确定;
- 是对未来一段时间内违约/逾期/失联概率的预测
- 有一个明确的正区间
- 通常分数越高越安全
- 数据驱动
- 主要的评分卡模型在互联网金融方面的表现形式是:申请评分卡、反欺诈评分卡、行为评分卡、催收评分卡。
其中申请评分卡、反欺诈评分卡使用在申请环节,行为评分卡使用在监控环节,催收评分卡使用在逾期管理环节。
评分卡开发的常用模型
- 逻辑回归
- 决策树
本文重点介绍申请评分卡暨A卡的实现逻辑
一、 数据准备
数据来自Kaggle的Give Me Some Credit,有15万条的样本数据,下图可以看到这份数据的大致情况。
数据属于个人消费类贷款,只考虑信用评分最终实施时能够使用到的数据应从如下一些方面获取数据:
– 基本属性:包括了借款人当时的年龄。
– 偿债能力:包括了借款人的月收入、负债比率。
– 信用往来:两年内35-59天逾期次数、两年内60-89天逾期次数、两年内90
天或高于90天逾期的次数。
– 财产状况:包括了开放式信贷和贷款数量、不动产贷款或额度数量。
– 贷款属性:暂无。
– 其他因素:包括了借款人的家属数量(不包括本人在内)。
– 时间窗口:自变量的观察窗口为过去两年,因变量表现窗口为未来两年。
| 循环信用贷使用率 | 年龄 | 30-59天不严重逾期次数 | 负债比率 | 月收入 | 贷款数量 | 90天逾期次数 | 不动产贷款数量 | 60-89天不严重逾期次数 | 家属数量 |
| RevolvingUtilizationOfUnsecuredLines | age | NumberOfTime30-59DaysPastDueNotWorse | DebtRatio | MonthlyIncome | NumberOfOpenCreditLinesAndLoans | NumberOfTimes90DaysLate | NumberRealEstateLoansOrLines | NumberOfTime60-89DaysPastDueNotWorse | NumberOfDependents |
| 0.766126609 | 45 | 2 | 0.802982129 | 9120 | 13 | 0 | 6 | 0 | 2 |
| 0.957151019 | 40 | 0 | 0.121876201 | 2600 | 4 | 0 | 0 | 0 | 1 |
| 0.65818014 | 38 | 1 | 0.085113375 | 3042 | 2 | 1 | 0 | 0 | 0 |
| 0.233809776 | 30 | 0 | 0.036049682 | 3300 | 5 | 0 | 0 | 0 | 0 |
| 0.9072394 | 49 | 1 | 0.024925695 | 63588 | 7 | 0 | 1 | 0 | 0 |
| 0.213178682 | 74 | 0 | 0.375606969 | 3500 | 3 | 0 | 1 | 0 | 1 |
| 0.305682465 | 57 | 0 | 5710 | NA | 8 | 0 | 3 | 0 | 0 |
| 0.754463648 | 39 | 0 | 0.209940017 | 3500 | 8 | 0 | 0 | 0 | 0 |
| 0.116950644 | 27 | 0 | 46 | NA | 2 | 0 | 0 | 0 | NA |
| 0.189169052 | 57 | 0 | 0.606290901 | 23684 | 9 | 0 | 4 | 0 | 2 |
| 0.644225962 | 30 | 0 | 0.30947621 | 2500 | 5 | 0 | 0 | 0 | 0 |
| 0.01879812 | 51 | 0 | 0.53152876 | 6501 | 7 | 0 | 2 | 0 | 2 |
| 0.010351857 | 46 | 0 | 0.298354075 | 12454 | 13 | 0 | 2 | 0 | 2 |
| 0.964672555 | 40 | 3 | 0.382964747 | 13700 | 9 | 3 | 1 | 1 | 2 |
| 0.019656581 | 76 | 0 | 477 | 0 | 6 | 0 | 1 | 0 | 0 |
| 0.548458062 | 64 | 0 | 0.209891754 | 11362 | 7 | 0 | 1 | 0 | 2 |
| 0.061086118 | 78 | 0 | 2058 | NA | 10 | 0 | 2 | 0 | 0 |
| 0.166284079 | 300 | 0 | 0.18827406 | 8800 | 7 | 0 | 0 | 0 | 0 |
二、 探索性数据分析
在建立模型之前,我们一般会对现有的数据进行 探索性数据分析(Exploratory Data Analysis) 。 EDA是指对已有的数据(特别是调查或观察得来的原始数据)在尽量少的先验假定下进行探索。常用的探索性数据分析方法有:直方图、散点图和箱线图等。
客户年龄分布如图4-1所示,可以看到年龄变量大致呈正态分布,符合统计分析的假设。
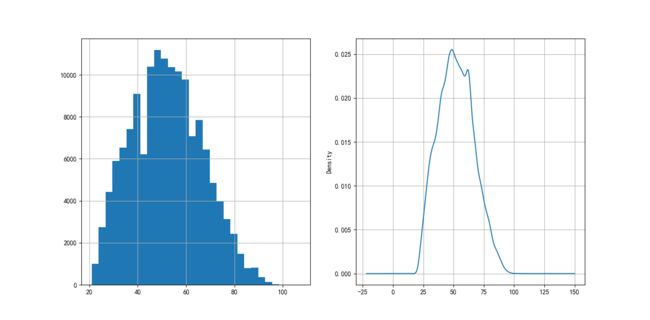 图2.1客户年龄
图2.1客户年龄
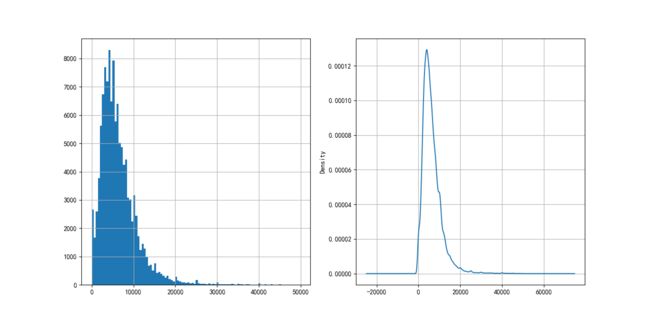 图2.2客户年收入
图2.2客户年收入
客户年龄、年收入分布如图2.1,2.2所示,大致呈正态分布,符合统计分析的需要。
三、 数据预处理
主要工作包括数据清洗、缺失值处理、异常值处理,排查各列数据,直接删除含有缺失值的样本;根据样本之间的相似性填补缺失值; 根据变量之间的相关关系填补缺失值。
比如MonthlyIncome:NA,age:300等数据
3.1 数据统计
在对数据处理之前,需要对数据的缺失值和异常值情况进行了解。Python内有describe()函数,可以了解数据集的缺失值、均值和中位数等,代码如下:
#载入数据
data = pd.read_csv('cs-training.csv')
#数据集确实和分布情况
data.describe().to_csv('DataDescribe.csv')数据集的详细情况:
|
|
SeriousDlqin2yrs |
RevolvingUtilizationOfUnsecuredLines |
age |
NumberOfTime30-59DaysPastDueNotWorse |
DebtRatio |
MonthlyIncome |
NumberOfOpenCreditLinesAndLoans |
NumberOfTimes90DaysLate |
NumberRealEstateLoansOrLines |
NumberOfTime60-89DaysPastDueNotWorse |
NumberOfDependents |
| count |
