C++学习笔记整理
c++ from 2019 10 20
C++学习
书:《 C++ primer 5th ed 》
排列较为混乱,但大体顺序基本正确,初学者可以参考此问安排学习内容。
C++简介
C++ 是一种静态类型的、编译式的、通用的、大小写敏感的、不规则的编程语言,支持过程化编程、面向对象编程和泛型编程。
C:1940 ,面向结构,面向过程,代码太多后,管理很难,未解决软件危机。
C++被认为是一种中级语言,它综合了高级语言和低级语言的特点。它 是由 Bjarne Stroustrup 于 1979 年在新泽西州美利山贝尔实验室开始设计开发的。编译器 操作系统 文字处理程序 大型游戏, 面向对象,进一步扩充和完善了 C 语言,最初命名为带类的C,后来在 1983 年更名为 C++。C++ 是 C 的一个超集,事实上,任何合法的 C 程序都是合法的 C++ 程序。
编译器实现的速度也让人惊喜 从开源的GCC、LLVM到专有的Visual C++和Intel C++。Code blocks DEV C++。集成IDE的编译器。
命令行编译 $ CC .\prog1.cc .\表示该文件在当前目录 查看状态可以键入 $ echo %ERRORLEVEL%
c++衍生JAVA C#模仿JAVA
c++最大的力量在于其不抽象 ,但能脱离C而存在,因为其强大的抽象能力, 4种编程风格 :C风格,基于对象,面向对象,泛型。
PS
-
软件危机(software crisis)
是指落后的软件生产方式无法满足迅速增长的计算机软件需求,从而导致软件开发与维护过程中出现一系列严重问题的现象 -
对象:对象是指一块能存储数据并具有某种类型的内存空间。命名了的的对象叫做变量或者能被程序修改的数据,value指只读的数据
-
开源:开源软件的源代码任何人都可以审查、修改和增强 源代码 (source
code)是程序员可以修改代码来改变一个软件的工作的方式,与之对应的是专有,闭源软件 proprietary or closed
source。 早期的创造者基于开源技术构建了互联网的大部分 such as Liunx操作系统 everyone受益与开源软件。 -
c++最大的力量在于其不抽象 ,但能脱离C而存在,因为其强大的抽象能力, 4种编程风格 C风格 基于对象 面向对象 泛型
-
recommend book: 《Effective C++ concurrency in Action》《Linux多线程服务端编程 》
include
#include 预处理指令
- iostream: input & output stream :有关输入输出的函数
- .h文件还是存在在底层,亦如: 同
- **<>**里的是头文件 header 对于不属于标准库的头文件 用双引号“”来表示
- 类通常被定义在头文件中,而且类所在头文件的名字应该与类一样
- 在cname的头文件中定义的名字从属于命名空间std 在名为.h的头文件中则不然
- 预处理器是运行于编译过程之前的一段程序 预处理变量不属于命名空间std 由预处理器管理 无需加上std::,确保头文件多次包含仍能安全工作的常用技术是预处理器(preprocessor)
C++还会用到一项预处理功能的是头文件保护符header guard。
PS
- C++头文件保护符的使用方法和工作原理
#ifndef A_H
#define A_H
…//头文件内容
#endif
头文件第一次被包含时,因为没有宏定义过“A_H”,因此经过语句
“
#ifndef A_H
#define A_H
”
并得到执行后,“A_H”就被定义了,并且头文件的内容会进入编译,直到遇见“#endif”。而一旦该头文件即将被错误地包含第二次时,与语句“#ifndef A_H”不符,因为第一次你已经定义过“A_H”了,所以“#ifndef A_H”之后的语句不会进入编译了,直到遇见“#endif”。若头文件被包含一次以上,编译时都会报错。C++头文件保护符的目的就是避免这类错误。
Namespace
命名空间可作为附加信息来区分不同库中相同名称的函数、类、变量等。使用了命名空间即定义了上下文。本质上,命名空间就是定义了一个范围。
使用例子
#include << 插入运算符
把右值插入stream中去
