1. 购物篮分析
购物篮分析(Market Basket Analysis)是数据挖掘十大经典算法之一关联规则挖掘的应用场景,目的是从大规模订单数据集中寻找商品之间的关联, 线下零售商可藉由此分析改变货架上的商品排列或是设计吸引客户的组合促销套餐等,线上电商则当然就是做商品推荐啦, 最著名的案例是沃尔玛那个啤酒和尿片的传说,虽然我极度怀疑其真实性。

要从订单中找到啤酒和尿片这样强相关的商品似乎超级简单,不就是一个哈希表吗,key是商品集,value是同时出现的次数, 对交易订单逐行遍历更新这个哈希表就是了,但这样会有两个问题:
- 订单中商品可能会很多,订单的条数也可能几百万,按结对组合来统计的话计算量有点大吧? 以几何级数递增的计算量很可能会是一个组合爆炸的搜索空间。
- 如果A商品和B商品在10000个订单中同时出现了2000次,而C商品和D商品在订单中同时出现了1000次,到底两个商品关联性更强呢? 如果A商品在订单中出现了8000次同时B商品出现了3000次才产生了2000次的交集,而C商品和在订单中出现了1500次同时D商品出现了1200次就产生了1000次的交集呢?
所以还是要先系统化的复习一下统计学的几个概念,然后再了解相关算法,在此之前我先准备了一份迷你的mock data, 一则说明起来更直观,更重要的是可以节省大量的代码调试与结果验证时间,等算法跑通了再无缝切换到真实数据集上。
2. 迷你数据集
模拟十条订单数据,每个订单中的商品从1个到4个不等。
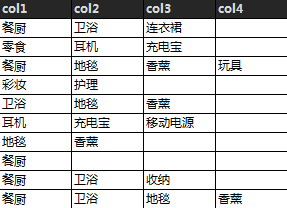
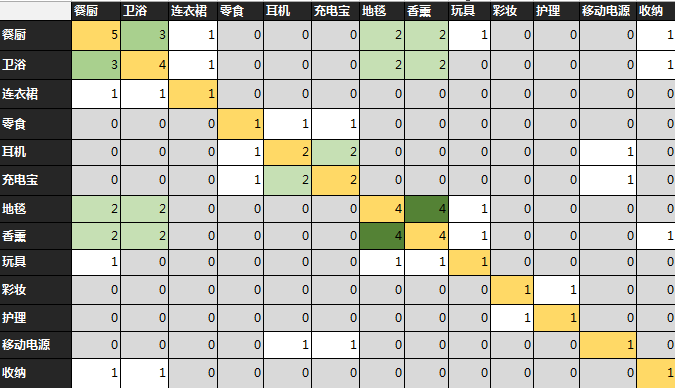
从模拟数据可以生成直观的关联矩阵,颜色越深则出现频率越高
3. 统计学概念
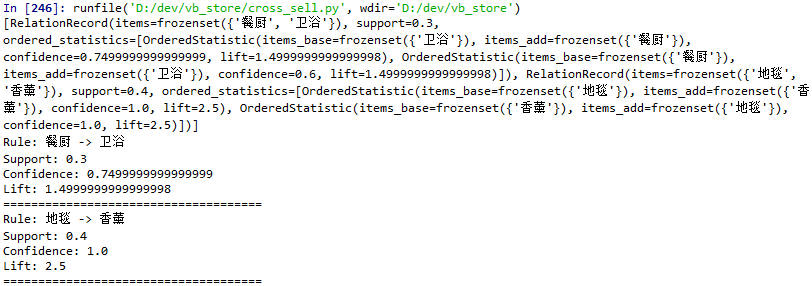
Support(支持度) - 某商品(或组合)在所有订单中出现的概率
Support(A) = (Transactions containing (A))/(Total Transactions)
Support(卫浴)=P(卫浴)=4/10=0.4
Support(卫浴->地毯)=P(卫浴∩地毯) =2/10=0.2
Confidence(置信度) - 在所有包含A的订单中出现B商品的概率
Confidence(A->B) = (Transactions containing both (A and B))/(Transactions containing A) = Support(A∩B)/Suport(A)