150000 |
150000 |
150000 |
150000 |
150000 |
120269 |
150000 |
150000 |
150000 |
150000 |
146076 |
| mean |
0.06684 |
6.048438055 |
52.29520667 |
0.421033333 |
353.0050758 |
6670.221237 |
8.45276 |
0.265973333 |
1.01824 |
0.240386667 |
0.757222268 |
| std |
0.249745531 |
249.7553706 |
14.77186586 |
4.192781272 |
2037.818523 |
14384.67422 |
5.14595099 |
4.169303788 |
1.129770985 |
4.155179421 |
1.115086071 |
| min |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
| 25% |
0 |
0.029867442 |
41 |
0 |
0.175073832 |
3400 |
5 |
0 |
0 |
0 |
0 |
| 50% |
0 |
0.154180737 |
52 |
0 |
0.366507841 |
5400 |
8 |
0 |
1 |
0 |
0 |
| 75% |
0 |
0.559046248 |
63 |
0 |
0.868253773 |
8249 |
11 |
0 |
2 |
0 |
1 |
| max |
1 |
50708 |
109 |
98 |
329664 |
3008750 |
58 |
98 |
54 |
98 |
20 |
count:总数;mean:均值;std:标准差;min:最小值;25%:四分之一分位数;50%:中位数;75%:四分之三分位数;max:最大值
从上可知,变量MonthlyIncome和NumberOfDependents存在缺失,变量MonthlyIncome共有缺失值29731个,NumberOfDependents有3924个缺失值。
3.2 缺失值处理
这种情况在现实问题中非常普遍,这会导致一些不能处理缺失值的分析方法无法应用,因此,在信用风险评级模型开发的第一步我们就要进行缺失值处理。缺失值处理的方法,包括如下几种。
(1) 直接删除含有缺失值的样本。
(2) 根据样本之间的相似性填补缺失值。
(3) 根据变量之间的相关关系填补缺失值。
变量MonthlyIncome缺失率比较大,所以我们根据变量之间的相关关系填补缺失值,我们采用随机森林法:
小贴士:
决策树:
举例:
数据:
| X1 | X2 | X3 | X4 | X5 | X6 | Y |
| 青绿 | 蜷缩 | 浊响 | 清晰 | 凹陷 | 硬滑 | 好瓜 |
| 乌黑 | 蜷缩 | 沉闷 | 清晰 | 凹陷 | 硬滑 | 好瓜 |
| 乌黑 | 蜷缩 | 浊响 | 清晰 | 凹陷 | 硬滑 | 好瓜 |
| 青绿 | 蜷缩 | 沉闷 | 清晰 | 凹陷 | 硬滑 | 好瓜 |
| 浅白 | 蜷缩 | 浊响 | 清晰 | 凹陷 | 硬滑 | 好瓜 |
| 青绿 | 稍蜷 | 浊响 | 清晰 | 稍凹 | 软粘 | 好瓜 |
| 乌黑 | 稍蜷 | 浊响 | 稍糊 | 稍凹 | 软粘 | 好瓜 |
| 乌黑 | 稍蜷 | 浊响 | 清晰 | 稍凹 | 硬滑 | 好瓜 |
| 乌黑 | 稍蜷 | 沉闷 | 稍糊 | 稍凹 | 硬滑 | 坏瓜 |
| 青绿 | 硬挺 | 清脆 | 清晰 | 平坦 | 软粘 | 坏瓜 |
| 浅白 | 硬挺 | 清脆 | 模糊 | 平坦 | 硬滑 | 坏瓜 |
| 浅白 | 蜷缩 | 浊响 | 模糊 | 平坦 | 软粘 | 坏瓜 |
| 青绿 | 稍蜷 | 浊响 | 稍糊 | 凹陷 | 硬滑 | 坏瓜 |
| 浅白 | 稍蜷 | 沉闷 | 稍糊 | 凹陷 | 硬滑 | 坏瓜 |
| 乌黑 | 稍蜷 | 浊响 | 清晰 | 稍凹 | 软粘 | 坏瓜 |
| 浅白 | 蜷缩 | 浊响 | 模糊 | 平坦 | 硬滑 | 坏瓜 |
| 青绿 | 蜷缩 | 沉闷 | 稍糊 | 稍凹 | 硬滑 | 坏瓜 |
原理参考:https://blog.csdn.net/weixin_44537194/article/details/88919114
随机森林:没搞懂
# 用随机森林对缺失值预测填充函数
def set_missing(df):
# 把已有的数值型特征取出来
process_df = df.ix[:,[5,0,1,2,3,4,6,7,8,9]]
# 分成已知该特征和未知该特征两部分
known = process_df[process_df.MonthlyIncome.notnull()].as_matrix()
unknown = process_df[process_df.MonthlyIncome.isnull()].as_matrix()
# X为特征属性值
X = known[:, 1:]
# y为结果标签值
y = known[:, 0]
# fit到RandomForestRegressor之中
rfr = RandomForestRegressor(random_state=0,
n_estimators=200,max_depth=3,n_jobs=-1)
rfr.fit(X,y)
# 用得到的模型进行未知特征值预测
predicted = rfr.predict(unknown[:, 1:]).round(0)
print(predicted)
# 用得到的预测结果填补原缺失数据
df.loc[(df.MonthlyIncome.isnull()), 'MonthlyIncome'] = predicted
return dfNumberOfDependents变量缺失值比较少,直接删除,对总体模型不会造成太大影响。对缺失值处理完之后,删除重复项。
data=set_missing(data)#用随机森林填补比较多的缺失值
data=data.dropna()#删除比较少的缺失值
data = data.drop_duplicates()#删除重复项
data.to_csv('MissingData.csv',index=False)3.3 异常值处理
缺失值处理完毕后,我们还需要进行异常值处理。异常值是指明显偏离大多数抽样数据的数值,比如个人客户的年龄为0时,通常认为该值为异常值。找出样本总体中的异常值,通常采用离群值检测的方法。
首先,我们发现变量age中存在0,显然是异常值,直接剔除:
# 年龄等于0的异常值进行剔除
data = data[data['age'] > 0]对于变量NumberOfTime30-59DaysPastDueNotWorse、NumberOfTimes90DaysLate、NumberOfTime60-89DaysPastDueNotWorse这三个变量,由下面的箱线图图3-2可以看出,均存在异常值,且由unique函数可以得知均存在96、98两个异常值,因此予以剔除。同时会发现剔除其中一个变量的96、98值,其他变量的96、98两个值也会相应被剔除。
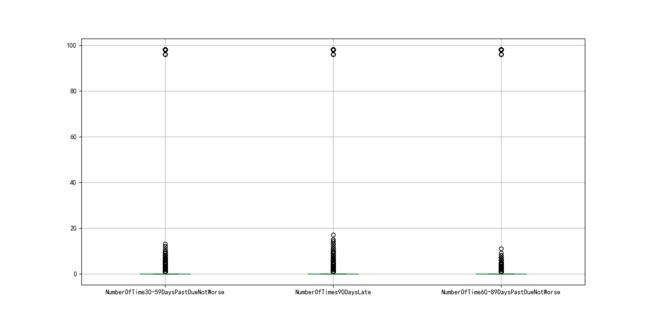
剔除变量NumberOfTime30-59DaysPastDueNotWorse、NumberOfTimes90DaysLate、NumberOfTime60-89DaysPastDueNotWorse的异常值。另外,数据集中好客户为0,违约客户为1,考虑到正常的理解,能正常履约并支付利息的客户为1,所以我们将其取反。
#剔除异常值
data = data[data['NumberOfTime30-59DaysPastDueNotWorse'] < 90]
#变量SeriousDlqin2yrs取反
data['SeriousDlqin2yrs']=1-data['SeriousDlqin2yrs']3.4 数据切分
为了验证模型的拟合效果,我们需要对数据集进行切分,分成训练集和测试集。
from sklearn.cross_validation import train_test_split
Y = data['SeriousDlqin2yrs']
X = data.ix[:, 1:]
#测试集占比30%
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.3, random_state=0)
# print(Y_train)
train = pd.concat([Y_train, X_train], axis=1)
test = pd.concat([Y_test, X_test], axis=1)
clasTest = test.groupby('SeriousDlqin2yrs')['SeriousDlqin2yrs'].count()
train.to_csv('TrainData.csv',index=False)
test.to_csv('TestData.csv',index=False)
四、 变量选择
该步骤主要是通过统计学的方法,筛选出对违约状态影响最显著的指标。主要有单变量特征选择方法和基于机器学习模型的方法 。特征变量选择(排序)对于数据分析、机器学习从业者来说非常重要。好的特征选择能够提升模型的性能,更能帮助我们理解数据的特点、底层结构,这对进一步改善模型、算法都有着重要作用。至于Python的变量选择代码实现可以参考结合Scikit-learn介绍几种常用的特征选择方法。在本文中,我们采用信用评分模型的变量选择方法,通过WOE分析方法,即是通过比较指标分箱和对应分箱的违约概率来确定指标是否符合经济意义。首先我们对变量进行离散化(分箱)处理。
4.1 分箱处理
变量分箱(binning)是对连续变量离散化(discretization)的一种称呼。信用评分卡开发中一般有常用的等距分段、等深分段、最优分段。其中等距分段(Equval length intervals)是指分段的区间是一致的,比如年龄以十年作为一个分段;等深分段(Equal frequency intervals)是先确定分段数量,然后令每个分段中数据数量大致相等;最优分段(Optimal Binning)又叫监督离散化(supervised discretizaion),使用递归划分(Recursive Partitioning)将连续变量分为分段,背后是一种基于条件推断查找较佳分组的算法。
分箱的意义,为什么要分箱:将特征变量统一,便于统一处理。
分箱的优点:
- 离散特征的增加和减少都很容易,易于模型的快速迭代;
- 稀疏向量内积乘法运算速度快,计算结果方便存储,容易扩展;
- 离散化后的特征对异常数据有很强的鲁棒性:比如一个特征是年龄>30是1,否则0。如果特征没有离散化,一个异常数据“年龄300岁”会给模型造成很大的干扰;
- 逻辑回归属于广义线性模型,表达能力受限;单变量离散化为N个后,每个变量有单独的权重,相当于为模型引入了非线性,能够提升模型表达能力,加大拟合;
- 离散化后可以进行特征交叉,由M+N个变量变为M*N个变量,进一步引入非线性,提升表达能力;
- 特征离散化后,模型会更稳定,比如如果对用户年龄离散化,20-30作为一个区间,不会因为一个用户年龄长了一岁就变成一个完全不同的人。当然处于区间相邻处的样本会刚好相反,所以怎么划分区间是门学问;
- 特征离散化以后,起到了简化了逻辑回归模型的作用,降低了模型过拟合的风险。
- 可以将缺失作为独立的一类带入模型。
- 将所有变量变换到相似的尺度上。
分箱的步骤:
- 我们首先把连续型变量分成一组数量较多的分类型变量,比如,将几万个样本分成100组,或50组;
- 确保每一组中都要包含两种类别的样本,否则IV值会无法计算
- 我们对相邻的组进行卡方检验,卡方检验的P值很大的组进行合并,直到数据中的组数小于设定的N箱为止
- 我们让一个特征分别分成[2,3,4.....20]箱,观察每个分箱个数下的IV值如何变化,找出最适合的分箱个数
- 分箱完毕后,我们计算每个箱的WOE值, bad%,观察分箱效果
- 这些步骤都完成后,我们可以对各个特征都进行分箱,然后观察每个特征的IV值,以此来挑选特征
- 我们首先选择对连续变量进行最优分段,在连续变量的分布不满足最优分段的要求时,再考虑对连续变量进行等距分段。最优分箱的代码如下:
# 定义自动分箱函数
def mono_bin(Y, X, n = 20):
r = 0
good=Y.sum()
bad=Y.count()-good
while np.abs(r) < 1:
d1 = pd.DataFrame({"X": X, "Y": Y, "Bucket": pd.qcut(X, n)})
d2 = d1.groupby('Bucket', as_index = True)
r, p = stats.spearmanr(d2.mean().X, d2.mean().Y)
n = n - 1
d3 = pd.DataFrame(d2.X.min(), columns = ['min'])
d3['min']=d2.min().X
d3['max'] = d2.max().X
d3['sum'] = d2.sum().Y
d3['total'] = d2.count().Y
d3['rate'] = d2.mean().Y
d3['woe']=np.log((d3['rate']/(1-d3['rate']))/(good/bad))
d4 = (d3.sort_index(by = 'min')).reset_index(drop=True)
print("=" * 60)
print(d4)