cout是打印 cin输入 cerr输出错误信息 clog输出一般信息。 endl是控制符manipulator 表示重起一行,强制前面的缓存显示,确保程序立即输出,效果是结束当前行,并将与设备关联的缓冲区buffer中的内容刷到设备中。 ::作用域运算符 syntax error(语法错误) 编译过程可以分为两个部分:编译和汇编 编译是读取源程序(字符流),对之进行词法和语法的分析,将高级语言指令转换为功能等效的汇编代码,源文件的编译过程包含两个主要阶段: 宏定义指令,如# define Name TokenString,# undef等。 条件编译指令,如# ifdef,# ifndef,# else,# elif,# endif等。 头文件包含指令,如# include “FileName” 或者# include < FileName> 等。 特殊符号,预编译程序可以识别一些特殊的符号。 编译、优化阶段 编译程序所要作得工作就是通过词法分析和语法分析,在确认所有的指令都符合语法规则之后,将其翻译成等价的中间代码表示或汇编代码。 汇编 代码段:该段中所包含的主要是程序的指令。该段一般是可读和可执行的,但一般却不可写。 数据段:主要存放程序中要用到的各种全局变量或静态的数据。一般数据段都是可读,可写,可执行的。 1Byte = 8 Bit 计算机可寻址的最小内存块称为 字节byte 存储的基本单元称为 字word 复合类型 compound type 引用和指针 references and pointers typedef 声明 PS: 本质上是定义一个数据类型的蓝图。这实际上并没有定义任何数据,但它定义了类的名称意味着什么,也就是说,它定义了类的对象包括了什么,以及可以在这个对象上执行哪些操作。 类的对象的公共数据成员可以使用直接成员访问运算符 (.) 来访问 由一个或多个连续的字节组成。在编程中,变量是用于保存数据的命名存储位置。变量允许程序员将数据存储到计算机内存中并使用其中的数据。它们提供对 RAM 的访问“接口”。 在函数或一个代码块内部声明的变量,称为局部变量。它们只能被函数内部或者代码块内部的语句使用。下面的实例使用了局部变量: 全局变量 PS: 算术运算符 : PS: 一个循环内可以嵌套另一个循环。C++ 允许至少 256 个嵌套层次。 判断结构要求程序员指定一个或多个要评估或测试的条件,以及条件为真时要执行的语句(必需的)和条件为假时要执行的语句(可选的)。 C++ 支持数组数据结构,它可以存储一个固定大小的相同类型元素的顺序集合。数组是用来存储一系列数据,但它往往被认为是一系列相同类型的变量。数组中的特定元素可以通过索引访问。所有的数组都是由连续的内存位置组成。最低的地址对应第一个元素,最高的地址对应最后一个元素。 PS : 数组详解分出来单个博文进行记载! 向量容器vector,它可以理解成动态数组,可以在运行阶段设置长度,实现数组快速索引,方便插入删除元素。 也可以这样定义,vector是一个封装了动态大小数组的顺序容器(Sequence Container)。跟任意其它类型容器一样,它能够存放各种类型的对象。可以简单的认为,向量是一个能够存放任意类型的动态数组。 vector 容器提供了更好的安全性和灵活性 各种操作其他文章 指针是一个变量,其值为另一个变量的地址,即,内存位置的直接地址。就像其他变量或常量一样,必须在使用指针存储其他变量地址之前,对其进行声明。 c++ 中 Null = 0; 可以对指针进行四种算术运算:++、–、+、-。 &height[0] 就是取得是数组第一个元素的地址,假设地址为 1000;&height 是直接对数组名进行取地址,这个时候就是取得是 height 整个数组的地址,指向包含 10 个元素的 int 型数组,地址范围为 1000~1036; 指针和数组是密切相关的。事实上,指针和数组在很多情况下是可以互换的。例如,一个指向数组开头的指针,可以通过使用指针的算术运算或数组索引来访问数组。 让数组存储指向 int 或 char 或其他数据类型的指针。 由于 C++ 运算符的优先级中,* 小于 [],所以 ptr 先和 [] 结合成为数组,然后再和 int * 结合形成数组的元素类型是 int * 类型,得到一个叫一个数组的元素是指针,简称指针数组。 