Motivation: 文章从BM3D去噪算法中的non-local means 和self-attention出发,在neural network中考虑不同空间和时间位置上的特征之间的关系。NL-means去噪与常用的双线性滤波、中值滤波等利用图像局部信息来滤波不同的是,它利用了整幅图像来进行去噪,以图像块为单位在图像中寻找相似区域,再对这些区域求平均,能够比较好地去掉图像中存在的高斯噪声。non-local在一个位置的计算响应是输入特性图中所有位置的特征的加权总和。一组位置可以在空间、时间或时空上,适用于图像、序列和视频问题。

non-local主要是下面这个公式:

上式中,输入是x(图片,序列,视频 features),输出是y,i和j分别代表输入的某个(空间,时间,时空)位置,x_i是一个向量,维数跟x的channel数一样,f是一个计算任意两点相似关系的函数,输出一个值作为权重,g函数计算j处这个点的特征。为了计算输出层的一个点,需要将输入的每个点都考虑一遍,而且考虑的方式很像attention,输出的某个点在原图上的attention,而mask则是相似性给出。最后C(x)是归一化项。
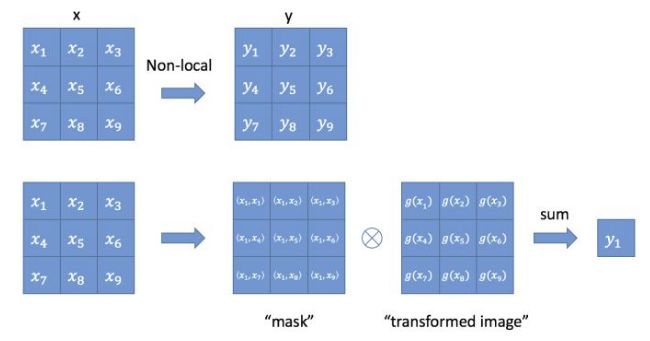
以图像为例,为了简化问题,作者简单地设置g函数实现时二维用1x1卷积,三维用1x1x1卷积,w均为待学习的参数。相似性度量函数f的选择有多种:

Embedded Gaussian的例子:
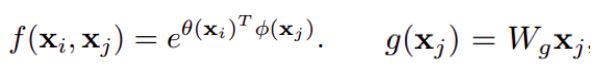
实现中可以用softmax归一化,non-local可以转换为:
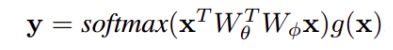
为了能让non-local作为一个组件直接插入任意的神经网络中,同时不破坏模型原有的操作。作者把non-local设计成residual block的形式,并且输出跟原图大小一致。Wz为1x1的卷积,这里采用bottleneck形式降维一半,最后利用1x1卷积升维至输入维度:
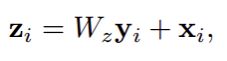
具体实现
用for循环实现肯定是很慢的。如果在尺寸很大的输入上应用non-local layer,也是计算量很大的。后者的解决方案是,只在高阶语义层中引入non-local layer。还可以通过对embedding( )的结果加pooling层来进一步地减少计算量。
对于前者,注意到f的计算可以化为矩阵运算,我们实际上可以将整个non-local化为矩阵乘法运算+卷积运算。如下图所示,其中oc为output_channels,卷积操作的输出filter数量。f(.)的操作是每个点的特征向量(通道个数的维度)进行内积,时空信息保留了下来,输出还是TxHxW大小。
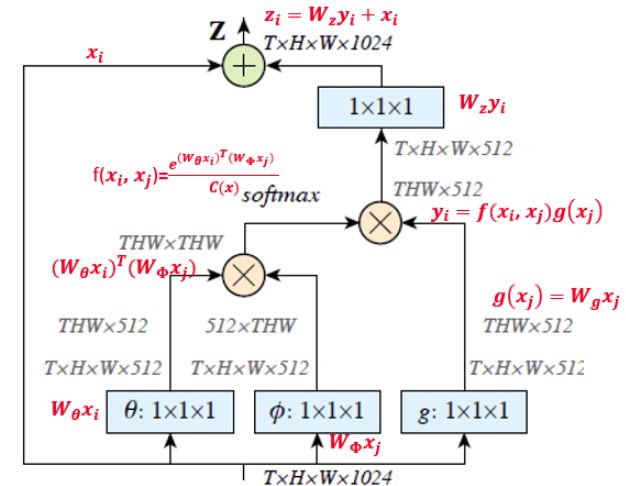
图中T,H,W代表输入特征的维度。其中T是对于视频帧数,特征图尺寸为T×H×W×1024 也就是有 1024 个通道。 f函数采用的是公式3中的Embedded Gaussian。蓝色框表示1×1×1 的卷积操作,这种结构为512通道的“瓶颈”(bottleneck)结构。对于分割或检测任务,1x1的卷积压缩通道数,形成瓶颈结构(bottleneck)。或者在f(.)对应的1x1卷积之后使用pooling来减小H,W,即采样一部分的j而不是所有的j进行信息融合。
与全连接层的关系:
non-local block利用两个点的相似性对每个位置的特征做加权,而全连接层则是利用位置相关的权重参数直接对每个位置加权。于是,全连接层可以看成non-local block的一个特例:
1. 任意两点的相似性仅跟两点的位置有关,而与两点的具体feature无关,即 f(xi,xj)=wij
2. g是identity函数, g(x)=x
3. 归一化系数为1。归一化系数跟输入无关,全连接层不能处理任意尺寸的输入。
Pytorch 复现代码:

非局部神经网络在计算上也比三维卷积神经网络更加经济。作者在 Kinetics 和 Charades 数据集上做了全面的对比研究。仅使用 RGB 数据,不使用任何高级处理(例如光流、多尺度测试),就取得了与这两个数据集上竞赛冠军方法相当乃至更好的结果。
为了证明非局部运算的通用性,作者在 COCO 数据集上进行了物体检测、实例分割和人体姿态关键点检测的实验。他们将非局部运算模块与 Mask R-CNN 结合,新模型在计算成本稍有增加的情况下,在所有三个任务中都取得了最高的精度。由此表明非局部模块可以作为一种通用的基本组件,在设计深度神经网络时使用。

实验:
对于视频分类任务整个视频平均取10个clip,计算softmax值后平均。8卡,一卡8个clip,minibatch为64,输入clip为32帧。
Reference
Wang X, Girshick R, Gupta A, et al. Non-local Neural Networks[J].CVPR 2018.
Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[C]. NIPS 2017.
知乎:https://zhuanlan.zhihu.com/p/33345791
Pytorch:https://github.com/AlexHex7/Non-local_pytorch
引自知乎:
cnn一开始是面向目标实体识别的任务的。它就是要模拟人的认知方式,达到一个从局部到宏观的层次化认知流程。所以每一层的卷积核就没有设计过大,底层的去捕捉轮廓信息,中层的组合轮廓信息,高层的组合全局信息。但对于序列化的任务,这种思路就不一定能学到充分的需要的信息。
识别挥拍这个动作,仅仅利用传统cnn卷积核关注手腕周围的信息是不够的,我们需要了解到人的手腕跟他的胳膊、肩膀、膝盖以及脚发生了哪些一系列的相对位移才能判断出挥拍动作。
卷积核真的只关注于局部吗?如果只看一层,那答案就是是的。但纵观整个网络,不同的全局信息最终被综合,但由于sampling损失了大量信息,就没有non-local效果明显。所以传统cnn不是很local,但是信息逐层传递丢失太多以致于不能有期待的效果。
1、单一的non-local block加在较浅层次效果显著。
高层次丢失的信息太多了,找不到细小的远距离的联系,太模糊了。
2、多个non-local block加入,也就是加深non-local特性,有一定效果提升但不会很明显。
既然容易起作用的是在低层加,那么使劲加深意义不大,加多了这种东西就要考虑梯度消失和引入噪声。毕竟你把背景全都扔进来算。
3、时空同时non-local比单一时间维度或单一空间维度效果都要好。
4、non-local比三维cnn要好。
这是有人会问,non-local这么吊怎么不把卷积层全都替换掉?
肯定不行的!你要依赖小卷积核去捕捉主体信息,同时用他的block捕捉全局信息,两者相辅相成才有好的效果。在视频变长以后,non-local的trick的提升变小了。因为在时间维度上,这些短视频帧数太短,时间维度上的小卷积得到的信息不足,劣势明显。时间变长了,non-local也不能handle这么大的信息量了,损失一些信息的小卷积反而不那么差劲了