Elasticsearch使用系列-ES简介和环境搭建
Elasticsearch使用系列-ES增删查改基本操作+ik分词
Elasticsearch使用系列-基本查询和聚合查询+sql插件
Elasticsearch使用系列-.NET6对接Elasticsearch
一、安装可视化工具Kibana
ES是一个NoSql数据库应用。和其他数据库一样,我们为了方便操作查看它,需要安装一个可视化工具 Kibana。
官网:https://www.elastic.co/cn/downloads/kibana

和前面安装ES一样,选中对应的环境下载,这里选择windows环境,注意安装的版本一定要和ES的版本一致,不然可能会启动不起来。
解压后进到config目录下修改kibana.yml配置文件


修改完配置,进入bin目录,双击 kibana.bat 文件启动。
启动后,打开kibana地址:http://localhost:5601/ ,出现下面界面就是安装成功了。
点自己浏览进入下面
点开发工具进入操作ES的界面,我们ES就在下面界面操作。
二、ES数据结构和数据类型
1.ES数据结构
这里以Mysql作对比,ES7.0以前的结构是Index,Type,Document,ES7.0以后废弃了Type,现在ES和Mysql的结构对比如下
| MySql | Elasitcsearch |
| database(数据库) | Elasitcsearch(实例) |
| table(表) | index(索引) |
| row(行) | document(文档) |
| column(列) | field(字段) |
2.ES数据类型
- 字符串:text,keyword (重点类型)
- 数值:long,integer,short,byte,double,float,half float,scaled float
- 日期类型:date
- 布尔类型:boolean
- 二进制类型:binary
- 等等。。。
这里的数据类型标红的是ES的重点类型,其它的和平时开发的类型一样,没什么特别。
三、ES的增删查改基本操作
| 请求方式 | url地址 | 描述 |
| PUT | http://localhost:9200/索引名称 | 创建索引 |
| POST | http://local | |
1.创建索引,相当于数据库创建表
PUT index


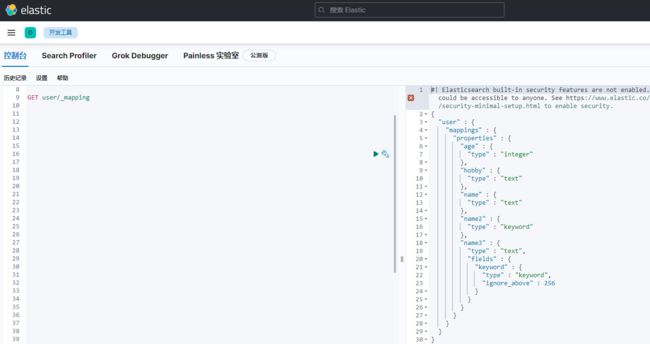
PUT user { "mappings" : { "properties" : { "age" : { "type" : "integer" }, "name" : { "type" : "text" }, "name2" : { "type" : "keyword" }, "name3" : { "type" : "text", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 256 } } }, "hobby" : { "type" : "text" } } } }

这里说一下kibana执行的原理,kibana执行的是http请求,前面的PUT为请求方式,还有POST,GET等,后面的user是索引名称,因为kibana配置了es的信息,
所以会自动带上es的地址和端口,实际的请求为 PUT http://192.168.101.13:9200/user
查看索引字段信息
GET index
2.创建文档,相当于数据库插入数据记录
POST index/_doc/id (index:索引名称,_doc:固定,id:指定记录id,不填会自动生成一个唯一id)

4.查询
4.1查询全部
GET index/_search

4.2按条件查询
GET user/_search { "query": { "term": { "FIELD": { "value": "VALUE" } } } }
5.更新
对应sql语句:update user set age=19 where id=1
_doc,doc,_update:固定写法

6.删除
6.1删除文档(相当于删除一条数据)
对应sql语句: delete from user where id=1
DELETE user/_doc/1
6.2删除索引(相当于删除表)
对应sql语句:drop table user
DELETE user
四、全文索引和ik分词
1.全文索引

