selenium自动化测试基础
- 1. 使用测试工具
- 1.1 自动化测试理论介绍
- 自动化测试的
4W1H - 自动化测试的典型金字塔原理
- 自动化测试的适用范围
- 自动化测试的
- 1.2 自动化测试工具
- Selenium 基本介绍
- Selenium 工具集
- 自动化编程语言Python选择
- JetBrains PyCharm 使用
- Selenium 的环境搭建
- 1.3 Selenium 的最简脚本
- 1.4 Selenium WebDriver API 的使用
- 控制浏览器
- 元素定位操作
- 依据XPath进行查找
- 依据CSS选择器进行查找
- 特殊 iframe 操作
- 特殊 Select 操作
- 鼠标事件操作
- 键盘事件操作
- 截图操作
- 1.5 unittest 单元测试框架
- 为什么选择 unittest
- 1.6 为什么需要封装 Selenium
- 1.7 如何封装
- 1.8 Page-Object设计模式介绍
- 1.1 自动化测试理论介绍
- 2. 构建测试方案
- 2.1 数据驱动在自动化测试中的应用
- 2.2 测试方案的编码实现
- 2.3 测试报告的生成
原文阅读对象是针对测试人员,测试人员普遍开发能力偏弱,所以讲的比较琐碎,这里做了一定的删减和改写,主要针对测试主管或有一定经验的开发人员或负责人,快速了解及考虑使用selenium自动化测试方案。
自动化测试并不属于新鲜的事物,或者说自动化测试的各种方法论已经层出不穷,但是,能够在项目中持之以恒的实践自动化测试的团队,却依旧不是非常多。有的团队知道怎么做,做的还不够好;有的团队还正在探索和摸索怎么做,甚至还有一些多方面的技术上和非技术上的旧系统需要重构……
本文从
使用和实践两个视角,尝试对基于Web UI自动化测试做细致的分析和解读,给各位去思考和实践做一点引路,以便各团队能找到更好的方式。
1. 使用测试工具
在开始具体的自动化测试之前,我们需要做好更多的准备,包括以下几个方面:
- 认识自动化测试
- 准备自动化测试工具
- 使用有效的方式
- 针对具体的测试对象
1.1 自动化测试理论介绍
自动化测试不再是一个陌生的话题,作为测试实践活动的一部分,我们首先分析一下自动化测试的方方面面。
自动化测试的4W1H
-
WHAT- 什么是自动化测试《软件测试艺术》一书中,给出了测试的定义:
“程序测试是为了发现错误而执行的过程。”
自动化测试:以人为驱动的测试行为转化为机器执行的一种过程
自动化测试,就是把手工进行的测试过程,转变成机器自动执行的测试过程。该过程,依旧是为了发现错误而执行。因此自动化测试的关键在于“自动化”三个字。自动化测试的内容,也就相应的转变成如何“自动化”去实现原本手工进行的测试的过程。
通过程序,可以把手工测试,转变成自动化测试。
-
WHEN- 在什么时候开展自动化测试自动化测试的开展,依赖于“程序”。那么程序,其实就是由“源代码”构建而来的。那么原则上,只要能做出自动化测试所需要的“程序”的时候,就可以进行自动化测试。但往往,并不是所有的“时候”都是好的“时机”。从这个
W开始,我们将会加入对于成本的顾虑,也正是因为“成本”的存在,才使得下面的讨论,变得有意义。所有的开销,都是有成本的。构建成“程序”的源代码,也是由工程师写出来的。那么需要考虑这个过程中的成本。基于这个考虑,在能够比较稳定的构建“程序”的时候,不需要花费太多开销在“源代码”的时候,就是开展自动化测试的好时机。这个开销包括
编写和修改源代码,而源代码指的是构建出用来做自动化测试的程序的源代码。 -
WHERE- 在什么地方进行自动化测试自动化测试的执行,依靠的是机器。那么自动化测试必将在“机器”上进行。一般来说,这个机器包括桌面电脑和服务器。通过将写好的
源代码部署在机器上,构建出用来做自动化测试的"程序",并且运行该程序,实现自动化测试。 -
WHICH- 对什么目标进行自动化测试自动化测试的目标,是被测试的软件。抛开人工智能的成分,手工测试必将在“人工智能”足够普及和足够“智能”之前,替代一大部分不需要“人类智能”的手工测试;以及自动化测试会做一些手工测试无法实施的,或者手工测试无法覆盖的测试。
- 不需要“人类智能”的普通手工测试
- 界面的普通操作
- 通过固定输入和固定操作而进行的流程化测试
- 重复的普通测试
- 手工测试无法实施或者覆盖的
- 大量的数据的输入
- 大量的步骤的操作
- 源代码基本的测试
- 系统模块间接口的调用测试
- ……
-