Confidence(卫浴->地毯)=Support(卫浴->地毯)/Support(卫浴)=P(地毯|卫浴)=0.5
Lift(提升度) - 销售A商品对B商品带来的提升率
Lift(A->B) = Confidence(A->B)/Support (B)=P(B|A)/P(B)
Lift(卫浴->地毯)=0.5/0.4=1.25
我自己感觉支持度大于0.05, 置信度大于0.25的商品关联算是比较有价值的。
4. 挖掘算法
4.1 Apriori
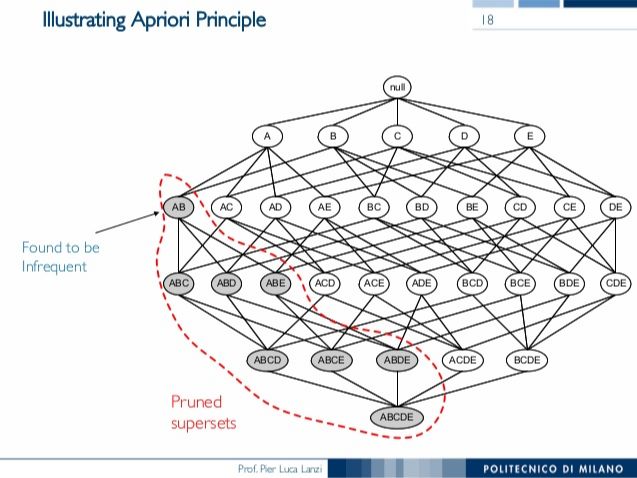
Apriori是先验算法,假设子集S出现了k次,那么任何包含S的其它子集只会出现小于或等于k次. 反之如果S不满足最小的支持度阈值,则任何包含S的子集也不会满足,因此包含S的子集就可以忽略计算了。这样可以避免子集数目的指数增长,从而在合理时间内完成计算。所以这个算法会先生成一元子集(只有一个商品的候选集)的列表,把不满足支持度阈值的记录排除,然后用剩下的一元子集组合成二元子集,继续用支持度阈值卡一道,接下来组合成三元子集,and so on. 这就是个剪枝算法,例如下面的图例中如果发现子集[AB]不满足最小支持度阈值就可以一刀把所有包含[AB]的子集全部干掉。
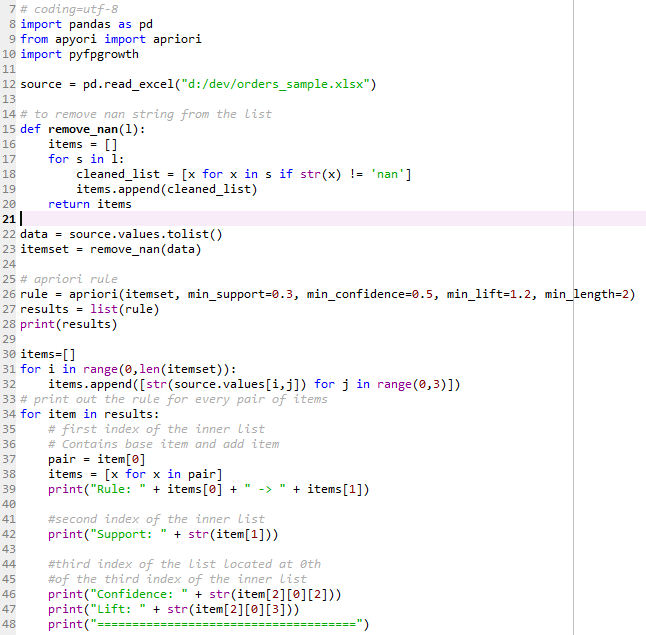
代码解读:
加载数据后从dataframe转化成list
循环处理去除所有的nan(因为pandas将excel表格中为空的cell记录成nan了)
调用apriori函数设置四个最小阈值得到一串rule
为了看得清楚一些最后再写一段代码将rule遍历一次以更好的可读形式打印出来
Apriori的瓶颈是对数据集扫描过多,从一元子集到多元子集生成每一层候选集都要扫描一次,如果支持度阈值不够高则每一层的递进都可能是指数增长,如果订单中商品比较多还会生成庞大的数据集,所以接下来再看看2000年提出的一个改进算法FP-Growth, 多数情况下性能比Apriori高上一两个数量级。
4.2 FP-Growth
FP-Growth是深度优先算法,只需要遍历数据集两次,时间复杂度大大降低。
算法分为两个步骤: 种树和挖树
种树
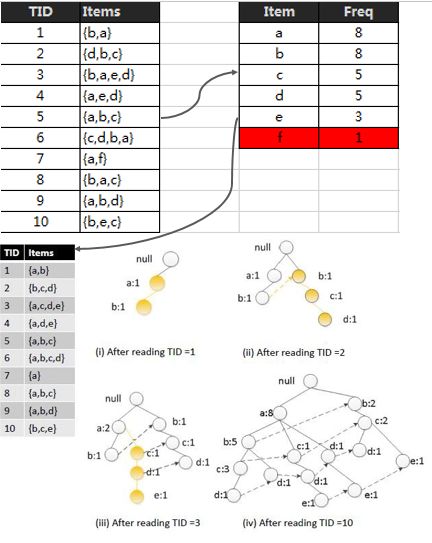