创建索引的时候我上面故意创建了name(text),name1(keyword),name2(text+keyword),然后数据类型也说了text,keyword是ES的重点类型,这里演示他们的区别。
- keyword类型:查询时条件只能全匹配
- text类型:全文索引查询,查询时会先分词,然后用分词去匹配查询
- keyword+text类型,一个字段两种类型,可以全匹配,也可以全文索引查询
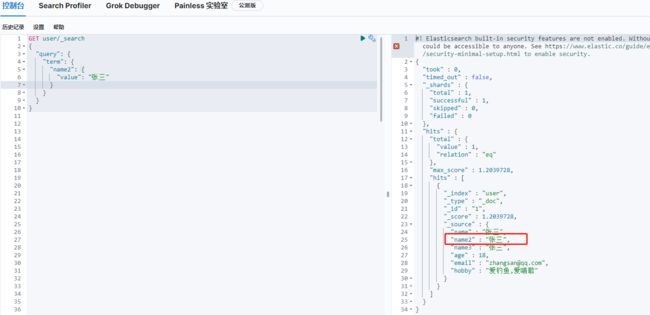
keyword查询例子,name2(keyword)的查询:
keyword的查询用term,或terms(配置多个值)


因为是全匹配,条件”张三“查到数据,条件”张“时查不到数据。
text查询例子,name(text)的查询
text的查询用match
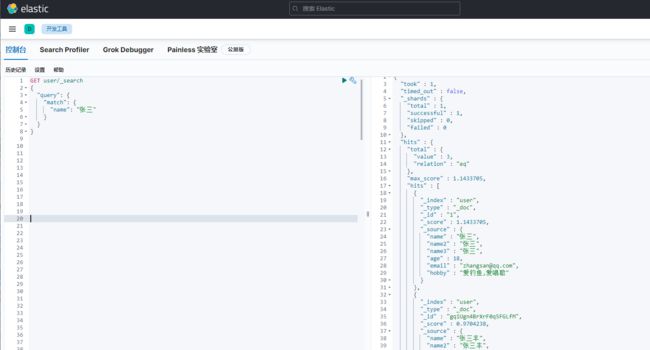
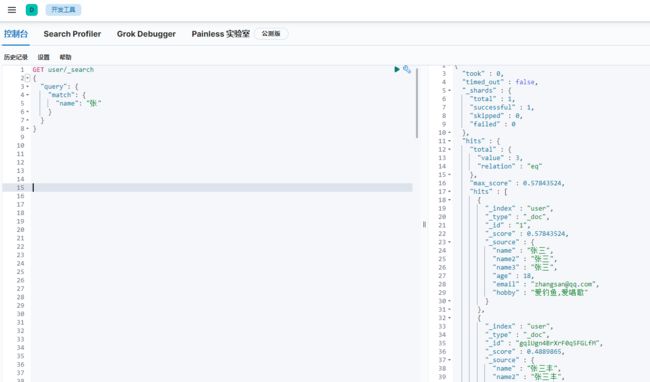
因为是全文索引分词匹配,所以条件“张三”和条件“张”的,都把匹配到的数据都查询出来了。
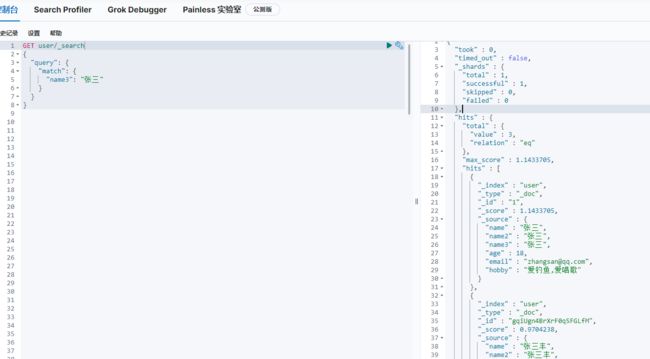
keyword+text查询例子,name3(text+keyword)的查询。
当只想查全匹配时,用term查询

当想用全文索引查询时,用match
2.ik分词
1.什么是分词?

