前言
本文旨在以工作实务为重心,着力于数据分析的工作思路思维,力求高效精准地完成数据分析任务。简而言之,就是一份数据摆在面前,我们要如何快速有效地做出分析,完成工作目标。
分析思路
对一份数据进行分析,一般包括数据清洗、数据分析和数据展示三个步骤。数据清洗是最花时间的,往往会占到整个分析的70%~80%。数据清洗好了,分析和展示部分其实是相对没有那么繁琐的,甚至可以说是分析师享受的时间。但拿到数据时,切勿马上进行数据清洗。因为我们所有的数据分析工作都是围绕分析目标展开的。了解你的分析目标,或者说要利用这份数据达到什么目的,是我们首先要去明确的。这样你的清洗工作才会更有针对性、更有效率。
本次使用的数据为链家2015年-2019年在北京的部分二手房销售数据。假设我们的分析需求(目标)如下:
- 计算每平米二手房均价
- 各大区房屋面积总和
- 2019年北京二手房交易趋势
- 2019年北京二手房成交的单位均价走势
- 按周分析2019年平均挂牌周期
通过观察这些需求,我们会有一个大致的了解。要对这些需求进行分析,我们一定会用到数据中跟价格、面积和时间等有关的字段。所以在对数据的清洗时,务必对这些字段进行正确的清洗,否则无法进行相应的运算。
数据清洗
材料:链家二手房销售数据
工具:Jupyter Notebook
在这个阶段,我们优先对重要的、与数字有关的、以及容易判断和处理的字段进行处理。
首先导入分析常用的库和进行一些设置
import numpy as np
import pandas as pd
import re
import matplotlib.pyplot as plt
import matplotlib as mpl
import seaborn as sns
import warnings
warnings.filterwarnings("ignore") # 忽略警告信息
pd.set_option('max_columns', 50) # 设置最大列显示数,方便查看
%matplotlib inline # 图表以嵌入式显示
sns.set() # seaborn默认设置
plt.rcParams['font.sans-serif']=['SimHei'] # 解决图表中文乱码
plt.rcParams['axes.unicode_minus']=False # 解决图表负号显示
完成以上操作,就可以加载数据,并对它进行观察了
lianjia = pd.read_csv('lianjia.csv', encoding='utf8', sep='\t') # 加载数据
lianjia.info() # 观察数据格式、完整性等

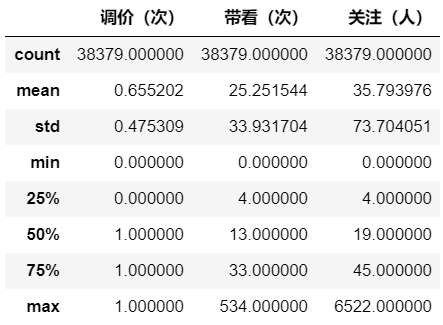
lianjia.describe() # 可参与计算的字段的描述性分析
lianjia[lianjia.duplicated()] # 查看重复项
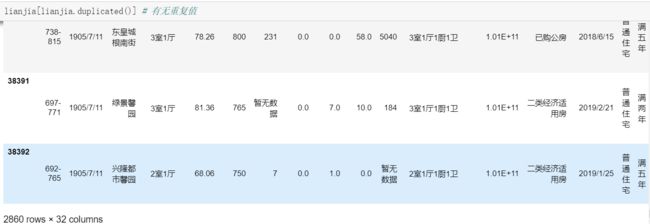
lianjia = lianjia.drop_duplicates() # 删除重复项
lianjia.head(5) # 显示数据前5行
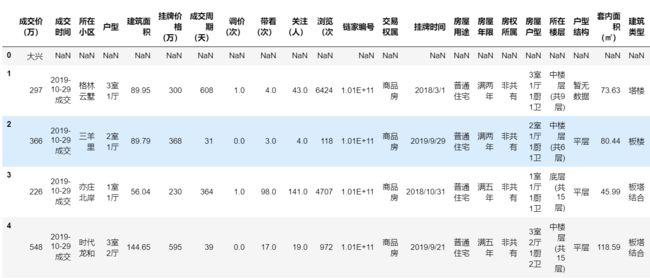

