一文读懂最强中文NLP预训练模型ERNIE
基于飞桨开源的持续学习的语义理解框架ERNIE 2.0,及基于此框架的ERNIE 2.0预训练模型,在共计16个中英文任务上超越了BERT和XLNet, 取得了SOTA效果。本文带你进一步深入了解ERNIE的技术细节。
一:ERNIE 简介
1.1 简介
Google 最近提出的 BERT 模型,通过随机屏蔽15%的字或者word,利用 Transformer 的多层 self-attention 双向建模能力,在各项nlp 下游任务中(如 sentence pair classification task,singe sentence classification task,question answering task) 都取得了很好的成绩。但是,BERT 模型主要是聚焦在针对字或者英文word粒度的完形填空学习上面,没有充分利用训练数据当中词法结构,语法结构,以及语义信息去学习建模。比如 “我要买苹果手机”,BERT 模型 将 “我”,“要”, “买”,“苹”, “果”,“手”, “机” 每个字都统一对待,随机mask,丢失了“苹果手机” 是一个很火的名词这一信息,这个是词法信息的缺失。同时 我 + 买 + 名词 是一个非常明显的购物意图的句式,BERT 没有对此类语法结构进行专门的建模,如果预训练的语料中只有“我要买苹果手机”,“我要买华为手机”,哪一天出现了一个新的手机牌子比如栗子手机,而这个手机牌子在预训练的语料当中并不存在,没有基于词法结构以及句法结构的建模,对于这种新出来的词是很难给出一个很好的向量表示的,而ERNIE 通过对训练数据中的词法结构,语法结构,语义信息进行统一建模,极大地增强了通用语义表示能力,在多项任务中均取得了大幅度超越BERT的效果!!
1.2 下载地址(这么好用的模型赶紧下载起来吧!)
ERNIE 的Fine-tuning代码和英文预训练模型已通过飞桨开源
Github 地址:
https://github.com/PaddlePaddle/ERNIE
二:ERNIE 详解
2.1 ERNIE 结构
2.1.1 ERNIE 初探

2.1.1 ERNIE 结构详解

Figure 2:ERNIE 的encoder 结构详解
相比transformer,ERNIE 基本上是 transformer 的encoder 部分,并且encoder 在结构上是全部一样的,但是并不共享权重,具体区别如下:
-
Transformer: 6 encoder layers, 512 hidden units, 8 attention heads
-
ERNIE Base: 12 encoder layers, 768 hidden units, 12 attention heads
-
ERNIE Large: 24 encoder layers,1024 hidden units, 16 attention heads
从输入上来看第一个输入是一个特殊的CLS, CLS 表示分类任务就像 transformer 的一般的encoder, ERINE 将一序列的words 输入到encoder 中。 每层使用self-attention, feed-word network, 然后把结果传入到下一个encoder。
2.1.2 ERNIE encoder 说明
encoder
encoder 由两层构成, 首先流入self-attention layer,self-attention layer 输出流入 feed-forward 神经网络。至于self-attention的结构,我们在这里不再展开,有兴趣的同学可以进入以下链接仔细阅读http://jalammar.github.io/illustrated-transformer/,来进一步了解self-attention的结构!!

