前言
- 本篇是关于 2022-MIT 6.828 的关于 Raft 的实验记录;
- 如果发现内容上的纰漏,请不要吝啬您的键盘。
Raft 基本概念
Raft 是怎么运行的
Raft 对于 Paxos 来说是个相对简单的共识算法,但再怎么简单“Raft 是怎么运行的”也不是三言两语就能搞定的,而且我本来就没想三言两语搞定。所以在看了 Raft 论文 之后,这里有两个网页可以帮助你理解 Raft 是怎么运行的:
另外还有三张我认为对我自己理解 Raft 很有帮助的图,第一张是实验指导书上的
How the replicated service and Raft communicate,第二三张是 Morris 教授授课的板书截图:



协议对四个指针的约束
Figure 3 中的约束是 Raft 共识算法运行正确的基础,我们将要实现的 Raft 代码库就要是实现这些约束:
lastApplied <= commitIndex <= matchIndex < nextIndex- 其中
matchIndex和nextIndex是 Leader 才有的字段; - 在所有节点中,都有上述
lastApplied和commitIndex的关系; - 在 Leader 中,对与它维护的过半数的 peer 的
commitIndex和matchIndex都有上述关系。 - 在 Leader 中,对与它维护的任一一个 peer 的
matchIndex和nextIndex都有上述关系。
- 其中
- 无论是 Leader 的
lastApplied还是 Follower 的lastApplied它们都是要尽全力地追赶各自的commitIndex,途中需要把经过的 LogEntry 通过 applyCh 返回到上层应用中去。 Leader 的
commitIndex:for index := Log.firstLogIndex() + 1; index <= Log.LastLogIndex(); index++- 跳过所有
Log.at(index).term != currentTerm的日志,因为为了解决 Figure 8 中的 Safty 问题,Leader 只能提交自己任期内的日志。 - 找到一个最大的
index,在matchIndex[]中,使得有最少的多于一半个数的matchIndex都大于等于这个index,最后commitIndex := index。
Follower 的
commitIndex小于等于leaderCommit,因为 Follower 只有在 Leader 提交之后才能跟着提交的嘛。所以当leaderCommit > commitIndex时,commitIndex = min(leaderCommit, index of last new entry)。leaderCommit > commitIndex的原因有很多,可能是由于 Follower 掉线了一阵子或是 Leader 之前的 AppendEntries RPC 丢包有异或是 Follower 单纯运行得慢等各种原因导致 Follower 没及时同步。
而对于 Leader 的 matchIndex 和 nextIndex 之间的约束关系有点复杂,取决于 Log Consistency 的实现方式,即怎么解决 Figure 7 中的 Leader 和 Follower 的 Log Replica 不一致的问题的。论文提到了一个基础版本和一个优化方式,而这个优化版本正是我们要在 Part 2C 中要做的。但在此之前,先通过 TA 提供的 Student Guide 里的提到的一段话来简述 matchIndex 和 nextIndex:
nextIndexis a guess as to what prefix the leader shares with a given follower. It is generally quite optimistic (we share everything), and is moved backwards only on negative responses.matchIndexis used for safety. It is a conservative measurement of what prefix of the log the leader shares with a given follower.- 虽然最终稳定下来会有
matchIndex + 1 == nextIndex的关系,但实际编写代码的时候千万不要直接用nextIndex - 1的值来更新matchIndex,因为当你发送 PRC 的期间nextIndex的值有可能会改变,所以需要用args.prevLogIndex + len(args.entries)的值来更新matchIndex。
- 虽然最终稳定下来会有
Log Replication
基础版是通过一个条目一个条目的迭代式地搜索这个 Follower 的合适的 nextIndex 的值的。优化版则是在基础版的算法上提高了步进,即是通过一个任期一个任期的迭代式地搜索目标值。Raft Paper 里对基础版做了比较详细的描述,但优化版关键就一句带过,并没有很详细地说明这一块的逻辑,但幸好 TA 的 Student Guide 就有提供伪码级的实现。基础版就在 Paper 的 5.3 节,每一句话都要理解,这就直接介绍优化版的迭代搜索算法:
- 在 Leader 中,
prevLogIndex := nextIndex - 1; prevLogTerm := Log.at(prevLogIndex).term,向 Follower 发送 AppendEntries RPC Request; Follower 执行 Consistency Check:
If
prevLogIndex超出了本地日志范围,则令conflictTerm := -1,Leader 将会把nextIndex := conflictIndex + 1:- 当
prevLogIndex > Log.lastLogIndex()时,conflictIndex := Log.lastLogIndex(),将reply.success := false并返回; - 当
prevLogIndex < Log.firstLogIndex()时,conflictIndex := Log.firstLogIndex(),将reply.success := false并返回;
- 当
- Else If
Log.at(prevIndex).term != prevLogTerm,则令conflictTerm := Log.at(prevIndex).term,然后在本地的 Log 中找到index最小的属于conflictTerm的 LogEntry,最后令conflictIndex := index,将reply.success := false并返回。 Else,表示 match 成功,没有任何的 conflict,但先不要着急截断
