只是自己学习时的一些笔记
R语言常用代码整理
commannd+shift+c #批量多行注释的快捷键
排序 order()函数
> b<-b[order(b$sub),] #将b数据框按照列名为sub的这一列升序排列,并重新赋值给b
#将数据框data按照性别排列,每种性别下再按照年龄升序排列。
> data1<-data[order(data$性别,data$年龄),]
> data2<-data[order(data$性别),] # 按照性别升序排列
> data3<-data[order(data$性别,-data$年龄),] #性别升序,性别内年龄降序排列。
均值
mean(b$number)计算b数据框number这一列的平均值
rowMeans(c)计算每行的平均值
colMeans(c)计算每列的平均值
mean_se计算得到平均值,平均值+标准误,平均值-标准误
high_ingroup<-mean_se(b[b$power==1 & b$group==1,"number"])
读取b中 power一列等于1,并且 group一列等于1,所在的行,对应的number一列的数据。
b1<-b[b$power==1 & b$group==1,"number"]
读取b中 power一列等于1,并且 group一列等于2,所在的行,对应的number一列的数据。
b2<-b[b$power==1 & b$group==2,"number"]
计算b2的每一个唯一值对应的 b1数据的平均值。
比如b2的唯一值总共有4个(0,1,2,3)。看以下b1都有哪些行 b2等于0,计算这些行b1的平均值。b2等于1,2,3同上。
c<-tapply(b1,b2,mean)
用apply()函数求平均值
> x<-matrix(data=c(1,2,3,4,5,6,7,8,9,10,11,12),nrow=3)
> x
[,1] [,2] [,3] [,4]
[1,] 1 4 7 10
[2,] 2 5 8 11
[3,] 3 6 9 12
> apply(x,1,mean) #求每行的平均值
[1] 5.5 6.5 7.5
> apply(x,2,mean) #求每列的平均值
[1] 2 5 8 11
rbind 将矩阵 纵向 合并在一起。
也就是,high_ingroup和high_outgroup等都有相同的列,按照 纵向的方式拼接在一起。
rbind(high_ingroup,high_outgroup,high_unclass,low_ingroup,low_outgroup,low_unclass)
与rbind对应的是 cbind,将矩阵横向合并在一起
library(dplyr) # 载入包dplyr,方便下一步用 此包里的rename函数给数据框的列重新命名
将y重命名为mean_number;将ymin重命名为min_number;将ymax重命名为max_number
df1<-rename(df1, mean_number=y, min_number=ymin,max_number=ymax)
还可以用names()函数来重命名。不需要额外载入包。
> names(data)
[1] "condition" "power" "membership" "序号" "实验编号"
[6] "性别" "年龄" "职业" "权力主观评定" "情景想象程度"
[11] "惩罚Q1_情景1" "惩罚Q2_情景1" "惩量Q3_情景1" "惩罚Q4_情景1" "惩罚Q5_情景1"
[16] "惩罚Q6_情景1" "惩罚平均得分_情景1" "惩罚平均得分2_情景1" "惩罚平均得分3_情景1" "惩罚Q1_情景2"
[21] "惩罚Q2_情景2" "惩量Q3_情景2" "惩罚Q4_情景2" "惩罚Q5_情景2" "惩罚Q6_情景2"
[26] "惩罚平均得分_情景2" "报复性惩罚Q1" "报复性惩罚Q2" "报复性惩罚" "期待满足性惩罚"
[31] "威慑动机Q1" "威慑动机Q2" "威慑动机Q3" "威慑动机" "剥夺动机"
[36] "改善违规者未来行为" "mean_puni_s1" "cat"
> names(data)[5]<-"subID" # 将实验编号 重命名为 subID
> mydata<-data.frame(a=matrix(data=c(1,2,3,4,5,6,7,8,9,0),nrow=5,ncol=2))
> mydata
a.1 a.2
1 1 6
2 2 7
3 3 8
4 4 9
5 5 0
> mydata1<-data.frame(a=matrix(data=c(1,2,3,4,5,6,7,8,9,0,3,2),nrow=4,ncol=3))
> mydata1
a.1 a.2 a.3
1 1 5 9
2 2 6 0
3 3 7 3
4 4 8 2
# 要合并mydata和mydata1,但是两个数据,变量个数不同,所以要给mydata添加一列。
> mydata2<-transform(mydata, a.4=NA)
> mydata2
a.1 a.2 a.4
1 1 6 NA
2 2 7 NA