HOW- 如何开展自动化测试- 准备测试用例
- 找到合适的自动化测试工具
- 用准确的编程形成测试脚本
- 在测试脚本中对目标进行“检查”,即做断言
- 记录测试日志,生成测试结果
和所有的其他测试一样,自动化测试的流程也是由“用例”执行和“缺陷”验证组成。差别是需要找到合适的“工具”来替代“人手”。不同目标的自动化测试有不同的测试工具,但是任何工具都无不例外的需要“编程”的过程,实现“源代码”,也可以称之为测试脚本。
于是开展自动化测试的方式基本上如下:
自动化测试的典型金字塔原理
谈到自动化测试,就不得不提的一个人和概念就是:Martin Fowler和他的金字塔原理。首先请看金字塔原理的图示如下:
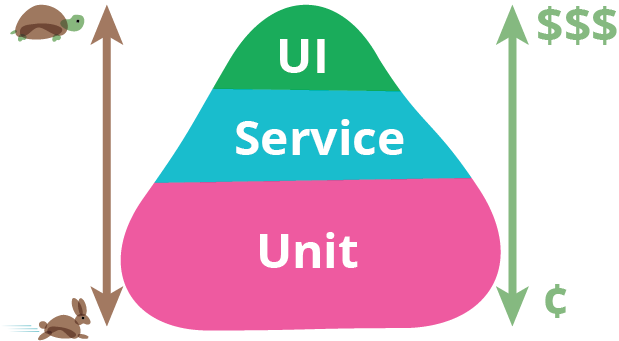
该图说明了三个问题:
- 自动化测试包括三个方面:UI前端界面,Service服务契约和Unit底层单元
- 越是底层的测试,运行速度越快,时间开销越少,金钱开销越少
- 越是顶层的测试,运行速度越慢,时间开销越多,金钱开销越多
这是理想中的金字塔原理。
在实际的项目中,尤其是结合国内的项目实践,其实还隐藏了另一个问题:越是顶层的测试,效果越明显。有句话说“贵的东西,除了贵,其他都是好的!”能够很清晰的阐述这个观点。
金字塔原理在国内的适应性也有一定的问题
- 自动化测试的起步不是特别早
- 甚至软件测试很长一段时间都在进行基于业务的手工测试,测试人员的代码能力相对较弱
- 开发人员在代码中不太习惯写单元测试
- 近些年基于服务契约的API测试也在兴起
相对来说,在基于UI前端界面的自动化测试反倒是开展和实施的不是特别多。尽管基于界面的测试带来的效果还是能够立竿见影的。对于产品的质量提升,还是比较容易有保证。
自动化测试的适用范围
自动化测试可以涉及和试用的范围主要在以下方面:
- 基于
Web UI的浏览器应用的界面测试 - 基于
WebService或者WebAPI的服务契约测试 - 基于
WCF、.net remoting、Spring等框架的服务的集成测试 - 基于
APP UI的移动应用界面测试 - 基于
Java、C#等编程文件进行的单元测试
本文集中讨论第一条:基于Web UI的浏览器应用的界面测试。界面的改动对于测试来说,具有较大的成本风险。主要考虑以下方面:
- 任务测试明确,不会频繁变动
- 每日构建后的测试验证
- 比较频繁的回归测试
- 软件系统界面稳定,变动少
- 需要在多平台上运行的相同测试案例、组合遍历型的测试、大量的重复任务
- 软件维护周期长
- 项目进度压力不太大
- 被测软件系统开发比较规范,能够保证系统的可测试性
- 具备大量的自动化测试平台
- 测试人员具备较强的编程能力
- 自动化测试的流程
自动化测试和普通的手工测试遵循的测试流程,与项目的具体实践相关。一般来说,也是需要从测试计划开始涉及自动化测试的。
- 测试计划:划定自动化测试的范围包含哪些需求,涉及到哪些测试过程
- 测试策略:确定自动化测试的工具、编程方案、代码管理、测试重点
- 测试设计:使用测试设计方法对被测试的需求进行设计,得出测试的测试点、用例思维导图等
- 测试实施:根据测试设计进行用例编写,并且将测试用例用编程的方式实现测试脚本
- 测试执行:执行测试用例,运行测试脚本,生成测试结果
1.2 自动化测试工具
基于Web UI的自动化测试工具主要有两大类:付费的商业版工具和免费使用的开源版工具。典型的有两种:
- UFT,QTP被惠普收购以后的新名称。
- 通过程序的录制,可以实现测试的编辑
- 录制的测试脚本是 VBScript 语法
- 成熟版的商业付费工具
- 工具比较庞大,对具体的项目定制测试有难度
- SELENIUM,本次选择的开源工具
- 本身不是测试工具,只是模拟浏览器操作的工具
- 背后有 Google 维护源代码
- 支持全部主流的浏览器
- 支持主流的编程语言,包括:Java、Python、C#、PHP、Ruby、JavaScript等
- 工具很小,可以实现对测试项目的定制测试方案
- 基于标准的 WebDriver 语法规范
Selenium 基本介绍
Selenium`是开源的自动化测试工具,它主要是用于Web 应用程序的自动化测试,不只局限于此,同时支持所有基于web 的管理任务自动化。
-
Selenium官网的介绍Selenium is a suite of tools to automate web browsers across many platforms.