Figure 3: encoder 结构详解
embedding
最下层的encoder的输入是embedding的向量, 其他的encoder的输入,便是更下层的encoder的输出, 一般设置输入的vectors 的维度为512,同学们也可以自己设置。

Figure 4: encoder 结构详解
2.2 : ERNIE 1.0 介绍
相比于BERT, ERNIE 1.0 改进了两种 masking 策略,一种是基于phrase (在这里是短语 比如 a series of, written等)的masking策略,另外一种是基于 entity(在这里是人名、位置、组织、产品等名词,比如Apple, J.K. Rowling)的masking 策略。在ERNIE 当中,将由多个字组成的phrase 或者entity 当成一个统一单元,相比于bert 基于字的mask,这个单元当中的所有字在训练的时候,统一被mask。对比直接将知识类的query 映射成向量然后直接加起来,ERNIE 通过统一mask的方式可以潜在地学习到知识的依赖以及更长的语义依赖来让模型更具泛化性。

Figure 5: ERNIE 1.0 不同的mask 策略说明
2.3: ERNIE 2.0 介绍
传统的pre-training 模型主要基于文本中words 和 sentences 之间的共现进行学习。 事实上,训练文本数据中的词法结构、语法结构、语义信息也同样是很重要的。在命名实体识别中人名、机构名、组织名等名词包含概念信息对应了词法结构,句子之间的顺序对应了语法结构,文章中的语义相关性对应了语义信息。为了去发现训练数据中这些有价值的信息,在ERNIE 2.0 中,提出了一个预训练框架,可以在大型数据集合中进行增量训练。

Figure 6: ERNIE 2.0 框架
2.3.1 ERNIE 2.0 结构
ERNIE 2.0 中有一个很重要的概念便是连续学习(Continual Learning),连续学习的目的是在一个模型中顺序训练多个不同的任务,以便在学习下个任务当中可以记住前一个学习任务学习到的结果。通过使用连续学习,可以不断积累新的知识,模型在新任务当中可以用历史任务学习到参数进行初始化,一般来说比直接开始新任务的学习会获得更好的效果。
a: 预训练连续学习
ERNIE 的预训练连续学习分为两步,首先,连续用大量的数据与先验知识连续构建不同的预训练任务。其次,不断的用预训练任务更新ERNIE 模型。
对于第一步,ERNIE 2.0 分别构建了词法级别,语法级别,语义级别的预训练任务。所有的这些任务,都是基于无标注或者弱标注的数据。需要注意的是,在连续训练之前,首先用一个简单的任务来初始化模型,在后面更新模型的时候,用前一个任务训练好的参数来作为下一个任务模型初始化的参数。这样不管什么时候,一个新的任务加进来的时候,都用上一个模型的参数初始化保证了模型不会忘记之前学习到的知识。通过这种方式,在连续学习的过程中,ERNIE 2.0 框架可以不断更新并记住以前学习到的知识可以使得模型在新任务上获得更好的表现。我们在下面的e, f, g 中会具体介绍ERNIE 2.0 构建哪些预训练任务,并且这些预训练任务起了什么作用。
在图7中,介绍了ERNIE2.0连续学习的架构。这个架构包含了一系列共享文本encoding layers 来 encode 上下文信息。这些encoder layers 的参数可以被所有的预训练任务更新。有两种类型的 loss function,一种是sequence level 的loss, 一种是word level的loss。在ERNIE 2.0 预训练中,一个或多个sentence level的loss function可以和多个token level的loss functions 结合来共同更新模型。
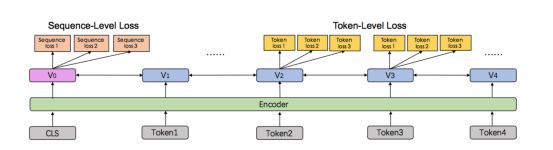
Figure 7: ERINE 2.0 连续学习流程
b: encoder
ERNIE 2.0 用了我们前文提到的transformer 结构encoder,结构基本一致,但是权重并不共享。
c: task embedding.
ERNIE 2.0 用了不同的task id 来标示预训练任务,task id 从1 到N 对应下面的e, f ,g中提到的预训练任务。对应的token segment position 以及task embedding 被用来作为模型的输入。

Figure 8: ERNIE 2.0 连续学习详解
e: 构建词法级别的预训练任务,来获取训练数据中的词法信息
1: knowledge masking task,即 ERNIE 1.0 中的entity mask 以及 phrase entity mask 来获取phrase 以及entity的先验知识,相较于 sub-word masking, 该策略可以更好的捕捉输入样本局部和全局的语义信息。
2: Capitalization Prediction Task,大写的词比如Apple相比于其他词通常在句子当中有特定的含义,所以在ERNIE 2.0 加入一个任务来判断一个词是否大写。
3: Token-Document Relation Prediction Task,类似于tf-idf,预测一个词在文中的A 段落出现,是否会在文中的B 段落出现。如果一个词在文章当中的许多部分出现一般就说明这个词经常被用到或者和这个文章的主题相关。通过识别这个文中关键的的词, 这个任务可以增强模型去获取文章的关键词语的能力。
f: 构建语法级别的预训练任务,来获取训练数据中的语法信息
1: Sentence Reordering Task,在训练当中,将paragraph 随机分成1 到m 段,将所有的组合随机shuffle。我们让pre-trained 的模型来识别所有的这些segments正确的顺序。这便是一个k 分类任务
![]()
通常来说,这些sentence 重排序任务能够让pre-trained 模型学习到document 中不同sentence 的关系。
2: Sentence Distance Task, 构建一个三分类任务来判别句子的距离,0表示两个句子是同一个文章中相邻的句子,1表示两个句子是在同一个文章,但是不相邻,2表示两个句子是不同的文章。通过构建这样一个三分类任务去判断句对 (sentence pairs) 位置关系 (包含邻近句子、文档内非邻近句子、非同文档内句子 3 种类别),更好的建模语义相关性。
