比赛地址:https://tianchi.aliyun.com/competition/entrance/531864/introduction?spm=5176.12281949.1003.16.493e8f15PPTpkV
baseline地址:https://github.com/datawhalechina/team-learning-cv/tree/master/DefectDetection (我自己没有在baseline上跑通,后来重新clone yolov5官方镜像,在文中将会提到)
yolov5官方地址:https://github.com/ultralytics/yolov5
yolo5中文汉化地址:https://github.com/wudashuo/yolov5
赛题背景
在布匹的实际生产过程中,由于各方面因素的影响,会产生污渍、破洞、毛粒等瑕疵,为保证产品质量,需要对布匹进行瑕疵检测。布匹疵点检验是纺织行业生产和质量管理的重要环节,目前人工检测易受主观因素影响,缺乏一致性;并且检测人员在强光下长时间工作对视力影响极大。由于布匹疵点种类繁多、形态变化多样、观察识别难道大,导致布匹疵点智能检测是困扰行业多年的技术瓶颈。
近年来,人工智能和计算机视觉等技术突飞猛进,在工业质检场景中也取得了不错的成果。纺织行业迫切希望借助最先进的技术,实现布匹疵点智能检测。革新质检流程,自动完成质检任务,降低对大量人工的依赖,减少漏检发生率,提高产品的质量。
本赛场聚焦布匹疵点智能检测,要求选手研究开发高效可靠的计算机视觉算法,提升布匹疵点检验的准确度,降低对大量人工的依赖,提升布样疵点质检的效果和效率。要求算法既要检测布匹是否包含疵点,又要给出疵点具体的位置和类别,既考察疵点检出能力、也考察疵点定位和分类能力。
赛题数据
赛题组深入佛山南海纺织车间现场采集布匹图像,制作并发布大规模的高质量布匹疵点数据集,同时提供精细的标注来满足算法要求。大赛数据涵盖了纺织业中布匹的各类重要瑕疵,每张图片含一个或多种瑕疵。本次比赛主要使用花色布数据,约12000张。
数据示例
花色布数据包含原始图片、模板图片和瑕疵的标注数据。标注数据详细标注出疵点所在的具体位置和疵点类别,,数据示例如下。

训练数据文件结构
我们将提供用于训练的图像数据和识别标签,文件夹结构:
|-- defect Images #存放有瑕疵的图像数据
|-- normal Images #存放无疵点的图像数据,jpeg编码图像文件
|-- Annotations #存放属性标签标注数据
|-- README.md #对数据的详细介绍
数据下载地址:
guangdong1_round2_train2_20191004_images.zip
guangdong1_round2_train2_20191004_Annotations.zip
代码运行
前提
- 将数据集下载后放到代码根目录下的train_data文件夹中,并解压
- 在yolov5 release下下载预训练好的权重
运行过程
python convertTrainLabel.pypython process_data_yolo.py- 修改process_data_yolo.py
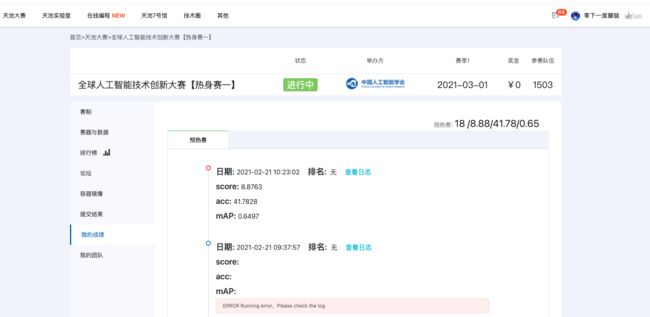
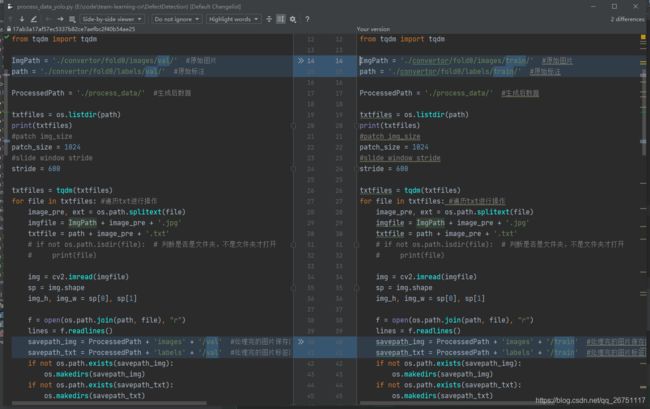
rain.sh文件中,第二步使用了process_data_yolo.py,源码中关于数据集存放位置存在问题,只写了val的处理,没写train的处理,所以生成的process_data文件夹中, 只有val而没有train,训练时会报错。
所以不能直接用train.sh脚本,要顺序运行里面的命令,到第二步的时候,先执行一遍,如下图做修改后再执行一遍,从而把训练集和验证集都准备好。
- 再次运行
python process_data_yolo.py rm -rf ./convertor-
python train.py,在运行train.py的时候遇到了问题,我首先从官方仓库中下载了yolov5x.pt权重,但是在运行过程中报错AttributeError:Can't get attribute 'C3' on,也就说说没有C3这个属性,官方Issue,两个建议一是安装完整的requirements.txt,尝试无果;二是说代码需要更新,我就重新clone了官方代码,运行OK,没有问题了,运行5个epoch,几分钟时间,速度就是很快,开心。
注意- convertTrainLabel和process_data_yolo代码其实这个时候用不到了,可以不拷贝过来,但是需要把最终生成的process_data目录放到yolov5代码根目录下
- 修改data/coco128.yaml,作用为指定训练和验证集目录,指定类别数量和种类
# train and val datasets (image directory or *.txt file with image paths) train: ./process_data/images/train/ val: ./process_data/images/val/ # number of classes nc: 15 # class names names: ['1', '2', '3', '4', '5', '6', '7', '8', '9', '10', '11', '12','13', '14', '15']
提交Docker
运行完以后就需要打包docker镜像了
- 将yolov5代码重新放到一个文件中中,如yolo,直接使用clone的也行,但是记得删除训练的图片,要不打包镜像很大的
- 修改dockerfile,内容如下,我为了打包的镜像小一点直接用的基础python3的镜像,这个是没有GPU的,不过只是测试了,有没有都没那么重要了
# Start FROM Nvidia PyTorch image https://ngc.nvidia.com/catalog/containers/nvidia:pytorch
FROM registry.cn-shanghai.aliyuncs.com/tcc-public/python:3
# Install linux packages
RUN apt update && apt install -y screen libgl1-mesa-glx
## 把当前文件夹里的文件构建到镜像的根目录下
ADD . /
## 指定默认工作目录为根目录(需要把run.sh和生成的结果文件都放在该文件夹下,提交后才能运行)
WORKDIR /
# Install python dependencies
RUN python -m pip install --upgrade pip
