CTR深度学习模型之 DSIN(Deep Session Interest Network) 论文解读
之前的文章讲解了DIEN模型:CTR深度学习模型之 DIEN(Deep Interest Evolution Network) 的理解与示例,而这篇文章要讲的是DSIN模型,它与DIEN一样都从用户历史行为中抽取兴趣表示,但不同的是DSIN把历史行为划分成了不同的Session,并且使用Transformer对每个Session内的行为抽取特征。
模型解读
整体模型的结构如下:

首先看看右下部分的矩形区域,这部分主要是对用户的行为序列建模,其中包含了4个子模块。
1. Session Divsion Layer
从下往上看的话,最底层的粉色区域是Session分割层:

首先是把用户的行为序列 S = b 1 , b 2 , . . . B N S={b_1, b_2, ... B_N} S=b1,b2,...BN 划分成K个Session会话 Q 1 , Q 2 , . . . Q K Q_1, Q_2, ... Q_K Q1,Q2,...QK ,不同的Session直接的间隔大于30分钟,同一Session内的序列 b 1 , b 2 , . . . , b T {b_1, b_2, ..., b_T} b1,b2,...,bT 的间隔小于30分钟。
2. Session Interest Extractor Layer
得到K个Session后,输入到黄色的Session兴趣抽取层,最终得到K个Session的兴趣表示:
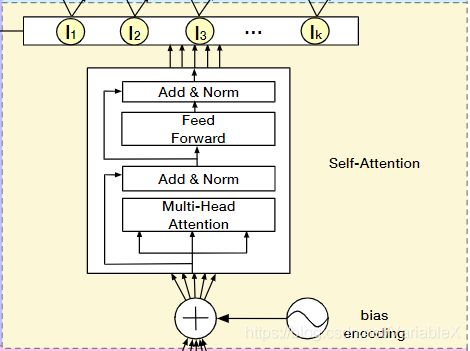
这一层把每个Session的序列数据 Q k Q_k Qk 和对应的 bias encoding 结合起来,通过Transformer的 Multi-head Self-Attention机制提取Session内部行为之间的联系,进而得到Session对应的兴趣表示 I k I_k Ik 。
2.1 bias encoding
首先,这个 bias encoding 是怎么回事?
为了刻画不同Session中不同物品的顺序关系,引入了 bias encoding :
B E ( k , t , c ) = w k K + w t T + w c C BE_{(k,t,c)} = w_k^K + w_t^T + w_c^C BE(k,t,c)=wkK+wtT+wcC
B E ( k , t , c ) BE_{(k,t,c)} BE(k,t,c) 表示第k个session中第t个物品的embedding向量的第c个位置的偏置项,于是输入到 Self-attention 中的数据为:
Q = Q + B E Q = Q + BE Q=Q+BE
其中,Q 包含了 Q 1 , Q 2 , . . . , Q K Q_1, Q_2, ... , Q_K Q1,Q2,...,QK。
2.2 Multi-head Self Attention
然后就是每个Session的数据输入到 Transformer 中:

对于输入的数据,首先进入的是 Multi-head Self-Attention,不同 head 学习到的 Attention 可能有所不同,这好比是用户对商品的注意力头可能放在颜色,款式,价格等不同因素上。假设要使用 H 个 head,那么作者把 Q k Q_k Qk 中每个物品的embedding平分成了H份: Q k = [ Q k 1 , Q k 2 , . . . , Q k H ] Q_k = [Q_{k1}, Q_{k2}, ..., Q_{kH}] Qk=[Qk1,Qk2,...,QkH] ,其中 Q k h ∈ R T × d h , d h = 1 H d m o d e l Q_{kh} \in \mathbb{R}^{T \times d_h}, d_h = \frac{1}{H} d_{model} Qkh∈RT×dh,dh=H1dmodel , 然后就是计算每个 head 的 attention:
head h = Attention ( Q k h W Q , Q k h W K , Q k h W V ) = softmax ( Q k h W Q W K T Q k h T d model ) Q k h W V \begin{aligned} \text { head }_{h} &=\text { Attention }\left(\mathbf{Q}_{k h} \mathbf{W}^{Q}, \mathbf{Q}_{k h} \mathbf{W}^{K}, \mathbf{Q}_{k h} \mathbf{W}^{V}\right) \\ &=\operatorname{softmax}\left(\frac{\mathbf{Q}_{k h} \mathbf{W}^{Q} \mathbf{W}^{K^{T}} \mathbf{Q}_{k h}^{T}}{\sqrt{d_{\text {model }}}}\right) \mathbf{Q}_{k h} \mathbf{W}^{V} \end{aligned} head h= Attention (QkhWQ,QkhWK,QkhWV)=softmax(dmodel QkhWQWKTQkhT)QkhWV
其中 W Q , W K , W V W^Q, W^K, W^V WQ,WK,WV 是线性变换矩阵,是模型需要学习的参数。然后将 Q k Q_k Qk 所有的 head 拼接到一起,然后经过 Add & Norm 层(残差连接与层归一化),输入到前馈神经网络中:
I k Q = F F N ( C o n c a t ( h e a d 1 , h e a d 2 , . . . , h e a d H ) W o ) I_k^Q = FFN(Concat(head_1, head_2, ..., head_H)W^o) IkQ=FFN(Concat(head1,head2,...,headH)Wo)
然后再经过一个 Add & Norm 层。需要注意的是, I k Q I_k^Q IkQ 仍然是 T × d m o d e l T\times d_{model} T×dmodel的大小,于是可以使用一个平均值池化把每个Session的序列转为 d m o d e l d_{model} dmodel 维向量:
I k = A v g ( I k Q ) I_k = Avg(I_k^Q) Ik=Avg(IkQ)
3. Session Interest Interacting Layer
得到了K个Session的兴趣表示 I 1 , I 2 , . . . , I K I_1, I_2, ..., I_K I1,I2,...,IK 后,还需要输入到 Bi-LSTM 中捕获不同Session间的演变过程:
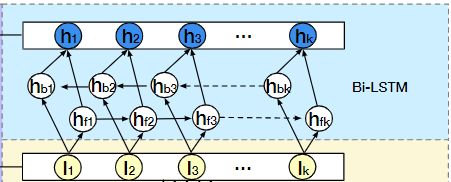
最终每个时刻的输出为:
H t = C o n c a t ( h f t , h b t ) H_t = Concat (h_{ft}, h_{bt}) Ht=Concat(hft,hbt)
其中 h f t , h b t h_{ft}, h_{bt} hft,hbt 是前向LSTM的隐藏状态和反向LSTM的隐藏状态。
4. Session Interest Activating Layer