通过观察,可以发现:
- 这份数据一共有38393条记录,只有“成交价(万)”字段的非空记录达到这个数字,其他大部分字段的记录数相等且接近最大记录数,同时“xx1”、“xx2”这两个字段只有少量数据
- 从描述性分析可以看出能够直接进行计算的字段不多,且都不是我们的分析目标需要的字段,需要的那些字段都要进行清洗
- 预览前5条数据,可以看到“成交价(万)”字段存在中文记录;另外,“xx1”、“xx2”字段存在大量NaN值。
我们先从这几个有明显问题的字段入手,逐步进行清洗。
成交价(万)
根据“成交价(万)”字段的数据显示方式,初步判断这份数据是北京市各个大区汇总的数据。每个区的第一行都有大区的名称进行区分,导致其他字段记录为NaN。从操作数据的角度来看,我们更希望大区作为单独的字段在数据中显示,这会为我们在后续分析中进行聚合操作提供便利,所以我的思路是创建单独的“大区”字段,“成交价(万)”字段里跟区域有关的记录则删除掉,代码如下:
lianjia['大区'] = lianjia['成交价(万)'] # 生成新的字段“大区”
lianjia['大区'] = lianjia['大区'].str.replace('-', '').replace('\d+', np.nan, regex=True) # 利用正则,将数值替换成NaN
lianjia['大区'].fillna(method='ffill', inplace=True) # 将NaN值向前填充,记录将正确对应各自的大区
lianjia.dropna(axis=0, inplace=True, thresh=10) # 删除非空字段不足10个的记录,等于把“成交价(万)”中的区域名称删除了
“大区”是一个比较重要的字段,可以把它放在第一列
temp = lianjia['大区'] # 将大区字段赋值给一个临时变量
lianjia.drop('大区', axis=1, inplace=True) # 删除原“大区”字段
lianjia.insert(0, '大区', temp) # 将临时变量的值插入原数据第一列
处理完,看起来舒服多了,但是成交价(万)还不是可以进行计算的数据类型,同时还存在“xxx-xxx”这类的数据需要处理

这里通过定义一个函数,使用映射的方式进行处理
def trans(dprice):
dprice2 = str(dprice).split('-')
if len(dprice2) == 1: # 如果无需拆分则直接返回原值
return dprice
else:
avgprice = (float(dprice2[0]) + float(dprice2[1])) / 2 # 如能按照'-'拆分则求平均值
return avgprice
lianjia['成交价(万)'] = lianjia['成交价(万)'].map(trans)
lianjia['成交价(万)'] = lianjia['成交价(万)'].astype('float32') # 可以正确转换为浮点数了!
xx1、xx2
再来看看“xx1”、“xx2”的非空字段
lianjia[lianjia['xx1'].isnull() == False].sample(3)
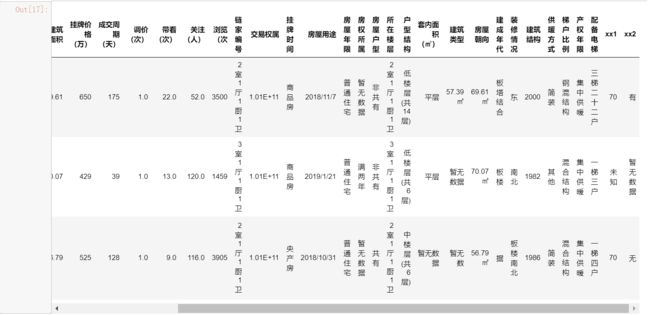
仔细观察,可以发现“xx1”、“xx2”字段出现记录的原因是因为其他字段记录的数据出现了错位,而且错位的数据中有两个面积数据,这就非常的麻烦了。因为我们不能单纯的认为所有错位的数据同时移动了n列,事实也证明了这一点:这些数据一开始只移动了一列,后来变成移动了两列,而这也只是从观察上的推测,这使得我们已经无法判断原数据是怎样的情况了。如果硬要清洗这部分数据,需要把它单独拿出来处理。但这个错位可能在数据写入时就已经发生,不清楚数据仓库的结构,我们很难去对它进行还原。但是不处理这些记录,错位的数据又会导致我们在清洗其他字段时遇到大量异常值。
所幸的是,这些错位的数据记录并不太大,只占整个数据的10%不到,我们可以考虑删除这些记录而不使整体数据和清洗效率受到太大影响。

