转载自https://www.jianshu.com/p/4c0f798e16b7
0.介绍
本文基于豆瓣电影数据构建了一个电影知识图谱。其中包括电影、演员、导演三种节点及相关关系。并使用InteractiveGraph对图谱完成可视化工作。
- 数据丰富,图谱包含2.7万个节点,5万条关系
- 使用Neo4j图数据库进行图存储
- 支持大图全局可视化预览
- 支持节点关联发现
- 支持节点展开浏览可视化
所用到的程序包括:
- Tomcat 8.5
- Neo4j 社区版3.5.12
- InteractiveGraph 0.3.2 (项目地址:https://github.com/grapheco/InteractiveGraph)
- InteractiveGraph-neo4j 0.0.3 (项目地址:https://github.com/grapheco/InteractiveGraph-neo4j
)
1.数据处理
该数据来自openKG(http://www.openkg.cn/dataset/douban-movie-kg),抽取自豆瓣电影。示例数据如下,包括电影的标题、封面、分类、语言基本信息以及导演、编剧和主演等人员信息。

{
"id": 1292052,
"title": "肖申克的救赎",
"url": "http://movie.douban.com/subject/1292052/",
"cover": "http://img3.douban.com/view/movie_poster_cover/lpst/public/p480747492.jpg",
"rate": 9.6,
"director": ["弗兰克·德拉邦特"],
"composer": ["弗兰克·德拉邦特", "斯蒂芬·金"],
"actor": ["蒂姆·罗宾斯", "摩根·弗里曼", "鲍勃·冈顿", "威廉姆·赛德勒", "克兰西·布朗", "吉尔·贝罗斯", "马克·罗斯顿", "詹姆斯·惠特摩", "杰弗里·德曼", "拉里·布兰登伯格", "尼尔·吉恩托利", "布赖恩·利比", "大卫·普罗瓦尔", "约瑟夫·劳格诺", "祖德·塞克利拉"],
"category": ["剧情", "犯罪"],
"district": ["United States of America_美国"],
"language": ["英语"],
"showtime": 1994.0,
"length": 142.0,
"othername": ["月黑高飞(港)", "刺激1995(台)", "地狱诺言", "铁窗岁月", "消香克的救赎"]
}
数据集为JSON格式,在导入Neo4j之前还需要做一些处理。
首先使用Pandas读入数据集:
import pandas as pd
import numpy as np
# 读入数据集
data = pd.read_json('data/dbmovies.json', dtype=object)
由于最终构建的图谱包含电影和人这两类节点,因此需要将人物信息从电影信息中抽取出来。观察数据集可以发现,人物信息出现在主演、导演和编剧这三个字段中,所以需要将这三类信息转换成边信息并合并出人员节点数据。
以演员为例,首先把原数据中actor中的演员集合转换成包含<电影id,演员姓名>这两列的DataFrame,然后导出为CSV文件作为边数据。导出为CSV是因为方便Neo4j导入。
有了边数据之后,将这三类人物提取到一列并做去重。这里忽略了演员之间同名的问题,姑且认为同名的人是同一个人。同样的,把合并的数据也转换成CSV格式作为人员节点数据。
person = pd.DataFrame()
labels = ['actor', 'director', 'composer']
for label in labels:
df = data[['id', label]]
df = df.dropna(axis=0, how='any')
df = pd.DataFrame({'id': df['id'].repeat(df[label].str.len()),
label: np.concatenate(df[label].values)})
person = pd.concat([person, df[label]], axis=0)
df.to_csv('data/'+label+'.csv', index=False)
person.drop_duplicates(inplace=True, ignore_index=True)
