InnoDB数据页结构
[toc]
不同类型页
InnoDB存储引擎为了出于不同的存储目的设计多种类型的页,比如
存放表空间头部信息的页,存放 Insert Buffer信息的页,存放 INODE 信息的页,存放 undo 日志信息的页等等等等
其中这次重点介绍:存放数据表中记录的那种类型的页,官方称这种存放记录的页为索引( INDEX )页
数据页结构
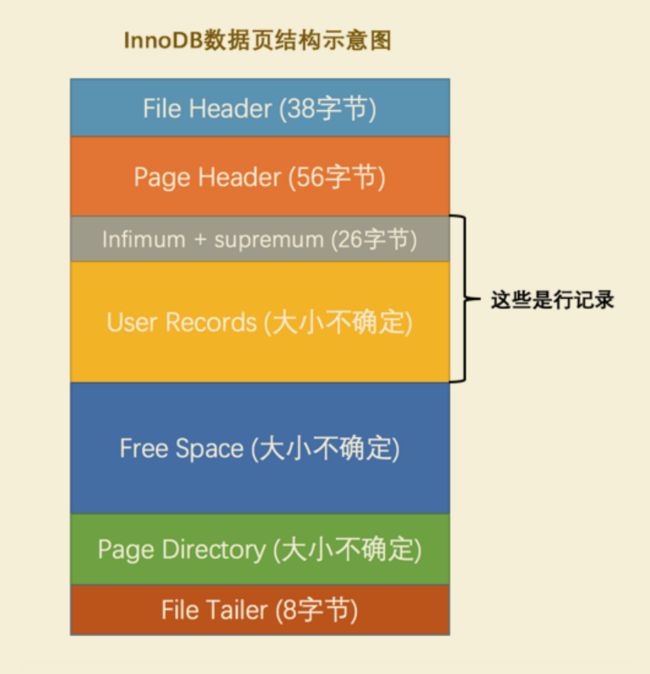
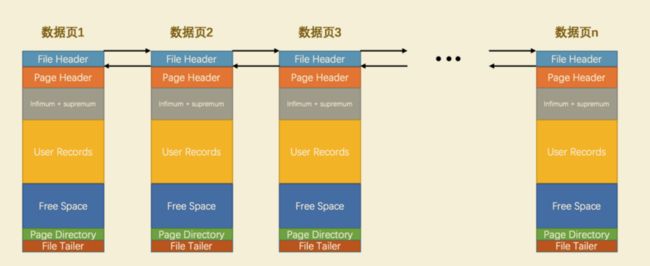
InnoDB 数据页的存储空间大致被划分成了 7 个部分
| 名称 | 中文名 | 占用空间大小 | 简单描述 |
|---|---|---|---|
| File Header | 文件头部 | 38字节 | 页的一些通用信息 |
| Page Header | 页面头部 | 56字节 | 数据页专有的一些信息 |
| Infimum + Supremum | 最小记录和最大记录 | 26字节 | 两个虚拟的行记录 |
| User Records | 用户记录 | 不确定 | 实际存储行记录内容 |
| Free Space | 空闲空间 | 不确定 | 页中尚未使用的空间 |
| Page Directory | 页面目录 | 不确定 | 页中的某些记录的相对位置 |
| File Trailer | 文件尾部 | 8字节 | 校验页是否完整 |
记录在页中的储存
在页的7个组成部分中,我们自己存储的记录会按照我们指定的 行格式 存储到 User Records 部分。但是在一开始生成页的时候,其实并没有 User Records 这个部分,每当我们插入一条记录,都会从 Free Space 部分,也就是尚未使用的存储空间中申请一个记录大小的空间划分到 User Records 部分,当 Free Space 部分的空间全部被 User Records 部分替代掉之后,也就意味着这个页使用完了,如果还有新的记录插入的话,就需要去申请新的页了,这个过程的图示如下:
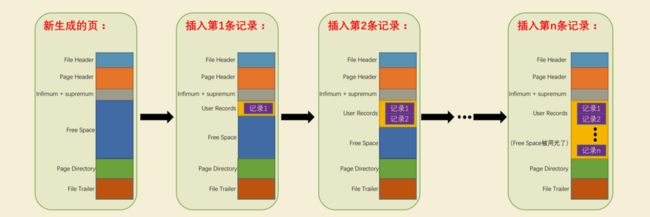
你以为插入记录就是这么简单吗,不!这只是大概的过程,要具体了解这个过程还得从行格式的变化说起
###记录信息头的秘密
为了更好的了解记录在页变化的过程,我们先创建一个表,插入四条数据
mysql> CREATE TABLE page_demo(
-> c1 INT,
-> c2 INT,
-> c3 VARCHAR(10000),
-> PRIMARY KEY (c1)
-> ) CHARSET=ascii ROW_FORMAT=Compact;
Query OK, 0 rows affected (0.03 sec)
mysql> INSERT INTO page_demo VALUES(1, 100, 'aaaa'), (2, 200, 'bbbb'), (3, 300, 'cccc'),
(4, 400, 'dddd');
Query OK, 4 rows affected (0.00 sec)
Records: 4 Duplicates: 0 Warnings: 0
这个新创建的 page_demo 表有3个列,其中 c1 和 c2 列是用来存储整数的, c3 列是用来存储字符串的。需要注意的是,我们把 c1 列指定为主键,所以在具体的行格式中InnoDB就没必要为我们去创建那个所谓的 row_id 隐藏列了。而且我们为这个表指定了 ascii 字符集以及 Compact 的行格式。
