001. HTTP 报文结构是怎样的?
对于 TCP 而言,在传输的时候分为两个部分:TCP头和数据部分。
而 HTTP 类似,也是header + body的结构,具体而言:
起始行 + 头部 + 空行 + 实体
由于 http 请求报文和响应报文是有一定区别,因此我们分开介绍。
起始行
对于请求报文来说,起始行类似下面这样:
GET /home HTTP/1.1
也就是方法 + 路径 + http版本。
对于响应报文来说,起始行一般张这个样:
HTTP/1.1 200 OK
响应报文的起始行也叫做状态行。由http版本、状态码和原因三部分组成。
值得注意的是,在起始行中,每两个部分之间用空格隔开,最后一个部分后面应该接一个换行,严格遵循ABNF语法规范。
头部
展示一下请求头和响应头在报文中的位置:


不管是请求头还是响应头,其中的字段是相当多的,而且牵扯到http非常多的特性,这里就不一一列举的,重点看看这些头部字段的格式:
- 字段名不区分大小写
- 字段名不允许出现空格,不可以出现下划线_
- 字段名后面必须紧接着:
空行
很重要,用来区分开头部和实体。
问: 如果说在头部中间故意加一个空行会怎么样?
那么空行后的内容全部被视为实体。
实体
就是具体的数据了,也就是body部分。请求报文对应请求体, 响应报文对应响应体。
002. 如何理解 HTTP 的请求方法?
有哪些请求方法?
http/1.1规定了以下请求方法(注意,都是大写):
- GET: 通常用来获取资源
- HEAD: 获取资源的元信息
- POST: 提交数据,即上传数据
- PUT: 修改数据
- DELETE: 删除资源(几乎用不到)
- CONNECT: 建立连接隧道,用于代理服务器
- OPTIONS: 列出可对资源实行的请求方法,用来跨域请求
- TRACE: 追踪请求-响应的传输路径
GET 和 POST 有什么区别?
GET 和 POST 的区别
004: 如何理解 HTTP 状态码?
HTTP 应答状态码
005: 简要概括一下 HTTP 的特点?HTTP 有哪些缺点?
HTTP 特点
HTTP 的特点概括如下:
- 灵活可扩展,主要体现在两个方面。一个是语义上的自由,只规定了基本格式,比如空格分隔单词,换行分隔字段,其他的各个部分都没有严格的语法限制。另一个是传输形式的多样性,不仅仅可以传输文本,还能传输图片、视频等任意数据,非常方便。
- 可靠传输。HTTP 基于 TCP/IP,因此把这一特性继承了下来。这属于 TCP 的特性,不具体介绍了。
- 请求-应答。也就是一发一收、有来有回, 当然这个请求方和应答方不单单指客户端和服务器之间,如果某台服务器作为代理来连接后端的服务端,那么这台服务器也会扮演请求方的角色。
- 无状态。这里的状态是指通信过程的上下文信息,而每次 http 请求都是独立、无关的,默认不需要保留状态信息。
HTTP 缺点
无状态
所谓的优点和缺点还是要分场景来看的,对于 HTTP 而言,最具争议的地方在于它的无状态。
在需要长连接的场景中,需要保存大量的上下文信息,以免传输大量重复的信息,那么这时候无状态就是 http 的缺点了。
但与此同时,另外一些应用仅仅只是为了获取一些数据,不需要保存连接上下文信息,无状态反而减少了网络开销,成为了 http 的优点。
明文传输
即协议里的报文(主要指的是头部)不使用二进制数据,而是文本形式。
这当然对于调试提供了便利,但同时也让 HTTP 的报文信息暴露给了外界,给攻击者也提供了便利。WIFI陷阱就是利用 HTTP 明文传输的缺点,诱导你连上热点,然后疯狂抓你所有的流量,从而拿到你的敏感信息。
队头阻塞问题
当 http 开启长连接时,共用一个 TCP 连接,同一时刻只能处理一个请求,那么当前请求耗时过长的情况下,其它的请求只能处于阻塞状态,也就是著名的队头阻塞问题。
006: 对 Accept 系列字段了解多少?
