关于canal,你想了解的都在这儿
前言
对canal有所了解的同学应该知道,canal是阿里开源的一款mysql数据库同步的工具,主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费
github地址:https://github.com/alibaba/canal
什么是 Canal
阿里巴巴 B2B 公司,因业务的特性,卖家主要集中在国内,买家主要集中在国外,所
以衍生出了同步杭州和美国异地机房的需求,从 2010 年开始,阿里系公司开始逐步的尝试基于数据库的日志解析,获取增量变更进行同步,由此衍生出了增量订阅&消费的业务
Canal 是用 Java 开发的基于数据库增量日志解析,提供增量数据订阅&消费的中间件。
目前。Canal 主要支持了 MySQL 的 Binlog 解析,解析完成后才利用 Canal Client 来处理获得的相关数据。(数据库同步需要阿里的 Otter 中间件,基于 Canal)
除了关系型数据库同步,canal目前为止支持的消息中间件很全面了,比如Kafka、RocketMQ,RabbitMQ
MySQL 的 Binlog
在真正学习canal之前,有必要对MySQL 的 Binlog做一下了解
1、什么是 Binlog
MySQL 的二进制日志可以说 MySQL 最重要的日志了,它记录了所有的 DDL 和 DML(除
了数据查询语句)语句,以事件形式记录,还包含语句所执行的消耗的时间,MySQL 的二进制日志是事务安全型的。
一般来说开启二进制日志大概会有 1%的性能损耗。二进制有两个最重要的使用场景:
- 其一:MySQL Replication 在 Master 端开启 Binlog,Master 把它的二进制日志传递给 Slaves来达到 Master-Slave 数据一致的目的。
- 其二:自然就是数据恢复了,通过使用 MySQL Binlog 工具来使恢复数据。
二进制日志包括两类文件:二进制日志索引文件(文件名后缀为.index)用于记录所有
的二进制文件,二进制日志文件(文件名后缀为.00000*)记录数据库所有的 DDL 和 DML(除了数据查询语句)语句事件。
2、 Binlog 的分类
MySQL Binlog 的格式有三种,分别是 STATEMENT,MIXED,ROW。在配置文件中可以选择配置 binlog_format= statement|mixed|row。三种格式的区别:
- statement:语句级,binlog 会记录每次一执行写操作的语句。相对 row 模式节省空
间,但是可能产生不一致性,比如“update tt set create_date=now()”,如果用 binlog 日志进行恢复,由于执行时间不同可能产生的数据就不同。优点是节省空间,缺点是有可能造成数据不一致 - row:行级, binlog 会记录每次操作后每行记录的变化。优点是保持数据的绝对一致性。因为不管 sql 是什么,引用了什么函数,他只记录执行后的效果。缺点是占用较大空间
- mixed:statement 的升级版,一定程度上解决了,因为一些情况而造成的statement模式不一致问题,默认还是 statement,在某些情况下譬如:当函数中包含 UUID() 时;包含AUTO_INCREMENT 字段的表被更新时;执行 INSERT DELAYED 语句时;用 UDF 时;会按照ROW 的方式进行处理,优点是节省空间,同时兼顾了一定的一致性。缺点是还有些极个别情况依旧会造成不一致,另外 statement 和 mixed 对于需要对binlog 的监控的情况都不方便。
综上对比,Canal 想做监控分析,选择 row 格式比较合适。
mysql主从复制工作原理
在全面深入的学习与应用canal之前,有必要对其工作原理有一个了解,mysql的主从复制想必都不陌生,见下图:

主从复制的原理说明:
- master 节点将数据变更写入二进制日志( binary log, 要查看的话需要提前开启)
- slave 将 master 的 binary log events 拷贝到它的中继日志(relay log)
- slave 将 master 的 binary log events 拷贝到它的中继日志(relay log)
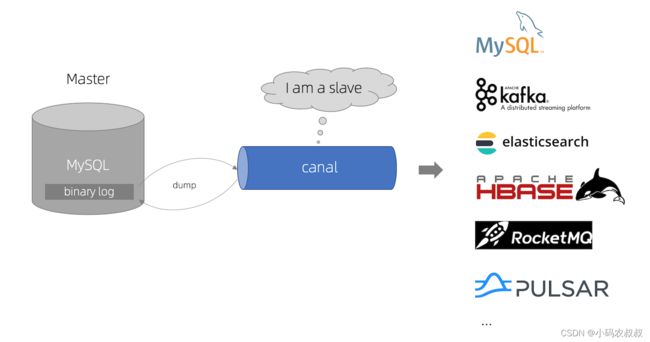
canal 工作原理
- canal 模拟 MySQL的 slave 的交互协议,将自己伪装成 MySQL slave ,向 MySQL master 发送dump 协议
- MySQL 的master 收到 dump 请求后,开始推送 binary log 给 slave (即 canal )
- canal 解析 binary log 对象(原始为 byte 流)
一句话总结canal的原理就是:把自己伪装成 Slave,假装从 Master 复制数据
接下来将从canal的环境搭建,到实战案例运用多个维度一起探讨canal吧
canal环境搭建
光说不练等于白干,我们先快速搭建一个环境,实际感受下canal是如何运作的吧
一、环境准备
1、下载安装包
canal安装包,包括:canal.adapter-1.1.4.tar.gz , canal.deployer-1.1.4.tar.gz
canal安装包下载地址:https://github.com/alibaba/canal/releases

2、 mysql环境准备
两台服务器,并各自安装了mysql服务,假设各自的外网IP为:IP1和IP2,并且在IP1的服务器上开启binlog
使用:show variables like ‘log_bin’; 检查binlog是否开启

如果没有开启,请在mysql的配置文件my.cnf中添加如下配置,然后重启mysql服务
[mysqld]
server-id=1
log-bin=mysql-bin
binlog_format=row
binlog-do-db=bank1
同时,分别在IP1和IP2上面安装的mysql数据库下创建了 user_info 表和 tar_user表,最终要达到的目的是,数据要从 IP1:user_info => IP2: tar_user 表同步

user_info 和tar_user 建表语句
CREATE TABLE `user_info` (
`id` varchar(255) DEFAULT NULL,
`name` varchar(255) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
3、 在IP1所在mysql创建一个用于同步数据的账户
该账户的作用是,canal拉取数据时候使用
mysql> set global validate_password_length=4;
mysql> set global validate_password_policy=0;
mysql> GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO
'canal'@'%' IDENTIFIED BY 'canal' ;
![]()
二、具体搭建步骤
canal下载的安装包包括2个,canal.adapter和canal.deployer
deployer 配置
canal的deployer可理解为canal服务的server端,负责订阅并解析Mysql-Binlog
1、解压canal.deployer-1.1.4.tar.gz 到指定目录
tar -zxvf canal.deployer-1.1.4.tar.gz -C 目标文件目录

2、进入conf目录,修改canal.properties
如果同步的数据是msyql到mysql,该配置文件无需做修改,保持默认即可,需要注意的地方如下:

3、进入example目录,修改instance.properties

主要需要修改的地方如下:
canal.instance.master.address=IP:3306 #mysql源地址,本例为:IP1地址

mysql源地址授权canal获取数据的账户名和密码,即为上面创建的那个同步数据的账户

4、启动deployer服务
进入到bin目录,直接使用下面的脚本启动,启动后检查下进程

可以看到,其实就是一个springboot的JVM进程

adapter 配置
anal-adapter可理解为canal客户端适配器,能直接将canal同步的数据写入到目标数据库(hbase,rdb,es,kafka…),rdb是关系型数据库比如MySQL、Oracle、PostgresSQL和SQLServer等,或消息中间件kafka等,下面演示同步到mysql的配置
1、解压 canal.adapter-1.1.4.tar.gz 到指定目录
tar -zxvf canal.adapter-1.1.4.tar.gz 指定目录