pervLogIndex之后的日志,因为网络一直是不可靠的,Leader 发送过来的 AppendEntries RPC Request 可能乱序到达,我们要做的就是先检查 Follower 的日志是否已经全部包含发送过来的args.entries:- If 全部包含,不要截断任何日志,将
reply.success := true并返回; - Else,截断
prevLogIndex之后的所有日志,将args.entries追加到本地日志的尾部,最后将reply.success := true并返回。
- If 全部包含,不要截断任何日志,将
Leader 根据 Consistency Check 结果更新 nextIndex 和 matchIndex。
- If
reply.success == true,证明匹配成功,matchIndex := args.prevIndex + len(args.entries),nextIndex := matchIndex + 1; - Else If
reply.conflictTerm == -1,令nextIndex := conflictIndex + 1; Else,Leader 在本地日志中搜索是否存在任期为
conflictTerm的日志:- If 存在,设这些属于
conflictTerm的日志中,拥有的最大的索引为index,则令nextIndex := index + 1; - Else,则令
nextIndex := conflictIndex。
- If 存在,设这些属于
- If
程序测试和调试
测试基本概念
Lab Guidance 上写的对 Error 和 Fault 的定义很清楚:
Fault 是潜伏在代码中的,导致 Error 的原因。typo 或是对协议的理解偏差都可以算作是 Fault。
- Fault 和 Error 都是客观存在的,Error 是某些 Fault 的一次实例化的结果。
Error 是指某一时刻程序的理论正确的状态和程序的实际状态之间的偏差。
Latent Error:隐式地在代码中传播,最终会演化成 Observable Error 或 Masked Error;
- 如在 Raft 中,一个 Log Entry 被错误地追加到了本地日志中。
Observable Error:显现在程序的输出上的不一致,如输出错误信息、与预期不符的输出结果等;
- 上面错误的 Log Entry 又被错误地提交了,导致测试报错;
Masked Error:由于某种原因,如实现特性或设计,使得先前的 Latent Error 可以被忽略。
- 上面错误地 Log Entry 在更进一步的变成 Observable Error 之前,被其它 Log Entry 覆写掉了。
Instrumentation 是指一段可以报告当前程序状态的代码。
- 可以是刻意地检测某个可能的错误,如
assert()语句,Log.Fatalf()语句等; - 也可以是打印当前状态使得我们可以根据这些历史运行信息来判断任何可能的错误,如
printf()语句、Log.printf()语句等。
- 可以是刻意地检测某个可能的错误,如
你可能已经注意到了上一个部分介绍的 Consistency Check 算法不能区分 Figure 7 中 (c)(d) 中拥有 Extraneous Log 的情况(Latent Error)和正常的既没有 Extraneous Log 和 Miss Log 的的情况(Correct Status),即此时 Leader 发来一个 AppendEntries RPC Request,(c)(d) 没法截断它自身超出去的日志。这是个 masked error,并不影响程序最终执行到正确的状态。
Debug 的方法有两种,一种是 Fault to Error 称为前向调试,另一种则是 Error to Fault 称为反向调试。前者典型的有白盒测试,后者典型的就是黑盒测试。
在 6.824 的所有 Lab 你都会应用反向调试这种方法,因为附带的黑盒测试程序能即时反映出的程序的 Error 信息。我们要做的就是锁定 Fault 的位置,一开始你需要猜测 Fault 的位置,然后根据你的假设去加入一些 Instrumentations 来使 Error 尽可能快地显现出来,从而缩小 Fault 的出现的范围。如果假设经过校验(通过 current first observable error)发现不成立那就换一个假设继续测试。最终这样迭代几轮,通过不断地近似得到 Fault 出现的精确位置(可以精确到某一行代码)。
一个有用的小技巧是,在程序内部的某一次迭代运行过程中,可以通过二分搜索的方式在代码中插入 Instrumentations 来加速 Debug 过程。这个技巧对简单的程序是很管用的,但对一些大而复杂的系统来说,你往往很难去判断一次迭代运行的边界是哪里,而且也很难判断这次运行的 “middle” 在哪儿。
快速地设计和实现你自己的为某个程序调试而配套的优秀的 Instrumentation 是件考验程序员经验和功底的事情。下面是一些设计 Instrumentation 的实践(不好翻译,所以直接放原文了):
How much detail do you need from your instrumentation? Either in general, or just for the current step in your debugging process? How can you make it easier to adjust the level of detail and the main focus of your instrumentation? Can you turn on or off different pieces of debugging without deleting them from your code?
(In particular, consider using an approach like the provided DPrintf function does, and defining one or more constant boolean flags to turn on or off different aspects of your instrumentation.)
How can you optimize your own ability to quickly read and understand what your instrumentation is indicating? Can you use text colors, columns, consistent formats, codewords, or symbols to make it easier to read?
The best approach will be personalized to the particular way that YOU best percieve information, so you should experiment to find out what works well for you.