g:构建语义级别的预训练任务,来获取训练数据中的语义任务
1: Discourse Relation Task,除了上面的distance task,ERNIE通过判断句对 (sentence pairs) 间的修辞关系 (semantic & rhetorical relation),更好的学习句间语义。
2: IR Relevance Task,在这里主要是利用baidu 的日志来获取这个关系,将query 作为第一个sentence,title 作为第二个 sentence。0 表示强关系, 1 表示弱关系,2表示无关系,通过类似google-distance 的关系来衡量 两个query之间的语义相关性,更好的建模句对相关性。
三: 代码梳理
3.1 : 预训练脚本
-
set -eux
-
export FLAGS_eager_delete_tensor_gb=
0
-
export FLAGS_sync_nccl_allreduce=
1
-
-
export CUDA_VISIBLE_DEVICES=
0,
1,
2,
3,
4,
5,
6,
7
-
-
python ./pretrain_launch.py \
-
-
--nproc_per_node
8 \
-
-
--selected_gpus
0,
1,
2,
3,
4,
5,
6,
7 \
-
-
--node_ips $(hostname -i) \
-
-
--node_id
0 \.
-
-
/train.py --use_cuda True \
-
-
--is_distributed False\
-
-
--use_fast_executor True \
-
-
--weight_sharing True \
-
-
--in_tokens
true \
-
-
--batch_size
8192 \
-
-
--vocab_path ./config/vocab.txt \
-
-
--train_filelist ./data/train_filelist \
-
-
--valid_filelist ./data/valid_filelist \
-
-
--validation_steps
100 \
-
-
--num_train_steps
1000000 \
-
-
--checkpoints ./checkpoints \
-
-
--save_steps
10000 \
-
-
--ernie_config_path ./config/ernie_config.json \
-
-
--learning_rate
1e-4 \
-
-
--use_fp16
false \
-
-
--weight_decay
0.01 \
-
-
--max_seq_len
512 \
-
-
--skip_steps
10
脚本初始化代码 pretrain_launch.py
-
from __future__
import absolute_import
-
-
from __future__
import division
-
-
from __future__
import print_function
-
-
from __future__
import unicode_literals
-
-
from __future__
import absolute_import
-
-
from __future__
import division
-
-
-
-
import sys
-
-
import subprocess
-
-
import os
-
-
import six
-
-
import copy
-
-
import argparse
-
-
import time
-
-
import logging
-
-
-
-
from utils.args
import ArgumentGroup, print_arguments, prepare_logger
-
-
from pretrain_args
import parser
as worker_parser
-
-
-
-
# yapf: disable
-
-
parser = argparse.ArgumentParser(__doc__)
-
-
multip_g = ArgumentGroup(parser,
"multiprocessing",
-
-
"start paddle training using multi-processing mode.")
-
-
multip_g.add_arg(
"node_ips", str, None,
-
-
"paddle trainer ips")
-
-
multip_g.add_arg(
"node_id", int,
0,
-
-
"the trainer id of the node for multi-node distributed training.")
-
-
multip_g.add_arg(
"print_config", bool, True,
-
-
"print the config of multi-processing mode.")
-
-
multip_g.add_arg(
"current_node_ip", str, None,
-
-
"the ip of current node.")
-
-
multip_g.add_arg(
"split_log_path", str,
"./log",
-
-
"log path for each trainer.")
-
-
multip_g.add_arg(
"log_prefix", str,
"",
-
-
"the prefix name of job log.")
-
-
multip_g.add_arg(
"nproc_per_node", int,
8,
-
-
"the number of process to use on each node.")
-
-
multip_g.add_arg(
"selected_gpus", str,
"0,1,2,3,4,5,6,7",
-
-
"the gpus selected to use.")