去重后记录不多,我们直接一个个删
lianjia.drop(lianjia[lianjia['xx1'] == '70'].index, inplace=True) # 就地删除
lianjia.drop(lianjia[lianjia['xx1'] == '40'].index, inplace=True)
lianjia.drop(lianjia[lianjia['xx1'] == '50'].index, inplace=True)
lianjia.drop(lianjia[lianjia['xx1'] == '未知'].index, inplace=True)
删完一个,另一个也没了

两个字段的错位记录都删除了,现在删除这两列
lianjia.drop(['xx1', 'xx2'], axis=1, inplace=True)
成交时间、成交周期(天)、挂牌时间
时间放在一起分析
lianjia[['成交时间', '成交周期(天)', '挂牌时间']].sample(5)

看起来,“成交时间”的记录是比较乱的,有的包含文字,有的没有天数,分隔符也不一致;“成交周期(天)”的异常值都是”暂无数据“,但它可以从“挂牌时间”减去“成交时间”得到;“挂牌时间”则没有什么问题,只需将数据类型转换为日期类型即可。
Dataframe中的每个字段实际就是一个Series,利用其str属性来处理多余的字符。
lianjia['成交时间'] = lianjia['成交时间'].str.replace('成交', '') # 将“成交”替换成空
为成交时间只有年月的记录增加天数。这里一般有以下三种策略:
1)统一为当月第一天
2)统一为月中
3)统一为月末最后一天
第一种最简单,直接使用to_datetime函数,只有年月的记录会自动将天数变更为“01”,但由于有的记录是当月成交的,这就会使“成交周期(天)”变成负值(成交周期(天)= 成交时间 - 挂牌时间)。策略2也会出现这种问题,所以我选了策略3去尽量避免这种情况。
定义一个函数来添加天数。由于分隔符不一致,需要使用正则表达式来进行分割,这又会使分割出来的出现 ["YYYY", "mm"] 和 ["YYYY", "mm", ""]两种情况;每个月末最后一天也不尽相同,如果数据有2000年这种是100的倍数的年份还要计算世纪闰年,这些都需要考虑进去。
def redate(dtime):
dtime2 = re.split(r'\W', str(dtime))
if len(dtime2) == 2 or (len(dtime2) == 3 and dtime2[-1] == ''):
if dtime2[1] in ('01', '03', '05', '07', '08', '10', '12'):
return dtime2[0]+ '-' + dtime2[1] + '-' + '31'
elif dtime2[1] in ('04', '06', '09', '11'):
return dtime2[0] + '-' + dtime2[1] + '-' + '30'
elif int(dtime2[0]) // 4 == 0 and datime2[0] == '02': # 普通闰年二月
return dtime2[0] + '-' + dtime2[1] + '-' + '29'
else:
return dtime2[0] + '-' + dtime2[1] + '-' + '28' # 平年二月
else:
return dtime
lianjia['成交时间'] = lianjia['成交时间'].map(redate) # 应用定义的函数映射给“成交时间”字段
lianjia['成交时间'] = pd.to_datetime(lianjia['成交时间']) # 可以转换为日期类型了
lianjia['挂牌时间'] = pd.to_datetime(lianjia['挂牌时间']) # 字段记录正常,直接转换为日期类型
lianjia['成交周期(天)'] = lianjia['成交时间'] - lianjia['挂牌时间'] # 处理“成交周期(天)”
lianjia[lianjia['成交周期(天)'].dt.days < 0] # 查看成交周期小于零的记录

可以看到,即使经过较为合理的清洗,“成交周期(天)”依然有负值。这可能是工作人员将成交时间和挂牌时间的数据录反了。这些记录的其他字段数据都比较齐全,我选择将其绝对值化。
lianjia['成交周期(天)'] = np.abs(lianjia['成交周期(天)']) # 求“成交周期(天)”字段的绝对值
户型、建筑面积、套内面积(㎡)
接下来要处理跟面积有关的字段了。
但是在这之前,我发现了“户型”字段的一些问题——这个字段居然包含了车位!这可不属于二手房销售的范畴,需要剔除

顺便看看这个字段还有哪些异常值需要处理
lianjia['户型'].unique()

lianjia[(lianjia['户型'] == "#NAME?") | (lianjia['户型'] == "车位")].sample(3)