How can you enhance your own ability to add instrumentation? Can you use existing tools (like the go "log" package) to help? (I recommend turning on the Lmicroseconds flag, if you do.)
Can you build your own helper functions, so that a common set of data (current server, term, and role, perhaps?) will always be displayed?
- You might also consider trying to condense each individual event you report into a single line to facilitate your ability to scan output quickly.
Lab 2 调试的优秀实践
这门课的 TA 给学生提供了他自己在做的 Instrumentation,原文为 Debugging by Pretty Printing。在做实验之前把这些都配好,可以大幅提升你 Debug 的效率。
比起传统的上面介绍的调试手段,GDB 无疑是非常黑科技一样的存在,因为它能时刻显示程序的所有状态,但它还是招架不住 Raft 的特殊性,因为有超时机制。当然你想在每个物理节点上都去跑个 GDB 也不是不行,但一旦物理节点多了起来,用 GDB 调试可能会累死个人。
所以这时只能依靠程序运行打印输出的日志信息来帮助我们排错。但这些产生的日志信息有这三个特点:错综复杂、庞大、信噪比低。因此大量的时间将会被耗费在 Debug 上,由于 Time is money,所以这里的实践目标是让日志信息更加可读,从而缩短 Debug 的时间,具体有以下几点:
日志输出需要遵循一定的格式,使输出结果规整,方便阅读以及后续脚本程序处理;
- Who is printing each line and what topic the message is related to.
- When the message has been printed out (optional, ususally using a timestamp to represent that)
尽量只将必要的事件信息输出到日志中,减少无效信息;
- Confirm the top set, and it's better to have no many types of event related to each topic.
- 如果关联的事件过多就考虑划分成若干个更小的 topic,注意控制粒度。
- topic 和 event 的描述要精确。
通过脚本程序将这些日志信息格式化显示,如筛选、搜索、标色等等
在最后 TA 也提倡同学们自己去搭建自己的 Instrumentation,不要直接拿来主义,这些代码同样是很好的学习范式,源代码以附录的形式贴在了文章的末尾。
实验部分
基本设置
我自己的配置是 Election Timeout 为 400ms,心跳为 50ms。在上个实验(MapReduce)中,我是用一个非常麻烦的类似于中段触发的方式来实现 Election Timeout 倒计时处理的,更重要的是那种实现我没法很好地封装。但这次实验跟上个实验的 LoC 和复杂度就不一样,再用这种实现估计会疯掉……
不过 Student Guidance 里提示用半轮询的方式来实现就简单很多很多了。重置倒计时可以用一个方法去很好地封装里面的处理逻辑,更新未来什么时候将会倒时即可。然后 go ticker() 单开一个线程,通过 sleep() 每隔 5ms 去检查这个字段看看和现在相比是否超时就行了。
此外 Log 的设计也是个比较重要的地方,不好好封装 Log 的逻辑,可能会在 Lab 2D 那部分里四处碰壁,原因是有了 snapshot 之后,Log 的 firstLogIndex 就不一定是 0 了。所以选择用一些方法如 Log.at(), Log.firstLogIndex(), Log.lastLogIndex(), Log.trimTail(), Log.trimPrefix() 来封装这些操作可大大降低复杂度。
最后添加一个辅助方法 newTerm(term int),因为 Figure 2 中对所有 Server 要求,不论是 RPC 的发送端还是接收端,只要发现对方的任期比自己大,就要转换成 Follower,并将任期更新为最新的任期,而这个操作算上一共会用到 6 次(三种 RPC,每个 RPC 都有 Sender 和 Handler),所以很有必要将这个操作封装一下:
func (rf *Raft) newTerm(term int) {
rf.status = Follower
rf.votedFor = -1
rf.currentTerm = term
}所以根据 Figure 2 和 上面介绍的 Raft 的相关约束,我们就可以自然地写出下面的伪代码。需要注意的是所有 RPC sender 对 reply 的处理都必须要在当前 term 处理,因为 term 变掉了就证明自身状态就改变了。而且一些细节我就忽略了,像是 send RPC 新开线程、RPC 字段首字母大写、锁的获取和释放时机等等,因为就一把大锁没什么技巧。另外持久化我也省略了,反正但凡更新需要那些非易失的字段时就持久化一下就 ok 了。
Applier
// Applier go routine
for rf.killed() == false {
if !rf.hasSnap {
rf.hasSnap = true // apply snapshot only once
if rf.snapshot.Snapshot == nil || len(rf.snapshot.Snapshot) < 1 {
continue
}
create and config ApplyMsg
rf.applicant.applyCh <- msg
} else if rf.lastApplied + 1 <= rf.commitIndex {
rf.lastApplied += 1
create and config ApplyMsg