return d4针对我们将使用最优分段对于数据集中的RevolvingUtilizationOfUnsecuredLines、age、DebtRatio和MonthlyIncome进行分类。
针对不能最优分箱的变量,分箱如下:
# 连续变量离散化
cutx3 = [ninf, 0, 1, 3, 5, pinf]
cutx6 = [ninf, 1, 2, 3, 5, pinf]
cutx7 = [ninf, 0, 1, 3, 5, pinf]
cutx8 = [ninf, 0,1,2, 3, pinf]
cutx9 = [ninf, 0, 1, 3, pinf]
cutx10 = [ninf, 0, 1, 2, 3, 5, pinf]4.2 WOE
WoE分析, 是对指标分箱、计算各个档位的WoE值并观察WoE值随指标变化的趋势。其中WoE的数学定义是:
woe=ln(goodattribute/badattribute)
在进行分析时,我们需要对各指标从小到大排列,并计算出相应分档的WoE值。其中正向指标越大,WoE值越小;反向指标越大,WoE值越大。正向指标的WoE值负斜率越大,反响指标的正斜率越大,则说明指标区分能力好。WoE值趋近于直线,则意味指标判断能力较弱。若正向指标和WoE正相关趋势、反向指标同WoE出现负相关趋势,则说明此指标不符合经济意义,则应当予以去除。
4.3 相关性分析和IV筛选
接下来,我们会用经过清洗后的数据看一下变量间的相关性。注意,这里的相关性分析只是初步的检查,进一步检查模型的VI(证据权重)作为变量筛选的依据。
相关性图我们通过Python里面的seaborn包,调用heatmap()绘图函数进行绘制,实现代码如下:
corr = data.corr()#计算各变量的相关性系数
xticks = ['x0','x1','x2','x3','x4','x5','x6','x7','x8','x9','x10']#x轴标签
yticks = list(corr.index)#y轴标签
fig = plt.figure()
ax1 = fig.add_subplot(1, 1, 1)
sns.heatmap(corr, annot=True, cmap='rainbow', ax=ax1, annot_kws={'size': 9, 'weight': 'bold', 'color': 'blue'})#绘制相关性系数热力图
ax1.set_xticklabels(xticks, rotation=0, fontsize=10)
ax1.set_yticklabels(yticks, rotation=0, fontsize=10)
plt.show()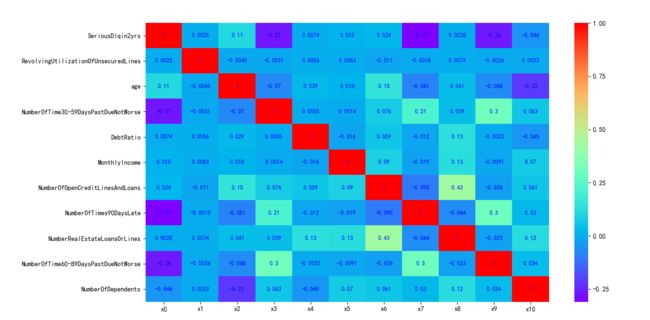
由上图可以看出,各变量之间的相关性是非常小的。NumberOfOpenCreditLinesAndLoans和NumberRealEstateLoansOrLines的相关性系数为0.43。
接下来,我进一步计算每个变量的Infomation Value(IV)。IV指标是一般用来确定自变量的预测能力。 其公式为:
IV=sum((goodattribute-badattribute)*ln(goodattribute/badattribute))
通过IV值判断变量预测能力的标准是:
< 0.02: 无预测性,该特征可以删除
0.02 to 0.1: 弱预测性
0.1 to 0.3: 中等
0.3 to 0.5: 强
> 0.5: 难以置信,需确认

IV值计算代码如下:
# 定义自动分箱函数
def mono_bin(Y, X, n = 20):
r = 0
good=Y.sum()
bad=Y.count()-good
while np.abs(r) < 1:
d1 = pd.DataFrame({"X": X, "Y": Y, "Bucket": pd.qcut(X, n)})
d2 = d1.groupby('Bucket', as_index = True)
r, p = stats.spearmanr(d2.mean().X, d2.mean().Y)
n = n - 1
d3 = pd.DataFrame(d2.X.min(), columns = ['min'])
d3['min']=d2.min().X
d3['max'] = d2.max().X
d3['sum'] = d2.sum().Y
d3['total'] = d2.count().Y
d3['rate'] = d2.mean().Y
d3['woe']=np.log((d3['rate']/(1-d3['rate']))/(good/bad))
d3['goodattribute']=d3['sum']/good
d3['badattribute']=(d3['total']-d3['sum'])/bad
iv=((d3['goodattribute']-d3['badattribute'])*d3['woe']).sum()
d4 = (d3.sort_index(by = 'min')).reset_index(drop=True)
print("=" * 60)
print(d4)
cut=[]
cut.append(float('-inf'))
for i in range(1,n+1):
qua=X.quantile(i/(n+1))
cut.append(round(qua,4))
cut.append(float('inf'))
woe=list(d4['woe'].round(3))
return d4,iv,cut,woe
IV图生成代码:
ivlist=[ivx1,ivx2,ivx3,ivx4,ivx5,ivx6,ivx7,ivx8,ivx9,ivx10]#各变量IV
index=['x1','x2','x3','x4','x5','x6','x7','x8','x9','x10']#x轴的标签
fig1 = plt.figure(1)
ax1 = fig1.add_subplot(1, 1, 1)
x = np.arange(len(index))+1
ax1.bar(x, ivlist, width=0.4)#生成柱状图
ax1.set_xticks(x)
ax1.set_xticklabels(index, rotation=0, fontsize=12)
ax1.set_ylabel('IV(Information Value)', fontsize=14)
#在柱状图上添加数字标签
for a, b in zip(x, ivlist):
plt.text(a, b + 0.01, '%.4f' % b, ha='center', va='bottom', fontsize=10)
plt.show()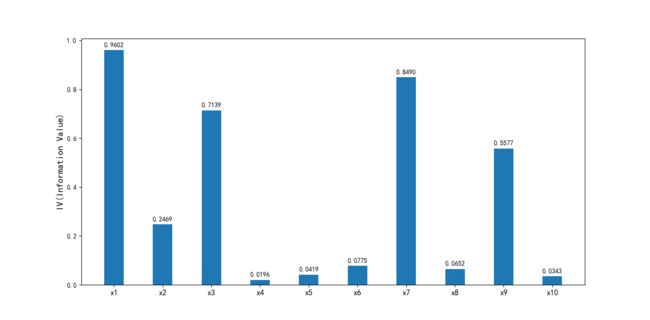