3 3 8 NA
4 4 9 NA
5 5 0 NA
# 由于添加的变量名称a.4和mydata1里的a.3不同,所以合并时报错
> mydata_new=rbind(mydata1,mydata2)
Error in match.names(clabs, names(xi)) :
names do not match previous names
> names(mydata2)
[1] "a.1" "a.2" "a.4"
# 重命名a.4为a.3
> names(mydata2)[3]<-"a.3"
> names(mydata2)
[1] "a.1" "a.2" "a.3"
# 合并两个数据集
> mydata_new=rbind(mydata1,mydata2)
> mydata_new
a.1 a.2 a.3
1 1 5 9
2 2 6 0
3 3 7 3
4 4 8 2
5 1 6 NA
6 2 7 NA
7 3 8 NA
8 4 9 NA
9 5 0 NA
position=position_jitterdodge() 实现数据并列抖动功能。当数据大都是同一个值时,会重叠在一起,可以用这个功能。
用法:
position_jitterdodge(jitter.width = NULL, jitter.height = 0, dodge.width = 0.75, seed = NA)
用于箱线图或条形图和点图在一起的情形,且有顺序的,必须箱子或条形在前,点图在后,抖动只能用在散点几何对象中,
jitter.width 默认40%, jitter.height 默认0, dodge.width = 0.75 点分布于各组箱子(或条形)75%宽度上,默认点水平抖动错开
也可以考虑使用 position="jitter",等价于position=position_jitter() 这个是扰动,默认抖动50%。
可以自己自定义扰动的参数:
geom_point(position = position_jitter(width = 0.1, height = 0.1))
意思是:增加水平抖动10%,垂直抖动10%,但是抖动是随机的,每次结果都可能不一样。
position=position_jitterdodge()
position="jitterdodge"
纵向横向同时分割
p + facet_grid(drv ~ cyl)
当只想单独指定行分面或列分面时,没有指定分面变量的参数需要用'.'代替
纵向分割
p + facet_grid(drv ~ .)
横向分割
p + facet_grid(. ~ cyl)
数据类型转换
as.numeric(a)将a转化为num类型的数据

a[,-1]去掉数据a第一列的数据
mydata <- transform(mydata, sumx = x1 + x2, meanx = (x1 + x2)/2)将计算mydata中,x1和x2两列的和和平均值,并添加到数据框mydata中。
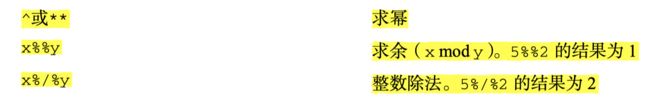

# 将data数据框情景想象程度一列,数值大于6的数据 记为 higher,
# 并新增一列cat,将数据存储在cat一列。
data$cat[data$情景想象程度>6]<-"higher"
View(data)
data$cat[data$情景想象程度<4]<-"higher"
data$cat[data$情景想象程度<4]<-"middle"
data$cat[data$情景想象程度>=4&data$情景想象程度<=6]<-"lower"
#等价于下面的代码
data2<-within(data2,{
+ cat<-NA
+ cat[情景想象程度>6] <-"higher"
+ cat[情景想象程度<4] <-"lower"
+ cat[情景想象程度>=4&情景想象程度<=6] <-"middle"
+ })
View(data2)
rm(data5,data6,data7,a,b,data3) #rm()删除特定变量,如果有多个变量,用逗号分隔
缺失值识别
在R中,缺失值以符号NA(not available)表示。
函数is.na()可以用来检测缺失值是否存在。它会返回一个与数据大小相同的逻辑对象,如果某个元素是缺失值,就返回TURE,否则就返回FALSE。
无限的值(正无穷和负无穷)分别用Inf和-Inf来表示。用is.infinite()来检测。
不可能出现的值用NaN(not a number)来表示。用is.nan()来检测。
要注意NA NaN Inf三者的区别。
> a<-is.na(data[,5:7])
subID 性别 年龄
[1,] TRUE FALSE FALSE
[2,] TRUE FALSE FALSE
[3,] TRUE FALSE FALSE
[4,] TRUE FALSE FALSE
[5,] TRUE FALSE FALSE
[6,] TRUE FALSE FALSE
> str(a)
logi [1:174, 1:3] TRUE TRUE TRUE TRUE TRUE TRUE ...