- runs in many browsers and operating systems
- can be controlled by many programming languages and testing frameworks.
- Selenium 官网:http://seleniumhq.org/
- Selenium Github 主页:https://github.com/SeleniumHQ/selenium
Selenium 是用于测试 Web 应用程序用户界面 (UI) 的常用框架。它是一款用于运行端到端功能测试的超强工具。您可以使用多个编程语言编写测试,并且 Selenium 能够在一个或多个浏览器中执行这些测试。
Selenium 工具集
-
Selenium IDE
Selenium IDE (集成开发环境) 是一个创建测试脚本的原型工具。它是一个 Firefox 插件,实现简单的浏览器操作的录制与回放功能,提供创建自动化测试的建议接口。Selenium IDE 有一个记录功能,能记录用户的操作,并且能选择多种语言把它们导出到一个可重用的脚本中用于后续执行。
-
Selenium RC
Selenium RC 是selenium 家族的核心工具,Selenium RC 支持多种不同的语言编写自动化测试脚本,通过selenium RC 的服务器作为代理服务器去访问应用从而达到测试的目的。
selenium RC 使用分Client Libraries 和Selenium Server。
- Client Libraries 库主要主要用于编写测试脚本,用来控制selenium Server 的库。
- Selenium Server 负责控制浏览器行为,总的来说,Selenium Server 主要包括3 个部分:Launcher、Http Proxy、Core。
-
Selenium Grid
Selenium Grid 使得 Selenium RC 解决方案能提升针对大型的测试套件或者哪些需要运行在多环境的测试套件的处理能力。Selenium Grid 能让你并行的运行你的测试,也就是说,不同的测试可以同时跑在不同的远程机器上。这样做有两个优势,首先,如果你有一个大型的测试套件,或者一个跑的很慢的测试套件,你可以使用 Selenium Grid 将你的测试套件划分成几份同时在几个不同的机器上运行,这样能显著的提升它的性能。同时,如果你必须在多环境中运行你的测试套件,你可以获得多个远程机器的支持,它们将同时运行你的测试套件。在每种情况下,Selenium Grid 都能通过并行处理显著地缩短你的测试套件的处理时间。
-
Selenium WebDriver
WebDriver 是 Selenium 2 主推的工具,事实上WebDriver是Selenium RC的替代品,因为Selenium需要保留向下兼容性的原因,在 Selenium 2 中, Selenium RC才没有被彻底的抛弃,如果使用Selenium开发一个新的自动化测试项目,那么我们强烈推荐使用Selenium2 的 WebDriver进行编码。另外, 在Selenium 3 中,Selenium RC 被移除了。
自动化编程语言Python选择
- 测试人员的编程能力普遍不是很强,而Python作为一种脚本语言,不仅功能强大,而且语法优美,支持多种自动化测试工具,而且学习上手比较容易。
- 对于有一定编程基础的人员,使用Python作为自动化测试的语言可以非常顺畅的转换,几乎没有学习成本。同时Python是标准的面向对象的编程语言,对于C#、Java等面向对象的语言有着非常好的示例作用,通过Python的示例可以非常轻松的触类旁通,使用其他语言进行Selenium2.0的WebDriver的使用。
使用的工具集
- IDE: Jetbrains PyCharm
- 语言: Python
- 工具: Selenium WebDriver
- 源代码管理: SVN/Git
JetBrains PyCharm 使用
- JetBrains PyCharm 的介绍
PyCharm 是 JetBrains 公司针对Python推出的IDE(Integrated Development Environment,集成开发环境)。是目前最好的Python IDE之一。目前包含了两个版本:
- 社区版,Community Edition
- 专业版,Professional Edition
- 付费
- 比社区版主要多了Web开发框架
我们推荐使用免费的社区版本,进行Python脚本的编写和自动化测试执行。
PyCharm可以在官网下载,http://www.jetbrains.com
Selenium 的环境搭建
在 Windows 搭建和部署 Selenium 工具
先安装python
-
安装 Selenium 工具包
由于 安装好的 Python 默认有
pipPython 包管理工具,可以通过pip非常方便的安装 Selenium。
```
pip install selenium
```
```
pip install -U selenium
```
当然,可以事先下载 Selenium 的 Python 安装包,再进行手动安装。
官方下载地址:https://pypi.python.org/pypi/selenium
```
python setup.py install
```
-
配置浏览器和驱动
Selenium 3 对于所有的浏览器都需要安装驱动,本文以 Chrome 和 Firefox、IE为例设置浏览器和驱动。
ChromeDriver下载地址:http://chromedriver.storage.googleapis.com/index.html
ChromeDriver 与 Chrome 对应关系表:
ChromeDriver版本 | 支持的Chrome版本 |
-|-|
v2.31| v58-60 |
v2.30 |v58-60 |
v2.29 |v56-58 |
GeckoDriver下载地址:https://github.com/mozilla/geckodriver/releases
GeckoDriver 与 Firefox 的对应关系表:
GeckoDriver版本 |支持的Firefox版本 |
-|-|
v0.18.0| v56 |
v0.17.0 |v55 |