可以看出,DebtRatio、MonthlyIncome、NumberOfOpenCreditLinesAndLoans、NumberRealEstateLoansOrLines和NumberOfDependents变量的IV值明显较低,所以予以删除。
五、 模型开发
该步骤主要包括变量分段、变量的WOE(证据权重)变换和逻辑回归估算三部分
证据权重(Weight of Evidence,WOE)转换可以将Logistic回归模型转变为标准评分卡格式。引入WOE转换的目的并不是为了提高模型质量,只是一些变量不应该被纳入模型,这或者是因为它们不能增加模型值,或者是因为与其模型相关系数有关的误差较大,其实建立标准信用评分卡也可以不采用WOE转换。这种情况下,Logistic回归模型需要处理更大数量的自变量。尽管这样会增加建模程序的复杂性,但最终得到的评分卡都是一样的。
在建立模型之前,我们需要将筛选后的变量转换为WoE值,便于信用评分。
5.1 WOE转换
我们已经能获取了每个变量的分箱数据和woe数据,只需要根据各变量数据进行替换,并将每个变量都进行替换,并将其保存到WoeData.csv文件中,实现代码如下:
#替换成woe函数
def replace_woe(series,cut,woe):
list=[]
i=0
while i=0:
if value>=cut[j]:
j=-1
else:
j -=1
m -= 1
list.append(woe[m])
i += 1
return list
# 替换成woe
data['RevolvingUtilizationOfUnsecuredLines'] = Series(replace_woe(data['RevolvingUtilizationOfUnsecuredLines'], cutx1, woex1))
data['age'] = Series(replace_woe(data['age'], cutx2, woex2))
data['NumberOfTime30-59DaysPastDueNotWorse'] = Series(replace_woe(data['NumberOfTime30-59DaysPastDueNotWorse'], cutx3, woex3))
data['DebtRatio'] = Series(replace_woe(data['DebtRatio'], cutx4, woex4))
data['MonthlyIncome'] = Series(replace_woe(data['MonthlyIncome'], cutx5, woex5))
data['NumberOfOpenCreditLinesAndLoans'] = Series(replace_woe(data['NumberOfOpenCreditLinesAndLoans'], cutx6, woex6))
data['NumberOfTimes90DaysLate'] = Series(replace_woe(data['NumberOfTimes90DaysLate'], cutx7, woex7))
data['NumberRealEstateLoansOrLines'] = Series(replace_woe(data['NumberRealEstateLoansOrLines'], cutx8, woex8))
data['NumberOfTime60-89DaysPastDueNotWorse'] = Series(replace_woe(data['NumberOfTime60-89DaysPastDueNotWorse'], cutx9, woex9))
data['NumberOfDependents'] = Series(replace_woe(data['NumberOfDependents'], cutx10, woex10))
data.to_csv('WoeData.csv', index=False) 5.2 Logisic模型建立
我们直接调用statsmodels包来实现逻辑回归:
导入数据
data = pd.read_csv('WoeData.csv')
#应变量
Y=data['SeriousDlqin2yrs']
#自变量,剔除对因变量影响不明显的变量
X=data.drop(['SeriousDlqin2yrs','DebtRatio','MonthlyIncome', 'NumberOfOpenCreditLinesAndLoans','NumberRealEstateLoansOrLines','NumberOfDependents'],axis=1)
X1=sm.add_constant(X)
logit=sm.Logit(Y,X1)
result=logit.fit()
print(result.summary())
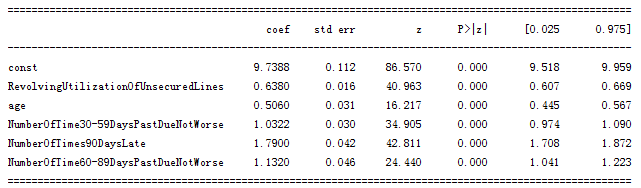
通过上图可知,逻辑回归各变量都已通过显著性检验,满足要求。
七、模型评估
该步骤主要是评估模型的区分能力(KS)、预测能力(ROC)、稳定性(PSI),并形成模型评估报告,得出模型是否可以使用的结论,评估指标说明:
- ROC
x轴为FPR,y轴为TPR - k-s指标
x为RPP,y为TPR-FPR
RPP=(TP+FP)/(FP+TP+FN+TN) - 洛伦兹图
x为RPP,y为TPR - lift图:
lift=PV/K ;
K=(TP+FN)/(FP+TP+FN+TN)
PV=TP/(TP+FP)
x轴为RPP,y轴为Lift - gini系数
x为TNR,y为FNR
GINI=2*AUC-1 - 群体稳定性
PSI计算公式为:
sum(实际占比-预期占比)*ln(实际占比/预期占比)
PSI小于0.1稳定性较好 - 特征稳定性:CSI
7.1 ROC-AUC
ROC:ROC曲线及AUC系数主要用来检验模型对客户进行正确排序的能力。ROC曲线描述了在一定累计好客户比例下的累计坏客户的比例,模型的分别能力越强,ROC曲线越往左上角靠近。AUC系数表示ROC曲线下方的面积。AUC系数越高,模型的风险区分能力越强。
AUC(Area Under Curve):ROC曲线下与坐标轴围成的面积,显然这个面积的数值不会大于1
7.1.1 混淆矩阵
混淆矩阵是用来总结一个分类器结果的矩阵。对于k元分类,其实它就是一个k x k的表格,用来记录分类器的预测结果。
对于最常见的二元分类来说,它的混淆矩阵是2乘2的,如下:

TP = True Postive = 真阳性; FP = False Positive = 假阳性
FN = False Negative = 假阴性; TN = True Negative = 真阴性
比如我们一个模型对15个样本进行预测,然后结果如下。
真实值:0 1 1 0 1 1 0 0 1 0 1 0 1 0 0
预测值:1 1 1 1 1 0 0 0 0 0 1 1 1 0 1