所以这个表中记录的行格式示意图就是这样的:
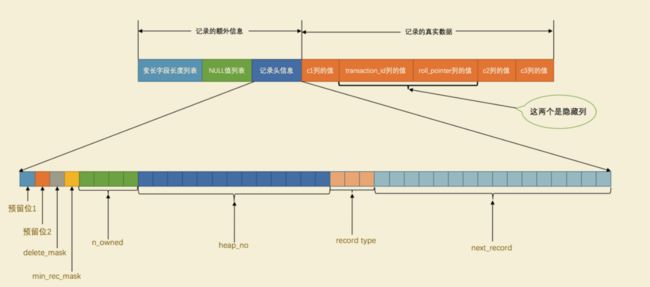
| 名称 | 大小(单位:bit) | 描述 |
|---|---|---|
| 预留位1 | 1 | 没有使用 |
| 预留位2 | 1 | 没有使用 |
| delete_mask | 1 | 标记该记录是否被删除 |
| min_rec_mask | 1 | B+树的每层非叶子节点中的最小记录都会添加该标记 |
| n_owned | 4 | 表示当前记录拥有的记录数 |
| heap_no | 13 | 表示当前记录在记录堆的位置信息 |
| record_type | 3 | 表示当前记录的类型, 0 表示普通记录, 1 表示B+树非叶节点记录, 2 表示最小记录, 3表示最大记录 |
| next_record | 16 | 表示下一条记录的相对位置 |
- delete_mask
这个属性标记着当前记录是否被删除,占用1个二进制位,值为 0 的时候代表记录并没有被删除,为 1 的时 候代表记录被删除掉了。啥?被删除的记录还在 页 中么?是的,摆在台面上的和背地里做的可能大相径庭,你以为它删除了,可它 还在真实的磁盘上[摊手](忽然想起冠希~)。这些被删除的记录之所以不立即从磁盘上移除,是因为移除它们之后把其他的记录在磁盘上重新排列需要性能消耗,所以只是打一个删除标记而已,所有被删除掉的记录都会组成一个所谓的 垃圾链表 ,在这个链表中的记录占用的空间称之为所谓的 可重用空间 ,之后如果有新记录插入到表中的话,可能把这些被删除的记录占用的存储空间覆盖掉。
- next_record
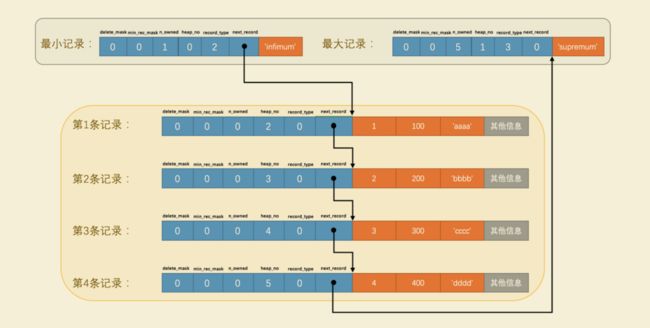
这玩意儿非常重要,说白了就是单向链表的存放了下个节点的地址。它表示从当前记录的真实数据到下一条记录的真实数据的地址偏移量。比方说第一条记录的 next_record 值为 32 ,意味着从第一条记录的真实数据的地址处向后找 32 个字节便是下一条记录的真实数据。如果你熟悉数据结构的话,就立即明白了,这其实是个 链表 ,可以通过一条记录找到它的下一条记录。但是需要注意注意再注意的一点是, 下一条记录 指得并不是按照我们插入顺序的下一条记录,而是按照主键值由小到大的顺序的下一条记录。而且规定 Infimum记录(也就是最小记录) 的下一条记录就是本页中主键值最小的用户记录,而本页中主键值最大的用户记录的下一条记录就是 Supremum记录(也就是最大记录) ,为了更形象的表示一下这个 next_record 起到的作用,我们用箭头来替代一下 next_record 中的地址偏移量:
Page Directory(页目录)
上面我们可以知道记录在页中是以单向链表的形式存在,如果我们要查找一条记录,比如下面
SELECT * FROM page_demo WHERE c1 = 3;
最笨的办法:从 Infimum 记录(最小记录)开始,沿着链表一直往后找,总有一天会找到(或者找不到[摊手]),在找的时候还能投机取巧,因为链表中各个记录的值是按照从小到大顺序排列的,所以当链表的某个节点代表的记录的主键值大于你想要查找的主键值时,你就可以停止查找了,因为该节点后边的节点的主键值依次递增。时间复杂度为O(n)。
但是设计InnoDB的大叔们可没有那么笨,他们采取了类似二分查找的方法,来查询记录;
- 将所有正常的记录(包括最大和最小记录,不包括标记为已删除的记录)划分为几个组。