IEDriverServer下载地址:http://selenium-release.storage.googleapis.com/index.html
IEDriverServer 的版本需要与 Selenium 保持严格一致。
**浏览器驱动的配置**
- 首先,将下载好的对应版本的浏览器安装。
- 其次,在 Python 的根目录中,放入浏览器驱动。
- 最好再重启电脑,一般情况下不重启也可以的。
1.3 Selenium 的最简脚本
通过上一节的环境安装成功以后,我们可以进行第一个对Selenium 的使用,就是最简脚本编写。脚本如下:
# 声明一个司机,司机是个Chrome类的对象
driver = webdriver.Chrome()
# 让司机加载一个网页
driver.get("http://demo.xxx.com")
# 给司机3秒钟去打开
sleep(3)
# 开始登录
# 1. 让司机找用户名的输入框
we_account = driver.find_element_by_css_selector('#account')
we_account.clear()
we_account.send_keys("demo")
# 2. 让司机找密码的输入框
we_password = driver.find_element_by_css_selector('#password')
we_password.clear()
we_password.send_keys("demo")
# 3. 让司机找 登录按钮 并 单击
driver.find_element_by_css_selector('#submit').click()
sleep(3)
实际上一段20行的代码,也不能算太少了。但是这段代码的使用,确实体现了 Selenium 的最简单的使用。这些代码有开发基础的同学,一看都懂。
注意:Chrome 是 WebDriver 的子类,是 WebDriver 类的一种
1.4 Selenium WebDriver API 的使用
通过上述最简脚本的使用,我们可以来进一步了解 Selenium 的使用。事实上,上一节用的,便是 Selenium 的 WebDriver API。
Selenium WebDriver API 官方参考:http://seleniumhq.github.io/selenium/docs/api/py/
具体API文档地址:https://seleniumhq.github.io/selenium/docs/api/py/api.html
控制浏览器
浏览器的控制也是自动化测试的一个基本组成部分,我们可以将浏览器最大化,设置浏览器的高度和宽度以及对浏览器进行导航操作等。
# 浏览器打开网址
driver.get("https://www.baidu.com")
# 浏览器最大化
driver.maximize_window()
# 设置浏览器的高度为800像素,宽度为480像素
driver.set_window_size(480, 800)
# 浏览器后退
driver.back()
# 浏览器前进
driver.forward()
# 浏览器关闭
driver.close()
# 浏览器退出
driver.quit()
元素定位操作
WebDriver提供了一系列的定位符以便使用元素定位方法。常见的定位符有以下几种:
- id
- name
- class name
- tag
- link text
- partial link text
- xpath
- css selector
那么我们以下的操作将会基于上述的定位符进行定位操作。
对于元素的定位,WebDriver API可以通过定位简单的元素和一组元素来操作。在这里,我们需要告诉Selenium如何去找元素,以至于他可以充分的模拟用户行为,或者通过查看元素的属性和状态,以便我们执行一系列的检查。
在Selenium2中,WebDriver提供了多种多样的find_element_by方法在一个网页里面查找元素。这些方法通过提供过滤标准来定位元素。当然WebDriver也提供了同样多种多样的find_elements_by的方式去定位多个元素。
尽管上述的方式,可以进行元素定位,实际上我们也是更多的用组合的方式进行元素定位。
| 方法Method | 描述Description | 参数Argument | 示例Example |
|---|---|---|---|
id |
该方法通过ID的属性值去定位查找单个元素 | id: 需要被查找的元素的ID | find_element_by_id('search') |
name |
该方法通过name的属性值去定位查找单个元素 | name: 需要被查找的元素的名称 | find_element_by_name('q') |
class name |
该方法通过class的名称值去定位查找单个元素 | class_name: 需要被查找的元素的类名 | find_element_by_class_name('input-text') |
tag_name |
该方法通过tag的名称值去定位查找单个元素 | tag: 需要被查找的元素的标签名称 | find_element_by_tag_name('input') |
link_text |
该方法通过链接文字去定位查找单个元素 | link_text: 需要被查找的元素的链接文字 | find_element_by_link_text('Log In') |
partial_link_text |
该方法通过部分链接文字去定位查找单个元素 | link_text: 需要被查找的元素的部分链接文字 | find_element_by_partial_link_text('Long') |
xpath |
该方法通过XPath的值去定位查找单个元素 | xpath: 需要被查找的元素的xpath | find_element_by_xpath('//*[@id="xx"]/a') |
css_selector |
该方法通过CSS选择器去定位查找单个元素 | css_selector: 需要被查找的元素的ID | find_element_by_css_selector('#search') |
而find_elements_by的方法依据匹配的具体标准返回一系列的元素。
下面代码通过ID的属性值去定义一个查找文本框的查找:
根据上述代码,这里我们使用find_element_by_id()的方法去查找搜索框并且检查它的最大长度maxlength属性。我们通过传递ID的属性值作为参数去查找,参考如下的代码示例:
def test_search_text_field_max_length(self):
# get the search textbox
search_field = self.driver.find_element_by_id("search")
# check maxlength attribute is set to 128
self.assertEqual("128", search_field.get_attribute("maxlength"))
如果使用find_elements_by_id()方法,将会返回所有的具有相同ID属性值的一系列元素。
这里还是根据上述ID查找的HTML代码,使用find_element_by_name的方法进行查找。参考如下的代码示例:
# get the search textbox
self.search_field = self.driver.find_element_by_name("q")
同样,如果使用find_elements_by_name()方法,将会返回所有的具有相同name属性值的一系列元素。
依据class name查找
除了上述的ID和name的方式查找,我们还可以使用class name的方式进行查找和定位。
事实上,通过ID,name或者类名class name查找元素是最提倡推荐的和最快的方式。
根据上述代码,使用find_element_by_class_name()方法去定位元素。
def test_search_button_enabled(self):
# get Search button
search_button = self.driver.find_element_by_class_name("button")
# check Search button is enabled
self.assertTrue(search_button.is_enabled())
其他方式都可以参考jquery或一些爬虫关于html节点查找的方法。
依据XPath进行查找
XPath是一种在XML文档中搜索和定位节点node的一种查询语言。所有的主流Web浏览器都支持XPath。
常用的XPath的方法有starts-with(),contains()和ends-with()等
若想要了解更多关于XPath的内容,请查看http://www.w3schools.com/XPath/
如下有一段HTML代码,其中里面的alt属性,定位到指定的tag。
-

-

-

具体代码如下:
def test_vip_promo(self):
# get vip promo image
vip_promo = self.driver.\
find_element_by_xpath("//img[@alt='Shop Private Sales - Members Only']")
# check vip promo logo is displayed on home page
self.assertTrue(vip_promo.is_displayed())
# click on vip promo images to open the page
vip_promo.click()
# check page title
self.assertEqual("VIP", self.driver.title)
当然,如果使用find_elements_by_xpath()的方法,将会返回所有匹配了XPath查询的元素。
依据CSS选择器进行查找
CSS是一种设计师用来描绘HTML文档的视觉的层叠样式表。一般来说CSS用来定位多种多样的风格,同时可以用来是同样的标签使用同样的风格等。
Recently added item(s)
×
You have no items in your shopping cart.
我们来创建一个测试,验证这些消息是否正确。
def test_shopping_cart_status(self):
# check content of My Shopping Cart block on Home page
# get the Shopping cart icon and click to open the
# Shopping Cart section
shopping_cart_icon = self.driver.\
find_element_by_css_selector("div.header-minicart
span.icon")
shopping_cart_icon.click()
# get the shopping cart status
shopping_cart_status = self.driver.\
find_element_by_css_selector("p.empty").text
self.assertEqual("You have no items in your shopping cart.",
shopping_cart_status)
# close the shopping cart section
close_button = self.driver.\
find_element_by_css_selector("div.minicart-wrapper
a.close")
close_button.click()
特殊 iframe 操作
iframe 元素会创建包含另外一个文档的内联框架(即行内框架)。
在一个中,包含了另一个
示例
iframe示例
这里是H1,标记了标题
这里是段落,标记一个段落,属于外层
需要定位上面示例中的:
这里是div中的段落,需要被定位
如下是selenium WebDiriver的代码
## 查找并定位 iframe
element_frame = driver.find_element_by_css_selector('#iframe-1')
## 切换到刚刚查找到的 iframe
driver.switch_to.frame(element_frame)
## 定位
driver.find_element_by_css_selector('#div-1 > p')
