数据中心 CLOS 架构
1、数据中心网络架构挑战
随着技术的发展,数据中心的规模越来越大,一个数据中心的服务器容量从几年前的几千台服务器发展到今天的几万甚至几十万台。为了降低网络建设和运维成本,数据中心网络的设计者们也竭力将一个网络模块的规模尽可能扩大。同时,数据中心网络内部东西向流量也日益增加,在一些集群业务的需求驱动下,数据中心网络设计者们甚至开始讨论一个网络模块内10000台千兆线速服务器的可能性。
常见的数据中心网络模块的典型架构是双核心交换机+TOR接入交换机两级结构,如下图所示:
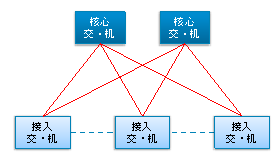
图1 典型数据中心网络模块架构
那么,在这种更大规模数据中心的发展趋势下,这样的数据中心网络架构(其实另外一种典型的三层结构也一样)会面临什么挑战那?
首先,我们会看到单个网络模块的规模直接受限于核心交换机设备的端口密度。比如,对应10000台千兆服务器1:1超载比接入的要求,每台核心交换机应该提供至少500个线速无阻塞万兆端口,这已经在挑战商业市场主流交换机产品的极限了。如果需要更大规模的网络那?貌似只能等待厂商推出更高密度的产品了。
其次,随着核心交换机设备越来越庞大,端口数量越来越多,核心交换机的功耗也据高不下,很轻易的达到接近10kw的量级。这个电源的要求虽然对很多财大气粗的互联网企业自建的数据中心来说是小菜一碟,但对于大部分企业来说,这意味着2~3个月以上的机架电源改造周期,要知道,在国内大多数IDC机房,单机架的供电能力仅3kw左右。
于是,数据中心网络设计工作者开始研究是否有其它的架构设计方案。
2、CLOS网络架构登场
在讨论正题之前让我们一起看看业内人士经常挂在嘴边的CLOS到底是何方神圣。CLOS是一种多级交换架构,目的是为了在输入输出增长的情况下尽可能减少中间的交叉点数。典型的对称3级CLOS架构如下图所示:
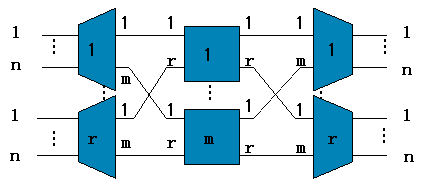
图2 对称3级CLOS交换网络
事实上CLOS架构并不是什么新鲜的东西,早在1953年,贝尔实验室Charles Clos博士在《无阻塞交换网络研究》论文中提出这种架构,后被广泛应用于TDM网络(多半是程控交换机),为纪念这一重大成果,便以他的名字CLOS命名这一架构。
现在我们再回到数据中心网络设计的话题。实际上,前面提到的严重依赖厂商产品端口密度的架构设计方法让很多设计者们如鲠在喉,让他们找到了挑战的兴奋点。犹如Linux 社区的开源之风一般,他们更希望的是摆脱厂商产品限制,找到一种架构设计方法,最好是可以使用廉价、普通的小盒子设备来搭建一个规模可以非常庞大的网络。
在美国加利福尼亚大学计算机科学与工程系以Mohammad Al-Fares为代表的几位教授的研究下,这种思路达到了登峰造极的程度。
在他们于2008年发表于SIGCOMM的论文《A Scalable, Commodity Data Center Network Architecture》中,明确提出了一种三级的,被称之为胖树(Fattree)的CLOS网络架构。利用这种架构方法,可以采用一种固定数量端口的盒式交换机搭建一个大规模服务器接入的网络。具体的说,当采用端口数为k的交换机时,核心交换机数量为(k/2)2个,共有k个Pod,每个Pod各有(k/2)个汇聚和接入交换机,可接入的服务器数量为k3/4。并且这种架构可以保证接入、汇聚、核心的总带宽一致,保证服务器接入带宽1:1的超载比。下图所示的是该架构当k=4的示例。
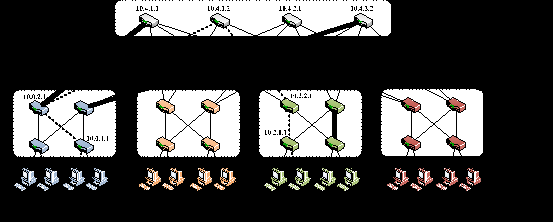
图3 k=4时的胖树CLOS网络
显然,当k=48,即采用48端口千兆盒式交换机时,这个架构的核心交换机数量为576个,一共有48个Pod,每个Pod有24台汇聚交换机和24台接入交换机,共2880个交换机,可以支持到27648台千兆服务器的1:1超载比接入。设备的数量虽然看上去很惊人,但毫无疑问的确是一种可扩展的架构,而且似乎对设备没有特别的要求。