2、进入conf 目录,首先修改application.yml 文件
server:
port: 8081
spring:
jackson:
date-format: yyyy-MM-dd HH:mm:ss
time-zone: GMT+8
default-property-inclusion: non_null
canal.conf:
mode: tcp # kafka rocketMQ
canalServerHost: Canal的deployer服务所在IP地址:11111
# zookeeperHosts: slave1:2181
# mqServers: 127.0.0.1:9092 #or rocketmq
# flatMessage: true
batchSize: 500
syncBatchSize: 1000
retries: 0
timeout:
accessKey:
secretKey:
srcDataSources:
defaultDS:
url: jdbc:mysql://mysql源数据库IP:3306/shop001?useUnicode=true
username: root
password: root
canalAdapters:
- instance: example # canal instance Name or mq topic name
groups:
- groupId: g1
outerAdapters:
- name: logger
- name: rdb
key: mysql1
properties:
jdbc.driverClassName: com.mysql.jdbc.Driver
jdbc.url: jdbc:mysql://目标同步->IP2:3306/shop001?useUnicode=true
jdbc.username: root
jdbc.password: root
3、进入rdb 目录,首先修改mytest_user.yml 文件

下面贴出核心修改的文件内容,需要注意的地方包括:
- groupId: g1 ,这个和上面第二步中的该配置保持一致
- outerAdapterKey: mysql1 ,这个和第二步中的该配置保持一致
- mapAll: true,如果源表和目标表的字段结构等完全一致,直接开启此配置即可,下面的targetColumns可以注释掉
dataSourceKey: defaultDS
destination: example
groupId: g1
outerAdapterKey: mysql1
concurrent: true
dbMapping:
database: shop001 #mysql源数据库名称
table: user_info #mysql源数据库下的表名称
targetTable: shop001.tar_user #同步到目标数据库-数据表名称
targetPk:
id: id
mapAll: true #如果源表和目标表的字段结构等完全一致,直接开启此配置即可,下面的targetColumns可以注释掉
#targetColumns:
# id:
# name:
# role_id:
# c_time:
# test1:
#etlCondition: "where c_time>={}"
#commitBatch: 3000 # 批量提交的大小
4、启动 adapter 服务
进入bin目录下,使用下面的启动脚本进行启动,然后检查服务进程

看到上面两个进程都在,自此,实验环境下canal的配置部分以及服务已经正常可以使用了,下面开始做一下测试
测试之前,确保IP1下的数据库下的user_info表,和IP2数据库下的tar_user表均为空

当前的状态为,两个库下的两个表均为空,执行下面的数据插入 sql ,给 user_info表插入一条数据
INSERT INTO `shop001`.`user_info` (`id`, `name`, `sex`) VALUES ('1', 'xiaoma', 'male');