第一次扫描首先统计单个元素的出现频次做降序排列并抛弃不达支持度门槛的元素(假设support threshold=2则f被干掉),然后按照频次高低对原有数据表中的每一个子集进行排序,最后开始构建FP Tree。构建树的时候逐行读取每一个子集,检查子集中的路径前缀是否在树中存在,是则将前缀节点的计数加1并挂靠在现有路径上进行延展(TID=3),否则创建一个全新的分支(TID=2)。相同元素的节点之间用虚线相连。
挖树
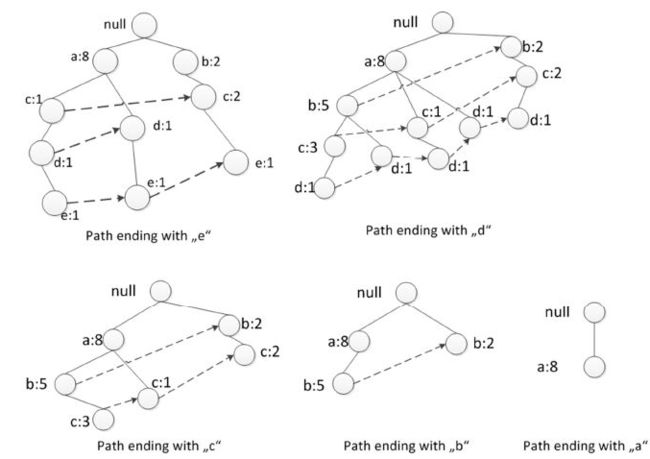
挖树的时候是从下往上(bottom-up), 从叶子节点往根部开始挖,因为每个订单子集都能在FP-Tree找到映射的路径,所以这是一种divide and conquer的策略,将问题分解成多个小的子集最终再把结果合并起来,算法可以分布式平行处理。
挖树分为两个子过程
a. 根据订单子集表将FP-Tree拆解成多颗小树苗
b. 从下到上递归遍历每一颗小树苗
例如我们要找到以e结尾的频繁子集,首先拆解出下图左上角那个小树苗,在这个小树苗里e对应的三个前缀路径为{(a,c,d), (a,d), (b,c)},这个大的任务可以拆解成三个小任务:
找到ae结尾的频繁子集
找到ce结尾的频繁子集
找到de结尾的频繁子集
be结尾的不用管,因为它被支持度阈值过滤了。


5. 实战数据
现在可以切换真实数据源了,直接连接数据库读取百万级别订单数据。因为数据量大处理时间稍长,如果要改变算法的条件门槛多次尝试的话最好把处理好的列表数据用pickle dump出来,多次执行只要反序列化加载即可。订单数据中零食出现频次过高,和很多品类都有连带,所以我把订单中的零食也直接过滤了。当设置出现频次高于300且置信度不小于0.2的时候得到以下结果:

如果有人有兴趣挑战百万级别订单数据挖掘的话可以去看看Kaggle两年前的一个购物篮分析挑战竞赛, 从这个链接可以下载到三百万订单的真实数据。
如果要把分析做的更精细应该还可以考虑结合门店聚类,通过门店各品类销售占比做一个聚类分析就能看出三个特别比较明显的分类
一类门店的客群应该是顾家型已婚妇女
第二类喜欢买服装,但是是低单价的比较单薄的服装为主
第三类也喜欢买服装,且在大衣/羽绒/外套上的贡献突出
References:
Association Rule Mining via Apriori Algorithm in Python
Apriori vs FP-Growth for frequent item set mining
Frequent Itemset Generation Using FP-Growth
Frequent Pattern FP-Growth Algorithm
关联规则挖掘基础