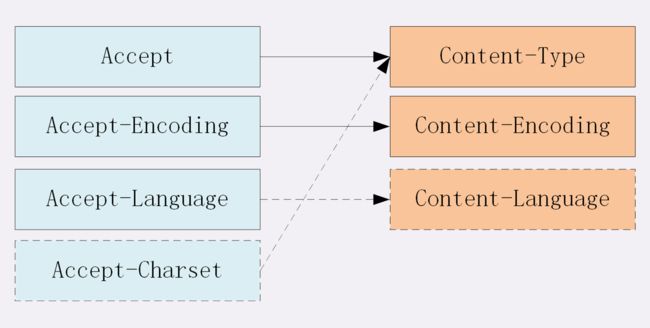
对于Accept系列字段的介绍分为四个部分: 数据格式、压缩方式、支持语言和字符集。
数据格式
上一节谈到 HTTP 灵活的特性,它支持非常多的数据格式,那么这么多格式的数据一起到达客户端,客户端怎么知道它的格式呢?
当然,最低效的方式是直接猜,有没有更好的方式呢?直接指定可以吗?
答案是肯定的。不过首先需要介绍一个标准——MIME(Multipurpose Internet Mail Extensions, 多用途互联网邮件扩展)。它首先用在电子邮件系统中,让邮件可以发任意类型的数据,这对于 HTTP 来说也是通用的。
因此,HTTP 从MIME type取了一部分来标记报文 body 部分的数据类型,这些类型体现在Content-Type这个字段,当然这是针对于发送端而言,接收端想要收到特定类型的数据,也可以用Accept字段。
具体而言,这两个字段的取值可以分为下面几类:
- text: text/html, text/plain, text/css 等
- image: image/gif, image/jpeg, image/png 等
- audio/video: audio/mpeg, video/mp4 等
- application: application/json, application/javascript, application/pdf, application/octet-stream
压缩方式
当然一般这些数据都是会进行编码压缩的,采取什么样的压缩方式就体现在了发送方的Content-Encoding字段上, 同样的,接收什么样的压缩方式体现在了接受方的Accept-Encoding字段上。这个字段的取值有下面几种:
- gzip: 当今最流行的压缩格式
- deflate: 另外一种著名的压缩格式
- br: 一种专门为 HTTP 发明的压缩算法
// 发送端
Content-Encoding: gzip
// 接收端
Accept-Encoding: gzip
支持语言
对于发送方而言,还有一个Content-Language字段,在需要实现国际化的方案当中,可以用来指定支持的语言,在接受方对应的字段为Accept-Language。如:
// 发送端
Content-Language: zh-CN, zh, en
// 接收端
Accept-Language: zh-CN, zh, en
字符集
最后是一个比较特殊的字段, 在接收端对应为Accept-Charset,指定可以接受的字符集,而在发送端并没有对应的Content-Charset, 而是直接放在了Content-Type中,以charset属性指定。如:
// 发送端
Content-Type: text/html; charset=utf-8
// 接收端
Accept-Charset: charset=utf-8
最后以一张图来总结一下吧:
008: HTTP 如何处理大文件的传输?
对于几百 M 甚至上 G 的大文件来说,如果要一口气全部传输过来显然是不现实的,会有大量的等待时间,严重影响用户体验。因此,HTTP 针对这一场景,采取了范围请求的解决方案,允许客户端仅仅请求一个资源的一部分。
如何支持
当然,前提是服务器要支持范围请求,要支持这个功能,就必须加上这样一个响应头:
Accept-Ranges: none
用来告知客户端这边是支持范围请求的。
Range 字段拆解
而对于客户端而言,它需要指定请求哪一部分,通过Range这个请求头字段确定,格式为bytes=x-y。接下来就来讨论一下这个 Range 的书写格式:
- 0-499表示从开始到第 499 个字节。
- 500- 表示从第 500 字节到文件终点。
- -100表示文件的最后100个字节。
服务器收到请求之后,首先验证范围是否合法,如果越界了那么返回416错误码,否则读取相应片段,返回206状态码。
同时,服务器需要添加Content-Range字段,这个字段的格式根据请求头中Range字段的不同而有所差异。
具体来说,请求单段数据和请求多段数据,响应头是不一样的。
举个例子:
// 单段数据
Range: bytes=0-9
// 多段数据
Range: bytes=0-9, 30-39
接下来我们就分别来讨论着两种情况。
单段数据
对于单段数据的请求,返回的响应如下:
HTTP/1.1 206 Partial Content
Content-Length: 10
Accept-Ranges: bytes
Content-Range: bytes 0-9/100
i am xxxxx
值得注意的是Content-Range字段,0-9表示请求的返回,100表示资源的总大小,很好理解。
多段数据
接下来我们看看多段请求的情况。得到的响应会是下面这个形式:
HTTP/1.1 206 Partial Content
Content-Type: multipart/byteranges; boundary=00000010101
Content-Length: 189
Connection: keep-alive
Accept-Ranges: bytes
--00000010101
Content-Type: text/plain
Content-Range: bytes 0-9/96
i am xxxxx
--00000010101
Content-Type: text/plain
Content-Range: bytes 20-29/96
eex jspy e
--00000010101--
这个时候出现了一个非常关键的字段Content-Type: multipart/byteranges;boundary=00000010101,它代表了信息量是这样的:
- 请求一定是多段数据请求
- 响应体中的分隔符是 00000010101
因此,在响应体中各段数据之间会由这里指定的分隔符分开,而且在最后的分隔末尾添上--表示结束。
以上就是 http 针对大文件传输所采用的手段。
009: HTTP 中如何处理表单数据的提交?