person.to_csv('data/person.csv', index=False)
对人员信息处理完之后,需要对电影信息做处理。这里主要是把像电影语言这样的数组信息转换成字符串。同样的也要导出到CSV作为电影节点文件。
data.drop(labels, axis=1, inplace=True)
list_labels = ['category', 'district', 'language', 'othername']
for list_label in list_labels:
data[list_label] = data[list_label].apply(lambda x: '、'.join(x) if x!=None else x)
data.to_csv('data/movie.csv', index=False)
2.导入数据
下面开始导入数据到Neo4j中。首先把所有导出的CSV文件拷贝到Neo4j安装目录下的import目录中,并启动Neo4j。
使用如下Cypher导入电影节点数据。需要注意的是对评分、上映年份、时长这些数值类数据做处理,否则这些字段的数据自动作为字符串,无法计算。
USING PERIODIC COMMIT 500
LOAD CSV WITH HEADERS FROM 'file:///movie.csv' AS line
CREATE (:Movie{
id: line.id,
name: line.title,
url: line.url,
image: line.cover,
rate: toFloat(line.rate),
category: line.category,
district: line.district,
language: line.language,
showtime: toInteger(line.showtime),
length: toInteger(line.length),
othername: line.othername
})
导入人物数据:
USING PERIODIC COMMIT 500
LOAD CSV FROM 'file:///person.csv' AS line
CREATE (:Person{name:line[0]})
在创建关系之前,需要对节点字段做索引,这样能加快创建关系节点查找的速度。
CREATE INDEX ON :Movie(id)
CREATE INDEX ON :Movie(name)
CREATE INDEX ON :Person(name)
创建三种关系,分别是(人物)-[:饰演]->(电影),(人物)-[:导演]->(电影)和(人物)-[:编剧]->(电影)。
USING PERIODIC COMMIT 500
LOAD CSV WITH HEADERS FROM 'file:///actor.csv' AS line
MATCH (p:Person) where p.name = line.actor WITH p,line
MATCH (m:Movie) where m.id = line.id
MERGE (p)-[:play]->(m)
USING PERIODIC COMMIT 500
LOAD CSV WITH HEADERS FROM 'file:///director.csv' AS line
MATCH (p:Person) where p.name = line.director WITH p,line
MATCH (m:Movie) where m.id = line.id
MERGE (p)-[:direct]->(m)
USING PERIODIC COMMIT 500
LOAD CSV WITH HEADERS FROM 'file:///composer.csv' AS line
MATCH (p:Person) where p.name = line.composer WITH p,line
MATCH (m:Movie) where m.id = line.id
MERGE (p)-[:write]->(m)
这一步对人物做了一个打分计算,把人物参与的(可以是参演、编剧或导演)电影评分的均值作为人物的评分。
match (p:Person)-[]-(m:Movie) with p,avg(m.rate)*10 as avg
set p.rate = round(avg)/10
3.配置可视化系统