rf.applicant.applyCh <- msg
} else {
rf.applicant.applierCond.Wait()
}
}
RequestVoteRPC
Sender
// RequestVote RPC Sender pseudo code
// start a new election
rf.currentTerm += 1
rf.status = Candidate
rf.votedFor = rf.me
// vote for myself
vote := 1
rf.resetElectionTimeout()
for each peer in rf.peers {
create and config RequestVote RPC Argument and Reply
send RequestVote RPC Request to this peer
if args.term == rf.currentTerm {
if reply.term > rf.currentTerm {
rf.newTerm(reply.term)
} else if reply.voteGranted {
vote += 1
if vote == len(rf.peers)/2 + 1 {
rf.conver2Leader() // initialize nextIndex and matchIndex for each peer
send AppendEntires RPC to each peer
}
}
}
}
Handler
// RequestVote RPC Handler pseudo code
if args.term > rf.currentTerm {
rf.newTerm(args.term)
}
if (args.term == rf.currentTerm) && (rf.votedFor == -1 || rf.votedFor == args.candidateId) && isUp2Date {
rf.cotedFor = args.candidateId
reply.coteGranted = true
reply.term = rf.currentTerm
rf.resetElectionTimeout()
}
reply.Term = rf.CurrentTermAppendEntriesRPC
Sender
// AppendEntries RPC Sender pseudo code
rf.resetElectionTimeout()
for each peer in rf.peers {
if rf.nextIndex[peer] < rf.Log.start() + 1 {
send InstallSnapshot RPC to this peer
} else {
create and config AppendEntries RPC Argument and Reply
send AppendEntries RPC Request to this peer
if args.term == rf.currentTerm {
if reply.term > rf.currentTerm {
rf.newTerm(reply.term)
} else if reply.success {
update nextIndex, matchIndex, commitIndex
singal applier
} else {
update nextIndex
}
}
}
}
Handler
// AppendEntries RPC Handler pseudo code
if args.term > rf.currentTerm {
rf.newTerm(args.term)
}
if args.term == rf.currentTerm {
consistency check
rf.resetElectionTimeout()
}
reply.Term = rf.CurrentTerm
InstallSnapshot
这一部分我想了半天关于怎么把 snapshot 传给上层以及更新 snapshot 是否已经应用过的状态持久化的这两操作绑定在一起原子化。而后来才意识到状态机的状态是易失性的,crash 过后要从头 apply,所以只需保证 snapshot 的持久化就行了。
CondInstallSnapshot() 我就直接返回 True 了,因为我在 InstallSnapshot Handler 和 Applier 中的设计保证了不会有 Stale Snapshot 放到 applyCh 中去。
Snapshot
// Client call Snapshot pseudo code
if index < rf.lastApplied {
return
}
rf.Log.trimPrifix(index)
rf.snapshot.Snapshot = snapshot
rf.snapshot.SnapshotIndex = index
rf.snapshot.SnapshotTerm = rf.Log.at(index).term
rf.hasSnap = false // need to be applied
signal apllier
send InstallSnapshot RPC Request to each peersSender
// InstallSnapshot RPC Sender pseudo code
if rf.status != Leader {
return
}
rf.resetElectionTimeout()
for each peer in rf.peers {
create and config InstallSnapshot RPC Argument and Reply
send InstallSnapshot RPC Request to this peer
if args.term == rf.currentTerm {
if reply.term > rf.currentTerm {
rf.newTerm()
}
}
}
Handler
// InstallSnapshot RPC Handler pseudo code
if args.term > rf.currentTerm {
rf.newTerm(args.term)