更令人鼓舞的是,这几位教授除了纸上谈兵外,还非常注重实战,论文中详细的对IP地址划分、路由策略、流量调度算法等进行了详细设计,也和传统的设计方法进行了成本和功耗方面的对比。更匪夷所思的是,大概这几位老大也意识到交换机数量庞大带来的设备摆放和互联线缆问题,甚至还给出了设备打包和机架安排方案。一言以蔽之,只要你严格按照这篇论文进行设计,一个几万台1:1带宽超载比的千兆服务器数据中心网络就呼之欲出,几乎所有重要的问题都被周密的考虑到了。
另外,也可以将上述方案做一些变化,比如,将汇聚和核心设备换成全万兆端口的交换机,如现在流行的64端口万兆交换机,接入换成万兆上联的交换机,如现在流行的4万兆+48千兆的交换机,这样同样规模的网络情况下,设备和互联链路的数量可以大大减少。更具体的设计情况大家可以照猫画虎自己研究一下:)
3、迷雾重重
到这里,似乎问题都解决了,数据中心网络的设计工作者们多了一个选择,对业界主流厂商设备端口密度也不那么饥渴了。
喜爱钻研的设计者很快发现,其实CLOS网络架构是采用一个等价于三级CLOS的部分替代了传统设计的两台核心设备,如下图所示:
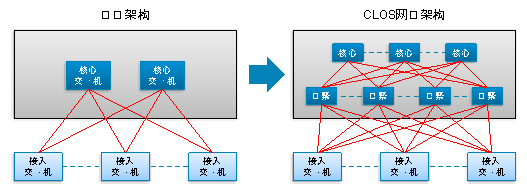
图4 传统网络架构和CLOS网络架构
或者进一步说,是采用一个三级CLOS的部分替代一台核心设备。为什么说是一个三级CLOS的部分,因为汇聚和核心都是双向通信,等价于一个标准的三级CLOS折叠以后把输入、输出单元合并的情况。
主流厂商的核心设备被一堆廉价的小盒子替代了,这是一个令人振奋的消息,同时令人迷惑。
首先是无阻塞的问题。大家都知道网络核心无阻塞的重要性。商业市场的主流核心设备通常都较为复杂,为了实现无阻塞,交换矩阵都有一定的加速比,还采用VoQ等技术,还要有调度仲裁或自路由的设计。那么,一堆廉价的小盒子如何实现无阻塞那?
其次,紧接着的一个很明显的问题,CLOS网络架构上下行的带宽一致,是否就可以实现无阻塞?
还有,交换机的输入输出缓存设计一直都是各主流设备厂家各执一词的,在CLOS网络架构中这部分如何体现的?
再有,CLOS网络架构的多条等价路径如何做到负载均衡?HASH算法是基于流的,不同流的差异无法解决;数据包是变长的,即便轮询也难以均衡。要知道,核心交换机通常内部都会用定长的信元把数据包重新封装以便于尽可能的均衡分布。那么CLOS网络架构是否需要一个集中的控制系统做流量调度?
继续思考下去,就可能会发现更多不容易回答的问题。
似乎CLOS网络架构也并不是那么简单了。
4、如何实现无阻塞
首先我们看看什么是有阻塞无阻塞。
·内部阻塞(Blocking)。若出、入线空闲,但因交换网络级间链路被占用而无法接通的现象,称为多级交换网络的内部阻塞。
·无阻塞(Non-blocking)。不管网络处于何种状态,任何时刻都可以在交换网络中建立一个连接,只要这个连接的起点、终点是空闲的,而不会影响网络中已建立起来的连接。
·可重排无阻塞(Re-arrangeable non-blocking)。不管网络处于何种状态,任何时刻都可以在交换网络中直接或对已有的连接重选路由来建立一个连接,只要这个连接的起点、终点是空闲的,而不会影响网络中已建立起来的连接。
·广义无阻塞(Scalable non-blocking)。指一个给定的网络存在着固有的阻塞可能,但又可能存在着一种精巧的选路方法,使得所有的阻塞均可避免,而不必重新安排网络中已建立起来的连接。
那么CLOS网络架构的阻塞情况如何那?根据数据中心的网络架构,我们研究之前图2中的对称3级结构的CLOS网络的情况就可以了。
这种对称3级CLOS网络,第一级的入线和第三级出线均为n,第二级的单元数量为m。为了确保链路无阻塞,完成a到b的信息交换,至少还应该存在一条空闲链路,即中间级交换单元要有(n-1) (n-1) 1 = 2n-1个,因此无阻塞的条件为:m>=2n-1。如下图所示:

图5 对称3级CLOS网络无阻塞条件为m>=2n-1
另外,Slepian-Duguid定理也证明了,当m=n的时候,对称3级CLOS网络为可重排无阻塞。可重排无阻塞意味着要对交换网络做端到端的调度。
这也就直接证明了CLOS网络中无阻塞的设计,汇聚到核心的带宽应该至少是接入到汇聚的带宽的(2n-1)/n=2-1/n倍,接近2倍。