本文使用的知识图谱可视化系统包括两个部分:InteractiveGraph和InteractiveGraph-neo4j,前者为可视化系统的Web前端部分,负责显示和交互;后者为可视化系统的后端部分,负责管理数据以及提供各种数据访问接口。
InteractiveGraph-neo4j安装与配置
下载与部署
首先从github下载最新的发行版war包:https://github.com/grapheco/InteractiveGraph-neo4j/releases
将下载完成的war包放到Tomcat的webapps目录中,tomcat会自动解压war包生成graphserver文件夹(如果没有自动解压可以尝试重启Tomcat)。
修改配置文件
修改配置文件graphserver/WEB_INF/conf1.properties:
allowOrigin=*
backendType=neo4j-bolt
neo4j.boltUrl=bolt://localhost:7687
neo4j.boltUser=neo4j
neo4j.boltPassword=1
neo4j.regexpSearchFields=name
neo4j.strictSearchFields=label:name
neo4j.nodeCategories=Person:人物,Movie:电影
layout_on_startup=false
visNodeProperty.label==$prop.name
visNodeProperty.value==$prop.rate
visNodeProperty.image==$prop.image
visNodeProperty.x ==$prop.x
visNodeProperty.y ==$prop.y
visNodeProperty.info= #if($prop.image) 
#end ${prop.name}
- 评分:${node.rate}
- 类型:${node.category}
- 时长:${node.length}分钟
- 语言:${node.language}
其中:
- allowOrigin:是允许访问的域,默认允许所有,这里不需要修改;
- backendType:后端类型,本文使用的是neo4j因此也不需要修改;
- neo4j.boltUrl:Neo4j的地址;
- neo4j.boltUser:Neo4j用户名;
- neo4j.boltPassword:Neo4j密码;
- neo4j.regexpSearchFields:这一项是搜索时匹配的字段名,在这里指定为节点的
name字段; - neo4j.strictSearchFields:严格搜索的接受格式,这里设置为
节点label:name字段(如Person:周星驰); - neo4j. nodeCategories:这一项指定数据库中有哪些节点类型,本文中有人物和电影;
- layout_on_startup:是否自动布局。本文中数据有几万个节点和边,这个数量级的数据前端浏览器的计算力已经不足以每次都对数据在线布局。因此需要服务端使用布局算法离线计算节点位置,并记录在Neo4j中。由于本文的数据库中没有位置信息,因此这一项设置为
true。当本次预计算完成后,下一次启动服务端时可以设置成false避免再次计算; - visNodeProperty.label:前端可视化节点显示的名称对应的字段,这里设置为数据库中节点的
name字段; - visNodeProperty.value:前端可视化节点的值对应的字段。值的大小决定了前端显示的节点的实际大小。这里设置为
rate字段,这样在前端显示时,类似《肖申克的救赎》这样的高分节点就会显示的比较大,而《上海堡垒》这种烂片就会显示的比较小; - visNodeProperty.image:前端可视化节点的图片对应的字段,这里设置为数据库节点中的
image字段; - visNodeProperty.x:前端可视化节点的x坐标对应的字段,默认为数据库的
x字段,因为自动布局算法设定的就是这个字段所以这里不用更改,如果数据库本事有位置信息可以自行指定; - visNodeProperty.y: 同上;
- visNodeProperty.info:前端信息面板的展示代码。在本文中设定和对应效果如下:
#if($prop.image)
#end
${prop.name}
- 评分:${node.rate}
- 类型:${node.category}
- 时长:${node.length}分钟
- 语言:${node.language}