}
if args.term == rf.currentTerm {
if args.lastIncludedIndex >= rf.Log.lastIndex() ||
args.lastIncludedTerm != rf.Log.at(args.lastIncludedIndex).Term {
rf.Log = makeLog(args.lastIncludedIndex, args.lastIncludedTerm)
rf.commitIndex = args.lastIncludedIndex
} else {
rf.Log.trimPrefix(args.lastIncludedIndex)
}
rf.lastApplied = args.lastIncludedIndex
rf.snapshot.Snapshot = args.data
rf.snapshot.SnapshotIndex = args.lastIncludedIndex
rf.snapshot.SnapshotTerm = args.lastIncludedTerm
rf.hasSnap = false // need to be applied
signal applier
rf.resetElectionTime()
}
reply.term = rf.currentTerm
后记
Lab 2 的内容真的有点多,做完之后就算通过了所有测试还是有点迷糊的感觉,这次实验做下来之后我觉得什么都可以忘,但有六个是不能忘的:
- Replicated Service 和 Raft 交互图;
- Figure 3 的约束;
- Raft 对怎么通过这四个指针来实现这个约束的;
- Log Replication 中的 Consistency Check 算法;
- Figure 8 解决了什么问题;
- Debug 的技巧。

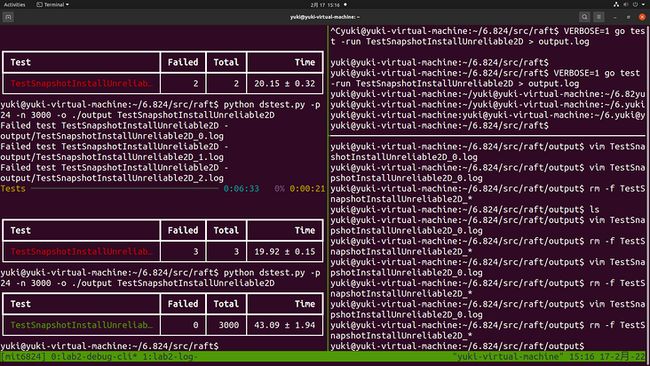
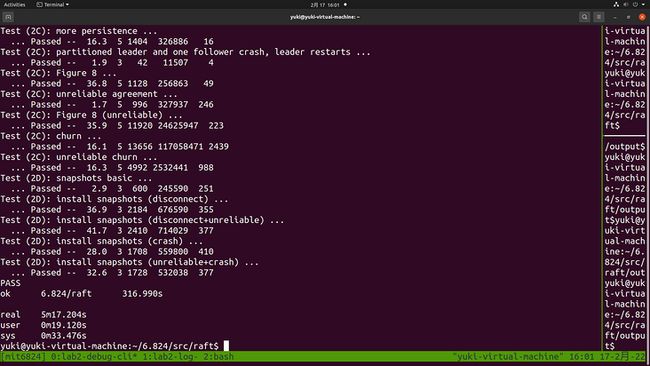
Lab 2 完整的一次测试实际时间为 5 分钟,实际 CPU 时间小于 30 秒,达到了 Lab 2 的要求。调试的时候心态要放平,好好看看测试为什么报错,如果从日志看不出猫腻那一定是你打印的日志信息太少了,多加点就好,剩下的就交给时间吧。
2 月 4 号从开始看 Raft 论文,到现在已经花了近 2 周的时间,感觉调试的能力增加了……
另外在补充上次 MapReduce 文章末尾关于系统开发的另三个步骤,也是目前个人的理解:
- 需求分析:目前市面上同类产品的问题,因此我们的系统应该具备哪些功能,本质上是一系列指标的 trade-off。
- 接口定义:API 接口函数定义
- 架构设计:通常有很强的炫技空间,需要综合考虑运算、存储和通信的方式,需要在这个阶段描述系统的各个对象是怎么运行的,输出一份架构图和相关设计文档。为实现 API 和需求,需要设计全局和每个对象应用的算法和数据结构,并给出合理性。
内心 OS:
我以为是 6.824 是开给本科生的课,结果是给 MIT 的硕士生开的……
怎么这么卷呀,人均水平是不是太高了点,幸存者偏差不适用是吧,有没有搞错???
参考链接
Appendix
Instrumentaion
// ./util.go
package raft
import (
"fmt"
"log"
"os"
"strconv"
"time"
)
// Debugging
const debug = 0
func DPrintf(format string, a ...interface{}) (n int, err error) {
if debug >= 1 {
log.Printf(format, a...)
}
return
}
// Retrieve the verbosity level from an environment variable
func getVerbosity() int {
v := os.Getenv("VERBOSE")
level := 0
if v != "" {
var err error
level, err = strconv.Atoi(v)
if err != nil {
log.Fatalf("Invalid verbosity %v", v)
}
}
return level
}
type logTopic string
const (
dClient logTopic = "CLNT" //
dCommit logTopic = "CMIT"
dDrop logTopic = "DROP" //
dError logTopic = "ERRO"
dInfo logTopic = "INFO"
dLeader logTopic = "LEAD" //
dLog logTopic = "LOG1"
dLog2 logTopic = "LOG2"
dPersist logTopic = "PERS"
dSnap logTopic = "SNAP"
dTerm logTopic = "TERM" //
dTest logTopic = "TEST"
dTimer logTopic = "TIMR" //
dTrace logTopic = "TRCE"
dVote logTopic = "VOTE" //
dWarn logTopic = "WARN"
)
var debugStart time.Time
var debugVerbosity int
func Init() {
debugVerbosity = getVerbosity()
debugStart = time.Now()
log.SetFlags(log.Flags() &^ (log.Ldate | log.Ltime))
}
func Debug(topic logTopic, format string, a ...interface{}) {
if debug >= 1 {
time := time.Since(debugStart).Microseconds()
time /= 100
prefix := fmt.Sprintf("%06d %v ", time, string(topic))
format = prefix + format
log.Printf(format, a...)