## TODO....
## 退出刚刚切换进去的 iframe
driver.switch_to.default_content()
特殊 Select 操作
是选择列表Select 是个selenium的类
selenium.webdriver.support.select.Select
示例,选择 Audi
## 查找并定位到 select
element_select = driver.find_element_by_css_selector('#brand')
## 用Select类的构造方法,实例化一个对象 object_select
object_select = Select(element_select)
## 操作 object_select
object_select.select_by_index(3)
## 也可以这样
object_select.select_by_value('audi')
## 还可以这样
object_select.select_by_visible_text('Audi')
组合操作
自动化经验的积累,需要100%按照手工的步骤进行操作。
比如步骤如下:
代码示例
driver.find_element_by_css_selector('#customer_chosen').click()
sleep(1)
driver.find_element_by_css_selector('#customer_list > li:nth-child(5)').click()
鼠标事件操作
Web测试中,有关鼠标的操作,不只是单击,有时候还要做右击、双击、拖动等操作。这些操作包含在ActionChains类中。
常用的鼠标方法:
- context_click() # 右击
- double_click() # 双击
- drag_and_drop() # 拖拽
- move_to_element() # 鼠标停在一个元素上
- click_and_hold() # 按下鼠标左键在一个元素上
例子:
# 方法模拟鼠标右键,参考代码如下:
# 引入ActionChains 类
from selenium.webdriver.common.action_chains import ActionChains
...
# 定位到要右击的元素
right =driver.find_element_by_xpath("xx")
# 对定位到的元素执行鼠标右键操作
ActionChains(driver).context_click(right).perform()
...
# 定位到要双击的元素
double = driver.find_element_by_xpath("xxx")
# 对定位到的元素执行鼠标双击操作
ActionChains(driver).double_click(double).perform()
键盘事件操作
键盘操作经常处理的如下:
| 代码 | 描述 | ||
|---|---|---|---|
send_keys(Keys.BACKSPACE) |
删除键(BackSpace) | send_keys(Keys.SPACE) |
空格键(Space) |
send_keys(Keys.TAB) |
制表键(Tab) | ||
send_keys(Keys.ESCAPE) |
回退键(Esc) | ||
send_keys(Keys.ENTER) |
回车键(Enter) | ||
send_keys(Keys.CONTROL,'a') |
全选(Ctrl+A) | send_keys(Keys.CONTROL,'c') |
复制(Ctrl+C) |
代码如下
from selenium import webdriver
# 引入Keys 类包
from selenium.webdriver.common.keys import Keys
import time
driver = webdriver.Chrome()
driver.get("http://www.baidu.com")
# 输入框输入内容
driver.find_element_by_id("kw").send_keys("selenium")
time.sleep(3)
# 删除多输入的一个m
driver.find_element_by_id("kw").send_keys(Keys.BACK_SPACE)
time.sleep(3)
# 输入空格键+“教程”
driver.find_element_by_id("kw").send_keys(Keys.SPACE)
driver.find_element_by_id("kw").send_keys("教程")
time.sleep(3)
# ctrl+a 全选输入框内容
driver.find_element_by_id("kw").send_keys(Keys.CONTROL,'a')
截图操作
截图的方法:save_screenshot(file)
1.5 unittest 单元测试框架
在上一节,我们对 Selenium WebDriver 的使用,仅仅停留在让网页自动的进行操作的阶段,并没有对任何一个步骤进行“检查”。当然,这样没有“检查”的操作,实际上是没有测试意义的。那么第一项,我们需要解决的便是“检查”的问题。
所谓“检查”,实际上就是断言。对需要检查的步骤操作,通过对预先设置的期望值,和执行结果的实际值之间的对比,得到测试的结果。在这里,我们并不需要单独的写 if 语句进行各种判定,而是可以使用编程语言中对应的单元测试框架,即可解决好此类问题。
目前 Java 语言主流的单元测试框架有 JUnit 和 TestNG。Python 语言主流的单元测试框架有 unittest 。本小节的内容,主要介绍 unittest 的使用,探讨单元测试框架如何帮助自动化测试。
接下来我们将会使用 Python 语言的unittest框架展开“检查”。unittest框架的原本的名字是PyUnit。是从JUnit 这样一个被广泛使用的经典的Java应用开发的单元测试框架创造而来。类似的框架还有NUnit(.Net开发的单元测试框架)等。我们可以使用unittest框架为任意Python项目编写可理解的单元测试集合。现在这个unittest已经作为Python的标准库模块发布。我们安装完Python以后,便可以直接使用unittest。
使用unittest需要以下简单的三步:
- 引入unittest模组
- 继承unittest.TestCase基类
- 测试方法以
test开头