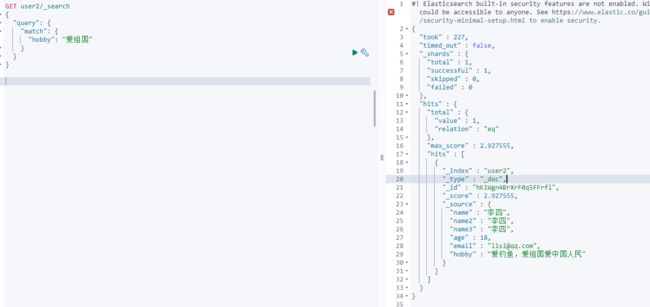
我搜的是爱祖国,为什么,“爱钓鱼,爱唱歌"的都被搜出来了呢?
因为ES默认内置了一个分词器standard,看下这个分词器的分词结果
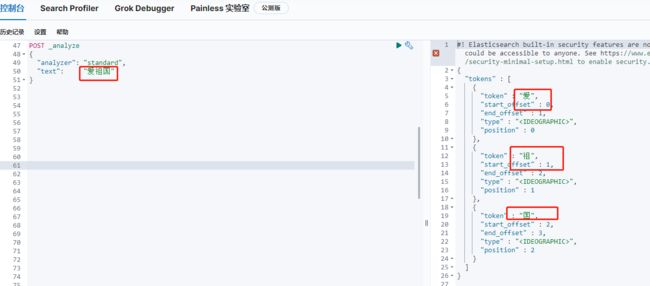
可以看到“爱祖国”的分词结果为“爱,祖,国”,被拆分成了单个字,只要一个字匹配到就查出来,这样的结果很多不是我们想要的。我们需要一款根据常用词语的分词器,这样查到的结果会更准确,
这里就用到了ik分词,ik分词也是企业开发用的最多的。
2.ik分词器插件安装
官网下载:https://github.com/medcl/elasticsearch-analysis-ik/releases
下载的版本要和es一致。

把文件下载后,解压复制到es部署文件的plugins文件夹下,并把文件夹的名称改为ik,必须要叫ik。windows,linux,docker(docker为挂载文件夹的方式把文件映射进去)一样,
然后重启es即可生效。
再看一下用ik分词器的分词结果。
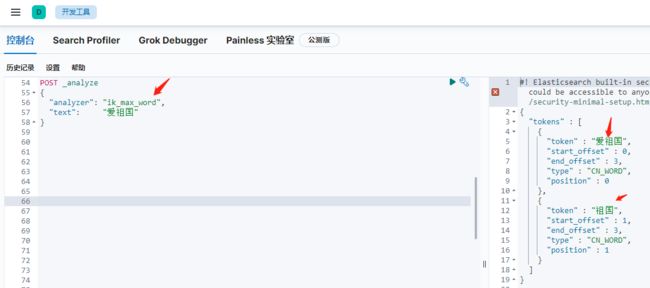
可以看到,已经是按常用词语分词了。
3.自定义词组
上面“爱祖国”,被分成“爱祖国,祖国”,假如我想“爱组”也是一个词,现在这个词没被收怎么办?
打开刚才的ik文件夹下的config目录
里面的.dic结尾的都是分词,打开其中一个看一下。
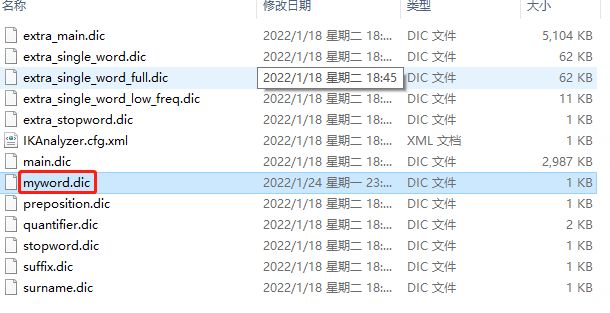
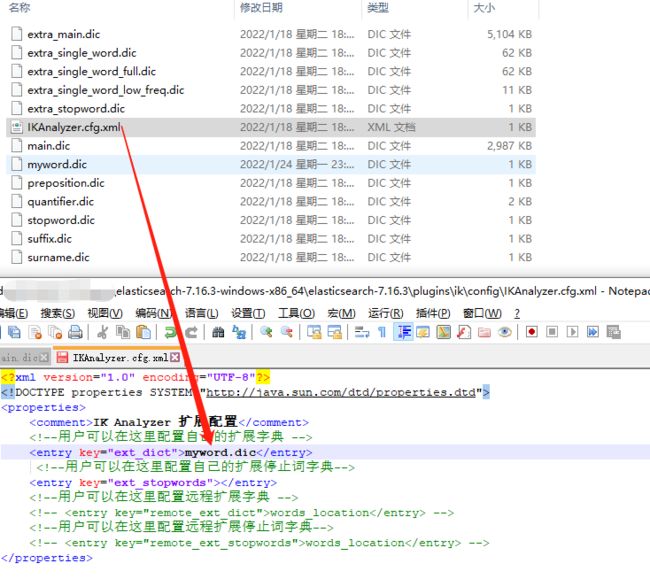
所以我们要自定义词语,可以新建一个myword.dic
里面写上想要的分词
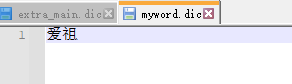
然后在IKAnalyzer.cfg.xml文件加上刚才的文件名
重启es,再看一下分词结果。