}
}
func Status2Str(status int) string {
var res string
switch status {
case Follower:
res = "Follower"
case Candidate:
res = "Candidate"
case Leader:
res = "Leader"
default:
res = "None"
}
return res
}
Pretty Print Python 脚本程序
# ./dslogs.py
#!/usr/bin/env python
import sys
import shutil
from typing import Optional, List, Tuple, Dict
import typer
from rich import print
from rich.columns import Columns
from rich.console import Console
from rich.traceback import install
# fmt: off
# Mapping from topics to colors
TOPICS = {
"TIMR": "#9a9a99",
"VOTE": "#67a0b2",
"LEAD": "#d0b343",
"TERM": "#70c43f",
"LOG1": "#4878bc",
"LOG2": "#398280",
"CMIT": "#98719f",
"PERS": "#d08341",
"SNAP": "#FD971F",
"DROP": "#ff615c",
"CLNT": "#00813c",
"TEST": "#fe2c79",
"INFO": "#ffffff",
"WARN": "#d08341",
"ERRO": "#fe2626",
"TRCE": "#fe2626",
}
# fmt: on
def list_topics(value: Optional[str]):
if value is None:
return value
topics = value.split(",")
for topic in topics:
if topic not in TOPICS:
raise typer.BadParameter(f"topic {topic} not recognized")
return topics
def main(
file: typer.FileText = typer.Argument(None, help="File to read, stdin otherwise"),
colorize: bool = typer.Option(True, "--no-color"),
n_columns: Optional[int] = typer.Option(None, "--columns", "-c"),
ignore: Optional[str] = typer.Option(None, "--ignore", "-i", callback=list_topics),
just: Optional[str] = typer.Option(None, "--just", "-j", callback=list_topics),
):
topics = list(TOPICS)
# We can take input from a stdin (pipes) or from a file
input_ = file if file else sys.stdin
# Print just some topics or exclude some topics (good for avoiding verbose ones)
if just:
topics = just
if ignore:
topics = [lvl for lvl in topics if lvl not in set(ignore)]
topics = set(topics)
console = Console()
width = console.size.width
panic = False
for line in input_:
try:
time, topic, *msg = line.strip().split(" ")
# To ignore some topics
if topic not in topics:
continue
msg = " ".join(msg)
# Debug calls from the test suite aren't associated with
# any particular peer. Otherwise we can treat second column
# as peer id
if topic != "TEST":
i = int(msg[1])
# Colorize output by using rich syntax when needed
if colorize and topic in TOPICS:
color = TOPICS[topic]
msg = f"[{color}]{msg}[/{color}]"
# Single column printing. Always the case for debug stmts in tests
if n_columns is None or topic == "TEST":
print(time, msg)
# Multi column printing, timing is dropped to maximize horizontal
# space. Heavylifting is done through rich.column.Columns object
else:
cols = ["" for _ in range(n_columns)]
msg = "" + msg
cols[i] = msg
col_width = int(width / n_columns)
cols = Columns(cols, width=col_width - 1, equal=True, expand=True)
print(cols)
except:
# Code from tests or panics does not follow format
# so we print it as is
if line.startswith("panic"):
panic = True
# Output from tests is usually important so add a
# horizontal line with hashes to make it more obvious
if not panic:
print("#" * console.width)
print(line, end="")
if __name__ == "__main__":
typer.run(main)
Concurrent Test 脚本
Python 版本
选项 --help 输出提示信息
# ./dstest.py
#!/usr/bin/env python
import itertools
import math
import signal
import subprocess
import tempfile
import shutil
import time
import os
import sys
import datetime
from collections import defaultdict
from concurrent.futures import ThreadPoolExecutor, wait, FIRST_COMPLETED
from dataclasses import dataclass
from pathlib import Path
from typing import List, Optional, Dict, DefaultDict, Tuple
import typer
import rich
from rich import print
from rich.table import Table
from rich.progress import (
Progress,
TimeElapsedColumn,
TimeRemainingColumn,
TextColumn,
BarColumn,
SpinnerColumn,
)
from rich.live import Live
from rich.panel import Panel
from rich.traceback import install
install(show_locals=True)
@dataclass
class StatsMeter:
"""
Auxiliary classs to keep track of online stats including: count, mean, variance
Uses Welford's algorithm to compute sample mean and sample variance incrementally.
https://en.wikipedia.org/wiki/Algorithms_for_calculating_variance#On-line_algorithm
"""
n: int = 0
mean: float = 0.0
S: float = 0.0
def add(self, datum):