在 http 中,有两种主要的表单提交的方式,体现在两种不同的Content-Type取值:
- application/x-www-form-urlencoded
- multipart/form-data
由于表单提交一般是POST请求,很少考虑GET,因此这里我们将默认提交的数据放在请求体中。
application/x-www-form-urlencoded
对于application/x-www-form-urlencoded格式的表单内容,有以下特点:
- 其中的数据会被编码成以&分隔的键值对
- 字符以URL编码方式编码。
// 转换过程: {a: 1, b: 2} -> a=1&b=2 -> 如下(最终形式)
"a%3D1%26b%3D2"
multipart/form-data
对于multipart/form-data而言:
- 请求头中的Content-Type字段会包含boundary,且boundary的值有浏览器默认指定。例: Content-Type: multipart/form-data;boundary=----WebkitFormBoundaryRRJKeWfHPGrS4LKe。
- 数据会分为多个部分,每两个部分之间通过分隔符来分隔,每部分表述均有 HTTP 头部描述子包体,如Content-Type,在最后的分隔符会加上--表示结束。
相应的请求体是下面这样:
Content-Disposition: form-data;name="data1";
Content-Type: text/plain
data1
----WebkitFormBoundaryRRJKeWfHPGrS4LKe
Content-Disposition: form-data;name="data2";
Content-Type: text/plain
data2
----WebkitFormBoundaryRRJKeWfHPGrS4LKe--
小结
值得一提的是,multipart/form-data 格式最大的特点在于:每一个表单元素都是独立的资源表述。
另外,你可能在写业务的过程中,并没有注意到其中还有boundary的存在,如果你打开抓包工具,确实可以看到不同的表单元素被拆分开了,之所以在平时感觉不到,是以为浏览器和 HTTP 给你封装了这一系列操作。
而且,在实际的场景中,对于图片等文件的上传,基本采用multipart/form-data而不用application/x-www-form-urlencoded,因为没有必要做 URL 编码,带来巨大耗时的同时也占用了更多的空间。
010: HTTP1.1 如何解决 HTTP 的队头阻塞问题?
什么是 HTTP 队头阻塞?
HTTP 传输是基于请求-应答的模式进行的,报文必须是一发一收,但值得注意的是,里面的任务被放在一个任务队列中串行执行,一旦队首的请求处理太慢,就会阻塞后面请求的处理。这就是著名的HTTP队头阻塞问题。
并发连接
对于一个域名允许分配多个长连接,那么相当于增加了任务队列,不至于一个队伍的任务阻塞其它所有任务。在RFC2616规定过客户端最多并发 2 个连接,不过事实上在现在的浏览器标准中,这个上限要多很多,Chrome 中是 6 个。
但其实,即使是提高了并发连接,还是不能满足人们对性能的需求。
域名分片
一个域名不是可以并发 6 个长连接吗?那我就多分几个域名。
比如 content1.sanyuan.com 、content2.sanyuan.com。
这样一个sanyuan.com域名下可以分出非常多的二级域名,而它们都指向同样的一台服务器,能够并发的长连接数更多了,事实上也更好地解决了队头阻塞的问题。
011: 对 Cookie 了解多少?
Cookie 简介
前面说到了 HTTP 是一个无状态的协议,每次 http 请求都是独立、无关的,默认不需要保留状态信息。但有时候需要保存一些状态,怎么办呢?