经过上面的步骤,得到了两种 Session表示: I 1 , I 2 , . . . , I K I_1, I_2, ..., I_K I1,I2,...,IK 以及 H 1 , H 2 , . . . , H K H_1, H_2, ... , H_K H1,H2,...,HK,接下来就可以分别和目标商品计算相似度了,如下图的紫色部分所示:
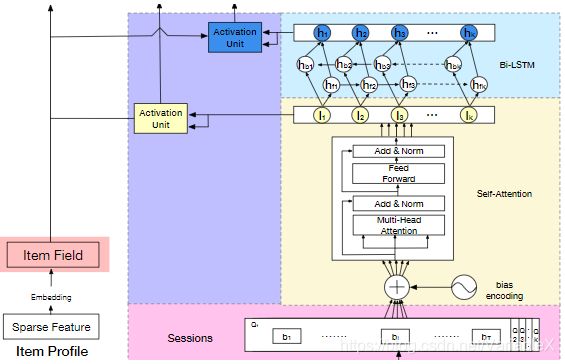
其中的 Activation Unit 结构如下图所示:
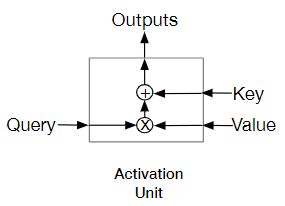
左边的输入是目标物品的 embedding,右边的两个输入都是Session表示,这个注意力单元可以给不同的 Session 分配不同的权重,用来表示某个 Session 和目标物品的相关性,进而可以对各个 Session 进行加权求和:
a k I = exp ( I k W I X I ) ) ∑ k K exp ( I k W I X I ) U I = ∑ k a k I I k \begin{aligned} a_{k}^{I} &=\frac{\left.\exp \left(\mathbf{I}_{k} \mathbf{W}^{I} \mathbf{X}^{I}\right)\right)}{\sum_{k}^{K} \exp \left(\mathbf{I}_{k} \mathbf{W}^{I} \mathbf{X}^{I}\right)} \\ \mathbf{U}^{I} &=\sum_{k} a_{k}^{I} \mathbf{I}_{k} \end{aligned} akIUI=∑kKexp(IkWIXI)exp(IkWIXI))=k∑akIIk
a k H = exp ( H k W H X I ) ) ∑ k K exp ( H k W H X I ) U H = ∑ k K a k H H k \begin{aligned} a_{k}^{H} &=\frac{\left.\exp \left(\mathbf{H}_{k} \mathbf{W}^{H} \mathbf{X}^{I}\right)\right)}{\sum_{k}^{K} \exp \left(\mathbf{H}_{k} \mathbf{W}^{H} \mathbf{X}^{I}\right)} \\ \mathbf{U}^{H} &=\sum_{k}^{K} a_{k}^{H} \mathbf{H}_{k} \end{aligned} akHUH=∑kKexp(HkWHXI)exp(HkWHXI))=k∑KakHHk
其中的X,就是目标item的embedding.
最后一个部分就是把用户特征向量、待推荐物品向量、会话兴趣加权向量 U I U^I UI、带上下文信息的会话兴趣加权向量 U H U^H UH进行横向拼接,输入到全连接层中,得到输出:
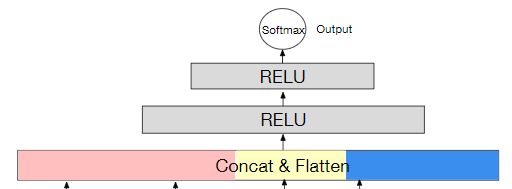
实验结果
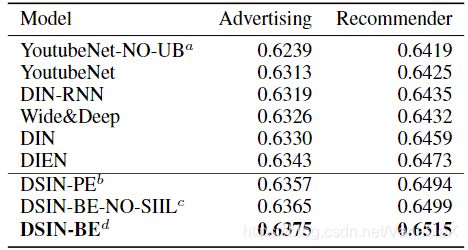
使用了两个数据集进行了实验,分别是阿里妈妈的广告数据集(Advertising)和阿里巴巴的电商推荐数据集(Recommender)。如下图所示:
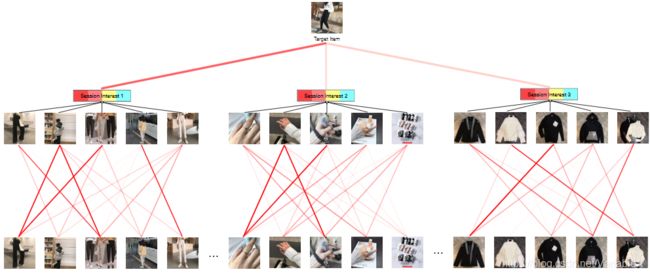
对于某个商品,attention 可视化结果如下所示:
参考文章:
Deep Session Interest Network for Click-Through Rate Prediction
DSIN(Deep Session Interest Network )分享
推荐系统论文DSIN:Deep Session Interest Network