unittest 并未使用 Java 语言常见的注解方式,依旧停留在 比较早期的 Java 版本中依靠方法名称进行识别的方式。主要有以下两个固定名字的方法:
- setUp():在每个测试方法运行前,执行。是测试前置条件。
- tearDown():在每个测试方法运行后执行,是测试清理操作。
具体的代码如下:
## 引入unittest模组
import unittest
## 定义测试类,名字为DemoTests
## 该类必须继承unittest.TestCase基类
class DemoTests(unittest.TestCase):
## 使用'@'修饰符,注明该方法是类的方法
## setUpClass方法是在执行测试之前需要先调用的方法
## 是开始测试前的初始化工作
@classmethod
def setUpClass(cls):
print("call setUpClass()")
## 每一个测试开始前的预置条件
def setUp(self):
print("call setUp()")
## 每一个测试结束以后的清理工作
def tearDown(self):
print("call tearDown()")
## 测试一(务必以test开头)
def test_01(self):
print("call test_01()")
pass
## 测试三(务必以test开头)
def test_02(self):
print("call test_02()")
pass
## 测试三(务必以test开头)
def test_03(self):
print("call test_03()")
pass
## tearDownClass方法是执行完所有测试后调用的方法
## 是测试结束后的清除工作
@classmethod
def tearDownClass(cls):
print("call tearDownClass()")
# 执行测试主函数
if __name__ == '__main__':
## 执行main全局方法,将会执行上述所有以test开头的测试方法
unittest.main(verbosity=2)
需要注意步骤:
- 引入 unittest 模组
- 继承 unittest.TestCase 类
- 做测试用例的方法,方法以 test_ 开头
- 附加 setUp(), tearDown(), 在每个 test_ 方法执行前后 进行执行
- 附加 setUpClass(), tearDownClass()
需要在 类实例化的对象,运行的开头和结尾进行执行。
加了星号(*)的步骤,可以不用。
上述代码运行结果如下:
call setUpClass()
call setUp()
call test_01()
call tearDown()
call setUp()
call test_02()
call tearDown()
call setUp()
call test_06()
call tearDown()
call tearDownClass()
为什么选择 unittest
清晰的单元测试框架,提供 TestCase, TestSuite, TextTestRunner 等基本类
unittest 是 原生 Python 的一部分
unittest 有第三方可用的 HTML 库,可以轻松的生成 测试报告
-
unittest 的断言配置使用
unittest 的断言,属于
TestCase类,只要继承了该类,均可以通过 self调用断言方法 Method 检查条件
assertEqual(a, b [, msg])a == b,msg可选,用来解释失败的原因assertNotEqual(a, b [, msg]a != b,msg可选,用来解释失败的原因assertTrue(x [, msg])x 是真,msg可选,用来解释失败的原因assertFalse(x [, msg])x 是假,msg可选,用来解释失败的原因assertIsNot(a, b [, msg])a 不是 b,msg可选,用来解释失败的原因
1.6 为什么需要封装 Selenium
-
什么是封装
封装是一个面向对象编程的概念,是面向对象编程的核心属性,通过将代码内部实现进行密封和包装,从而简化编程。对Selenium进行封装的好处主要有如下三个方面:
- 使用成本低
- 不需要要求所有的测试工程师会熟练使用Selenium,而只需要会使用封装以后的代码
- 不需要对所有的测试工程师进行完整培训。也避免工作交接的成本。
- 测试人员使用统一的代码库
- 维护成本低
- 通过封装,在代码发生大范围变化和迁移的时候,不需要维护所有代码,只需要变更封装的部分即可
- 维护代码不需要有大量的工程师,只需要有核心的工程师进行封装的维护即可
- 代码安全性
- 对作为第三方的Selenium进行封装,是代码安全的基础。
- 对于任何的代码的安全隐患,必须由封装来解决,使得风险可控。
- 使用者并不知道封装内部的代码结构。
1.7 如何封装
这里面向的用户是开发者,有一定基础的,特别是面向对象开发基础的开发者。封装,最简单直接就是函数、方法、类。这里不再复述。
1.8 Page-Object设计模式介绍
-
Page-Object设计模式的本质
Page Object设计模式是Selenium自动化测试项目的最佳设计模式之一,强调测试、逻辑、数据和驱动相互分离。
Page Object模式是Selenium中的一种测试设计模式,主要是将每一个页面设计为一个Class,其中包含页面中需要测试的元素(按钮,输入框,标题等),这样在Selenium测试页面中可以通过调用页面类来获取页面元素,这样巧妙的避免了当页面元素id或者位置变化时,需要改测试页面代码的情况。当页面元素id变化时,只需要更改测试页Class中页面的属性即可。
它的好处如下:
- 集中管理元素对象,便于应对元素的变化
- 集中管理一个page内的公共方法,便于测试用例的编写
- 后期维护方便,不需要重复的复制和修改代码
具体的做法如下:
- 创建一个页面的类
- 在类的构造方法中,传递 WebDriver 参数。
- 在测试用例的类中,实例化页面的类,并且传递在测试用例中已经实例化的WebDriver对象。
- 在页面的类中,编写该页面的所有操作的方法
- 在测试用例的类中,调用这些方法
-
Page 如何划分
一般通过继承的方式,进行按照实际Web页面进行划分
-
Page-Object 类如何实现
实现的示例
-
Page 基类