RUN pip install -i https://pypi.tuna.tsinghua.edu.cn/simple -r requirements.txt gsutil
## 镜像启动后统一执行 sh run.sh
CMD ["sh", "run.sh"]
- 修改requirements.txt
# pip install -r requirements.txt
# base ----------------------------------------
Cython
matplotlib>=3.2.2
numpy>=1.18.5
opencv-python>=4.1.2
Pillow
PyYAML>=5.3.1
scipy>=1.4.1
tensorboard>=2.2
torch>=1.7.0
torchvision>=0.8.1
tqdm>=4.41.0
# logging -------------------------------------
# wandb
# plotting ------------------------------------
seaborn>=0.11.0
pandas
# export --------------------------------------
# coremltools>=4.1
# onnx>=1.8.1
# scikit-learn==0.19.2 # for coreml quantization
# extras --------------------------------------
thop # FLOPS computation
pycocotools>=2.0 # COCO mAP
- 创建run.sh
python getImage.py
python detect.py
- 创建getImage.py,因为天池的测试数据集都在tcdata下,而且一张图片一个文件夹,为了方便就将待检测都放到defect文件夹下
import os
import shutil as sh
defect_imgs = '/defect'
os.makedirs(defect_imgs)
path = '/tcdata/guangdong1_round2_testB_20191024'
folders = os.listdir(path)
for folder in folders:
locations = os.path.join(path,folder,folder+'.jpg')
if os.path.exists(locations):
sh.copy(locations,defect_imgs)
- 修改detect.py,参照baseline的代码修改yolov5的detect代码,主要是为了保存需要提交的result.json,该文件需要注意的就是一个地方:参数weights需要将你生成的权重地址修改好
import argparse
import time
from pathlib import Path
import cv2
import torch
import torch.backends.cudnn as cudnn
from numpy import random
import os
import json
from models.experimental import attempt_load
from utils.datasets import LoadStreams, LoadImages
from utils.general import check_img_size, check_requirements, check_imshow, non_max_suppression, apply_classifier, \
scale_coords, xyxy2xywh, strip_optimizer, set_logging, increment_path
from utils.plots import plot_one_box
from utils.torch_utils import select_device, load_classifier, time_synchronized
def detect(save_img=False):
source, weights, view_img, save_txt, imgsz = opt.source, opt.weights, opt.view_img, opt.save_txt, opt.img_size
webcam = source.isnumeric() or source.endswith('.txt') or source.lower().startswith(
('rtsp://', 'rtmp://', 'http://'))
# Directories
save_dir = Path(increment_path(Path(opt.project) / opt.name, exist_ok=opt.exist_ok)) # increment run
(save_dir / 'labels' if save_txt else save_dir).mkdir(parents=True, exist_ok=True) # make dir
# Initialize
set_logging()
device = select_device(opt.device)
half = device.type != 'cpu' # half precision only supported on CUDA
# Load model
model = attempt_load(weights, map_location=device) # load FP32 model
stride = int(model.stride.max()) # model stride
imgsz = check_img_size(imgsz, s=stride) # check img_size
if half:
model.half() # to FP16
# Second-stage classifier
classify = False
if classify:
modelc = load_classifier(name='resnet101', n=2) # initialize
modelc.load_state_dict(torch.load('weights/resnet101.pt', map_location=device)['model']).to(device).eval()
# Set Dataloader
vid_path, vid_writer = None, None
if webcam:
view_img = check_imshow()
cudnn.benchmark = True # set True to speed up constant image size inference
dataset = LoadStreams(source, img_size=imgsz, stride=stride)
else:
save_img = True
dataset = LoadImages(source, img_size=imgsz, stride=stride)
# Get names and colors
names = model.module.names if hasattr(model, 'module') else model.names
colors = [[random.randint(0, 255) for _ in range(3)] for _ in names]
# Run inference
if device.type != 'cpu':
model(torch.zeros(1, 3, imgsz, imgsz).to(device).type_as(next(model.parameters()))) # run once
t0 = time.time()
save_json = True
result = []
for path, img, im0s, vid_cap in dataset:
img = torch.from_numpy(img).to(device)
img = img.half() if half else img.float() # uint8 to fp16/32
img /= 255.0 # 0 - 255 to 0.0 - 1.0
if img.ndimension() == 3:
img = img.unsqueeze(0)
# Inference
t1 = time_synchronized()
pred = model(img, augment=opt.augment)[0]
# Apply NMS
pred = non_max_suppression(pred, opt.conf_thres, opt.iou_thres, classes=opt.classes, agnostic=opt.agnostic_nms)
t2 = time_synchronized()
# Apply Classifier
if classify:
pred = apply_classifier(pred, modelc, img, im0s)
# Process detections
for i, det in enumerate(pred): # detections per image
if webcam: # batch_size >= 1
p, s, im0, frame = path[i], '%g: ' % i, im0s[i].copy(), dataset.count
else:
p, s, im0, frame = path, '', im0s, getattr(dataset, 'frame', 0)
p = Path(p) # to Path
save_path = str(save_dir / p.name) # img.jpg
txt_path = str(save_dir / 'labels' / p.stem) + ('' if dataset.mode == 'image' else f'_{frame}') # img.txt
s += '%gx%g ' % img.shape[2:] # print string
gn = torch.tensor(im0.shape)[[1, 0, 1, 0]] # normalization gain whwh
if len(det):
# Rescale boxes from img_size to im0 size
det[:, :4] = scale_coords(img.shape[2:], det[:, :4], im0.shape).round()
# Print results
for c in det[:, -1].unique():
n = (det[:, -1] == c).sum() # detections per class
s += f"{n} {names[int(c)]}{'s' * (n > 1)}, " # add to string
# Write results
for *xyxy, conf, cls in reversed(det):
if save_txt: # Write to file
xywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(-1).tolist() # normalized xywh
line = (cls, *xywh, conf) if opt.save_conf else (cls, *xywh) # label format
with open(txt_path + '.txt', 'a') as f:
f.write(('%g ' * len(line)).rstrip() % line + '\n')
# write jiang #################
if save_json:
name = os.path.split(txt_path)[-1]
# print(name)
x1, y1, x2, y2 = float(xyxy[0]), float(xyxy[1]), float(xyxy[2]), float(xyxy[3])
bbox = [x1, y1, x2, y2]
img_name = name
conf = float(conf)
#add solution remove other
result.append(
{'name': img_name+'.jpg', 'category': int(cls+1), 'bbox': bbox,
'score': conf})
print("result: ", {'name': img_name+'.jpg', 'category': int(cls+1), 'bbox': bbox,'score': conf})
if save_img or view_img: # Add bbox to image
label = f'{names[int(cls)]} {conf:.2f}'
plot_one_box(xyxy, im0, label=label, color=colors[int(cls)], line_thickness=3)
# Print time (inference + NMS)
print(f'{s}Done. ({t2 - t1:.3f}s)')