4.ik分词怎么在索引中使用
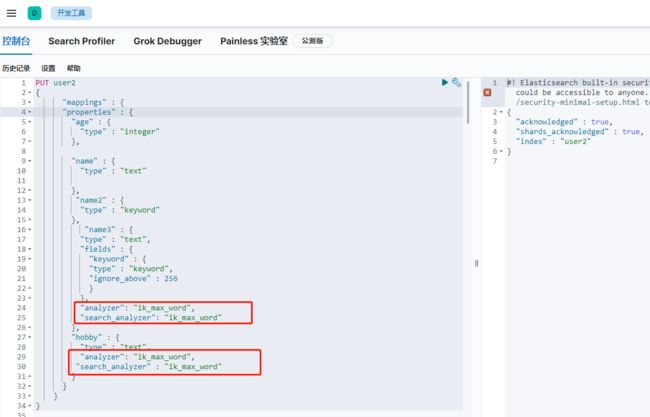
创建索引的时候,text类型如果没指定使用分词器,就会默认内置的分词器,所以使用ik分词器时,创建索引时需要指定。
PUT user2 { "mappings" : { "properties" : { "age" : { "type" : "integer" }, "name" : { "type" : "text" }, "name2" : { "type" : "keyword" }, "name3" : { "type" : "text", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 256 } }, "analyzer": "ik_max_word", "search_analyzer": "ik_max_word" }, "hobby" : { "type" : "text", "analyzer": "ik_max_word", "search_analyzer" : "ik_max_word" } } } }
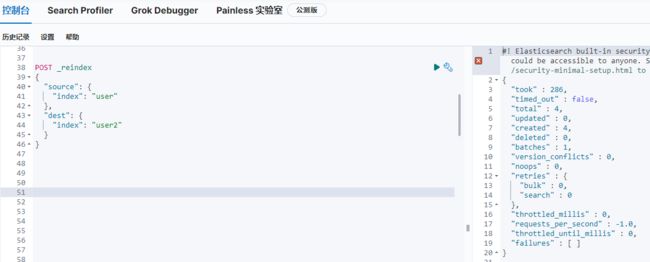
把user的数据复制到user2。
再次查询“爱祖国”,得到一条想要的数据,没有多余数据。证明ik分词在索引中生效了。