值为"#NAME?"的记录的其他字段存在大量值的缺失,跟车位一起删除吧
lianjia.drop(lianjia[lianjia['户型'] == '#NAME?'].index, inplace=True)
lianjia.drop(lianjia[lianjia['户型'] == '车位'].index, inplace=True)
现在可以处理建筑面积了,观察一下数据
似乎没什么问题,那就转换成数值型
lianjia['建筑面积'] = pd.to_numeric(lianjia['建筑面积'], errors='coerce') # 转换成数值型,发生错误时将无法转换的类型强制转为NaN
只有两条异常数据,且没有同小区同户型的面积可以参照,删除之

lianjia.drop(lianjia[lianjia['建筑面积'].isnull()==True].index, inplace=True)
“套内面积(㎡)”处理方式跟“建筑面积”类似。但这个字段记录缺失比较严重,很多记录都是“暂无数据”
强制转为数值类型,可以看到NaN值超过1万3千条
lianjia['套内面积(㎡)'] = pd.to_numeric(lianjia['套内面积(㎡)'], errors='coerce')
lianjia[lianjia['套内面积(㎡)'].isnull() == True]

由于NaN值较多,为求数据尽量反应真实情况,先按“所在小区”和“房屋户型”分组,将NaN替换为分组后的面积均值(其实就是同户型的正确面积)
lianjia['套内面积(㎡)'] = lianjia['套内面积(㎡)'].fillna(lianjia.groupby(['所在小区', '房屋户型'])['套内面积(㎡)'].transform('mean'))
lianjia[lianjia['套内面积(㎡)'].isnull() == True]
处理完依然有差不多6千多条没有替换

退而求其次,按照相同房屋户型分组的面积均值进行替换
lianjia['套内面积(㎡)'] = lianjia['套内面积(㎡)'].fillna(lianjia.groupby('房屋户型')['套内面积(㎡)'].transform('mean'))
剩下不到50条,再按整个“套内面积(㎡)”的面积均值进行替换
lianjia['套内面积(㎡)'] = lianjia['套内面积(㎡)'].fillna(lianjia['套内面积(㎡)'].mean())
其他
lianjia['挂牌价格(万)'].replace('暂无数据', 0, inplace=True) # 暂无数据的挂牌价格不好确定,改成0
lianjia['浏览(次'].replace('暂无数据', 0, inplace=True) # 暂无数据的浏览次数改为 0
重置索引
lianjia = lianjia.reset_index() # 重置索引
lianjia.info() # 再检查一遍数据及其类型
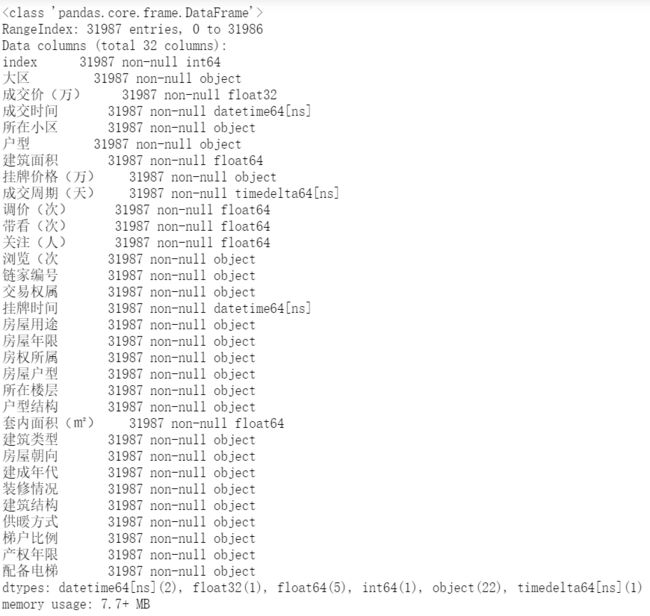
这样一来,主要的供分析使用的数据就已经清洗完毕了,其他的字段可以标记出来,留待有空或者有其他需求的时候再做处理。
分析需求
1.计算每平米二手房均价
在数据清洗干净的情况下,这个需求非常好得出,即:
每平米二手房均价 = 二手房销售价格总和 / 二手房总建筑面积(或套内面积,看需求)
ppsm = lianjia['成交价(万)'].sum() / lianjia['建筑面积'].sum()
display(str(ppsm)+'万')
2.各大区房屋面积总和,降序排序
这个也不难,按大区分组再对建筑面积求和即可
area = lianjia.groupby('大区')['建筑面积'].agg({'建筑面积': 'sum'})
area.sort_values('建筑面积', ascending=False) # ascending=True为升序,False为降序