- attr(*, "dimnames")=List of 2
..$ : NULL
..$ : chr [1:3] "subID" "性别" "年龄"
> dim(a)
[1] 174 3
> class(a)
[1] "matrix" "array"
> mode(a)
[1] "logical"
统计分析时,不考虑缺失值NA。
可以使用na.rm=TRUE不把缺失值纳入统计。
可以使用na.omit()删除所有含缺失值数据的行。
> sum(data$subID) #因为subID一列包含缺失值,所以返回值是NA
[1] NA
> sum(data$subID, na.rm=TRUE)#na.rm=TRUE不把缺失值纳入统计
[1] 5108
> data_new<-na.omit(data) #删除data中含有缺失值NA数据的行。
> data
condition power membership 序号 subID 性别 年龄 职业 权力主观评定 情景想象程度 惩罚Q1_情景1 惩罚Q2_情景1 惩量Q3_情景1
1 11 1 1 1 NA 2 19 1 5 5 7 7 6
2 11 1 1 2 NA 2 18 1 7 7 7 7 7
3 11 1 1 3 NA 2 20 1 7 6 6 6 6
4 11 1 1 4 NA 2 18 1 7 5 6 6 6
5 11 1 1 6 NA 2 18 1 7 7 7 7 7
> data_new
condition power membership 序号 subID 性别 年龄 职业 权力主观评定 情景想象程度 惩罚Q1_情景1 惩罚Q2_情景1 惩量Q3_情景1
34 11 1 1 1 101 2 22 1 7 4 7 7 7
35 11 1 1 2 103 2 22 1 7 5 6 6 6
36 11 1 1 3 107 1 26 1 7 4 6 6 6
37 11 1 1 4 109 2 23 1 6 6 6 6 6
72 12 1 2 1 999 2 26 1 7 7 7 7 7
显示时间和日期
> date() #显示当前的时间和日期
[1] "Thu Feb 25 11:58:27 2021"
> Sys.Date() #显示当前的日期
[1] "2021-02-25"
citation() # 输出R的引用 参考文献
citation(“lme4”) #输出lme4这个包的引用 参考文献
批量更改数据类型为factor
提取特定行/列的数据
leadership[ , c(6:10)] #这里代表leadership的所有行,6到10列的数据。
需要注意的是,在R里面,用留空代表所有行,这个是跟matlab不一样的地方。
另一种方法是:
> a<-c(1:8)
> b<-c(3:10)
> c<-paste("c",1:8,sep="")
> e<-data.frame(a,b,c)
> e
a b c
1 1 3 c1
2 2 4 c2
3 3 5 c3
4 4 6 c4
5 5 7 c5
6 6 8 c6
7 7 9 c7
8 8 10 c8
# 使用subset()函数,提取a列大于3同时b列小于8的行,c列的数据
> f<-subset(e,e$a>3 & e$b<8,select=c)
> f
c
4 c4
5 c5
删除特定列的数据
# %in%含义是:
# 看names(leadership)的元素是否包含在c("q3", "q4”)中,返回逻辑值TRUE 或者 FALSE
myvars <- names(leadership) %in% c("q3", "q4")
newdata <- leadership[!myvars]
# 上述代码的含义是:首先leadership中变量名为q3和q4的列会返回TRUE,
# 下一步,通过!myvars选择除了q3和q4之外的列,赋值给新的变量newdata。
# 这样就间接达到了删除q3和q4列的目的。
# 另一种方法
newdata <- leadership[c(-8,-9)] #前面加负号就代表删除这一列。
# 第三种方法
# 将q3和q4设置为NULL,达到的目的是一样的,就是把q3和q4两列删除
leadership$q3 <- leadership$q4 <- NULL
用sample()函数随机抽取数据
> nrow(e)
[1] 8
# 1:nrow(e)代表1到8,3代表从1到8中随机抽取3个数,replace=FALSE代表无放回的抽取
# e[sample(1:nrow(e),3,replace=FALSE), ]代表选取 e中,生成的行里面所有列的数据。
> e[sample(1:nrow(e),3,replace=FALSE), ]
a b c
6 6 8 c6
7 7 9 c7
8 8 10 c8
> e[sample(1:nrow(e),3,replace=FALSE), ]
a b c
6 6 8 c6
1 1 3 c1
8 8 10 c8
> e[sample(1:nrow(e),3,replace=FALSE), ]
a b c
7 7 9 c7
4 4 6 c4
2 2 4 c2
R中常用的数值和字符处理函数


当这些函数被应用于数值向量,矩阵或者数据框时,他们会作用于每一个独立的值。例如:下面的例子,是对向量中的每一个数值都求平方。
> a<-c(3.5,2.5,1.5,0.5,1.5,2.5,3.5)^2
> a
[1] 12.25 6.25 2.25 0.25 2.25 6.25 12.25

用scale()函数进行数据的标准化

> mydata<-read.csv(file.choose()) #手动选取文件读入数据
> str(mydata) #查看数据结构
'data.frame': 84 obs. of 5 variables:
$ subject : chr "F1" "F1" "F1" "F1" ...