char *names[MAX] 这种字符型的指针数组是存储指针的数组,但是在理解字符型指针数组的时候,可以将它理解为一个二维数组,如 const char *names[4] = {“Zara Ali”,“Hina Ali”,“Nuha Ali”,“Sara Ali”,} 可以理解为一个 4 行 8 列的数组,可以用 cout << *(names[i] + j)<< endl 取出数组中的每个元素。 PS:数组指针和指针数组的区别与联系 一个例子: &a 是整个数组的首地址,a是数组首元素的首地址。但是在上面的例子里,只有用&a才是对的,因为C++中要求赋值运算符=左右两边的数据类型应该相同。所以,在上面的例子中 int (*p)[5] 表示的是数组指针,所以应该对应初始化的是整个地址的首地址,而不是首个元素的首地址。 指向指针的指针是一种多级间接寻址的形式,或者说是一个指针链。通常,一个指针包含一个变量的地址。当我们定义一个指向指针的指针时,第一个指针包含了第二个指针的地址,第二个指针指向包含实际值的位置。 C++提供了string类,可以进行很多操作 PS: 6、strlen 的结果要在运行的时候才能计算出来,是用来计算字符串的长度,不是类型占内存的大小。 数学算术操作 随机数 PS: 引用变量是一个别名,也就是说,它是某个已存在变量的另一个名字。一旦把引用初始化为某个变量,就可以使用该引用名称或变量名称来指向变量。 C++ 标准库没有提供所谓的日期类型。C++ 继承了 C 语言用于日期和时间操作的结构和函数。为了使用日期和时间相关的函数和结构,需要在 C++ 程序中引用 头文件。 标准库中的函数time() C 库函数 time_t time(time_t *seconds) 返回自纪元 Epoch(1970-01-01 00:00:00 UTC)起经过的时间,以秒为单位。如果 seconds 不为空,则返回值也存储在变量 seconds 中。 C 库函数 char *ctime(const time_t *timer) 返回一个表示当地时间的字符串,当地时间是基于参数 timer。返回的字符串格式如下: Www Mmm dd hh:mm:ss yyyy 其中,Www 表示星期几,Mmm 是以字母表示的月份,dd 表示一月中的第几天,hh:mm:ss 表示时间,yyyy 表示年份。
控制cout的精度显示,强制以小数的方式显示 cout<错误类型
type error(类型错误)
delaration(声明错误)编译过程
读取c源程序,对其中的伪指令(以# 开头的指令)和特殊符号进行处理。
经过预编译得到的输出文件中,只有常量;如数字、字符串、变量的定义,以及C语言的关键字,如main, if , else , for , while , { , } , + , - , * , \ 等等。
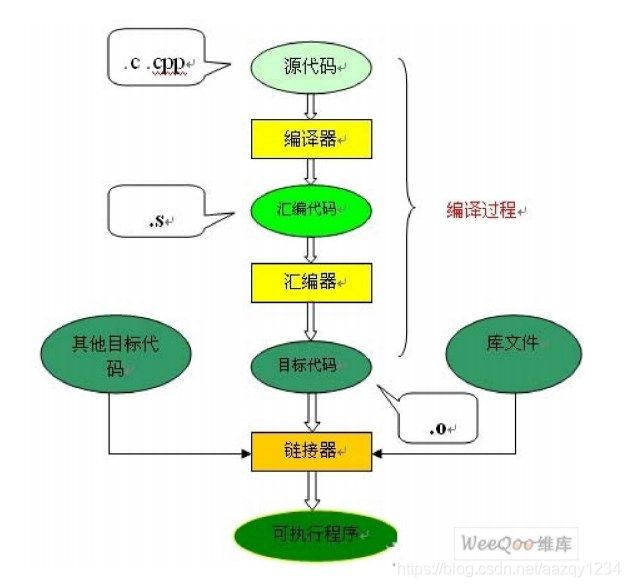
汇编过程实际上指把汇编语言代码翻译成目标机器指令的过程。对于被翻译系统处理的每一个C语言源程序,都将最终经过这一处理而得到相应的目标文件。目标文件中所存放的也就是与源程序等效的目标的机器语言代码。
目标文件由段组成。通常一个目标文件中至少有两个段:
PS:
内存中如何存放数据?
1KB = 1024Byte = 210Byte
1MB = 1024KB = 220Byte
1GB = 1024MB = 230Byte
1TB = 1024GB = 240Byte
1PB = 1024TB = 250Byte
1EB = 1024PB = 260Byte
大多数计算机的字节由8bit组成 字是4或8字节32或者64bit数据类型
bool 布尔类型
char 8位
wchar_t 宽字符 16位
char16_t unicode字符 16位
char32_t unicode字符 32位
short 短整型 16位
int 整型 16位
long int 长整型 32
long long int 长整型 64位
float 单精度浮点数 6位有效数字
double 双精度浮点数 10位有效数字
char, signed char, unsigned char
convert 类型转换enum 枚举名{
标识符[=整型常数],
标识符[=整型常数],
...