3.按周分析2019年北京二手房交易趋势
趋势分析首选折线图,以周次为x轴,交易量为y轴。但原数据里没有周记录,我们需要构建一个这样的字段方便我们计算:
lianjia['成交年'] = lianjia['成交时间'].dt.year # 根据成交时间创建年字段
lianjia['成交周'] = lianjia['成交时间'].dt.week # 根据成交时间创建周字段
result = lianjia.groupby(['成交年', '成交周'])['成交时间'].count()
数据长这样

画个简单的图看看效果
result.loc[2019].plot(kind='line')

结论:2019年北京二手房交易量是呈上升趋势的。
但是这些波峰是怎么回事?我们用条形图看看
result.loc[2019].plot(kind='bar')

几乎每隔4周就会有一次突起的交易量。不清楚的可能以为链家每个月都做一次促销活动。而实际上,如果你还记得我们当时是怎么处理“成交时间”这个字段的,你就会明白,这种数据的体现其实是受到了人为的影响:之前我把只有年月的时间都统一更新为月末的最后一天,当被这样处理的数据占一定比例时,在图形上就会集中体现在某一天,造成波峰的效果!所以我也不得不再次强调,如何处理数据,必须与业务部门进行确认,因为这些处理方式对数据的影响很可能是巨大的!
4.2019年北京二手房成交的单位均价走势
这是比较有意义的一个分析。
当前的房价是什么形式?房价会不会继续涨?手里的房子该不该套现?这种分析都可以给到一些参考。
P. S. 该数据为部分销售数据,本人亦不从事房产买卖。如据此投资楼市,盈亏自负:P
依然是折线图,我们要构建一个x轴为周次,y轴为均价的图形
result1 = lianjia.groupby(['成交年', '成交周'])[['成交价(万)', '建筑面积']].agg({'成交价(万)': 'sum', '建筑面积': 'sum'}) # 按年、周分组,求成交价和建筑面积总和
result1['成交均价'] = result1['成交价(万)'] / result1['建筑面积'] # 根据价格和面积创建成交均价字段
result1.loc[2019].head()

result1.loc[2019].plot(result1.loc[2019].index, '成交均价', kind='line')

结论:2019年上半年房价止跌回升,下半年一直横盘。房住不炒真的不是说说而已。
5.按周分析2019年平均挂牌周期
想卖房子了?看看一般多久才能卖出
lianjia['成交天数'] = lianjia['成交周期(天)'].dt.days # 构建整数类型的“成交天数”字段
result2 = lianjia.groupby(['成交年', '成交周'])['成交天数'].mean() # 每周挂牌的房子卖出周期
result2.loc[2019].mean() # 整个2019年每周的平均卖出周期
result2.loc[2019].plot(kind='bar')
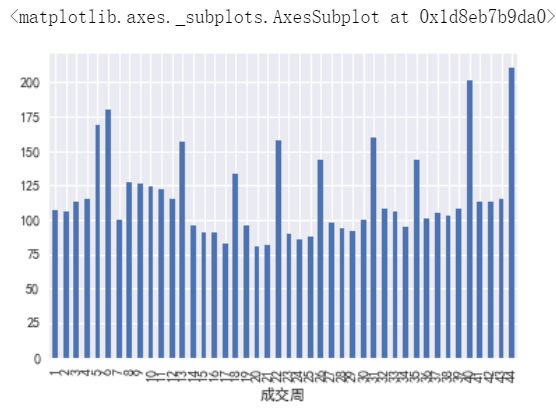
结论:2019年每周的平均卖出周期约为116天,接近4个月;极个别周平均交易周期超过5个月,甚至更高。
综上分析,对于购房者来说,在房住不炒的政策下,房价上涨的趋势得到了抑制,而且这应该也是未来几年国家对房市的基本论调。所以如果购房是刚需,则可以考虑不要再等下去,直接出手了;对于房产中介来说,虽然房价没有继续涨,但房屋交易量仍在上涨,可以针对刚需人群讨论营销策略来进行促成动作。
写在最后
以上便是从数据清洗到分析,再到数据展示的整个过程。值得注意的是,在这个过程中,我们对于一些字段的处理,策略是多样的。具体使用哪一种策略,需要不断去斟酌,使数据为最接近真实的反应。如果拿不定主意,切勿为了一时方便,自作主张地使用某一种策略来强行分析。这时应该再与业务部门再次确认需求,并告知对字段的处理方式可能会对分析造成的影响,经业务部门确认后再做处理!