线性回归算法原理推导
文章目录
- 1. 线性模型基本形式
- 2. 线性回归方程
- 3. 误差项分析
- 4. 似然函数求解
- 5. 线性回归求解
线性回归,是利用数理统计中回归分析,来确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法,运用十分广泛。
-
优点:结果易于理解,计算不复杂
-
缺点:对非线性的数据拟合不好
-
适用数据类型:数值型和标称型
线性回归是回归算法中最简单、实用的算法之一,在机器学习中很多知识点都是通用的,掌握一个算法相当于掌握一种思路,其他算法中会继续沿用的这个思路。
1. 线性模型基本形式

2. 线性回归方程
简洁的来说,线性回归的定义就是:目标值预期是输入变量的线性组合。
举个例子:假设某个人去银行准备贷款,银行首先会了解这个人的基本信息,例如年龄、工资等,然后输入银行的评估系统中,以此决定是否发放贷款以及确定贷款的额度,那么银行是如何进行评估的呢?下面详细介绍银行评估系统的建模过程。假设下面是银行贷款数据,相当于历史数据,有以下场景:
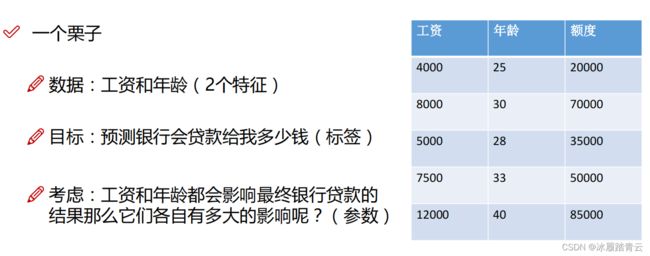
银行评估系统要做的就是基于历史数据建立一个合适的回归模型,只要有新数据传入模型中,就会返回一个合适的预测结果值。在这里,工资和年龄都是所需的数据特征指标,分别用x1和x2表示,贷款额度就是最终想要得到的预测结果,也可以叫作标签,用y表示。其目的是得到x1、x2与y之间的联系,一旦 找到它们之间合适的关系,这个问题就解决了。
目标明确后,数据特征与输出结果之间的联系能够轻易得到吗?在实际数据中,并不是所有数据点都整齐地排列成一条线,如下图所示:
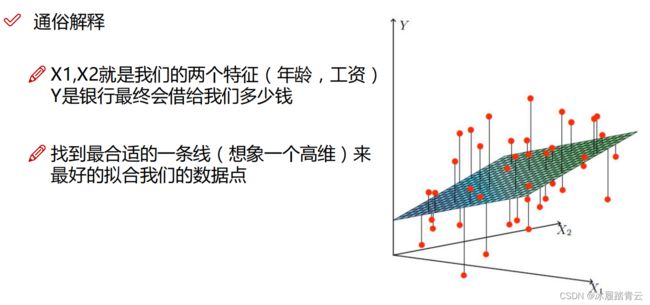
圆点代表输入数据,也就是用户实际得到的贷款金额,表示真实值。平面代表模型预测的结果,表示预测值。可以观察到实际贷款金额是由数据特征x1和x2共同决定的,由于输入的特征数据都会对结果产生影响,因此需要知道x1和x2对y产生多大影响。
我们可以用参数θ来表示这个含义,假设θ1表示年龄的参 数,θ2表示工资的参数,拟合的平面计算式如下:
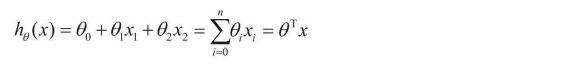
通过上式我们可以看到偏置项 θ 0 θ_0 θ0会对结果产生较小的影响, θ 1 θ_1 θ1和 θ 2 θ_2 θ2我们称它为权重参数,由于它们和我们的数据组合在一起,所以 θ 1 θ_1 θ1和 θ 2 θ_2 θ2会对结果产生较大的影响。
既然已经给出回归方程,那么找到最合适的参数θ这个问题也就解决了。 再强调一点, θ 0 θ_0 θ0为偏置项,但是在上式中并没有 θ 0 x 0 θ_0x_0 θ0x0项,那么如何进行整合呢?其实很简单,因为1乘以任何数都等于它本身,所以我们直接将x0这一列全部置为1就可以解决。
注意:在进行数值计算时,为了使得整体能用矩阵的形式表达,即便没有x0项也可以手动添加, 只需要在数据中加入一列x0并且使其值全部为1即可,结果不变。
3. 误差项分析