-
-
multip_g.add_arg(
"training_script", str, None,
"the program/script to be lauched "
-
-
"in parallel followed by all the arguments", positional_arg=True)
-
-
multip_g.add_arg(
"training_script_args", str, None,
-
-
"training script args", positional_arg=True, nargs=argparse.REMAINDER)
-
-
# yapf: enable
-
-
-
-
-
-
log = logging.getLogger()
-
-
-
-
def start_procs(args):
-
-
procs = []
-
-
log_fns = []
-
-
-
-
default_env = os.environ.copy()
-
-
-
-
node_id = args.node_id
-
-
node_ips = [x.strip()
for x
in args.node_ips.split(
',')]
-
-
current_ip = args.current_node_ip
-
-
if args.current_node_ip is None:
-
-
assert len(node_ips) ==
1
-
-
current_ip = node_ips[
0]
-
-
log.info(current_ip)
-
-
-
-
num_nodes = len(node_ips)
-
-
selected_gpus = [x.strip()
for x
in args.selected_gpus.split(
',')]
-
-
selected_gpu_num = len(selected_gpus)
-
-
-
-
all_trainer_endpoints =
""
-
-
for ip
in node_ips:
-
-
for i
in range(args.nproc_per_node):
-
-
if all_trainer_endpoints !=
"":
-
-
all_trainer_endpoints +=
","
-
-
all_trainer_endpoints +=
"%s:617%d" % (ip, i)
-
-
-
-
nranks = num_nodes * args.nproc_per_node
-
-
gpus_per_proc = args.nproc_per_node % selected_gpu_num
-
-
if gpus_per_proc ==
0:
-
-
gpus_per_proc = selected_gpu_num
// args.nproc_per_node
-
-
else:
-
-
gpus_per_proc = selected_gpu_num
// args.nproc_per_node + 1
-
-
-
-
log.info(gpus_per_proc)
-
-
selected_gpus_per_proc = [selected_gpus[i:i + gpus_per_proc]
for i
in range(
0, len(selected_gpus), gpus_per_proc)]
-
-
-
-
if args.print_config:
-
-
log.info(
"all_trainer_endpoints: %s"
-
-
", node_id: %s"
-
-
", current_ip: %s"
-
-
", num_nodes: %s"
-
-
", node_ips: %s"
-
-
", gpus_per_proc: %s"
-
-
", selected_gpus_per_proc: %s"
-
-
", nranks: %s" % (
-
-
all_trainer_endpoints,
-
-
node_id,
-
-
current_ip,
-
-
num_nodes,
-
-
node_ips,
-
-
gpus_per_proc,
-
-
selected_gpus_per_proc,
-
-
nranks))
-
-
-
-
current_env = copy.copy(default_env)
-
-
procs = []
-
-
cmds = []
-
-
log_fns = []
-
-
for i
in range(
0, args.nproc_per_node):
-
-
trainer_id = node_id * args.nproc_per_node + i
-
-
current_env.update({
-
-
"FLAGS_selected_gpus":
"%s" %
",".join([str(s)
for s
in selected_gpus_per_proc[i]]),
-
-
"PADDLE_TRAINER_ID" :
"%d" % trainer_id,
-
-
"PADDLE_CURRENT_ENDPOINT":
"%s:617%d" % (current_ip, i),
-
-
"PADDLE_TRAINERS_NUM":
"%d" % nranks,
-
-
"PADDLE_TRAINER_ENDPOINTS": all_trainer_endpoints,
-
-
"PADDLE_NODES_NUM":
"%d" % num_nodes
-
-
})
-
-
-
-
try:
-
-
idx = args.training_script_args.index(
'--is_distributed')
-
-
args.training_script_args[idx +
1] =
'true'
-
-
except ValueError:
-
-
args.training_script_args += [
'--is_distributed',
'true']
-
-
-
-
cmd = [sys.executable,
"-u",
-
-
args.training_script] + args.training_script_args
-
-
cmds.append(cmd)
-
-
-
-
if args.split_log_path:
-
-
fn = open(
"%s/%sjob.log.%d" % (args.split_log_path, args.log_prefix, trainer_id),
"a")
-
-
log_fns.append(fn)
-
-
process = subprocess.Popen(cmd, env=current_env, stdout=fn, stderr=fn)
-
-
else:
-
-
process = subprocess.Popen(cmd, env=current_env)
-
-
log.info(
'subprocess launched')
-
-
procs.append(process)
-
-
-
-
try:
-
-
for i
in range(len(procs)):
-
-
proc = procs[i]
-
-
proc.wait()
-
-
if len(log_fns) >
0:
-
-
log_fns[i].close()
-
-
if proc.returncode !=
0:
-
-
