tensorflow serving入门笔记
tensorflow serving入门
1. 部署
网上关于tensorflow serving的详细讲解很多。本人不是专门做机器学习的,所以讲不好,就不班门弄斧了。直接说自己的使用过程。多说一句,个人理解tensorflow serving是tensorflow官方版本的模型部署工具包。提供了模型加载、解析、接口封装暴露功能。其中暴露了restful API和GRPC两种模式。
进入正题,tensorflow serving有三种模式。建议采用docker方式,因为最简单,而且容器化已经基本确定了其主流地位。
# 最新版的镜像,该版本镜像是不支持二次开发和改造的。很多内容是固定的。对于我们不熟服务来说是可行的。
docker pull tensorflow/serving:latest
# 可以调整的镜像
docker pull tensorflow/serving:latest-devel多说一句,由于本人环境问题,docker的镜像仓库是绑定在了内网服务器上。不能拉取,只能曲线救国。先在其他服务器上,拉取镜像,然后通过docker save/load命令。保存和加载镜像。注意docker export/import这个命令是操作容器的。一开始就吃了这个亏。
部署命令,网上及管网的部署命令是这样的:
# 这里half_plus_two是管网提供的一个模型例子。
docker run -t --rm -p 8501:8501 \
-v "$TESTDATA/saved_model_half_plus_two_cpu:/models/half_plus_two" \
-e MODEL_NAME=half_plus_two \ tensorflow/serving &
网上查到的例子,可能是使用的–mount替换了-v。它们都是一样的,就是将宿主机物理地址挂在到容器指定目录下。
由于网络问题,经常访问不了github,因此没有下载下来这个模型文件,同时,我目标也不是将宿主机挂在到容器中。我是要部署在k8s中的。因此想将整个过程封装为镜像。
通过上面命令,我们明显感觉到以下几点:
- tensorflow serving的模型默认加载地址是/models;当然这个地址也是可以配置的。
- 对于单模型,可以通过MODEL_NAME环境变量来指定,同时需要与模型存放目录一致即/models/{MODEL_NAME}/{version}/.pb等文件。
基于上面考虑,我准备了两个模型,一个是tensorflow官网入门模型,手写数字识别的,一个是简单的加法模型。源码如下:
import tensorflow as tf
# 声明mnist对象,用于加载数据。
mnist = tf.keras.datasets.mnist
# 加载数据,并赋值给相关向量和数据声明
(x_train, y_train), (x_test, y_test) = mnist.load_data("mnist.npz")
print(x_train[0])
# 将整数转为小数,也就是rgb小数
x_train, x_test = x_train/255.0, x_test/255.0
# 创建模型,我们既可以通过new model,然后添加各层,也可以通过Sequential定义各层.
model = tf.keras.models.Sequential([
# 将数据压缩为一维的,接受一个inputshape
tf.keras.layers.Flatten(input_shape=(28, 28)),
# 全连接层,将数据输出为128维的向量空间,激活函数为relu,可以有效梯度下降的激活函数
tf.keras.layers.Dense(128, activation='relu'),
# 定义随机放弃的概率,用于减少计算量
tf.keras.layers.Dropout(0.2),
# 全连接层,输出为10,激活函数为softmax分类函数。
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer='adam',
loss= 'sparse_categorical_crossentropy',
metrics=['accuracy']
)
model.fit(x_train, y_train, epochs= 5)
model.evaluate(x_test, y_test, verbose= 2)
model.save("models/first", save_format="tf")
加法模型
# 尝试一个简单的加法运算
import numpy as np
import tensorflow as tf
# 训练数据为-100到100的加法
x = np.random.randint(-100, 100, (10000, 2))
y = x.sum(axis=1)
print(x)
print(y)
# 验证数据集
t_x = np.random.randint(1000, 10000, (2000, 2))
t_y = t_x.sum(axis=1)
# 构建模型
model = tf.keras.Sequential([
tf.keras.layers.Dense(10, activation='relu'),
tf.keras.layers.Dense(10, activation='relu'),
tf.keras.layers.Dense(1, activation=None),
])
model.build((None, 2))
model.compile(optimizer=tf.keras.optimizers.Adam(0.01), loss='mae')