self.n += 1
delta = datum - self.mean
# Mk = Mk-1+ (xk – Mk-1)/k
self.mean += delta / self.n
# Sk = Sk-1 + (xk – Mk-1)*(xk – Mk).
self.S += delta * (datum - self.mean)
@property
def variance(self):
return self.S / self.n
@property
def std(self):
return math.sqrt(self.variance)
def print_results(results: Dict[str, Dict[str, StatsMeter]], timing=False):
table = Table(show_header=True, header_style="bold")
table.add_column("Test")
table.add_column("Failed", justify="right")
table.add_column("Total", justify="right")
if not timing:
table.add_column("Time", justify="right")
else:
table.add_column("Real Time", justify="right")
table.add_column("User Time", justify="right")
table.add_column("System Time", justify="right")
for test, stats in results.items():
if stats["completed"].n == 0:
continue
color = "green" if stats["failed"].n == 0 else "red"
row = [
f"[{color}]{test}[/{color}]",
str(stats["failed"].n),
str(stats["completed"].n),
]
if not timing:
row.append(f"{stats['time'].mean:.2f} ± {stats['time'].std:.2f}")
else:
row.extend(
[
f"{stats['real_time'].mean:.2f} ± {stats['real_time'].std:.2f}",
f"{stats['user_time'].mean:.2f} ± {stats['user_time'].std:.2f}",
f"{stats['system_time'].mean:.2f} ± {stats['system_time'].std:.2f}",
]
)
table.add_row(*row)
print(table)
def run_test(test: str, race: bool, timing: bool):
test_cmd = ["go", "test", f"-run={test}"]
if race:
test_cmd.append("-race")
if timing:
test_cmd = ["time"] + cmd
f, path = tempfile.mkstemp()
start = time.time()
proc = subprocess.run(test_cmd, stdout=f, stderr=f)
runtime = time.time() - start
os.close(f)
return test, path, proc.returncode, runtime
def last_line(file: str) -> str:
with open(file, "rb") as f:
f.seek(-2, os.SEEK_END)
while f.read(1) != b"\n":
f.seek(-2, os.SEEK_CUR)
line = f.readline().decode()
return line
# fmt: off
def run_tests(
tests: List[str],
sequential: bool = typer.Option(False, '--sequential', '-s', help='Run all test of each group in order'),
workers: int = typer.Option(1, '--workers', '-p', help='Number of parallel tasks'),
iterations: int = typer.Option(10, '--iter', '-n', help='Number of iterations to run'),
output: Optional[Path] = typer.Option(None, '--output', '-o', help='Output path to use'),
verbose: int = typer.Option(0, '--verbose', '-v', help='Verbosity level', count=True),
archive: bool = typer.Option(False, '--archive', '-a', help='Save all logs intead of only failed ones'),
race: bool = typer.Option(False, '--race/--no-race', '-r/-R', help='Run with race checker'),
loop: bool = typer.Option(False, '--loop', '-l', help='Run continuously'),
growth: int = typer.Option(10, '--growth', '-g', help='Growth ratio of iterations when using --loop'),
timing: bool = typer.Option(False, '--timing', '-t', help='Report timing, only works on macOS'),
# fmt: on
):
if output is None:
timestamp = datetime.datetime.now().strftime("%Y%m%d_%H%M%S")
output = Path(timestamp)
if race:
print("[yellow]Running with the race detector\n[/yellow]")
if verbose > 0:
print(f"[yellow] Verbosity level set to {verbose}[/yellow]")
os.environ['VERBOSE'] = str(verbose)
while True:
total = iterations * len(tests)
completed = 0
results = {test: defaultdict(StatsMeter) for test in tests}
if sequential:
test_instances = itertools.chain.from_iterable(itertools.repeat(test, iterations) for test in tests)
else:
test_instances = itertools.chain.from_iterable(itertools.repeat(tests, iterations))
test_instances = iter(test_instances)
total_progress = Progress(
"[progress.description]{task.description}",
BarColumn(),
TimeRemainingColumn(),
"[progress.percentage]{task.percentage:>3.0f}%",
TimeElapsedColumn(),
)
total_task = total_progress.add_task("[yellow]Tests[/yellow]", total=total)
task_progress = Progress(
"[progress.description]{task.description}",
SpinnerColumn(),
BarColumn(),
"{task.completed}/{task.total}",
)
tasks = {test: task_progress.add_task(test, total=iterations) for test in tests}
progress_table = Table.grid()
progress_table.add_row(total_progress)
progress_table.add_row(Panel.fit(task_progress))
with Live(progress_table, transient=True) as live:
def handler(_, frame):
live.stop()
print('\n')
print_results(results)
sys.exit(1)
signal.signal(signal.SIGINT, handler)
with ThreadPoolExecutor(max_workers=workers) as executor:
futures = []
while completed < total:
n = len(futures)
if n < workers:
for test in itertools.islice(test_instances, workers-n):
futures.append(executor.submit(run_test, test, race, timing))
done, not_done = wait(futures, return_when=FIRST_COMPLETED)
for future in done:
test, path, rc, runtime = future.result()
results[test]['completed'].add(1)
results[test]['time'].add(runtime)
task_progress.update(tasks[test], advance=1)
dest = (output / f"{test}_{completed}.log").as_posix()
if rc != 0:
print(f"Failed test {test} - {dest}")
task_progress.update(tasks[test], description=f"[red]{test}[/red]")
results[test]['failed'].add(1)
else:
if results[test]['completed'].n == iterations and results[test]['failed'].n == 0:
task_progress.update(tasks[test], description=f"[green]{test}[/green]")
if rc != 0 or archive:
output.mkdir(exist_ok=True, parents=True)
shutil.copy(path, dest)
if timing:
line = last_line(path)
real, _, user, _, system, _ = line.replace(' '*8, '').split(' ')
results[test]['real_time'].add(float(real))
results[test]['user_time'].add(float(user))
results[test]['system_time'].add(float(system))
os.remove(path)
completed += 1
total_progress.update(total_task, advance=1)
futures = list(not_done)
print_results(results, timing)
if loop:
iterations *= growth
print(f"[yellow]Increasing iterations to {iterations}[/yellow]")
else:
break
if __name__ == "__main__":
typer.run(run_tests)