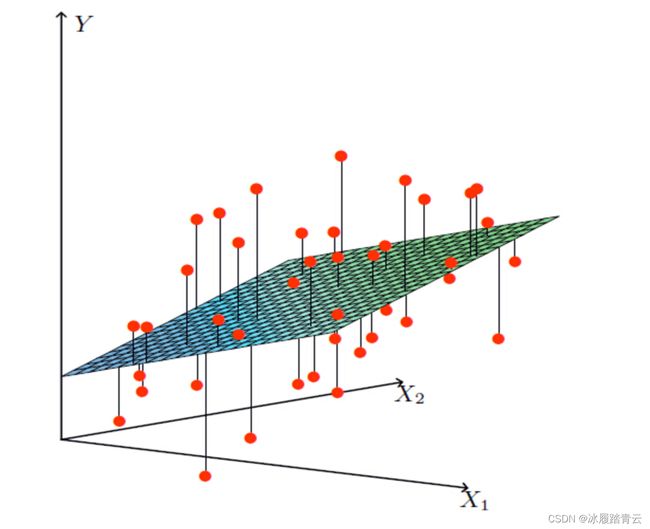
从以上X1,X2,Y构成的三维图中,我们可以看出回归方程的预测值和样本点的真实值并不是一一对应的。说明数据的真实值和预测值之间是有差异的,这个差异项通常称作误差项ε。它们之间的关系可以这样解释:在样本中,每一个真实值和预测值之间都会存在一个误差。

其中,i为样本编号; θ T x ( i ) θ^Tx^{(i)} θTx(i)为预测值; y ( i ) y^{(i)} y(i)为真实值。 这个误差项比较重要,接下来所有的分析与推导都是由此产生的。
先把下面这句看起来有点复杂的解释搬出来:误差ε是独立且具有相同的分布,并且服从均值为0方差为$θ^2$的高斯分布。突然搞出这么一串描述,可能大家有点懵,下面分别解释一下。
所谓独立,例如,张三和李四一起来贷款,他俩没关系也互不影响,这就是独立关系,银行会平等对待他们。
相同分布是指符合同样的规则,例如张三和李四分别去农业银行和建设银行,这就很难进行对比分析了,因为不同银行的规则不同,需在相同银行的条件下来建立这个回归模型。
高斯分布用于描述正常情况下误差的状态,银行贷款时可能会多给点,也可能会少给点,但是绝大多数情况下这个浮动不会太大,比如多或少三五百元。极少情况下浮动比较大,例如突然多给20万,这种可能性就不大。如右下图是高斯分布曲线,可以发现在均值两侧较近地方的可能性较大,越偏离的情况可能性就越小。
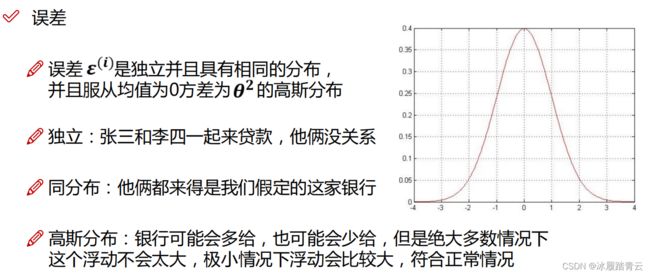
这些知识点不是线性回归所特有的,基本所有的机器学习算法的出发点都在此,由此也可以展开分析,数据尽可能取自相同的源头,当拿到一份数据集时,建模之前肯定要进行洗牌操作,也就是打乱其顺序,让各自样本的相关性最低。
高斯分布也就是正态分布,是指数据正常情况下的样子,机器学习中会经常用到这个概念。
4. 似然函数求解
现在已经对误差项有一定认识了,接下来要用它来实际干点活了,高斯分布的表达式为:

大家应该对这个公式并不陌生,但是回归方程中要求的是参数θ,这里好像并没有它的影子,没关系 ,来转换一下,将 y ( i ) = θ T x ( i ) + ε ( i ) y^{(i)}=θ^Tx^{(i)}+ε(i) y(i)=θTx(i)+ε(i)代入上式可得:

为了更容易理解这个公式,先来给大家介绍一下似然函数:假设参加超市的抽奖活动,但是事前并不知道中奖的概率是多少,观察一会儿发现,前面连着10个参与者都获奖了,即前10个样本数据都得到了相同的结果,那么接下来的抽奖者可能就会有100%的信心认为自己也会中奖。因此,如果超市中奖这件事受一组参数控制,似然函数就是通过观察样本数据的情况来选择最合适的参数,从而得到与样本数据相似的结果。
现在解释一下上式的含义,基本思路就是找到最合适的参数来拟合数据点,可以把它当作是参数与数据组合后得到的跟标签值一样的可能性大小(如果预测值与标签值一模一样,那就做得很完美 了)。对于这个可能性来说,当然是越大越好了,因为得到的预测值跟真实值越接近,意味着回归方程做得越好。所以就有了极大似然估计,找到最好的参数θ,使其与X组合后能够成为Y 的可能性越大越好。 下面给出似然函数的定义:
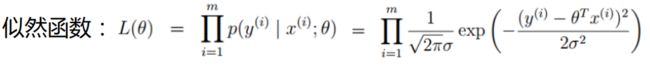
其中,i为当前样本,m为整个数据集样本的个数。
此外,还要考虑,建立的回归模型是满足部分样本点还是全部样本点呢?应该是尽可能满足数据集整体,所以需要考虑所有样本。那么如何解决乘法问题呢?一旦数据量较大,这个公式就会相当复杂, 这就需要对似然函数进行对数变换,让计算简便一些。
如果对上式做变换,得到的结果值可能跟原来的目标值不一样了,但是在求解过程中希望得到极值点,而非极值,也就是能使L(θ)越大的参数θ,所以当进行变换操作时,保证极值点不变即可。
在对数中,可以将乘法转换成加法,即log(A·B)=logA+logB。
对似然函数两边计算其对数结果,可得:
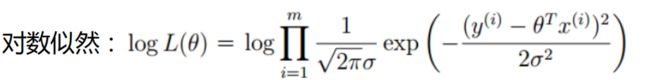
乘法难解,加法就容易了,对数里面乘法可以转换成加法。
继续展开化简,可得:
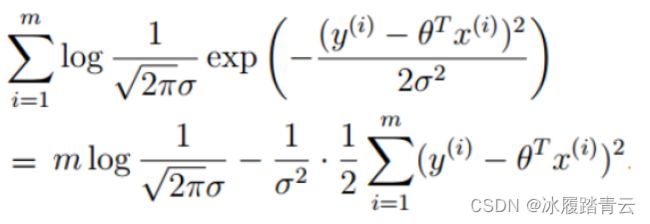
一路走到这里,公式变换了很多,别忘了要求解的目标依旧是使得上面的对数似然取得极大值时的极值点 (参数和数据组合之后,成为真实值的可能性越大越好)。先来观察一下,在减号两侧可以分成两部分,左边部分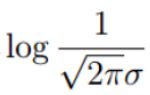
可以当作一个常数项,因为它与参数θ没有关系。对于右边部分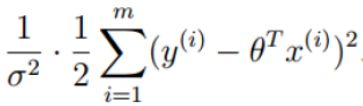
由于有平方项,其值必然恒为正。整体来看就是要使得一个常数项减去一个恒正的公式的值越大越好,由于常数项不变,那就只能让右边部分越小越好, 1 σ 2 \frac 1{\sigma^2} σ21 可以认为是一个常数,故只需让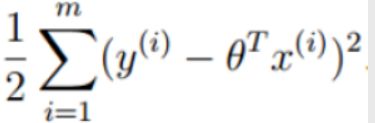
越小越好,这就是最小二乘法。
虽然最后得到的公式看起来既简单又好理解,就是让预测值和真实值越接近越好,但是其中蕴含的基本思想还是比较有学习价值的,在数学推导过程中,最重要的是要理解每一步的目的,对于理解其他算法也是有帮助的。
5. 线性回归求解
搞定目标函数后,下面讲解求解方法,列出目标函数列如下:
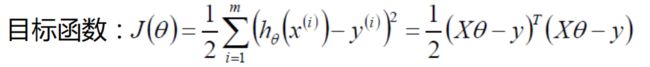
既然要求极值(使其得到最小值的参数θ),对目标函数计算其偏导数即可:
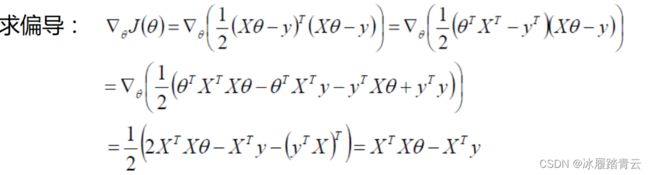
经过一系列的矩阵求导计算就得到最终的结果(关于矩阵求导知识,了解即可),但是,如果上式中的矩阵不可逆会怎么样?显然那就得不到结果了。
其实大家可以把线性回归的结果当作一个数学上的巧合,真的就是恰好能得出这样的一个值。但这和机器学习的思想却有点矛盾,本质上是希望机器不断地进行学习,越来越聪明,才能找到最适合的参数,但是机器学习是一个优化的过程,而不是直接求解的过程。
没有谁的生活会一直完美,但无论什么时候,都要看向前方,满怀希望就会所向披靡。—— 巫哲 《撒野》