HTTP 为此引入了 Cookie。
Cookie 本质上就是浏览器里面存储的一个很小的文本文件,内部以键值对的方式来存储(在chrome开发者面板的Application这一栏可以看到)。
向同一个域名下发送请求,都会携带相同的 Cookie,服务器拿到 Cookie 进行解析,便能拿到客户端的状态。
而服务端可以通过响应头中的Set-Cookie字段来对客户端写入Cookie。举例如下:
// 请求头
Cookie: a=xxx;b=xxx
// 响应头
Set-Cookie: a=xxx
set-Cookie: b=xxx
Cookie 属性
生存周期
Cookie 的有效期可以通过Expires和Max-Age两个属性来设置。
- Expires即过期时间
- Max-Age用的是一段时间间隔,单位是秒,从浏览器收到报文开始计算。
若 Cookie 过期,则这个 Cookie 会被删除,并不会发送给服务端。
作用域
关于作用域也有两个属性: Domain和path, 给 Cookie 绑定了域名和路径,在发送请求之前,发现域名或者路径和这两个属性不匹配,那么就不会带上 Cookie。
值得注意的是,对于路径来说,/表示域名下的任意路径都允许使用 Cookie。
安全相关
如果带上Secure,说明只能通过 HTTPS 传输 cookie。
如果 cookie 字段带上HttpOnly,那么说明只能通过 HTTP 协议传输,不能通过 JS 访问,这也是预防 XSS 攻击的重要手段。
相应的,对于 CSRF 攻击的预防,也有SameSite属性。
SameSite可以设置为三个值,Strict、Lax和None。
- a. 在Strict模式下,浏览器完全禁止第三方请求携带Cookie。比如请求sanyuan.com网站只能在sanyuan.com域名当中请求才能携带 Cookie,在其他网站请求都不能。
- b. 在Lax模式,就宽松一点了,但是只能在 get 方法提交表单况或者a 标签发送 get 请求的情况下可以携带 Cookie,其他情况均不能。
- c. 在None模式下,也就是默认模式,请求会自动携带上 Cookie。
Cookie 的缺点
- 容量缺陷。Cookie 的体积上限只有4KB,只能用来存储少量的信息。
- 性能缺陷。Cookie 紧跟域名,不管域名下面的某一个地址需不需要这个 Cookie ,请求都会携带上完整的 Cookie,这样随着请求数的增多,其实会造成巨大的性能浪费的,因为请求携带了很多不必要的内容。但可以通过Domain和Path指定作用域来解决。
- 安全缺陷。由于 Cookie 以纯文本的形式在浏览器和服务器中传递,很容易被非法用户截获,然后进行一系列的篡改,在 Cookie 的有效期内重新发送给服务器,这是相当危险的。另外,在HttpOnly为 false 的情况下,Cookie 信息能直接通过 JS 脚本来读取。
013: 如何理解 HTTP 缓存及缓存代理?
浏览器的缓存机制
强缓存
浏览器中的缓存作用分为两种情况,一种是需要发送HTTP请求,一种是不需要发送。
首先是检查强缓存,这个阶段不需要发送HTTP请求。
如何来检查呢?通过相应的字段来进行,但是说起这个字段就有点门道了。
在HTTP/1.0和HTTP/1.1当中,这个字段是不一样的。在早期,也就是HTTP/1.0时期,使用的是Expires,而HTTP/1.1使用的是Cache-Control。让我们首先来看看Expires。
Expires
Expires即过期时间,存在于服务端返回的响应头中,告诉浏览器在这个过期时间之前可以直接从缓存里面获取数据,无需再次请求。
Expires: Wed, 22 Nov 2019 08:41:00 GMT
表示资源在2019年11月22号8点41分过期,过期了就得向服务端发请求。
这个方式看上去没什么问题,合情合理,但其实潜藏了一个坑,那就是服务器的时间和浏览器的时间可能并不一致,那服务器返回的这个过期时间可能就是不准确的。因此这种方式很快在后来的HTTP1.1版本中被抛弃了。
Cache-Control
在HTTP1.1中,采用了一个非常关键的字段:Cache-Control。这个字段也是存在于
它和Expires本质的不同在于它并没有采用具体的过期时间点这个方式,而是采用过期时长来控制缓存,对应的字段是max-age。比如这个例子:
Cache-Control:max-age=3600
代表这个响应返回后在 3600 秒,也就是一个小时之内可以直接使用缓存。
如果你觉得它只有max-age一个属性的话,那就大错特错了。
它其实可以组合非常多的指令,完成更多场景的缓存判断, 将一些关键的属性列举如下:
public: 客户端和代理服务器都可以缓存。因为一个请求可能要经过不同的代理服务器最后才到达目标服务器,那么结果就是不仅仅浏览器可以缓存数据,中间的任何代理节点都可以进行缓存。