Shell 版本
# ./go-test-many.sh
# https://gist.github.com/jonhoo/f686cacb4b9fe716d5aa
#!/bin/bash
#
# Script for running `go test` a bunch of times, in parallel, storing the test
# output as you go, and showing a nice status output telling you how you're
# doing.
#
# Normally, you should be able to execute this script with
#
# ./go-test-many.sh
#
# and it should do The Right Thing(tm) by default. However, it does take some
# arguments so that you can tweak it for your testing setup. To understand
# them, we should first go quickly through what exactly this script does.
#
# First, it compiles your Go program (using go test -c) to ensure that all the
# tests are run on the same codebase, and to speed up the testing. Then, it
# runs the tester some number of times. It will run some number of testers in
# parallel, and when that number of running testers has been reached, it will
# wait for the oldest one it spawned to finish before spawning another. The
# output from each test i is stored in test-$i.log and test-$i.err (STDOUT and
# STDERR respectively).
#
# The options you can specify on the command line are:
#
# 1) how many times to run the tester (defaults to 100)
# 2) how many testers to run in parallel (defaults to the number of CPUs)
# 3) which subset of the tests to run (default to all tests)
#
# 3) is simply a regex that is passed to the tester under -test.run; any tests
# matching the regex will be run.
#
# The script is smart enough to clean up after itself if you kill it
# (in-progress tests are killed, their output is discarded, and no failure
# message is printed), and will automatically continue from where it left off
# if you kill it and then start it again.
#
# By now, you know everything that happens below.
# If you still want to read the code, go ahead.
if [ $# -eq 1 ] && [ "$1" = "--help" ]; then
echo "Usage: $0 [RUNS=100] [PARALLELISM=#cpus] [TESTPATTERN='']"
exit 1
fi
# If the tests don't even build, don't bother. Also, this gives us a static
# tester binary for higher performance and higher reproducability.
if ! go test -c -o tester; then
echo -e "\e[1;31mERROR: Build failed\e[0m"
exit 1
fi
# Default to 100 runs unless otherwise specified
runs=100
if [ $# -gt 0 ]; then
runs="$1"
fi
# Default to one tester per CPU unless otherwise specified
parallelism=$(grep -c processor /proc/cpuinfo)
if [ $# -gt 1 ]; then
parallelism="$2"
fi
# Default to no test filtering unless otherwise specified
test=""
if [ $# -gt 2 ]; then
test="$3"
fi
# Figure out where we left off
logs=$(find . -maxdepth 1 -name 'test-*.log' -type f -printf '.' | wc -c)
success=$(grep -E '^PASS$' test-*.log | wc -l)
((failed = logs - success))
# Finish checks the exit status of the tester with the given PID, updates the
# success/failed counters appropriately, and prints a pretty message.
finish() {
if ! wait "$1"; then
if command -v notify-send >/dev/null 2>&1 &&((failed == 0)); then
notify-send -i weather-storm "Tests started failing" \
"$(pwd)\n$(grep FAIL: -- *.log | sed -e 's/.*FAIL: / - /' -e 's/ (.*)//' | sort -u)"
fi
((failed += 1))
else
((success += 1))
fi
if [ "$failed" -eq 0 ]; then
printf "\e[1;32m";
else
printf "\e[1;31m";
fi
printf "Done %03d/%d; %d ok, %d failed\n\e[0m" \
$((success+failed)) \
"$runs" \
"$success" \
"$failed"
}
waits=() # which tester PIDs are we waiting on?
is=() # and which iteration does each one correspond to?
# Cleanup is called when the process is killed.
# It kills any remaining tests and removes their output files before exiting.
cleanup() {
for pid in "${waits[@]}"; do
kill "$pid"
wait "$pid"
rm -rf "test-${is[0]}.err" "test-${is[0]}.log"
is=("${is[@]:1}")
done
exit 0
}
trap cleanup SIGHUP SIGINT SIGTERM
# Run remaining iterations (we may already have run some)
for i in $(seq "$((success+failed+1))" "$runs"); do
# If we have already spawned the max # of testers, wait for one to
# finish. We'll wait for the oldest one beause it's easy.
if [[ ${#waits[@]} -eq "$parallelism" ]]; then
finish "${waits[0]}"
waits=("${waits[@]:1}") # this funky syntax removes the first
is=("${is[@]:1}") # element from the array
fi
# Store this tester's iteration index
# It's important that this happens before appending to waits(),
# otherwise we could get an out-of-bounds in cleanup()
is=("${is[@]}" $i)
# Run the tester, passing -test.run if necessary
if [[ -z "$test" ]]; then
./tester -test.v 2> "test-${i}.err" > "test-${i}.log" &
pid=$!
else
./tester -test.run "$test" -test.v 2> "test-${i}.err" > "test-${i}.log" &
pid=$!
fi
# Remember the tester's PID so we can wait on it later
waits=("${waits[@]}" $pid)
done
# Wait for remaining testers
for pid in "${waits[@]}"; do
finish "$pid"
done
if ((failed>0)); then
exit 1
fi
exit 0