可以看到,数据几乎是准实时的插入到tar_user表中,当然,当你执行删除、修改等操作时候,同样会同步过去
同时更加细腻度的配置,比如指定同步某个表,或者同步某个表的某些字段,以及使用select 语句的方式做同步控制等等,可以参考github上面的说明进一步研究
以上通过搭建canal服务演示了如何通过canal实现mysql到mysql的数据同步的完整过程,canal提供了基于mysql为数据源同步到其他数据服务能力,比如同步到rocketmq,kafka,oracle等,可以基于上面的配置做进一步的研究
canal客户端代码接入
在上面案例中,我们探讨的是直接基于配置的方式完成mysql端到端的数据同步,事实上,在真实的业务场景中,在应用层面,canal官方同样提供了SDK给开发者使用,通过程序层面监听数据表的数据变化,从而完成一些特殊的业务需求
举例来说,在某些审计或风控类的场景中,应用层面需要对订单表数据做监控,就可以利用canal对订单表做监听,一旦该表有数据变化,应用层面即可异步完成相关的上下游业务的处理
下面通过实例代码演示下如何在Java代码中使用canal
1、导入依赖
<dependency>
<groupId>com.alibaba.otter</groupId>
<artifactId>canal.client</artifactId>
<version>1.1.2</version>
</dependency>
2、编写一个demo,核心代码如下
import com.alibaba.fastjson.JSONObject;
import com.alibaba.otter.canal.client.CanalConnector;
import com.alibaba.otter.canal.client.CanalConnectors;
import com.alibaba.otter.canal.protocol.CanalEntry;
import com.alibaba.otter.canal.protocol.Message;
import com.google.protobuf.ByteString;
import java.net.InetSocketAddress;
import java.util.List;
public class CanalClient {
public static void main(String[] args) throws Exception{
//1.获取 canal 连接对象
CanalConnector canalConnector =
CanalConnectors.newSingleConnector(new
InetSocketAddress("canal所在服务器IP", 11111), "example", "", "");
System.out.println("canal启动并开始监听数据 ...... ");
while (true){
canalConnector.connect();
//订阅表
canalConnector.subscribe("shop001.*");
//获取数据
Message message = canalConnector.get(100);
//解析message
List<CanalEntry.Entry> entries = message.getEntries();
if(entries.size() <=0){
System.out.println("未检测到数据");
Thread.sleep(1000);
}
for(CanalEntry.Entry entry : entries){
//1、获取表名
String tableName = entry.getHeader().getTableName();
//2、获取类型
CanalEntry.EntryType entryType = entry.getEntryType();
//3、获取序列化后的数据
ByteString storeValue = entry.getStoreValue();
//判断是否rowdata类型数据
if(CanalEntry.EntryType.ROWDATA.equals(entryType)){
//对第三步中的数据进行解析
CanalEntry.RowChange rowChange = CanalEntry.RowChange.parseFrom(storeValue);
//获取当前事件的操作类型
CanalEntry.EventType eventType = rowChange.getEventType();
//获取数据集
List<CanalEntry.RowData> rowDatasList = rowChange.getRowDatasList();
//便利数据
for(CanalEntry.RowData rowData : rowDatasList){
//数据变更之前的内容
JSONObject beforeData = new JSONObject();
List<CanalEntry.Column> beforeColumnsList = rowData.getAfterColumnsList();
for(CanalEntry.Column column : beforeColumnsList){
beforeData.put(column.getName(),column.getValue());
}
//数据变更之后的内容
List<CanalEntry.Column> afterColumnsList = rowData.getAfterColumnsList();
JSONObject afterData = new JSONObject();
for(CanalEntry.Column column : afterColumnsList){
afterData.put(column.getName(),column.getValue());
}
System.out.println("Table :" + tableName +
",eventType :" + eventType +
",beforeData :" + beforeData +
",afterData : " + afterData);
}
}else {
System.out.println("当前操作类型为:" + entryType);
}
}
}
}
}
关于API的使用,可参考官方的demo示例代码,并且有详细的注释,其代码逻辑步骤大致如下:
- 建立连接
- 订阅指定数据库(或者所有数据库,或某个库下的表)
- 检测到数据变更
- 提取binlog中的元数据,解析变更数据类型,解析元数据中的信息
- 基于变更数据做自身的业务逻辑或其他业务
下面来对上述代码做一下测试,运行上面的代码,通过控制台日志发现监听程序以及开始监听

接下来去 shop001数据库中给 user_info表新增一条数据



通过控制台输出日志,可以看到对监听的数据表数据的操作,客户端这边能够立即感知到,那么对于应用端来说,即可以在监听到特定数据表数据发生变化时,根据实际的业务需求,做出相应的反应,比如给上下游业务发送消息通知等
应用场景一:数据下发
在一些大型的电商类网站,如某宝,某东,我们在网站中搜索特定的商品时,通常会快速的得到期望的搜索结果,其背后基本上都使用了诸如es这样的搜索引擎
有关电商开发经验的伙伴应该知道,通常用户检索出来的商品,其背后都是有一个商品上架的后台管理系统,不管是通过人工录入还是机器自动录入,原始的商品数据一定会在mysql中保存
但入库之后的商品存在mysql中,如何能被es检索呢?当然实现的方式有很多种,比如通过后台的定时任务轮询将新入库的商品写到es,或者在程序层面,当商品存入msql时,异步的将数据写入es等等
这都是可以落地实施的方案,但仔细分析来看,这样做都会与现有的商品入库业务造成或多或少的业务上的耦合
有了canal之后,我们不妨换个思路,利用canal来实现,具体实现思路如下:
- 配置canal服务,订阅数据库中的商品表
- 数据同步服务通过引入SDK订阅商品表,订阅商品表的新增event动作
- 监听到商品表数据变更时,同步将数据写到es