- 每个组的最后一条记录(也就是组内最大的那条记录)的头信息中的
n_owned属性表示该记录拥有多少条记录,也就是该组内共有几条记录。 - 将每个组的最后一条记录的地址偏移量单独提取出来按顺序存储到靠近
页的尾部的地方,这个地方就是所谓的 Page Directory ,也就是页目录(此时应该返回头看看页面各个部分的图)。页面目录中的这些地址偏移量被称为槽(英文名: Slot ),所以这个页面目录就是由槽组成的。
比方说现在的 page_demo 表中正常的记录共有6条, InnoDB 会把它们分成两组,第一组中只有一个最小记录,第二组中是剩余的5条记录,看下边的示意图:

注意:
- 现在 页目录 部分中有两个槽,也就意味着我们的记录被分成了两个组, 槽1 中的值是 112 ,代表最大记录的地址偏移量(就是从页面的0字节开始数,数112个字节); 槽0 中的值是 99 ,代表最小记录的地址偏移量。
- 注意最小和最大记录的头信息中的 n_owned 属性最小记录的 n_owned 值为 1 ,这就代表着以最小记录结尾的这个分组中只有 1 条记录,也就是最小记录本身。
- 最大记录的 n_owned 值为 5 ,这就代表着以最大记录结尾的这个分组中只有 5 条记录,包括最大记录本身还有我们自己插入的 4 条记录。
为什么最小记录的 n_owned 值为1,而最大记录的 n_owned 值为 5 呢,这里头有什么猫腻么?
设计 InnoDB 的大叔们对每个分组中的记录条数是有规定的:
对于最小记录所在的分组只能有 1 条记录,最大记录所在的分组拥有的记录条数只能在 1~8 条之间,
剩下的分组中记录的条数范围只能在是 4~8 条之间。
###查找过程
往表里面再添加12条记录
mysql> INSERT INTO page_demo VALUES(5, 500, 'eeee'), (6, 600, 'ffff'), (7, 700, 'gggg'),
(8, 800, 'hhhh'), (9, 900, 'iiii'), (10, 1000, 'jjjj'), (11, 1100, 'kkkk'), (12, 1200, 'l
lll'), (13, 1300, 'mmmm'), (14, 1400, 'nnnn'), (15, 1500, 'oooo'), (16, 1600, 'pppp');
Query OK, 12 rows affected (0.00 sec)
Records: 12 Duplicates: 0 Warnings: 0
现在页里边就一共有18条记录了(包括最小和最大记录),这些记录被分成了5个组,如图所示:
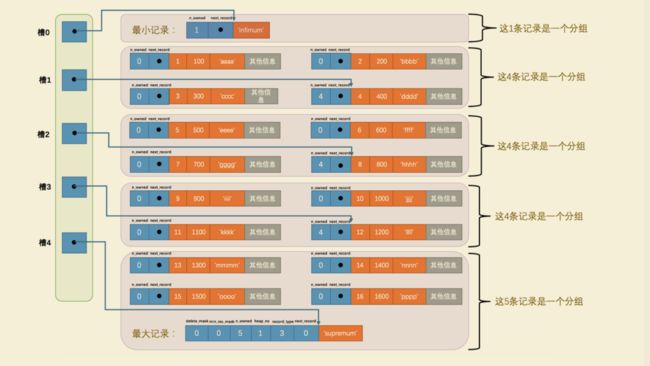
因为把16条记录的全部信息都画在一张图里太占地方,让人眼花缭乱的,所以只保留了用户记录头信息中的n_owned 和 next_record 属性,也省略了各个记录之间的箭头,我没画不等于没有啊!现在看怎么从这个 页目录中查找记录。因为各个槽代表的记录的主键值都是从小到大排序的,所以我们可以使用所谓的 二分法 来进行快速查找。
4个槽的编号分别是: 0 、 1 、 2 、 3 、 4 ,所以初始情况下最低的槽就是 low=0 ,最高的槽就是high=4 。比方说我们想找主键值为 6 的记录,过程是这样的:
- 计算中间槽的位置: (0+4)/2=2 ,所以查看 槽2 对应记录的主键值为 8 ,又因为 8 > 6 ,所以设置high=2 , low 保持不变。