- 精度(precision, 或者PPV, positive predictive value) = TP / (TP + FP)
在上面的例子中,精度 = 5 / (5+4) = 0.556
- 召回(recall, 或者敏感度,sensitivity,真阳性率,TPR,True Positive Rate) = TP / (TP + FN)
在上面的例子中,召回 = 5 / (5+2) = 0.714
- 特异度(specificity,或者真阴性率,TNR,True Negative Rate) = TN / (TN + FP)
在上面的例子中,特异度 = 4 / (4+2) = 0.667
- F1-值(F1-score) = 2*TP / (2*TP+FP+FN)
在上面的例子中,F1-值 = 2*5 / (2*5+4+2) = 0.625
- TPR:在所有实际为阳性的样本中,被正确地判断为阳性之比率。TPR=TP/(TP+FN)
- FPR:在所有实际为阴性的样本中,被错误地判断为阳性之比率。FPR=FP/(FP+TN)
7.2 ROC
放在具体领域来理解上述两个指(TPR、FPR)。如在医学诊断中,判断有病的样本。那么尽量把有病的揪出来是主要任务,也就是第一个指标TPR,要越高越好。而把没病的样本误诊为有病的,也就是第二个指标FPR,要越低越好。不难发现,这两个指标之间是相互制约的。如果某个医生对于有病的症状比较敏感,稍微的小症状都判断为有病,那么他的第一个指标应该会很高,但是第二个指标也就相应地变高。最极端的情况下,他把所有的样本都看做有病,那么第一个指标达到1,第二个指标也为1。
我们以FPR为横轴,TPR为纵轴,得到如下ROC空间:

我们可以看出:左上角的点(TPR=1,FPR=0),为完美分类,也就是这个医生医术高明,诊断全对;点A(TPR>FPR),医生A的判断大体是正确的。中线上的点B(TPR=FPR),也就是医生B全都是蒙的,蒙对一半,蒙错一半;下半平面的点C(TPR 上图中一个阈值,得到一个点。现在我们需要一个独立于阈值的评价指标来衡量这个医生的医术如何,也就是遍历所有的阈值,得到ROC曲线。还是一开始的那幅图,假设如下就是某个医生的诊断统计图,直线代表阈值。我们遍历所有的阈值,能够在ROC平面上得到如下的ROC曲线。 曲线距离左上角越近,证明分类器效果越好。 如上,是三条ROC曲线,在0.23处取一条直线。那么,在同样的FPR=0.23的情况下,红色分类器得到更高的TPR。也就表明,ROC越往上,分类器效果越好。我们用一个标量值AUC来量化他。 AUC值为ROC曲线所覆盖的区域面积,显然,AUC越大,分类器分类效果越好。 AUC = 1,是完美分类器,采用这个预测模型时,不管设定什么阈值都能得出完美预测。绝大多数预测的场合,不存在完美分类器。 0.5 < AUC < 1,优于随机猜测。这个分类器(模型)妥善设定阈值的话,能有预测价值。 AUC = 0.5,跟随机猜测一样(例:丢铜板),模型没有预测价值。 AUC < 0.5,比随机猜测还差;但只要总是反预测而行,就优于随机猜测。 假设分类器的输出是样本属于正类的socre(置信度),则AUC的物理意义为,任取一对(正、负)样本,正样本的score大于负样本的score的概率。 (1)第一种方法:AUC为ROC曲线下的面积,那我们直接计算面积可得。面积为一个个小的梯形面积之和,计算的精度与阈值的精度有关。 (2)第二种方法:根据AUC的物理意义,我们计算正样本score大于负样本的score的概率。取N*M(N为正样本数,M为负样本数)个二元组,比较score,最后得到AUC。时间复杂度为O(N*M)。 (3)第三种方法:与第二种方法相似,直接计算正样本score大于负样本的score的概率。我们首先把所有样本按照score排序,依次用rank表示他们,如最大score的样本,rank=n(n=N+M),其次为n-1。那么对于正样本中rank最大的样本(rank_max),有M-1个其他正样本比他score小,那么就有(rank_max-1)-(M-1)个负样本比他score小。其次为(rank_second-1)-(M-2)。最后我们得到正样本大于负样本的概率为: 计算代码: 定义:是在模型中用去区分尝试正负样本分隔程度的评价指标,值衡量的是好坏样本累计各部分之间的差值,好坏样本累计差异越大,KS指标越大。那么模型的风险区分能力越强,K-S=max|(TPR-FPR)| KS取值范围是【0,1】。通常来说,值越大,表明正负样本区分的程度越好。但并非所有情况都是KS越高越好。 在模型构建初期KS基本要满足在0.3以上。后续模型监测期间,如果KS持续下降恶化,就要考虑是市场发生了变化所致,或者是客群发生了偏移,或者是评分卡模型不够稳定,或者是评分卡内的某个特征变量发生重大变化所致。 如果KS下降至阈值之下,而无法通过重新训练模型进行修正的话,就要考虑上新的评分卡模型代替旧的版本。 不仅评分卡模型整体分数要进行KS的监测,模型内的每个特征变量同样要进行KS监测,这样就能立即发现究竟是模型整体发生恶化,还是单一某个特征变量区分能力在恶化。如果仅仅是单一某个特征变量区分能力在恶化的话,可以考虑更换特征变量或者剔除特征变量的方法进行修正。 征信模型中,最期望得到的信用分数分布是正态分布,对于正负样本分别而言,也都是期望呈正态分布的样子。如果KS值过大,一般超过0.9,就可以认为正负样本分的过开了。不太可能是正态分布,反而是比较极端化的分布状态(U字形,两边多,中间少),这样的分数就不很好,基本可以认为不可用。 但如果模式的目的就是完美区分正负样本,那么KS值越大就表明分隔能力越突出。另外,KS值所代表的仅仅是模型的分隔能力,并不代表样本是准确的。换句话说,正负样本完全分错,但KS值可以依然很高。 到这里,我们的建模部分基本结束了。我们需要验证一下模型的预测能力如何。我们使用在建模开始阶段预留的test数据进行检验。通过ROC曲线和AUC来评估模型的拟合能力。 从上图可知,AUC值为0.85,说明该模型的预测效果还是不错的,正确率较高。 参考:https://zhuanlan.zhihu.com/p/79682292 在风控中,稳定性压倒一切。原因在于,一套风控模型正式上线运行后往往需要很久(通常一年以上)才会被替换下线。如果模型不稳定,意味着模型不可控,对于业务本身而言就是一种不确定性风险,直接影响决策的合理性。这是不可接受的。 本文将从稳定性的直观理解、群体稳定性指标(Population Stability Index,PSI)的计算逻辑、PSI背后的含义等多维度展开分析。 如果你有基础的风控建模经验,想必会很熟悉PSI(Population Stability Index)指标。PSI反映了验证样本在各分数段的分布与建模样本分布的稳定性。在建模中,我们常用来筛选特征变量、评估模型稳定性。 那么,PSI的计算逻辑是怎样的呢?很多博客文章都会直接告诉我们,稳定性是有参照的,因此需要有两个分布——实际分布(actual)和预期分布(expected)。