raise subprocess.CalledProcessError(returncode=procs[i].returncode,
-
-
cmd=cmds[i])
-
-
else:
-
-
log.info(
"proc %d finsh" % i)
-
-
except KeyboardInterrupt
as e:
-
-
for p
in procs:
-
-
log.info(
'killing %s' % p)
-
-
p.terminate()
-
-
-
-
-
-
def main(args):
-
-
if args.print_config:
-
-
print_arguments(args)
-
-
start_procs(args)
-
-
-
-
-
-
if __name__ ==
"__main__":
-
-
prepare_logger(log)
-
-
lanch_args = parser.parse_args()
-
-
pretraining_args = worker_parser.parse_args(
-
-
lanch_args.training_script_args)
-
-
-
-
init_path = pretraining_args.init_checkpoint
-
-
if init_path and not pretraining_args.use_fp16:
-
-
os.system(
'rename .master "" ' + init_path +
'/*.master')
-
-
main(lanch_args)
训练代码 train.py
-
# Copyright (c)
2019 PaddlePaddle Authors. All Rights Reserved.
-
-
#
-
-
# Licensed under the Apache License, Version
2.0 (the
"License");
-
-
# you may not use
this file except
in compliance
with the License.
-
-
# You may obtain a copy
of the License at
-
-
#
-
-
# http:
//www.apache.org/licenses/LICENSE-2.0
-
-
#
-
-
# Unless required by applicable law or agreed to
in writing, software
-
-
# distributed under the License is distributed on an
"AS IS" BASIS,
-
-
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-
-
# See the License
for the specific language governing permissions and
-
-
# limitations under the License.
-
-
""
"ERNIE pretraining."
""
-
-
from __future__
import absolute_import
-
-
from __future__
import division
-
-
from __future__
import print_function
-
-
from __future__
import unicode_literals
-
-
from __future__
import absolute_import
-
-
-
-
import os
-
-
import time
-
-
import multiprocessing
-
-
import logging
-
-
-
-
import numpy
as np
-
-
import paddle.fluid
as fluid
-
-
-
-
from reader.pretraining
import ErnieDataReader
-
-
from model.ernie_v1
import ErnieModel, ErnieConfig
-
-
from optimization
import optimization
-
-
from utils.args
import print_arguments, check_cuda, prepare_logger
-
-
from utils.init
import init_checkpoint, init_pretraining_params
-
-
-
-
from pretrain_args
import parser
-
-
-
-
log = logging.getLogger()
-
-
args = parser.parse_args()
-
-
-
-
# yapf: enable.
-
-
-
-
-
-
def create_model(pyreader_name, ernie_config):
-
-
pyreader = fluid.layers.py_reader(
-
-
capacity=
70,
-
-
shapes=[[
-1, args.max_seq_len,
1], [
-1, args.max_seq_len,
1],
-
-
[
-1, args.max_seq_len,
1], [
-1, args.max_seq_len,
1], [
-1,
1],
-
-
[
-1,
1], [
-1,
1]],
-
-
dtypes=[
-
-
'int64',
'int64',
'int64',
'float32',
'int64',
'int64',
'int64'
-
-
],
-
-
lod_levels=[
0,
0,
0,
0,
0,
0,
0],
-
-
name=pyreader_name,
-
-
use_double_buffer=True)
-
-
-
-
(src_ids, pos_ids, sent_ids, input_mask, mask_label, mask_pos,
-
-
labels) = fluid.layers.read_file(pyreader)
-
-
-
-
ernie = ErnieModel(
-
-
src_ids=src_ids,
-
-
position_ids=pos_ids,
-
-
sentence_ids=sent_ids,
-
-
input_mask=input_mask,
-
-
config=ernie_config,
-
-
weight_sharing=args.weight_sharing,
-
-
use_fp16=args.use_fp16)
-
-
-
-
next_sent_acc, mask_lm_loss, total_loss = ernie.get_pretraining_output(
-
-
mask_label, mask_pos, labels)
-
-
-
-
return pyreader, next_sent_acc, mask_lm_loss, total_loss
-
-
-
-
def predict_wrapper(args,
-
-
exe,
-
-
ernie_config,
-
-
test_prog=None,
-
-
pyreader=None,
-
-
fetch_list=None):
-
-
# Context to
do validation.