标识符[=整型常数]
} 枚举变量;
可以使用 typedef 为一个已有的类型取一个新的名字。typedef int feet;
extern int i; //声明而非定义 int j;//定义 extern int i =1;//定义
变量只能被定义一次,但是可以被多次声明
定义:用于为变量分配存储空间,还可为变量指定初始值。程序中,变量有且仅有一个定义。
声明:用于向程序表明变量的类型和名字。含有extern
定义也是声明:当定义变量时我们声明了它的类型和名字。
函数的声明和定义区别比较简单,带有{ }的就是定义,否则就是声明
嵌套作用域 内层作用域 inner scope 外层作用域 outer scope
atuo类型说明符 必须有初始值
decltype类型说明符 希望从表达式的类型推断出要定义的变量的类型,但是不想用该表达式的值初始化变量 他的作用是选择并返回操作数的数据类型 decltype(f()) sum =x; //sum的类型就是函数 f 的返回类型类
class Box
{
public:
double length; // 盒子的长度
double breadth; // 盒子的宽度
double height; // 盒子的高度
};
Box1.height = 5.0;
Box1.length = 6.0;
Box1.breadth = 7.0;

变量
变量其实只不过是程序可操作的存储区的名称。C++ 中每个变量都有指定的类型,类型决定了变量存储的大小和布局,该范围内的值都可以存储在内存中,运算符可应用于变量上。
变量的名称可以由字母、数字和下划线字符组成。它必须以字母或下划线开头。大写字母和小写字母是不同的,因为 C++ 是大小写敏感的。


变量作用域
#include
在所有函数外部定义的变量(通常是在程序的头部),称为全局变量。全局变量的值在程序的整个生命周期内都是有效的。
全局变量可以被任何函数访问。也就是说,全局变量一旦声明,在整个程序中都是可用的。下面的实例使用了全局变量和局部变量:#include
初始化和赋值时两个完全不同的操作。初始化是指在创建变脸过的时候赋予其一个初始值,而赋值的含义是把当前值擦除,以一个新值来代替。

#include 常量
整数常量可以是十进制、八进制或十六进制的常量。前缀指定基数:0x 或 0X 表示十六进制,0 表示八进制,不带前缀则默认表示十进制。
整数常量也可以带一个后缀,后缀是 U 和 L 的组合,U 表示无符号整数(unsigned),L 表示长整数(long)。后缀可以是大写,也可以是小写,U 和 L 的顺序任意。
浮点常量由整数部分、小数点、小数部分和指数部分组成。您可以使用小数形式或者指数形式来表示浮点常量。
当使用小数形式表示时,必须包含整数部分、小数部分,或同时包含两者。当使用指数形式表示时, 必须包含小数点、指数,或同时包含两者。带符号的指数是用 e 或 E 引入的。
true 值代表真。
false 值代表假。
字符常量是括在单引号中。如果常量以 L(仅当大写时)开头,则表示它是一个宽字符常量(例如 L’x’),此时它必须存储在 wchar_t 类型的变量中。否则,它就是一个窄字符常量(例如 ‘x’),此时它可以存储在 char 类型的简单变量中。
字符常量可以是一个普通的字符(例如 ‘x’)、一个转义序列(例如 ‘\t’),或一个通用的字符(例如 ‘\u02C0’)。
在 C++ 中,有一些特定的字符,当它们前面有反斜杠时,它们就具有特殊的含义,被用来表示如换行符(\n)或制表符(\t)等。\r // 回车
\t // 水平制表符
\v // 垂直制表符
