干货!人体姿态估计与运动预测
点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!
我们人类具有识别人体姿态、预测短期未来的能力,例如在走路时我们会识别对向行人的姿态,根据对他们未来运动的预测来决定往左走还是往右走,在打篮球或踢足球时会根据对防守球员的姿态、运动预测选择如何突破。未来,机器要实现与人类的自然互动,势必需要能够理解人体的姿态、行为和预测未来运动。本文针对人体姿态估计与运动预测两个任务介绍我们最新的工作,具体来讲是从视频图像中估计人体姿态、基于人体或动物已知的姿态序列预测未来姿态序列两个工作。
本期AI TIME PhD直播间,我们邀请到浙江工商大学教授——刘振广,为我们带来报告分享《人体姿态估计与运动预测》。

刘振广:
浙江大学特聘研究员,浙江工商大学教授,曾任新加坡国立大学、新加坡科技研究局博士后和Research Fellow,博士和本科分别毕业于浙江大学和山东大学。主要研究方向为多媒体数据理解和区块链智能合约安全,入选首批“浙江省高校领军人才青年优秀人才",2018" 全球区块链专利创新人才百人榜”,获得过最佳论文提名奖、PoseTrack 2017、PoseTrack2018多帧姿态估计挑战赛全球第1名、互联网+创新创业大赛金奖等荣誉。近5年, 发表CCF A类和IEEE/ACM汇刊论文30余篇,其中第一或通讯作者CCF A类论文20余篇,涵盖PAMI、CVPR、ICCV、TKDE、AAAI、 ICAI、ACM Multimedia等顶会顶刊。担任CCF A类的CVPR、ICCV、AAAI、IJCAI、 ACM Multimedia、WWW等多个国际顶会的高级程序委员会委员或委员,担任多个TIP、TVCG、TMM、TOMM、TII等IEEE/ACM汇刊(Transaction)的审稿人。
一、 人体姿态估计
01
背 景
人体姿态估计是许多计算机视觉任务的基础,如动作识别、暴力检测和行为理解等现实应用都需要先识别人体姿态。人体姿态估计对于机器理解人类来说也至关重要,当机器对人体姿态能够进行预测,更有利于机器与人进行交互。
人体姿态估计研究的问题具体描述为:输入一段视频,输出视频中每一帧的人体姿态骨架,如下图所示。

现有方法大多是针对静态图像设计的,通常忽略了视频帧间的时间连续性和几何一致性。因此,当我们将这些方法应用到视频时,它们的效果往往并不理想。如下图所示,在视频中,由于人的快速运动,导致某一帧是模糊的,并且周围临近的人也会对当前人体姿态估计产生干扰,还有一些遮挡、无法对焦等问题,都会使得基于静态图像的姿态估计方法直接应用于视频的效果不好。
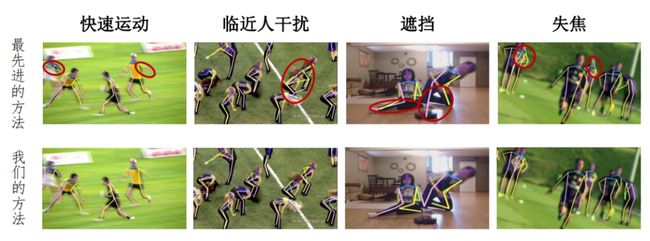
02
方 法
因此,我们提出了一种从视频图像中估计人体姿态估计的方法——DCPose(在论文《Deep Dual Consecutive Network for Human Pose Estimation》中提出)。DCPose的关键思想是合并来自双向时间方向的连续帧来改善视频中的姿态估计。我们使用当前帧的前一帧和后一帧来优化当前帧的姿态估计,以应对当前帧遮挡、失焦、快速运动等复杂情景。
DCPose算法的整体框架如下图,主要分为三个模块:姿态时序合并、姿态残差融合、姿态矫正网络。首先,采用矩形框将需要进行姿态估计的人体分别从当前帧、前一帧、后一帧中框出来,通过HRNet将人体头部、左右脚等人体各部位的热图分别估计出来。为了各部位之间互不影响,在姿态时序合并模块我们按照部位进行分组后进行分组卷积。姿态残差融合是使用后一帧减去当前帧、当前帧前去前一帧的方式得到运动残差,以此获得运动上下文信息。然后,在姿态矫正网络,我们设计了5层膨胀卷积将热图信息和运动上下文信息一起进行处理,给出一个姿态预测。
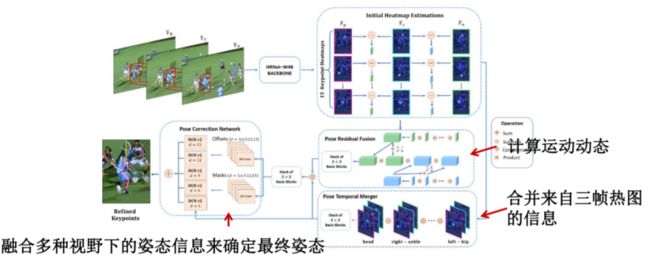
本文方法是第一个提出采用运动上下文信息进行姿态优化的,并且我们还设计了前面的某一邻居帧、当前帧、后面的某一邻居帧在估计时的权重,邻居帧离当前帧越近,分配的权重越大。
03
实 验
DCPose获大型数据集PoseTrack2017 多帧人体姿态估计挑战赛全球第1名。
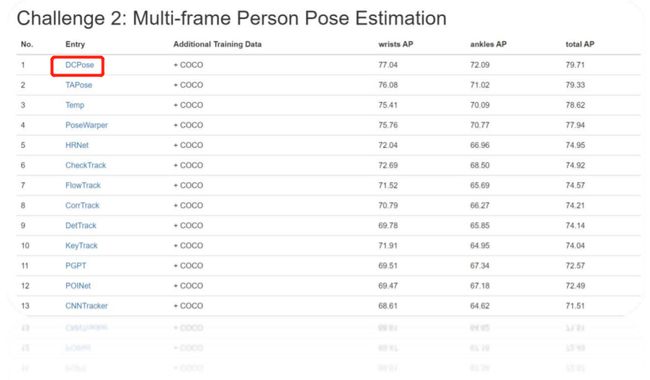
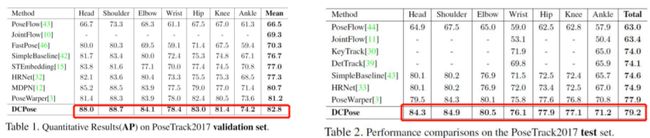
下面是DCPose与现有方法的比较——采用平均精度(mAP)作为评价指标。DCPose均取得最优表现。