# 填充数据,并训练
model.fit(x, y, epochs=20, verbose=1, validation_data=(t_x, t_y))
# 保存模型
model.save("models/plus", save_format="tf")我们将两个模型都拷贝到文件夹下。
这里分两条线来说。
单模型部署
docerfile 如下:
from tensorflow/serving:latest
RUN mkdir -p /models/plus/1
ADD models/plus /models/plus/1/
ENV MODEL_NAME=plus启动命令
docker run -p 8501:8501 --name plus -d firstmodel:0.0.1 如果要指定模型文件地址;追加参数 --model_base_path=/模型地址即可
启动成功后,访问 http://localhost:8501/v1/models/plus
即可看到模型信息
{
"model_version_status": [
{
"version": "1",
"state": "AVAILABLE",
"status": {
"error_code": "OK",
"error_message": ""
}
}
]
}访问 http://localhost:8501/v1/models/plus/metadata 可以看到详细信息。
{
"model_spec": {
"name": "plus",
"signature_name": "",
"version": "1"
},
"metadata": {
"signature_def": {
"signature_def": {
"serving_default": {
"inputs": {
"dense_input": {
"dtype": "DT_FLOAT",
"tensor_shape": {
"dim": [
{
"size": "-1",
"name": ""
},
{
"size": "2",
"name": ""
}
],
"unknown_rank": false
},
"name": "serving_default_dense_input:0"
}
},
"outputs": {
"dense_2": {
"dtype": "DT_FLOAT",
"tensor_shape": {
"dim": [
{
"size": "-1",
"name": ""
},
{
"size": "1",
"name": ""
}
],
"unknown_rank": false
},
"name": "StatefulPartitionedCall:0"
}
},
"method_name": "tensorflow/serving/predict"
},
"__saved_model_init_op": {
"inputs": {},
"outputs": {
"__saved_model_init_op": {
"dtype": "DT_INVALID",
"tensor_shape": {
"dim": [],
"unknown_rank": true
},
"name": "NoOp"
}
},
"method_name": ""
}
}
}
}
}这里我们就可以做测试了。注意,metadata中,我们的inputs是dense_input,我们请求时也用用到该key,在postman中。
post请求,http://localhost:8501/v1/models/plus:predict
参数为body ,json
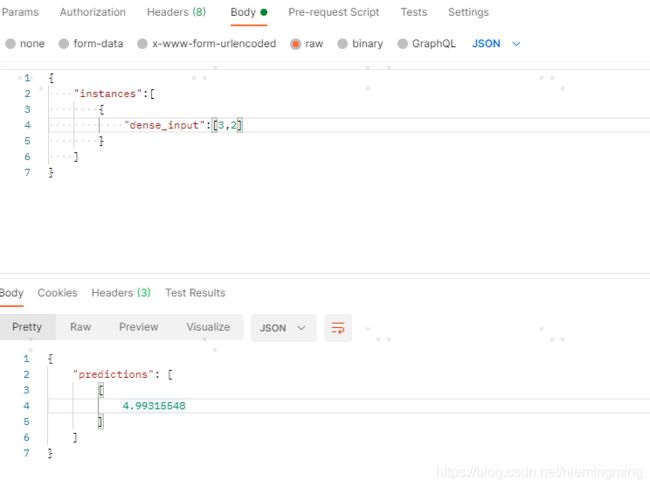
到这一步单模型部署就结束了。
多模型部署
多模型与单模型基本类似,不过我们需要增加一个配置文件。model.config内容如下:
model_config_list: {
config: {
name: "first",
base_path: "/models/first",
model_platform: "tensorflow"
},
config: {
name: "plus",
base_path: "/models/plus",
model_platform: "tensorflow"
}
}dockerfile 改为:
from tensorflow/serving:latest
RUN mkdir -p /models/plus/1
ADD models/plus /models/plus/1/
RUN mkdir -p /models/first/1
ADD models/first /models/first/1/
#ENV MODEL_NAME=plus
ADD model.config /models/
启动命令改为:
docker run -p 8501:8501 --name plus -d firstmodel:0.0.1 ----model_config_file=/models/model.config 启动成功后即可。如果想要使用GRPC形式调用,记得将8500端口映射出来。
关于tensorflowserving的热更新
目前还没有发现好的热更新方案。好在我们可以通过k8s的灰度发布实现类似的功能。不同版本的镜像和不同环境的管理,即可实现。
这里不再详细赘述了。
参考
- github 官方地址
- tensorflow serving入门介绍
- tensorflow serving多模型部署
- tensorflow serving restfulAPI介绍