$ gender : chr "F" "F" "F" "F" ...
$ scenario : int 1 1 2 2 3 3 4 4 5 5 ...
$ attitude : chr "pol" "inf" "pol" "inf" ...
$ frequency: num 213 204 285 260 204 ...
> head(mydata) #查看数据前6列
subject gender scenario attitude frequency
1 F1 F 1 pol 213.3
2 F1 F 1 inf 204.5
3 F1 F 2 pol 285.1
4 F1 F 2 inf 259.7
5 F1 F 3 pol 203.9
6 F1 F 3 inf 286.9
# 提取scenario和frequency两列的的数据,赋值给mydata1
> mydata1<-mydata[,names(mydata) %in% c("scenario","frequency")]
> head(mydata1) #查看mydata1的前6列
scenario frequency
1 1 213.3
2 1 204.5
3 2 285.1
4 2 259.7
5 3 203.9
6 3 286.9
> mydata2<-scale(mydata1) #对mydata1的所有列分别进行标准化,使其成为平均数为0,标准差为1的数据。
> head(mydata2)
scenario frequency
[1,] -1.4910447 0.3008524
[2,] -1.4910447 0.1665847
[3,] -0.9940298 1.3963552
[4,] -0.9940298 1.0088097
[5,] -0.4970149 0.1574300
[6,] -0.4970149 1.4238191
> mean1<-mean(mydata1$scenario) #计算scenario一列的平均值
> s1<-sd(mydata1$scenario) #计算scenario一列的标准差
> mean1
[1] 4
> s1
[1] 2.012012
# 手动标准化
> standard_scenario<-(mydata1$scenario-mean1)/s1
> standard_scenario
[1] -1.4910447 -1.4910447 -0.9940298 -0.9940298 -0.4970149 -0.4970149 0.0000000 0.0000000 0.4970149 0.4970149
[11] 0.9940298 0.9940298 1.4910447 1.4910447 -1.4910447 -1.4910447 -0.9940298 -0.9940298 -0.4970149 -0.4970149
[21] 0.0000000 0.0000000 0.4970149 0.4970149 0.9940298 0.9940298 1.4910447 1.4910447 -1.4910447 -1.4910447
[31] -0.9940298 -0.9940298 -0.4970149 -0.4970149 0.0000000 0.0000000 0.4970149 0.4970149 0.9940298 0.9940298
[41] 1.4910447 1.4910447 -1.4910447 -1.4910447 -0.9940298 -0.9940298 -0.4970149 -0.4970149 0.0000000 0.0000000
[51] 0.4970149 0.4970149 0.9940298 0.9940298 1.4910447 1.4910447 -1.4910447 -1.4910447 -0.9940298 -0.9940298
[61] -0.4970149 -0.4970149 0.0000000 0.0000000 0.4970149 0.4970149 0.9940298 0.9940298 1.4910447 1.4910447
[71] -1.4910447 -1.4910447 -0.9940298 -0.9940298 -0.4970149 -0.4970149 0.0000000 0.0000000 0.4970149 0.4970149
[81] 0.9940298 0.9940298 1.4910447 1.4910447