事实上,在官方给出的数据同步业务架构图中,是直接提供了canal同步mysql数据到es的解决方案,具体配置可参考小编的另一篇博文:canal同步mysql数据到es
官方的配置说明:https://github.com/alibaba/canal/wiki/Sync-ES
但是从实际经验来看,显然通过在应用程序中进行同步更恰当一些,毕竟真实的业务中,数据同步至es还有一些针对个别字段的处理,就显得更灵活可控
应用场景二:异地数据同步与数据回切
mysql异地数据同步与灾备是很多公司的产品在实际落地过程中必须考虑的场景之一,小编所在的某个项目中,就利用canal在项目的数据落地实施过程中进行了一次较好的探索,主要体现在数据的异地同步以及数据回切,具体的业务实现大致如下:
- 正常情况下,数据的读写在上海数据中心
- 正常情况下,通过第一个canal服务将变更数据同步至张家口数据中心
- 当上海数据中心发生了数据不可恢复的故障时,通过另一个canal服务将数据反向同步至上海数据中心

应用场景三:数据异构
在某些大型的平台级应用中,平台内部各个应用都是一个个独立的微服务,因此各个微服务之间的数据库基本上都是各自独立的,这种情况下,各个应用间如果需要数据互通时,必然需要通过rpc的方式互相调用
有这样一个需求,业务上需要将票据表的数据和VIP客户表的数据进行一个聚合,然后展示到内部的大屏上
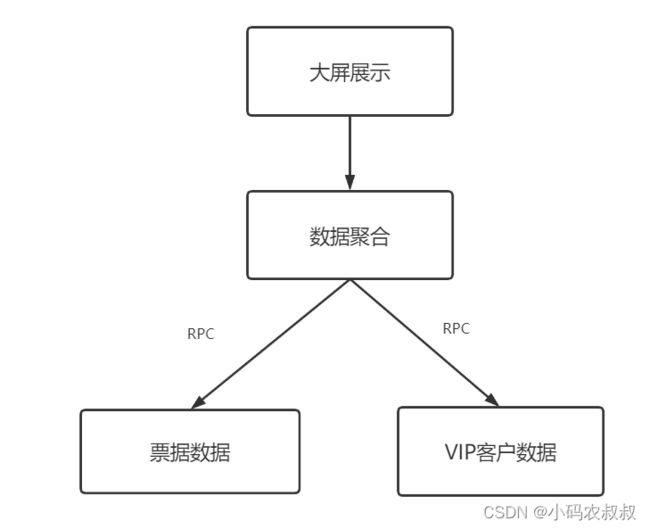
通常的做法是:
- 通过一个程序,分别调用票据服务和VIP服务,拿到数据
- 数据进行聚合,最后返回给大屏
但设想如果票据表的数据量级非常大,并且做了分库或分表的处理,这种情况下对程序上的处理就非常的麻烦了
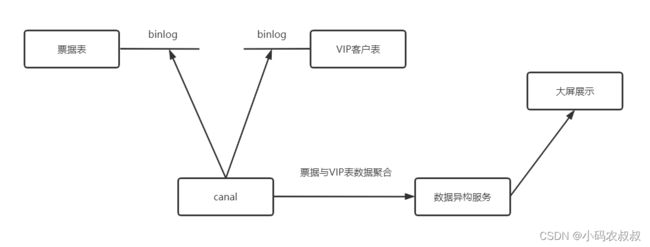
假如引入canal按照下面这样来改造:
- 启动canal服务,分别监听票据表和VIP表的数据变化
- 数据异构微服务监听来自canal的数据
- 异构微服务将异构数据推送至大屏
canal配置数据同步的几个注意点
最后,再结合canal在实际应用过程中发现的问题,对配置中一个关键点做一下补充说明
我们知道,canal同步是依靠binlog,很关键的就是binlog中的日志点的位置,根据日志点位置看,可将canal的数据同步简单分为增量同步和全量同步,所以,Canal启动时,需要配置开始同步的binglog位置,默认不做特定的配置会按照全量同步,有如下三种指定方式可以参考:
- 配置参数canal.instance.master.journal.name 与 canal.instance.master.position : 精确指定一个binlog位点,进行启动
- canal.instance.master.timestamp : 指定一个时间戳,canal会自动遍历mysql binlog,找到对应时间戳的binlog位点后,进行启动
- 不指定任何信息:默认从当前数据库的位点,进行启动。(show master status)