- 重新计算中间槽的位置: (0+2)/2=1 ,所以查看 槽1 对应的主键值为 4 ,又因为 4 < 6 ,所以设置low=1 , high 保持不变。
- 因为 high - low 的值为1,所以确定主键值为 5 的记录在 槽2 对应的组中。此刻我们需要找到 槽2 中主键值最小的那条记录,然后沿着单向链表遍历 槽2 中的记录。但是我们前边又说过,每个槽对应的记录都是该组中主键值最大的记录,这里 槽2 对应的记录是主键值为 8 的记录,怎么定位一个组中最小的记录呢?别忘了各个槽都是挨着的,我们可以很轻易的拿到 槽1 对应的记录(主键值为 4 ),该条记录的下一条记录就是 槽2 中主键值最小的记录,该记录的主键值为 5 。所以我们可以从这条主键值为 5 的记录出发,遍历 槽2 中的各条记录,直到找到主键值为 6 的那条记录即可。由于一个组中包含的记录条数只能是1~8条,所以 遍历一个组中的记录的代价是很小的。所以在一个数据页中查找指定主键值的记录的过程分为两步:
- 通过二分法确定该记录所在的槽,并找到该槽中主键值最小的那条记录。
- 通过记录的 next_record 属性遍历该槽所在的组中的各个记录。
Page Header(页面头部)
设计 InnoDB 的大叔们为了能得到一个数据页中存储的记录的状态信息,比如本页中已经存储了多少条记录,第一条记录的地址是什么,页目录中存储了多少个槽等等,特意在页中定义了一个叫 Page Header 的部分,它是页 结构的第二部分,这个部分占用固定的 56 个字节,专门存储各种状态信息

File Header(文件头部)
File Header 针对各种类型的页都通用,也就是说不同类型的页都会以 File Header 作为第一个组成部分,它描述了一些针对各种页都通用的一些信息,比方说这个页的编号是多少,它的上一个页、下一个页是谁啦吧啦吧啦~ 这个部分占用固定的 38 个字节,是由下边这些内容组成的:
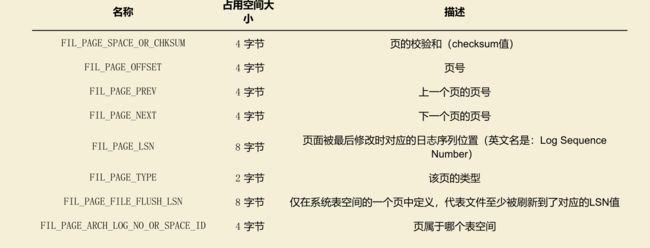
每个数据页的 File Header 部分都有上一个和下一个页的编号,所以所有的数据页会组成一个 双链表 。
File Trailer
我们知道 InnoDB 存储引擎会把数据存储到磁盘上,但是磁盘速度太慢,需要以 页 为单位把数据加载到内存中处理,如果该页中的数据在内存中被修改了,那么在修改后的某个时间需要把数据同步到磁盘中。但是在同步了一半的时候中断电了咋办,这不是莫名尴尬么?为了检测一个页是否完整(也就是在同步的时候有没有发生只同步一半的尴尬情况),设计 InnoDB 的大叔们在每个页的尾部都加了一个 File Trailer 部分,这个部分由 8 个字节组成,可以分成2个小部分:
- 前4个字节代表页的校验和
这个部分是和 File Header 中的校验和相对应的。每当一个页面在内存中修改了,在同步之前就要把它的校验和算出来,因为 File Header 在页面的前边,所以校验和会被首先同步到磁盘,当完全写完时,校验和也会被写到页的尾部,如果完全同步成功,则页的首部和尾部的校验和应该是一致的。如果写了一半儿断电了,那么在 File Header 中的校验和就代表着已经修改过的页,而在 File Trialer 中的校验和代表着原先的页,二者不同则意味着同步中间出了错。
- 后4个字节代表页面被最后修改时对应的日志序列位置(LSN)
这个部分也是为了校验页的完整性的,只不过我们目前还没说 LSN 是个什么意思,所以大家可以先不用管这个属性。 这个 File Trailer 与 File Header 类似,都是所有类型的页通用的。
欢迎关注ggball!