> mydata2<-cbind(mydata2,standard_scenario) #将手动标准化的结果与mydata2合并
> head(mydata2) #查看结果,发现,scenario和standard_scenario相等。
scenario frequency standard_scenario
[1,] -1.4910447 0.3008524 -1.4910447
[2,] -1.4910447 0.1665847 -1.4910447
[3,] -0.9940298 1.3963552 -0.9940298
[4,] -0.9940298 1.0088097 -0.9940298
[5,] -0.4970149 0.1574300 -0.4970149
[6,] -0.4970149 1.4238191 -0.4970149
# 对特定列scenario进行标准差为5,平均值为20的标准化,标准化后的结果赋值给变量standard_scenario2,并加入到mydata中生成新的一列,最后赋值给mydata3
> mydata3<-transform(mydata,standard_scenario2=scale(scenario)*5+20)
> head(mydata3)
subject gender scenario attitude frequency standard_scenario2
1 F1 F 1 pol 213.3 12.54478
2 F1 F 1 inf 204.5 12.54478
3 F1 F 2 pol 285.1 15.02985
4 F1 F 2 inf 259.7 15.02985
5 F1 F 3 pol 203.9 17.51493
6 F1 F 3 inf 286.9 17.51493
> mean(mydata3$standard_scenario2) #计算平均值,发现确实是20
[1] 20
> sd(mydata3$standard_scenario2)#计算标准差,发现确实是5
[1] 5
概率函数
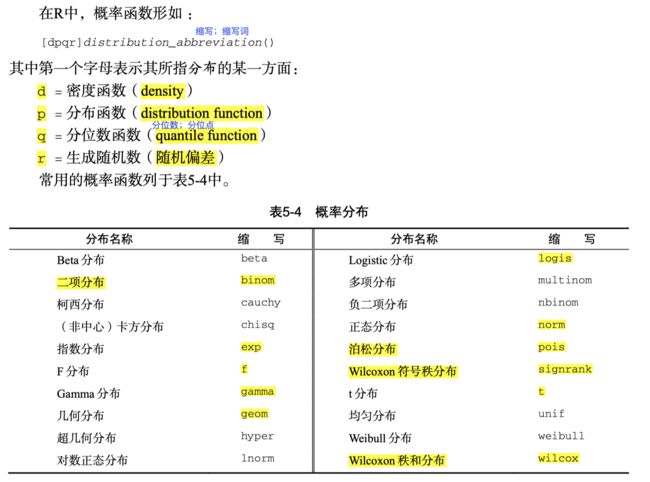
set.sed()指定种子,可以让结果重现。set.seed()括号里面的参数可以是任意数字,是代表你设置的第几号种子而已,不会参与运算,是个标记而已。
#将ToothGrowth_new数据框中的supp列,等于OJ的数据替换为WJ
#因为supp是factor,所以要先变成character 不然会报错
> ToothGrowth_new$supp<-as.character(ToothGrowth_new$supp)
> ToothGrowth_new$supp[which(ToothGrowth_new$supp=="OJ")] <-"WJ"
#通过aggregate函数,计算ToothGrowth$supp这一列,不同因子水平上 len这一列的平均值。
> aggregate(ToothGrowth$len,by=list(ToothGrowth$supp),FUN=mean)
Group.1 x
1 OJ 20.663
2 VC 16.963
#通过str()函数 或者as.numeric()函数可以查看 不同标签对应的数字是多少
as.numeric(ToothGrowth$supp,lable=c("OJ","VC"))
百分号的写法
> a<-percent(c(0,1))
> a
[1] "0%" "100%"
> str(a)
chr [1:2] "0%" "100%"
查看转义字符的使用方法
?Quotes
用sapply()函数提取列表的某一行的某一列
# "[" 是一个可以提取某个对象的一部分的函数。在这里是用来提取列表y个成分中的第一个和第二个元素的。
> sapply(y,"[",2) #提取y中的每一行的第二列的数据
[1] "Davis" "Williams" "Moose" "Jones"
[5] "Markhammer" "Cushing" "Ytzrhak" "Knox"
[9] "England" "Rayburn"
> sapply(y,"[",1) #提取y中的每一行的第一列的数据
[1] "John" "Angela" "Bullwinkle" "David"
[5] "Janice" "Cheryl" "Reuven" "Greg"
[9] "Joel" "Mary"
使用strsplit()函数将元素拆分 应用到字符串组成的向量上会返回一个列表