配置完成后,重启Tomcat。然后浏览器打开http://localhost:8080/graphserver/如果能看到字说明服务端配置成功。
InteractiveGraph安装与配置
下载与部署
首先从github下载最新的发行版:
https://github.com/grapheco/InteractiveGraph/releases
igraph.zip包含InteractiveGraph的js文件,可以结合项目README的流程自行使用。
本文直接下载了examples.zip中的示例内容,在其上做了适当修改。
首先在tomcat的webapps目录中新建igraph文件夹,并将examples.zip中的内容解压到这个文件夹中。
InteractiveGraph工具包括三个应用:
- GraphNavigator:图导航器,提供对整个图的全局视图可视化预览;
- GraphExplorer:图浏览器,通过对某个节点的展开操作,逐步浏览该节点和拓展节点的信息;
- RelationFinder:关系查找器,提供两个节点间的关系路径发现。
上述3个应用分别在example1.html,example2.html和example3.html。接下来需要修改其中的内容。
修改配置
打开example1.html,将js中app.loadGson修改为:
igraph.i18n.setLanguage("chs");
var app = new igraph.GraphNavigator(document.getElementById('graphArea'), 'LIGHT');
//修改了这下面↓,上面不要改
app.connect("http://localhost:8080/graphserver/connector-bolt");
这里的localhost:8080为graphserver的地址。
同理,对example2.html和example3.html也做上述修改。
igraph.i18n.setLanguage("chs");
var app = new igraph.GraphExplorer(document.getElementById('graphArea'));
//修改了这下面↓,上面不要改
app.connect("http://localhost:8080/graphserver/connector-bolt");
igraph.i18n.setLanguage("chs");
var app = new igraph.RelFinder(document.getElementById('graphArea'));
//修改了这下面↓,上面不要改
app.connect("http://localhost:8080/graphserver/connector-bolt");
4.可视化展示
图导航器
浏览器打开http://localhost:8080/igraph/example1.html进入图导航器可视化界面,如图:(由于数据集中的图片链接现在已被豆瓣更改,很多节点的图片无法显示)
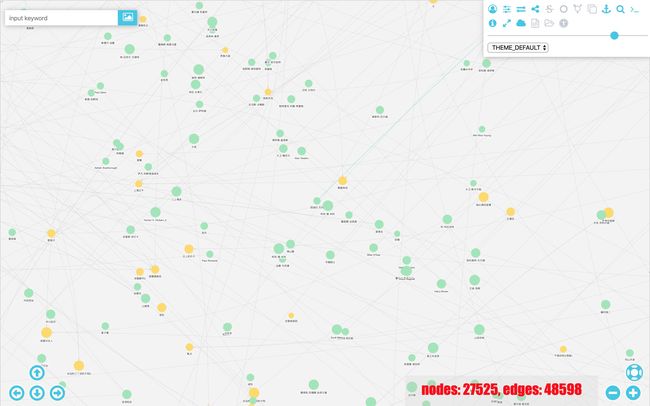
可以拖动显示区域浏览全局大图。
图浏览器
浏览器打开http://localhost:8080/igraph/example2.html进入图浏览器可视化界面。
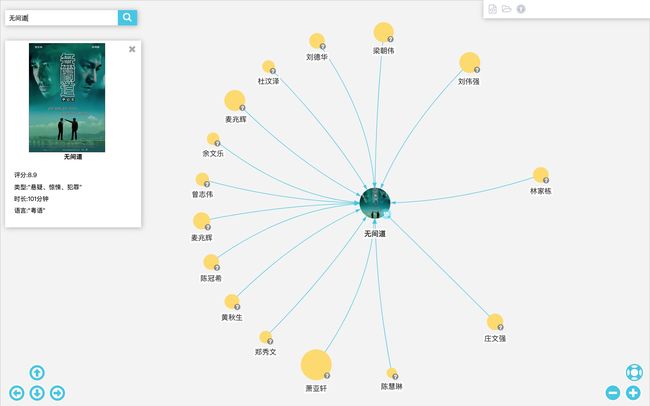
在搜索框中输入Movie:无间道,结果如图。
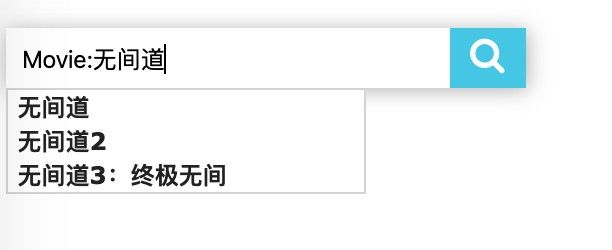
点击“无间道”,可以看到电影《无间道》对应的节点。

在图浏览器中,单击节点可以查看节点信息,双击可以展开节点。
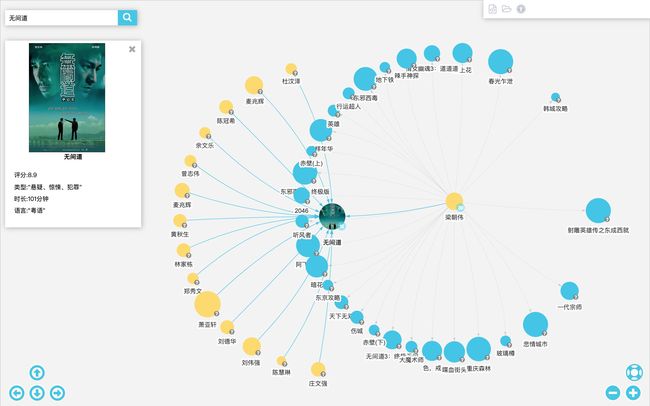
关系查找器
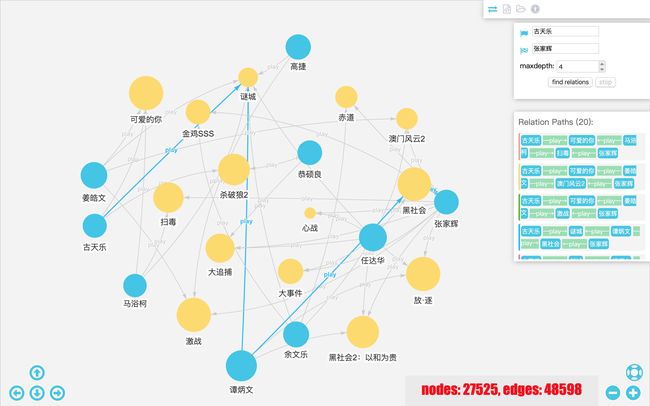
浏览器打开http://localhost:8080/igraph/example3.html进入关系查找器可视化界面。在右侧输入起始节点Person:古天乐和结束节点Person:张家辉并选中搜索出的人物,设定最大路径长度为4,搜索路径,结果如图所示。共有20条路径,点击右侧路径列表可以对这条路径高亮显示。
作者:川大宝
链接:https://www.jianshu.com/p/4c0f798e16b7
来源:
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。