-
-
filelist = args.test_filelist
if args.do_test
else args.valid_filelist
-
-
data_reader = ErnieDataReader(
-
-
filelist,
-
-
vocab_path=args.vocab_path,
-
-
batch_size=args.batch_size,
-
-
voc_size=ernie_config[
'vocab_size'],
-
-
shuffle_files=False,
-
-
epoch=
1,
-
-
max_seq_len=args.max_seq_len,
-
-
is_test=True)
-
-
-
-
if args.do_test:
-
-
assert args.init_checkpoint is not None,
"[FATAL] Please use --init_checkpoint '/path/to/checkpoints' \
-
-
to specify you pretrained model checkpoints"
-
-
-
-
init_pretraining_params(exe, args.init_checkpoint, test_prog)
-
-
-
-
def predict(exe=exe, pyreader=pyreader):
-
-
-
-
pyreader.decorate_tensor_provider(data_reader.data_generator())
-
-
pyreader.start()
-
-
-
-
cost =
0
-
-
lm_cost =
0
-
-
acc =
0
-
-
steps =
0
-
-
time_begin = time.time()
-
-
while True:
-
-
try:
-
-
each_next_acc, each_mask_lm_cost, each_total_cost = exe.run(
-
-
fetch_list=fetch_list, program=test_prog)
-
-
acc += each_next_acc
-
-
lm_cost += each_mask_lm_cost
-
-
cost += each_total_cost
-
-
steps +=
1
-
-
if args.do_test and steps % args.skip_steps ==
0:
-
-
log.info(
"[test_set] steps: %d" % steps)
-
-
-
-
except fluid.core.EOFException:
-
-
pyreader.reset()
-
-
break
-
-
-
-
used_time = time.time() - time_begin
-
-
return cost, lm_cost, acc, steps, (args.skip_steps / used_time)
-
-
-
-
return predict
-
-
-
-
-
def test(args):
-
-
ernie_config = ErnieConfig(args.ernie_config_path)
-
-
ernie_config.print_config()
-
-
-
-
test_prog = fluid.Program()
-
-
test_startup = fluid.Program()
-
-
with fluid.program_guard(test_prog, test_startup):
-
-
with fluid.unique_name.guard():
-
-
test_pyreader, next_sent_acc, mask_lm_loss, total_loss = create_model(
-
-
pyreader_name=
'test_reader', ernie_config=ernie_config)
-
-
-
-
test_prog = test_prog.clone(for_test=True)
-
-
-
-
place = fluid.CUDAPlace(
0)
if args.use_cuda == True
else fluid.CPUPlace()
-
-
exe = fluid.Executor(place)
-
-
exe.run(test_startup)
-
-
-
-
predict = predict_wrapper(
-
-
args,
-
-
exe,
-
-
ernie_config,
-
-
test_prog=test_prog,
-
-
pyreader=test_pyreader,
-
-
fetch_list=[next_sent_acc.name, mask_lm_loss.name, total_loss.name])
-
-
-
-
log.info(
"test begin")
-
-
loss, lm_loss, acc, steps, speed = predict()
-
-
log.info(
-
-
"[test_set] loss: %f, global ppl: %f, next_sent_acc: %f, speed: %f steps/s"
-
-
% (np.mean(np.array(loss) / steps),
-
-
np.exp(np.mean(np.array(lm_loss) / steps)),
-
-
np.mean(np.array(acc) / steps), speed))
-
-
-
-
-
def train(args):
-
-
log.info(
"pretraining start")
-
-
ernie_config = ErnieConfig(args.ernie_config_path)
-
-
ernie_config.print_config()
-
-
-
-
train_program = fluid.Program()
-
-
startup_prog = fluid.Program()
-
-
with fluid.program_guard(train_program, startup_prog):
-
-
with fluid.unique_name.guard():
-
-
train_pyreader, next_sent_acc, mask_lm_loss, total_loss = create_model(
-
-
pyreader_name=
'train_reader', ernie_config=ernie_config)
-
-
scheduled_lr, _ = optimization(
-
-
loss=total_loss,
-
-
warmup_steps=args.warmup_steps,
-
-
num_train_steps=args.num_train_steps,
-
-