二、运动预测
01
背 景
如下图所示,运动预测任务是:输入观测到的3D姿态(关节位置)序列,然后输出预测的未来姿态序列。人类有很强的短期运动预测能力,比如我们会根据对对向行人的未来预测选择往左走还是往右走,打篮球或踢足球时会根据防守球员未来运动的预测选择是突破还是传球。机器与人类交互,也需要预测人体未来运动的能力。
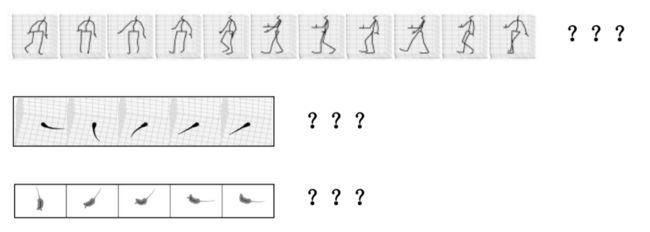
现有的运动估计方法主要存在两个方面的问题,一是短期预测连续性差,我们从视觉上看就是运动预测的第一帧与前面给定的观测到的视频序列末尾帧之间出现不连续或跳帧的现象;二是长期预测不够自然,随着时间推移,算法给出的运动预测结果人就开始一动不动(静止),或者变形。下面的例子是我们做的对比实验,其中横坐标是视频帧数,纵坐标是真实值和不同算法给出的预测。
现有方法表现差的本质原因:
①没有显式考虑骨骼本身特性:各关节真实自由度、骨骼长度不变性。
②依赖LSTM,GRU等传统时间序列深度学习建模方法。
02
方 法
我们提出了HMR算法来解决上面提到的运动预测的问题。
为了处理关节间的物理关系,我们使用李群建模关节间关系,显式嵌入关节自由度、骨骼长度不变性。以下面鱼骨的图为例,每个关节都建立一个三维坐标系,每个关节都能够通过前一个关节的坐标系通过旋转平移等操作进行表征。

并且,我们提出了新的网络模型处理时间序列。首先我们给视频中每一帧都设置一个局部隐状态,保存每一帧的运动信息。然后设置一个全局隐状态来建模整个时间序列的运动信息。每一个局部隐状态需要与自己的前后两个相邻帧进行信息交换,从而实现整个时间序列都进行了信息的传递与交换。根据任务难度,自适应进行递归所需步数的调整。
03
实 验
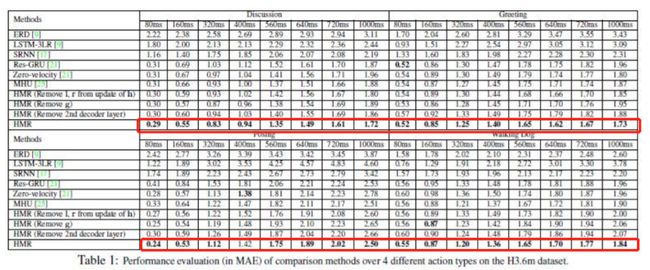
本文方法于其他运动预测的方法相比,短期预测更为精准,长期预测更为自然。
提
醒
论文链接:
https://arxiv.org/abs/2 103.07254
点击“阅读原文”,即可观看本场回放
整理:爱 国
审核:刘振广
直播预告

往期精彩文章推荐

记得关注我们呀!每天都有新知识!
关于AI TIME
2019年,清华大学人工智能研究院院长张钹院士、唐杰教授和李涓子教授等人联合发起“AI TIME science debate”,希望用辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
AI TIME是清华大学计算机系一群关注人工智能发展,并有思想情怀的青年学者创办的圈子。AI TIME旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法、场景、应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家与爱好者,打造成为全球AI交流与知识分享的聚集地。

我知道你
在看
哦
~
![]()
点击 阅读原文 查看回放!