其中,在建模时通常以训练样本(In the Sample, INS)作为预期分布,而验证样本通常作为实际分布。验证样本一般包括样本外(Out of Sample,OOS)和跨时间样本(Out of Time,OOT)。 我们从直觉上理解,是不是可以把两个分布重叠放在一起,比较下两个分布的差异有多大? PSI的计算公式:PSI = SUM( (实际占比 - 预期占比)* ln(实际占比 / 预期占比) ) 我们已经基本完成了建模相关的工作,并用ROC曲线验证了模型的预测能力。接下来的步骤,就是将Logistic模型转换为标准评分卡的形式。 个人总评分=基础分+各部分得分 面计算各变量部分的分数,计算各变量得分情况,各部分得分函数: 我们可以得到各部分的评分卡如图7-1所示: 批量计算的部分分结果: 本文通过对kaggle上的Give Me Some Credit数据的挖掘分析,结合信用评分卡的建立原理,从数据的预处理、变量选择、建模分析到创建信用评分,创建了一个简单的信用评分系统。

7.3 AUC
7.3.1 AUC值的定义
7.3.2 AUC值的物理意义
7.3.3 AUC值的计算
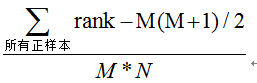
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import itertools
from sklearn.metrics import auc
%matplotlib inline
#测试样本的数量
parameter=40
data=pd.DataFrame(index=range(0,parameter),columns=('probability','The true label'))
data['The true label']=np.random.randint(0,2,size=len(data))
data['probability']=np.random.choice(np.arange(0.1,1,0.1),len(data['probability']))
cm=np.arange(4).reshape(2,2)
cm[0,0]=len(data[data['The ture label']==0][data['probability']<0.5])
#TN
cm[0,1]=len(data[data['The ture label']==0][data['probability']>=0.5])#FP
cm[1,0]=len(data[data['The ture label']==1][data['probability']<0.5]) #FN
cm[1,1]=len(data[data['The ture label']==1][data['probability']>=0.5])#TP
classes = [0,1]
plt.figure()
plt.imshow(cm, interpolation='nearest', cmap=plt.cm.Blues)
plt.title('Confusion matrix')
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=0)
plt.yticks(tick_marks, classes)
thresh = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, cm[i, j],
horizontalalignment="center",
color="white" if cm[i, j] > thresh else "black")
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
data.sort_values('probability',inplace=True,ascending=False)
TPRandFPR=pd.DataFrame(index=range(len(data)),columns=('TP','FP'))
for j in range(len(data)):
data1=data.head(n=j+1)
FP=len(data1[data1['The ture label']==0] [data1['probability']>=data1.head(len(data1))['probabi lity']])
/float(len(data[data['The ture label']==0]))
TP=len(data1[data1['The ture label']==1][data1['probability']>=data1.head(len(data1))['probability']])
/float(len(data[data['The ture label']==1]))
TPRandFPR.iloc[j]=[TP,FP]
AUC= auc(TPRandFPR['FP'],TPRandFPR['TP'])
plt.scatter(x=TPRandFPR['FP'],y=TPRandFPR['TP'],label='(FPR,TPR)',color='k')
plt.plot(TPRandFPR['FP'], TPRandFPR['TP'], 'k',label='AUC = %0.2f'% AUC)
plt.legend(loc='lower right')
plt.title('Receiver Operating Characteristic')
plt.plot([(0,0),(1,1)],'r--')
plt.xlim([-0.01,1.01])
plt.ylim([-0.01,01.01])
plt.ylabel('True Positive Rate')
plt.xlabel('False Positive Rate')
plt.show()7.4 K-S
ks值
含义
> 0.3
模型预测性较好
0,2~0.3
模型可用
0~0.2
模型预测能力较差
< 0
模型错误

在Python中,可以利用sklearn.metrics,它能方便比较两个分类器,自动计算ROC和AUC。
实现代码: #应变量
Y_test = test['SeriousDlqin2yrs']
#自变量,剔除对因变量影响不明显的变量,与模型变量对应
X_test = test.drop(['SeriousDlqin2yrs', 'DebtRatio', 'MonthlyIncome', 'NumberOfOpenCreditLinesAndLoans','NumberRealEstateLoansOrLines', 'NumberOfDependents'], axis=1)
X3 = sm.add_constant(X_test)