- 设计了一个基本的 Page类,以便所有的页面进行继承,该类标明了一个sub page类的基本功能和公共的功能。
- 全局变量: self.base_driver,让所有的子类都使用的。
# 基类的变量,所有继承的类,都可以使用 base_driver = None构造方法:
传递 driver的构造方法
# 方法 def __init__(self, driver: BoxDriver): """ 构造方法 :param driver: ":BoxDriver" 规定了 driver 参数类型 """ self.base_driver = driver- 私有的常量:存放元素的定位符
-
```python
LOGIN_ACCOUNT_SELECTOR = "s, #account"
LOGIN_PASSWORD_SELECTOR = "s, #password"
LOGIN_KEEP_SELECTOR = "s, #keepLoginon"
LOGIN_SUBMIT_SELECTOR = "s, #submit"
LOGIN_LANGUAGE_BUTTON_SELECTOR = "s, #langs > button"
LOGIN_LANGUAGE_MENU_SELECTOR = "s, #langs > ul > li:nth-child(%d) > a"
LOGIN_FAIL_MESSAGE_SELECTOR = "s, body > div.bootbox.modal.fade.bootbox-alert.in > div > div > div.modal-body"
```
- 成员方法:
- 每个子类都需要的系统功能:
- open
```pypthon
def open(self, url):
"""
打开页面
:param url:
:return:
"""
self.base_driver.navigate(url)
self.base_driver.maximize_window()
sleep(2)
```
- 所有子类(页面)都具有的业务功能
- select\_app
- logout
- Sub Pages(s)子类
- 具体的页面的类,定义了某个具体的页面的功能
- 必须继承基类
```
class MainPage(BasePage):
```
- 特定页面的业务
- 使用基类的 `self.base_driver` 成员变量
- Tests 类
- 这部分描述的是具体的测试用例。
- 声明全局变量
```
base_driver = None
base_url = None
main_page = None
```
- 调用各种页面(pages)
- 实例化Page
```python
self.main_page = MainPage(self.base_driver)
```
- 使用page的对象,调用成员方法
```python
self.main_page.open(self.base_url)
self.main_page.change_language(lang)
```
2. 构建测试方案
2.1 数据驱动在自动化测试中的应用
-
什么是数据驱动
主要的数据驱动方式有两种:
- 通过 文本文件或者 Excel 文件存储数据,并通过程序读取数据,遍历所有的行
- 通过数据库存储数据,并通过程序和 SQL 脚本读取数据,遍历所有的行
通过 CSV 文件 或者 MySQL 数据库,是主流的数据驱动方式。当然数据驱动也可以结合单元测试框架的参数化测试进行编写(此部分本文不做具体描述)。
无论使用了 哪一种(CSV 或者 MySQL),读取数据后都要进行遍历操作。
- 使用 csv
```python
import csv
csv_file = open("xxx.csv", "r", encoding="utf8")
csv_data = csv.reader(csv_file)
for row in csv_data:
# 进行测试
# 使用字典类型
data_to_test = {
"key1": row[0],
"key2": row[1]
}
csv_file.close()
```
- 使用 MySQL
```python
import pymysql
connect = pymysql.connect(host="xx", port=3306, user="root", passwd="xxx", db="xx")
cur = connect.cursor()
cur.execute("SELECT...")
mysql_data = cur.fetchall()
for row in mysql_data:
# 进行测试
# 使用字典类型
data_to_test = {
"key1": row[0],
"key2": row[1]
}
cur.close()
connect.close()
```
-
需要掌握的知识点:
- python的字典类型
dict类型 - python的读写文件
- python的读写数据库
- for循环
- 注意资源的释放
- 关闭数据库游标和连接
- 关闭文件
- python的字典类型
2.2 测试方案的编码实现
- main.py 测试入口
- runner.py 测试运行器
- cases 测试用例
- pages 测试页面
- base 底层封装与驱动
2.3 测试报告的生成
如何生成测试报告
测试报告的种类
-
HTML 测试报告的生成
HTML测试报告需要引入HTMLTestRunner
HTMLTestRunner是基于Python2.7的,我们的课程讲义基于Python3.x,那么需要对这个文件做一定的修改。
测试的示例代码如下
```python
# 声明一个测试套件
suite = unittest.TestSuite()
# 添加测试用例到测试套件
suite.addTest(RanzhiTests("test_ranzhi_login"))
# 创建一个新的测试结果文件
buf = open("./result.html", "wb")
# 声明测试运行的对象
runner = HTMLTestRunner.HTMLTestRunner(stream=buf,
title="Ranzhi Test Result",
description="Test Case Run Result")
# 运行测试,并且将结果生成为HTML
runner.run(suite)
# 关闭文件输出
buf.close()
```
From:测试/selenium自动化测试基础-www.9ong.com