0. 章节内容大纲:
- ScyllaDB的前世今生
- Cassandra(ScyllaDB)的应用场景
- ScyllaDB的系统架构
一. Scylla的前世今生
在学习任何源码前,我们都需要了解它的背景,它的架构。
ScyllaDB可以算得上是数据库界的奇葩,它用c++改写了java版的Cassandra。
为什么奇葩呢?因为大部分用其它语言改写的,都很难匹敌原系统。而它却相当成功,引起来了片欢呼。
它的成功来源于JVM GC的无止尽的噩梦,另一部分来自于大名顶顶的KVM团队开发成员!
国内很多人对于Cassandra很陌生。
有一句话说得很明白,亚洲用HBase,海外用Cassandra。
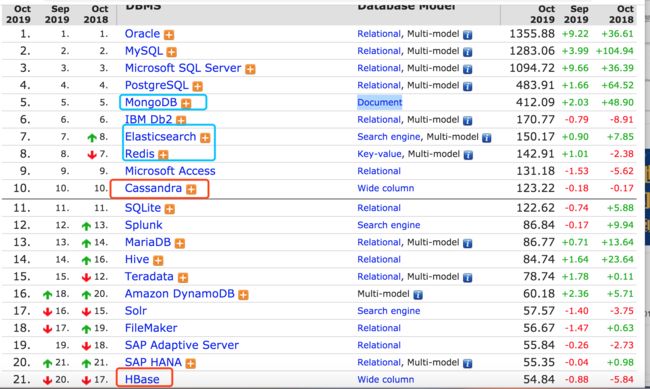
基于最新的数据库排名我们可以看到,Cassandra在NOSQL数据库中排在第四位,已经远远甩开了HBase。
那么Cassandra跟HBase有什么故事呢?
HBase是基于google bigtable的开源版本,而Cassandra是基于Amazon Dynamo + Google BigTable的开源版本。
10年前发生了一件大事,就是facebook弃用了Cassandra选用了HBase。
我们看一看那时候的场景。那时候Amazon的员工出走Facebook,依据Amazon Dynamo开始主导开发Cassandra,当时是没有啥地位的,属于探索性项目。
而Cassandra这个数据库复杂度过高,导致bug量一时周转不过来,而业务急着要用呢?索性,一下子切换到了HBase,毕竟已经经历过了市场检验。
而其中最知名的缘由,来自于分由式系统的cap理论。
cap包含三块: c代表consistent,表示一致性,说明所有的数据总是在任意时刻一致的; a代表可用性,就是说分布式系统出了故障,还是可用的。p代表分区容错性。
问题来了,cap理论证明只能满足两点。cassandra选择了ap, hbase选择了cp模型。
也就是说, hbase为了保证数据强一致性,它会等所有的节点数据全部落地,所以写入性能很差。如果主节点的数据出了故障,它是一定需要其它节点同步数据的,不然数据就很难保证一致性。所以一个节点数据写入时,如果其它节点不可用,那么写入是不能进行的,不然其它人数据就不一致了,所以整个系统就失去了可用性。
相反的,cassandra为了保证高可用性,允许数据不一致。但是呢,Cassandra机制更复杂,它是可调整的一致性。简单来说它分为写+读两部分。我们可以指定写入节点比例,也可以指定读入节点比例。如果写入节点比例+读入节点比例超过了100%,那么它就是强一致性。
比如写入时,必须有超过一半的成员参与。读取时必须有超噎一半的成员参与。如果读取时发生数据不一致,则要进行数据修复。所以cassandra写入速度奇快,不需要所有节点就绪,而读取速度则稍慢一些。由于已经有超过一半的数据一致了,而现在读取超过一半的时候必定有先前的成员,所以数据一定是跟写入相同的,如果不相同,则进行读修复操作。
那么现在我们可以看出,当时facebook选择hbase基于以下原因: hbase的强一致性且经过实践经验, cassandra技术性过强,bug较多。
我们可以感觉得出,cassandra技术确实强了不少,虽然复杂度高了太多。首先cassandra采用的是p2p的gossip模型,其次cassandra的cql可以有更好的扩展。当然cassandra有太多厉害的东西,我们后面再介绍。
这么好的东西,在facebook还只是个探索品,facebook没有太多耐心,直接开源了。这个时候国外有个人评测了无数据数据库之后,发现cassandra是个大宝藏啊!高兴得不得了,实在忍不住就创立了datastax,从此cassandra走上了商业化舞台。。。
东西是好东西,识货的人自然不少。特别是苹果公司高兴得不得了啊,这么免费的好东西直接来了16万台的集群。instagram也是高兴的不得了,用了cassandra之后直接去掉了redis,成本一下子少了四分之一。举国欢庆。。。这发展得势头,阿里也坐不住了,说好一辈子爱HBase的,也开始入下身段开搞Cassandra了。
无奈HBase简单是太烂了。。。
HBase烂到什么程序呢?连它爸爸都抛弃它去搞Apache Kudu了。
为什么HBase这么烂了。太多原因了。
首先,它有两个猪队友: HDFS与Zookeeper。其实,JVM GC不管怎么调永远是恶梦。再次,hbase完全没有生态,除了一个kylin自己封装了一套,基本也开始堕落了。
而Cassandra不一样,Cassandra的模型好呀。
支持分区,支持宽列。
所以Presto自助查询分分钟支持,kafka connect分分钟支持,连BI报表工具也开始分分钟支持了。
加上国外大火的SMACK(Spark, Mesos, Actor, Cassandra, Kafka)以Cassandra为核心的存储层架构建立起来,前途一片叫好。