# 这里是用空格符号将Student数据里的 姓氏和姓名分开
> y <- strsplit(roster$Student, " ")
> y
[[1]]
[1] "John" "Davis"
[[2]]
[1] "Angela" "Williams"
[[3]]
[1] "Bullwinkle" "Moose"
[[4]]
[1] "David" "Jones"
[[5]]
[1] "Janice" "Markhammer"
[[6]]
[1] "Cheryl" "Cushing"
[[7]]
[1] "Reuven" "Ytzrhak"
[[8]]
[1] "Greg" "Knox"
[[9]]
[1] "Joel" "England"
[[10]]
[1] "Mary" "Rayburn"
quantile()函数计算百分位
# 这里是计算score 的0.8 0.6 0.4和0.2百分位。
> y <- quantile(roster$score, c(.8,.6,.4,.2))
> y
80% 60% 40% 20%
0.74 0.44 -0.36 -0.89
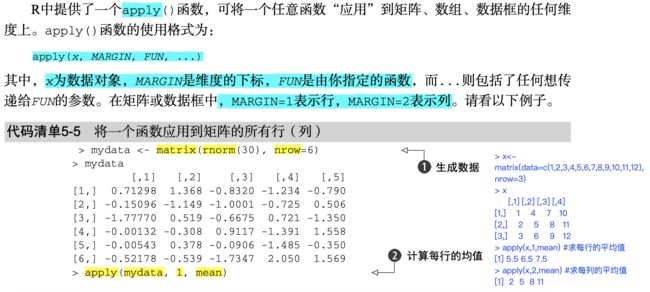
apply() lapply() sapply()
apply() 可以把函数应用到数组的某个维度上;
lapply() sapply()可以把函数应用到列表上。

cut()可以把连续变量x分割为有着n个水平的因子
> age1<-cut(bc$age,breaks = 3,labels = c(1,2,3))#平均分为3个区间,命名为1,2,3
> age2<-cut(bc$age,breaks=c(0,20,60,100),include.lowest=T,
labels = c(1,2,3))
#把age划分为0-20,20-60,60到100这样3个区间
> dd<-cbind(bc,age2) #把变量加入表格
> x<-cut(c(1,2,3,4,5,6,7,8,9), 3,labels=c(1,2,3))
> x
[1] 1 1 1 2 2 2 3 3 3
Levels: 1 2 3
循环 和 条件执行
for循环
for循环 重复执行一个语句,直到某个变量的值不再包含在序列seq中为止。
for (var in seq) statement
for (i in 1:10)
{
print("Hello")
}
while循环
while循环重复地执行一个语句,直到条件不为真为止。
while (cond) statement
i <- 10
while (i > 0)
{
print("Hello");
i <- i - 1
}
if-else
if (cond) statement if 在某个给定条件为真时执行语句。
if (cond) statement1 else statement2 if-else 在某个给定条件为真时执行语句,为假时执行另外的语句。
if (is.character(grade))
grade <- as.factor(grade)
if (!is.factor(grade))
grade <- as.factor(grade)
else
print("Grade already is a factor")
ifelse
ifelse(cond, statement1, statement2)
若cond为TRUE,则执行第一个语句statement1;若cond为FALSE,则执行第二个语句statement2。
ifelse(score > 0.5, print("Passed"), print("Failed"))
outcome <- ifelse (score > 0.5, "Passed", "Failed")
switch
switch(expr, ...) switch根据一个表达式的值选择语句执行。
feelings <- c("sad", "afraid")
for (i in feelings)
print(
switch(i,
happy = "I am glad you are happy",
afraid = "There is nothing to fear",
sad = “cheer up”,
angry = "Calm down now" )
# 含义是,i等于sad时,print(也就是输出)cheer up
# i等于afraid时,print(也就是输出)There is nothing to fear
)
用户自编函数

转置 t()
函数t()对一个矩阵或者数据框进行转置