字符串字面值或常量是括在双引号 “” 中的。一个字符串包含类似于字符常量的字符:普通的字符、转义序列和通用的字符。可以使用空格做分隔符,把一个很长的字符串常量进行分行。定义常量
#define identifier value
#define LENGTH 10
#define WIDTH 5
#define NEWLINE '\n'
const type variable = value;
const int LENGTH = 10;
const int WIDTH = 5;
const char NEWLINE = '\n';
运算符
算术运算符
++ – :一元运算符
“+ -* / %” 二元运算符
% 取模运算符 符号和第一个数(分子)相同,取某个数字的个位。 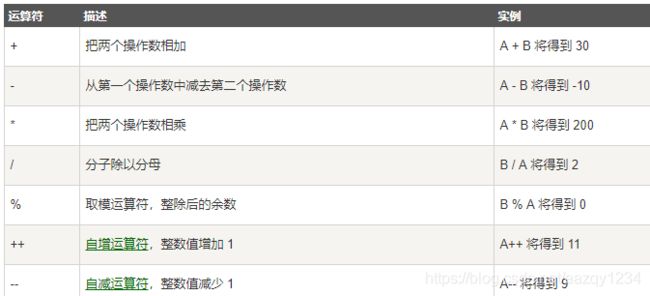
关系运算符

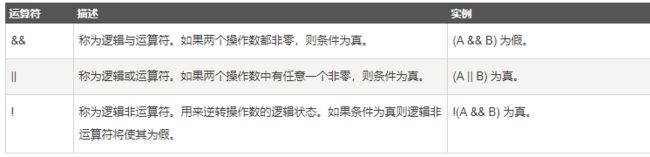
逻辑运算符
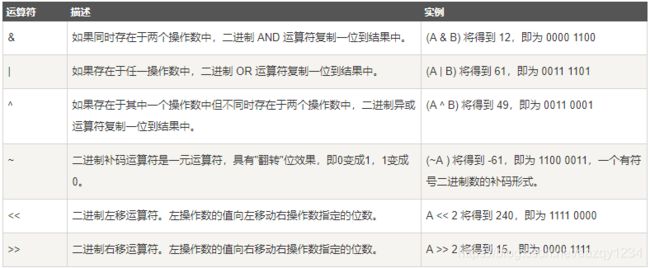
位运算符

赋值运算符
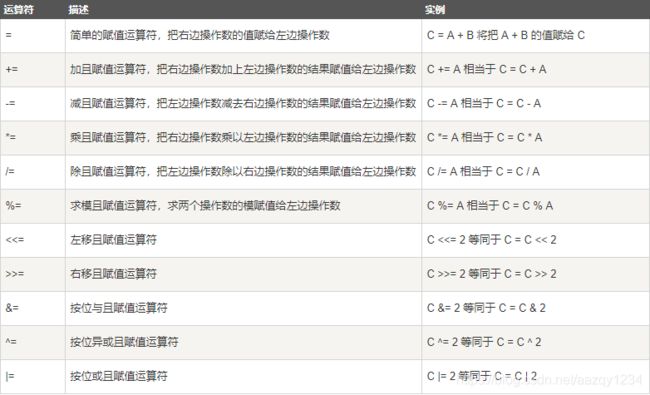
杂项运算符

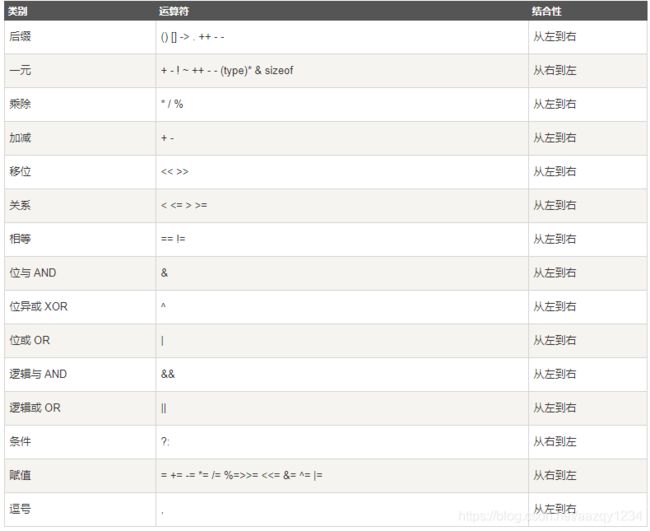
C++ 中的运算符优先级
循环
循环类型
while
while(condition)
{
statement(s);
}
for
for ( init; condition; increment )
{
statement(s);
}
(使用引用reference)int my_array[5] = {1, 2, 3, 4, 5};
// 每个数组元素乘于 2
for (int &x : my_array)
{
x *= 2;
cout << x << endl;
}
// auto 类型也是 C++11 新标准中的,用来自动获取变量的类型
for (auto &x : my_array)
{
x *= 2;
cout << x << endl;
}
do while
do
{
statement(s);
}while( condition );
嵌套循环
循环控制语句
判断
if else
if(boolean_expression)
{
// 如果布尔表达式为真将执行的语句
}
else
{
// 如果布尔表达式为假将执行的语句
}
if(boolean_expression 1)
{
// 当布尔表达式 1 为真时执行
}
else if( boolean_expression 2)
{
// 当布尔表达式 2 为真时执行
}
else if( boolean_expression 3)
{
// 当布尔表达式 3 为真时执行
}
else
{
// 当上面条件都不为真时执行
}
switch
switch(expression){
case constant-expression :
statement(s);
break; // 可选的
case constant-expression :
statement(s);
break; // 可选的
// 您可以有任意数量的 case 语句
default : // 可选的
statement(s);
}
?: 运算符
Exp1 ? Exp2 : Exp3;
数组
#include
int array[];
int main()//此方法非法
{
array[] = {5,10,20,40};// 此时不能用聚合的方法进行赋值,只能在初始化的时候运用聚合的方法
return 0;
}
数组和向量,引用等等动态用法
数组的长度 两个方法
数组的插入和删除 排序 会在数据结构与算法中写出