但是呢, Cassandra虽然没有猪队友hdfs跟zookeeper,虽然有着良好的生态圈,但是呢,依然摆脱不了JVM GC的恶梦。
怎么办呢?datastax二话不说,直接把底层存储用rocksdb来改写。
当然rocksdb也是个facebook出品的神器,我们不过多介绍。只是简单提到现在实时计算kafka及flink底层的状态存储,以及区块链的数据存储基本上被rocksDB一统了。而基于网络的redis, hbase开销太大,对于实时计算性能影响过大,已经属于上一个世界的技术了。当然这只是一方面,另一方面由于实时计算技术对于严格一次的处理对于内置状态有较高的需要,所以内置rocksdb有着极大的优势。然后通过kafka connect或者flink connector同步至外部存储即可,解耦合了架构的灵活性。
kvm团队一看,哇,cassandra是神器啊,未来不可限量,用jvm平台还有另外一个问题,就是compaction性能太差。
在分布式里面,所有的数据都只是append, 加上删除墓碑来处理,然后内存进行flush出来,进行compaction合并,这些都是常见套路。
但是compaction对于io有着较大的性能消耗。
所以呢,kvm团队一想,哇,我们的机会来了。
从此,我们的主角ScyllaDB诞生了。。。
然后cassandra
二. Cassandra(ScyllaDB)的应用场景
前面讲到了datastax, Apple, Instagram大量采用了Cassandra,海外大量采用Cassandra致使Cassandra排名远超HBase。
那么在国内呢?国内也是有一些的。。。
比如360团队,饿了么团队,ebay团队。。。
当然国内技术团队造势没有阿里强,所以自己玩就好啦。。。
前面也讲到了Cassandra属于正常的AP系统,当然可以调整为CP系统,但是性能是没有传统关系数据库的2PC(二阶段性能)高的。
所以Cassandra对于交易类型,性能会稍弱一些,自然也是可用的,只是没那么流行罢了。
所以Cassandra的主战场在nosql跟数据分析这两块。
首先Cassandra在nosql上跟redis有得一拼。redis这玩意好是好,但是数据量存不了多少,并且吃内存太厉害。所以在性能要求不是特别高的时候,Cassandra简单是太好用了。所以很多家都把redis迁移到了Cassandra上面。
当然你说如果性能要求高呢?性能要求高可以走rocksdb本地存储。而cassandra目前集成了rocksdb,scyllaDB采用c++改写性能也强悍得不得了了。所以kafka, flink根本不玩storm + redis这一套,都是采用了rocksdb。
那么对于数据分析领域来说呢? 当然就是知名的SMACK架构了。这里完全采用了Cassandra做存储。
这时候你要问?Cassandra不是对标HBase么,怎么能替换HDFS的存储功能呢?
Cassandra在数据分析上替换HBase已经是正途了。首先Cassandra有kafka, presto各大神器助阵, 接着BI报表厂商也开始纷纷加入。相反呢,HBase基于无力招架,只能眼睁睁被亲爹抛弃。再者说,hadoop这一套也是开始走下坡路,flink/spark开始纷纷拥抱k8s。
由于Cassandra有cql扩展,所以生态很容易扩展,cql类似于sql的语法,非常便于使用。
Cassandra跟HDFS比如何呢?Cassandra 有分区功能,虽然性能比不上HDFS,但是spark + cassandra基本够用了。连hadoop之父也不得不亲口承认spark + cassandra是未来的发展趋势。
当然,如果你用Cassandra只做分析,不做etl也是可以的。选择就很多了,比如ceph, minio这些,所以hdfs也是没有太大优势的。
而这几年ScyllaDB的迅速成长,spark + ScyllaDB 性能已直线上线,完全不用考虑太多。
另外Cassandra采用的是P2P模型,扩容轻松搞定,对于运维来说也是极其方便,即好用又好维护又好扩展,谁会不喜欢呢?
三. ScyllaDB的系统架构
这里就要开始我们的正题了,也是拉开我们源码分析的序幕。
1. ScyllaDB的目录结构
2. ScyllaDB的专有名词
- DHT
- Hinted Handoff
- Snitch
- SSTable
- Memtables
- Commit Log
- Tombstone
- Anti-Entropy
3. ScyllaDB的服务类型
- a. sql_server
- b. storage_service
- c. storage_proxy
- d. Stream Manager
4. ScyllaDB的网络通讯
- Message Service
- Gossip P2P
5. ScyllaDB的数据模型
- System Keyspace
- Wide Column
- TTL
- Masterialized Views