实际上,加利福尼亚大学那几位教授也在他们的论文中明确的指出了设计采用带宽超载比1:1的胖树CLOS架构是可重排无阻塞的,需要采用合适的调度算法尽可能满足可重排条件。
那是不是满足m>=2n-1的条件,就可以高枕无忧,肯定可以避免端到端的阻塞了那?当然不是,我们可以看到这时候无阻塞的模型前提是入向、出向信息均匀分布,如果分布不均匀就可能导致入向或出向阻塞。这时候我们就需要考虑入向、出向缓存以及加速比的情况。
5、玄妙的加速比Speedup
加速比的概念很直接,它是一种降低输入-输出阻塞的方法。如果一个交换网络可以在一个信元时间内将一个输入端口的N个信元传输至输出,则这个交换网络的加速比S=N。通俗的说,加速比是交换网络在“多打一”的情况下的处理能力。加速比越大,交换网络的中间单元数越多,成本越高。
我们很容易就可以算出,前面我们研究的交换网络,对称3级CLOS架构,在无阻塞条件m>=2n-1时,加速比S=(2n-1)/n=2-1/n,接近于2。而在可重排无阻塞条件m=n时,加速比为1。
在加速比为1时,为了避免入向的阻塞即所谓的“头端阻塞”,我们需要在交换网络的入方向有足够大的缓存,此时端到端的延迟将变得不可控,或者可能会非常大。如下图所示:
图6 入方向缓存的交换模型,S=1
随着加速比的增加,入方向的阻塞可能性越来越小,但出方向的阻塞可能性却越来越大,因此,在加速比比1大的时候,我们需要在交换网络的出方向有足够大的缓存。当S=N(N为入方向端口总数)时,入方向无需缓存,仅需要出方向的缓存,此时,交换网络的成本最为昂贵,但延迟最小。如下图所示:
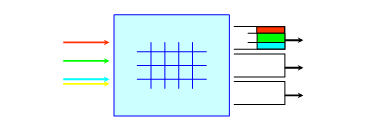
图7 出方向缓存的交换模型,S=N
因此,加速比让交换网络设计者们既爱又恨,但他们把爱和恨都转化成了一个问题,那就是,有没有可能进行巧妙的设计,在加速比1
答案是有可能的。经过努力,业界人士得到的结论是,2
据小道消息,业界部分产品的交换矩阵的加速比如下(无官方确认,仅供参考):
Cisco
· Cat6500:4
· Nexus7000:3.x
· CRS-1: 2.5
H3C
· S12500: 1.8
Juniper
· T /MX Series: S=2.25
好了,绕了一大圈,我们再回过来看看对于我们的CLOS网络架构,加速比如何选择比较合适。
还是先看加利福尼亚大学那几位教授的设计方案。这个方案在加速比为1的情况下,采用了全局集中的流量调度系统FlowScheduler直接控制汇聚和核心设备的路径选择,以获得较好的流量分布,同时在每个接入交换机都内置FlowReporter收集流信息。即便如此,在随机流的测试中网络的带宽利用率也不超过75%。显然这个方案并不完美,并且难以在普通商业产品上实施,对于大多数希望采用CLOS架构的设计者来说,这是一个难以实现的方案。也许随着OpenFlow等SDN技术的发展,这方面可以取得更大进展。Juniper的QFabric从某种程度来看,也类似一个有集中控制和调度的CLOS网络架构,目前很多设计细节还未披露,实际使用的效果如何也有待大规模商用的考验。
按照之前的分析,如果没有流量调度系统,在实际的情况下是无法避免入向或出向的阻塞的,只能尽可能降低阻塞的可能性。考虑到多条等价路径负载均衡的不完美,以及廉价盒式设备具备少许的输入输出缓存,但无法全局统筹调配使用,显然一定的加速比是需要的。兼顾成本因素,选择加速比为2~3也许是一个较为理想的选择。准确的加速比选择,需要进一步的实验室测试和验证,和设备选型也有关。
6、总结
在数据中心网络中,可以采用商用市场普通盒式交换机搭建胖树CLOS网络架构,实现可扩展、不依赖特定厂商产品的网络架构。但如果没有全局集中的流量调度和仲裁机制,也没有全局的入向和出向缓存供调配使用,将难以实现目前商业市场核心设备的无阻塞转发能力,在网络发生阻塞时对应用的性能会产生一定的影响。通过适当的加速比选择,如建议的2~3,可以减少阻塞。CLOS网络架构的设计需要进一步的研究、测试和验证,在将来通过SDN来共同实现可能更为理想。