多位数组
在c++中有sort函数对数组进行排序,需要头文件 algorithm
从小到大:sort(a,a+len); // a是数组名,len是数组长度(元素个数)
从大到小:sort(a,a+len,cmp);数组的替代品:vector
能够感知内存分配器的(Allocator-aware),容器使用一个内存分配器对象来动态地处理它的存储需求。指针
Null指针
void int *P1=nullptr;int P1=0;都是定义空指针
nullptr 给一个初始值0 不给初值是野指针 里面的是无对象的
void 指针存放一个内存地址 存储类型不确定 不可以修改 一般用来和别的指针比较指针的算术运算
可以在程序中使用指针代替数组,因为变量指针可以递增,而数组不能递增,因为数组是一个常量指针。
指针可以用关系运算符进行比较,如 ==、< 和 >。如果 p1 和 p2 指向两个相关的变量,比如同一个数组中的不同元素,则可对 p1 和 p2 进行大小比较。int height[10];//int型的数组
cout << &height << endl;//&用在数组名上
cout << &height[0] << endl;//&用在数组第一个元素上
我们知道 height 等价于 &height[0],height+1 会将地址加 4 个字节;但 &height+1 就是将地址增加 10*4 个字节。指针和数组的对比
例如 把 var[2] 赋值为 500:*(var + 2) = 500;
指针数组
可以用一个指向字符的指针数组来存储一个字符串列表。#include
指针数组:首先它是一个数组,数组的元素都是指针,数组占多少个字节由数组本身决定。它是“储存指针的数组”的简称。
int *p1[10]; 是指针数组
数组指针:首先它是一个指针,它指向一个数组。在32 位系统下永远是占4 个字节,至于它指向的数组占多少字节,不知道。它是“指向数组的指针”的简称。
int (*p2)[10];是数组指针int main()
{
char a[5]={'A','B','C','D'};
char (*p3)[5] = &a;
char (*p4)[5] = a;
return 0;
}
指向指针的指针

指针的指针运用不少,介绍三种较为常见的
代码如下:#include
代码如下:#include
#include字符串
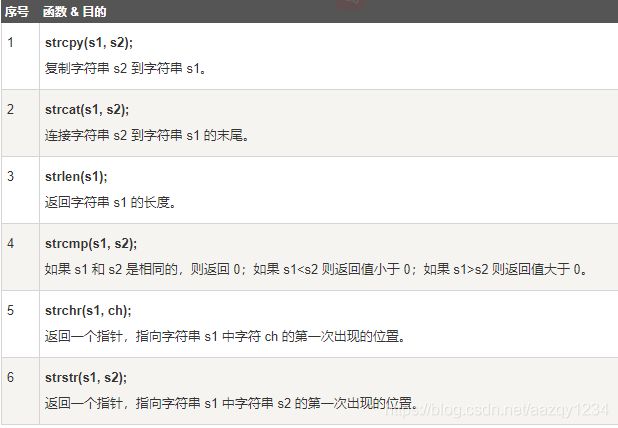
之后写文章进行记录学习
1、sizeof 操作符的结果类型是 size_t,它在头文件中 typedef 为 unsigned int 类型。该类型保证能容纳实现所建立的最大对象的字节大小。
2、sizeof 是运算符,strlen 是函数。
3、sizeof 可以用类型做参数,strlen 只能用 char* 做参数,且必须是以 \0 结尾的。
4、数组做 sizeof 的参数不退化,传递给 strlen 就退化为指针了。
5、大部分编译程序在编译的时候就把 sizeof 计算过了,是类型或是变量的长度,这就是 sizeof(x) 可以用来定义数组维数的原因。char str[20]="0123456789";
int a=strlen(str); // a=10;
int b=sizeof(str); // 而 b=20;
7、sizeof 后如果是类型必须加括弧,如果是变量名可以不加括弧。这是因为 sizeof 是个操作符不是个函数。
8、当适用一个结构类型或变量时, sizeof 返回实际的大小;当适用一静态地空间数组, sizeof 归还全部数组的尺寸;sizeof 操作符不能返回动态地被分派了的数组或外部的数组的尺寸。