resu = result.predict(X3)#进行预测
fpr, tpr, threshold = roc_curve(Y_test, resu)
rocauc = auc(fpr, tpr)#计算AUC
plt.plot(fpr, tpr, 'b', label='AUC = %0.2f' % rocauc)#生成ROC曲线
plt.legend(loc='lower right')
plt.plot([0, 1], [0, 1], 'r--')
plt.xlim([0, 1])
plt.ylim([0, 1])
plt.ylabel('真正率')
plt.xlabel('假正率')
plt.show()7.5 PSI

八、建立评分系统,根据信用评分方法,建立自动信用评分系统。


依据以上论文资料得到:
a=log(p_good/P_bad)
Score = offset + factor * log(odds)
在建立标准评分卡之前,我们需要选取几个评分卡参数:基础分值、 PDO(比率翻倍的分值)和好坏比。 这里, 我们取600分为基础分值,PDO为20 (每高20分好坏比翻一倍),好坏比取20。 # 我们取600分为基础分值,PDO为20(每高20分好坏比翻一倍),好坏比取20。
p = 20 / math.log(2)
q = 600 - 20 * math.log(20) / math.log(2)
baseScore = round(q + p * coe[0], 0)
#计算分数函数
def get_score(coe,woe,factor):
scores=[]
for w in woe:
score=round(coe*w*factor,0)
scores.append(score)
return scores
# 各项部分分数
x1 = get_score(coe[1], woex1, p)
x2 = get_score(coe[2], woex2, p)
x3 = get_score(coe[3], woex3, p)
x7 = get_score(coe[4], woex7, p)
x9 = get_score(coe[5], woex9, p)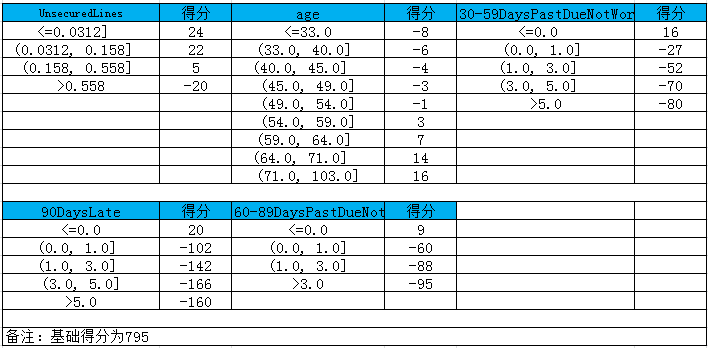
#根据变量计算分数
def compute_score(series,cut,score):
list = []
i = 0
while i < len(series):
value = series[i]
j = len(cut) - 2
m = len(cut) - 2
while j >= 0:
if value >= cut[j]:
j = -1
else:
j -= 1
m -= 1
list.append(score[m])
i += 1
return list
test1 = pd.read_csv('TestData.csv')
test1['BaseScore']=Series(np.zeros(len(test1)))+baseScore
test1['x1'] = Series(compute_score(test1['RevolvingUtilizationOfUnsecuredLines'], cutx1, x1))
test1['x2'] = Series(compute_score(test1['age'], cutx2, x2))
test1['x3'] = Series(compute_score(test1['NumberOfTime30-59DaysPastDueNotWorse'], cutx3, x3))
test1['x7'] = Series(compute_score(test1['NumberOfTimes90DaysLate'], cutx7, x7))
test1['x9'] = Series(compute_score(test1['NumberOfTime60-89DaysPastDueNotWorse'], cutx9, x9))
test1['Score'] = test1['x1'] + test1['x2'] + test1['x3'] + test1['x7'] +test1['x9'] + baseScore
test1.to_csv('ScoreData.csv', index=False)
SeriousDlqin2yrs
RevolvingUtilizationOfUnsecuredLines
age
NumberOfTime30-59DaysPastDueNotWorse
DebtRatio
MonthlyIncome
NumberOfOpenCreditLinesAndLoans
NumberOfTimes90DaysLate
NumberRealEstateLoansOrLines
NumberOfTime60-89DaysPastDueNotWorse
NumberOfDependents
BaseScore
x1
x2
x3
x7
x9
Score
1
0.617351763
41
4
0.167588827
15000
14
1
1
0
2
795
-20
-4
-70
-142
-60
499
1
0.084175501
58
0
0.388850795
14583
12
0
3
0
1
795
22
3
-27
-102
-60
631
1
0.307757394
47
0
0.181313158
18900
10
0
2
0
3
795
5
-3
-27
-102
-60
608
1
0.003265195
65
0
0.304615897
6000
6
0
2
0
0
795
24
14
-27
-102
-60
644
1
0.018516603
38
0
5870
2554
6
0
1
0
0
795
24
-6
-27
-102
-60
624
1
0.032119358
80
0
1020
2554
7
0
1
0
0
795
22
16
-27
-102
-60
644
1
0.9999999
48
0
1.152802571
2800
6
0
2
0
2
795
-20
-3
-27
-102
-60
583
1
0.199732383
66
0
0.319950777
6500
10
0
1
0
0
795
5
14
-27
-102
-60
625
1
0.037981203
50
0
0.710292667
3040
7
0
1
0
1
795
22
-1
-27
-102
-60
627
1
0.23648522
37
0
0.249862652
9100
7
0
2
0
3
795
5
-6
-27
-102
-60
605
九、总结以及展望
基于AI 的机器学习评分卡系统可通过把旧数据(某个时间点后,例如2年)剔除掉后再进行自动建模、模型评估、并不断优化特征变量,使得系统更加强大。