learning_rate=args.learning_rate,
-
-
train_program=train_program,
-
-
startup_prog=startup_prog,
-
-
weight_decay=args.weight_decay,
-
-
scheduler=args.lr_scheduler,
-
-
use_fp16=args.use_fp16,
-
-
use_dynamic_loss_scaling=args.use_dynamic_loss_scaling,
-
-
init_loss_scaling=args.init_loss_scaling,
-
-
incr_every_n_steps=args.incr_every_n_steps,
-
-
decr_every_n_nan_or_inf=args.decr_every_n_nan_or_inf,
-
-
incr_ratio=args.incr_ratio,
-
-
decr_ratio=args.decr_ratio)
-
-
-
-
-
-
test_prog = fluid.Program()
-
-
with fluid.program_guard(test_prog, startup_prog):
-
-
with fluid.unique_name.guard():
-
-
test_pyreader, next_sent_acc, mask_lm_loss, total_loss = create_model(
-
-
pyreader_name=
'test_reader', ernie_config=ernie_config)
-
-
-
-
test_prog = test_prog.clone(for_test=True)
-
-
-
-
if len(fluid.cuda_places()) ==
0:
-
-
raise RuntimeError(
'not cuda device cound, check ur env setting')
-
-
-
-
if args.use_cuda:
-
-
place = fluid.cuda_places()[
0]
-
-
dev_count = fluid.core.get_cuda_device_count()
-
-
else:
-
-
place = fluid.CPUPlace()
-
-
dev_count = int(os.environ.get(
'CPU_NUM', multiprocessing.cpu_count()))
-
-
-
-
log.info(
"Device count %d" % dev_count)
-
-
log.info(
"theoretical memory usage: ")
-
-
log.info(fluid.contrib.memory_usage(
-
-
program=train_program, batch_size=args.batch_size
// args.max_seq_len))
-
-
-
-
nccl2_num_trainers =
1
-
-
nccl2_trainer_id =
0
-
-
log.info(
"args.is_distributed: %s" % args.is_distributed)
-
-
if args.is_distributed:
-
-
worker_endpoints_env = os.getenv(
"PADDLE_TRAINER_ENDPOINTS")
-
-
worker_endpoints = worker_endpoints_env.split(
",")
-
-
trainers_num = len(worker_endpoints)
-
-
current_endpoint = os.getenv(
"PADDLE_CURRENT_ENDPOINT")
-
-
trainer_id = worker_endpoints.index(current_endpoint)
-
-
if trainer_id ==
0:
-
-
log.info(
"train_id == 0, sleep 60s")
-
-
time.sleep(
60)
-
-
log.info(
"worker_endpoints:{} trainers_num:{} current_endpoint:{} \
-
-
trainer_id:{}".format(worker_endpoints, trainers_num,
-
-
current_endpoint, trainer_id))
-
-
-
-
# prepare nccl2 env.
-
-
config = fluid.DistributeTranspilerConfig()
-
-
config.mode =
"nccl2"
-
-
t = fluid.DistributeTranspiler(config=config)
-
-
t.transpile(
-
-
trainer_id,
-
-
trainers=worker_endpoints_env,
-
-
current_endpoint=current_endpoint,
-
-
program=train_program,
-
-
startup_program=startup_prog)
-
-
nccl2_num_trainers = trainers_num
-
-
nccl2_trainer_id = trainer_id
-
-
-
-
exe = fluid.Executor(place)
-
-
exe.run(startup_prog)
-
-
-
-
if args.init_checkpoint and args.init_checkpoint !=
"":
-
-
init_checkpoint(exe, args.init_checkpoint, train_program, args.use_fp16)
-
-
-
-
data_reader = ErnieDataReader(
-
-
filelist=args.train_filelist,
-
-
batch_size=args.batch_size,
-
-
vocab_path=args.vocab_path,
-
-
voc_size=ernie_config[
'vocab_size'],
-
-
epoch=args.epoch,
-
-
max_seq_len=args.max_seq_len,
-
-
generate_neg_sample=args.generate_neg_sample)
-
-
-
-
exec_strategy = fluid.ExecutionStrategy()
-
-
if args.use_fast_executor:
-
-
exec_strategy.use_experimental_executor = True
-
-
exec_strategy.num_threads = dev_count
-
-