9.数组作为参数传给函数时传的是指针而不是数组,传递的是数组的首地址
10.`char* ss = "0123456789";
sizeof(ss);// 结果 4,ss 是指向字符串常量的字符指针,sizeof 获得的是一个指针的之所占的空间,应该是长整型的,所以是 4。
sizeof(*ss)// 结果 1, *ss 是第一个字符 其实就是获得了字符串的第一位 '0' 所占的内存空间,是 char 类型的,占了 1 位
strlen(ss)= 10 // 如果要获得这个字符串的长度,则一定要使用 strlen。strlen 用来求字符串的长度;而 sizeof 是用来求指定变量或者变量类型等所占内存大小。
数字

在许多情况下,需要生成随机数。关于随机数生成器,有两个相关的函数。一个是 rand(),该函数只返回一个伪随机数。生成随机数之前必须先调用 srand() 函数。
srand函数是随机数发生器的初始化函数。它需要提供一个种子,这个种子会对应一个随机数,如果使用相同的种子后面的rand()函数会出现一样的随机数。如: srand(1); 直接使用 1 来初始化种子。不过为了防止随机数每次重复,常常使用系统时间来初始化,即使用 time 函数来获得系统时间,它的返回值为从 00:00:00 GMT, January 1, 1970 到现在所持续的秒数,然后将 time_t 型数据转化为(unsigned)型再传给 srand 函数,即: srand((unsigned) time(&t)); 还有一个经常用法,不需要定义time_t型t变量,即: srand((unsigned) time(NULL)); 直接传入一个空指针,因为你的程序中往往并不需要经过参数获得的t数据。#include
1、rand 随机数产生的范围:在标准的 C 库中函数 rand() 可以生成 0~RAND_MAX 之间的一个随机数,其中 RAND_MAX 是 stdlib.h 中定义的一个整数,它与系统有关,至少为 32767。
2、使用 rand() 和 srand() 产生指定范围内的随机整数的方法:“模除+加法”的方法。如要产生 [m,n] 范围内的随机数 num,可用:int num=rand()%(n-m+1)+m;(即 rand()%[区间内数的个数]+[区间起点值])引用
#include
当函数返回一个引用时,则返回一个指向返回值的隐式指针。这样,函数就可以放在赋值语句的左边。C++时间和日期
有四个与时间相关的类型:clock_t、time_t、size_t 和 tm。类型 clock_t、size_t 和 time_t 能够把系统时间和日期表示为某种整数。
结构类型 tm 把日期和时间以 C 结构的形式保存,tm 结构的定义如下:struct tm {
int tm_sec; // 秒,正常范围从 0 到 59,但允许至 61
int tm_min; // 分,范围从 0 到 59
int tm_hour; // 小时,范围从 0 到 23
int tm_mday; // 一月中的第几天,范围从 1 到 31
int tm_mon; // 月,范围从 0 到 11
int tm_year; // 自 1900 年起的年数
int tm_wday; // 一周中的第几天,范围从 0 到 6,从星期日算起
int tm_yday; // 一年中的第几天,范围从 0 到 365,从 1 月 1 日算起
int tm_isdst; // 夏令时
}
声明:time_t time(time_t *t)
声明:char *ctime(const time_t *timer)#include