# Stream results
if view_img:
cv2.imshow(str(p), im0)
cv2.waitKey(1) # 1 millisecond
# Save results (image with detections)
if save_img:
if dataset.mode == 'image':
cv2.imwrite(save_path, im0)
else: # 'video'
if vid_path != save_path: # new video
vid_path = save_path
if isinstance(vid_writer, cv2.VideoWriter):
vid_writer.release() # release previous video writer
fourcc = 'mp4v' # output video codec
fps = vid_cap.get(cv2.CAP_PROP_FPS)
w = int(vid_cap.get(cv2.CAP_PROP_FRAME_WIDTH))
h = int(vid_cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
vid_writer = cv2.VideoWriter(save_path, cv2.VideoWriter_fourcc(*fourcc), fps, (w, h))
vid_writer.write(im0)
if save_txt or save_img:
s = f"\n{len(list(save_dir.glob('labels/*.txt')))} labels saved to {save_dir / 'labels'}" if save_txt else ''
print(f"Results saved to {save_dir}{s}")
if save_json:
with open(os.path.join("/result.json"), 'w') as fp:
json.dump(result, fp, indent=4, ensure_ascii=False)
print(f'Done. ({time.time() - t0:.3f}s)')
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--weights', nargs='+', type=str, default='./runs/train/exp3/weights/best.pt', help='model.pt path(s)')
parser.add_argument('--source', type=str, default='/defect', help='source') # file/folder, 0 for webcam
parser.add_argument('--save_dir', type=str, default='/', help='result save dir')
parser.add_argument('--img-size', type=int, default=640, help='inference size (pixels)')
parser.add_argument('--conf-thres', type=float, default=0.25, help='object confidence threshold')
parser.add_argument('--iou-thres', type=float, default=0.45, help='IOU threshold for NMS')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--view-img', action='store_true', help='display results')
parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')
parser.add_argument('--save-conf', action='store_true', help='save confidences in --save-txt labels')
parser.add_argument('--classes', nargs='+', type=int, help='filter by class: --class 0, or --class 0 2 3')
parser.add_argument('--agnostic-nms', action='store_true', help='class-agnostic NMS')
parser.add_argument('--augment', action='store_true', help='augmented inference')
parser.add_argument('--update', action='store_true', help='update all models')
parser.add_argument('--project', default='runs/detect', help='save results to project/name')
parser.add_argument('--name', default='exp', help='save results to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
opt = parser.parse_args()
print(opt)
check_requirements()
with torch.no_grad():
if opt.update: # update all models (to fix SourceChangeWarning)
for opt.weights in ['yolov5s.pt', 'yolov5m.pt', 'yolov5l.pt', 'yolov5x.pt']:
detect()
strip_optimizer(opt.weights)
else:
detect()
-
build镜像
docker build -t registry.cn-shenzhen.aliyuncs.com/your namespace:cv1.2 .

-
push镜像
docker push registry.cn-shenzhen.aliyuncs.com/your namespace:cv1.2

-
最终结果