exec_strategy.num_iteration_per_drop_scope = min(
10, args.skip_steps)
-
-
-
-
build_strategy = fluid.BuildStrategy()
-
-
build_strategy.remove_unnecessary_lock = False
-
-
-
-
train_exe = fluid.ParallelExecutor(
-
-
use_cuda=args.use_cuda,
-
-
loss_name=total_loss.name,
-
-
build_strategy=build_strategy,
-
-
exec_strategy=exec_strategy,
-
-
main_program=train_program,
-
-
num_trainers=nccl2_num_trainers,
-
-
trainer_id=nccl2_trainer_id)
-
-
-
-
if args.valid_filelist and args.valid_filelist !=
"":
-
-
predict = predict_wrapper(
-
-
args,
-
-
exe,
-
-
ernie_config,
-
-
test_prog=test_prog,
-
-
pyreader=test_pyreader,
-
-
fetch_list=[
-
-
next_sent_acc.name, mask_lm_loss.name, total_loss.name
-
-
])
-
-
-
-
train_pyreader.decorate_tensor_provider(data_reader.data_generator())
-
-
train_pyreader.start()
-
-
steps =
0
-
-
cost = []
-
-
lm_cost = []
-
-
acc = []
-
-
time_begin = time.time()
-
-
while steps < args.num_train_steps:
-
-
try:
-
-
steps += nccl2_num_trainers
-
-
skip_steps = args.skip_steps * nccl2_num_trainers
-
-
-
-
if nccl2_trainer_id !=
0:
-
-
train_exe.run(fetch_list=[])
-
-
continue
-
-
-
-
if steps % skip_steps !=
0:
-
-
train_exe.run(fetch_list=[])
-
-
else:
-
-
each_next_acc, each_mask_lm_cost, each_total_cost, np_lr = train_exe.run(
-
-
fetch_list=[
-
-
next_sent_acc.name, mask_lm_loss.name, total_loss.name,
-
-
scheduled_lr.name
-
-
])
-
-
acc.extend(each_next_acc)
-
-
lm_cost.extend(each_mask_lm_cost)
-
-
cost.extend(each_total_cost)
-
-
-
-
log.info(
"feed_queue size %d" % train_pyreader.queue.size())
-
-
time_end = time.time()
-
-
used_time = time_end - time_begin
-
-
epoch, current_file_index, total_file, current_file, mask_type = data_reader.get_progress(
-
-
)
-
-
log.info(
"current learning_rate:%f" % np_lr[
0])
-
-
log.info(
-
-
"epoch: %d, progress: %d/%d, step: %d, loss: %f, "
-
-
"ppl: %f, next_sent_acc: %f, speed: %f steps/s, file: %s, mask_type: %s"
-
-
% (epoch, current_file_index, total_file, steps,
-
-
np.mean(np.array(cost)),
-
-
np.mean(np.exp(np.array(lm_cost))),
-
-
np.mean(np.array(acc)), skip_steps / used_time,
-
-
current_file, mask_type))
-
-
cost = []
-
-
lm_cost = []
-
-
acc = []
-
-
time_begin = time.time()
-
-
-
-
if steps % args.save_steps ==
0:
-
-
save_path = os.path.join(args.checkpoints,
"step_" + str(steps))
-
-
fluid.io.save_persistables(exe, save_path, train_program)
-
-
-
-
if args.valid_filelist and steps % args.validation_steps ==
0:
-
-
vali_cost, vali_lm_cost, vali_acc, vali_steps, vali_speed = predict(
-
-
)
-
-
log.info(
"[validation_set] epoch: %d, step: %d, "
-
-
"loss: %f, global ppl: %f, batch-averged ppl: %f, "
-
-
"next_sent_acc: %f, speed: %f steps/s" %
-
-
(epoch, steps, np.mean(np.array(vali_cost) / vali_steps),
-
-
np.exp(np.mean(np.array(vali_lm_cost) / vali_steps)),
-
-
np.mean(np.exp(np.array(vali_lm_cost) / vali_steps)),
-
-
np.mean(np.array(vali_acc) / vali_steps), vali_speed))
-
-
-
-
except fluid.core.EOFException:
-
-
train_pyreader.reset()
-
-
break
-
-
-
-
-
if __name__ ==
'__main__':
-
-
prepare_logger(log)
-
-
print_arguments(args)