private: 这种情况就是只有浏览器能缓存了,中间的代理服务器不能缓存。
no-cache: 跳过当前的强缓存,发送HTTP请求,即直接进入协商缓存阶段。
no-store:非常粗暴,不进行任何形式的缓存。
s-maxage:这和max-age长得比较像,但是区别在于s-maxage是针对代理服务器的缓存时间。
must-revalidate: 是缓存就会有过期的时候,加上这个字段一旦缓存过期,就必须回到源服务器验证。
值得注意的是,当Expires和Cache-Control同时存在的时候,Cache-Control会优先考虑。
当然,还存在一种情况,当资源缓存时间超时了,也就是强缓存失效了,接下来怎么办?没错,这样就进入到第二级屏障——协商缓存了。
协商缓存
强缓存失效之后,浏览器在请求头中携带相应的缓存tag来向服务器发请求,由服务器根据这个tag,来决定是否使用缓存,这就是协商缓存。
具体来说,这样的缓存tag分为两种: Last-Modified 和 ETag。这两者各有优劣,并不存在谁对谁有绝对的优势,跟上面强缓存的两个 tag 不一样。
Last-Modified
即最后修改时间。在浏览器第一次给服务器发送请求后,服务器会在响应头中加上这个字段。
浏览器接收到后,如果再次请求,会在请求头中携带If-Modified-Since字段,这个字段的值也就是服务器传来的最后修改时间。
服务器拿到请求头中的If-Modified-Since的字段后,其实会和这个服务器中该资源的最后修改时间对比:
- 如果请求头中的这个值小于最后修改时间,说明是时候更新了。返回新的资源,跟常规的HTTP请求响应的流程一样。
- 否则返回304,告诉浏览器直接用缓存。
ETag
ETag 是服务器根据当前文件的内容,给文件生成的唯一标识,只要里面的内容有改动,这个值就会变。服务器通过响应头把这个值给浏览器。
浏览器接收到ETag的值,会在下次请求时,将这个值作为If-None-Match这个字段的内容,并放到请求头中,然后发给服务器。
服务器接收到If-None-Match后,会跟服务器上该资源的ETag进行比对:
- 如果两者不一样,说明要更新了。返回新的资源,跟常规的HTTP请求响应的流程一样。
- 否则返回304,告诉浏览器直接用缓存。
两者对比
- 在精准度上,ETag优于Last-Modified。优于 ETag 是按照内容给资源上标识,因此能准确感知资源的变化。而 Last-Modified 就不一样了,它在一些特殊的情况并不能准确感知资源变化,主要有两种情况:
- 编辑了资源文件,但是文件内容并没有更改,这样也会造成缓存失效。
- Last-Modified 能够感知的单位时间是秒,如果文件在 1 秒内改变了多次,那么这时候的 Last-Modified 并没有体现出修改了。
- 在性能上,Last-Modified优于ETag,也很简单理解,Last-Modified仅仅只是记录一个时间点,而 Etag需要根据文件的具体内容生成哈希值。
另外,如果两种方式都支持的话,服务器会优先考虑ETag。
缓存位置
前面我们已经提到,当强缓存命中或者协商缓存中服务器返回304的时候,我们直接从缓存中获取资源。那这些资源究竟缓存在什么位置呢?
浏览器中的缓存位置一共有四种,按优先级从高到低排列分别是:
- Service Worker
- Memory Cache
- Disk Cache
- Push Cache
Service Worker
Service Worker 借鉴了 Web Worker的 思路,即让 JS 运行在主线程之外,由于它脱离了浏览器的窗体,因此无法直接访问DOM。虽然如此,但它仍然能帮助我们完成很多有用的功能,比如离线缓存、消息推送和网络代理等功能。其中的离线缓存就是 Service Worker Cache。
Memory Cache 和 Disk Cache
Memory Cache指的是内存缓存,从效率上讲它是最快的。但是从存活时间来讲又是最短的,当渲染进程结束后,内存缓存也就不存在了。
Disk Cache就是存储在磁盘中的缓存,从存取效率上讲是比内存缓存慢的,但是他的优势在于存储容量和存储时长。稍微有些计算机基础的应该很好理解,就不展开了。
好,现在问题来了,既然两者各有优劣,那浏览器如何决定将资源放进内存还是硬盘呢?主要策略如下:
- 比较大的JS、CSS文件会直接被丢进磁盘,反之丢进内存
- 内存使用率比较高的时候,文件优先进入磁盘
Push Cache
即推送缓存,这是浏览器缓存的最后一道防线。它是 HTTP/2 中的内容,虽然现在应用的并不广泛,但随着 HTTP/2 的推广,它的应用越来越广泛。
参考
(建议精读)HTTP灵魂之问,巩固你的 HTTP 知识体系
001: 能不能说一说前端缓存?