HTML
1. 常用的瀏覽器内核
IE(Trident);
Chrome/Safari(Webkit);
Firefox/Mozilla(Gecko);
Opera(Presto);
2. 對瀏覽器内核的理解
瀏覽器的内核主要分成兩個部分:渲染引擎和JS引擎。
渲染引擎:負責取得網頁内容(HTML、XML、圖像等等)、整理訊息(例如加入CSS等),以及計算網頁的顯示方式,然後會輸出至顯示器或打印機。
瀏覽器内核的不同導致了對網頁的語法解釋會有不同,所以渲染的效果也不相同。所有網頁瀏覽器、電子郵件客戶端以及其他需要編輯、顯示的網絡内容的應用程序都需要内核。
2. Doctype作用?標準模式和兼容模式各有什麽區別?如何觸發?
(1) 告知瀏覽器的解析器用什麽文檔標準解析這個文檔。DOCTYPE不存在或格式不正確會導致文檔以兼容模式呈現。
(2) 標準模式的排版和JS運作模式都是以該瀏覽器支持的最高標準運行。在兼容模式中,頁面以寬鬆的向後兼容的方式顯示,模擬老式瀏覽器的行爲以防止站點無法工作。
(3)
/*HTML4.01嚴格模式*/
/*XHTML 1.0嚴格模式*/
4.瀏覽器標準模式和怪異模式之間的區別是什麼?
由於歷史原因,不同瀏覽器對頁面的渲染是不同的,甚至同一瀏覽器的不同版本也是不一樣的。在W3C標準出台之前,不同瀏覽器在頁面的渲染上沒有統一的規範,產生了差異,即Quirks mode(怪異模式或兼容模式)。當W3C標準出台之後,不同瀏覽器對頁面渲染有了統一的標準,即Strict mode(標準模式或嚴格模式)。
在W3C標準推出前,舊的頁面都是根據舊的渲染方式對頁面進行渲染的,因此在W3C標準推出后為了保證舊頁面的正常顯示,保持瀏覽器的兼容性,這樣瀏覽器上就產生了能夠兼容W3C標準渲染的嚴格模式和保證舊頁面顯示的怪異模式或標準兼容模式。
在標準模式中,瀏覽器根據規範呈現頁面;在混雜模式中,頁面以一種比較寬鬆的向後兼容的方式顯示。
如果XHTML文檔包含形式完整的DOCTYPE,那麼它一般以標準模式呈現。對於HTML4.01文檔,包含嚴格DTD的DOCTYPE常常導致頁面以標準模式呈現。包含過渡DTD和URI的DOCTYPE也導致頁面以標準模式呈現,但是有過渡DTD而沒有URI會導致頁面以混雜模式呈現。DOCTYPE不存在或形式不正確會導致HTML和XHTML文檔以混雜模式呈現。
區別在於:
在嚴格模式中:width是內容的寬度,元素真正的寬度 = magin-left + border-left-width + padding-left + width +padding-right + border-right-width + margin-right;
在怪異模式中:width則是元素的實際寬度,內容寬度 = width - (padding-left + padding-right + border-left+width + border-right-width);
5.DOCTYPE有多少種類型?
該標籤可聲明三種DTD類型,分別表示嚴格版本、過渡版本以及基於框架的HTML文檔。
HTML 4.01規定了三種文檔類型:Strict、Transitional、Frameset;
XHTML 1.0規定了三種XML文檔類型:Strict、Transitional、Frameset;
6. HTML5爲什麽只需要寫
因爲HTML5不基於SGML(標準通用標記語言),因此不需要對DTD(Document Type Definition 文檔類型定義)進行引用,但是需要對DOCTYPE來規範瀏覽器的行爲。
而HTML4.01基於SGML,所以需要對DTD進行引用,才能告知瀏覽器文檔所使用的文檔類型。
7. 使用XHTML的局限有哪些?
XHTML與HTML的區別為:
- XHTML元素必須被正確地嵌套;
- XHTML元素必須被關閉;
- XHTML標籤名必須用小寫字母;
- XHTML文檔必須擁有根元素;
- XHTML文檔要求給所有屬性賦一個值;
- XHTML要求所有的屬性必須用引號""括起來;
- XHTML文檔要求要把所有
<、>、&等特殊符號用編碼表示; - XHTML文檔不要在注釋中使用“--”;
- XHTML圖片必須有說明文字;
- XHTML文檔中用id屬性代替name屬性;
局限:
所有的XHTML元素都必須被正確地嵌套,XHTML必須擁有良好的結構,所有的標籤必須小寫,並且所有的XHTML元素必須被關閉,所有的XHTML文檔必須擁有DOCTYPE聲明,並且html、head、title和body元素必須存在。雖然代碼更加優雅,但缺少容錯性,不利於快速開發。
8.cookies,sessionStorage和localStorage有什麼區別?
| 特性 | cookie | sessionStorage | localStorage |
|---|---|---|---|
| 數據生命期 | 生成時就會被制定一個maxAge值,這就是cookie對的生存週期,在這個週期內cookie有效,默認關係瀏覽器失效 | 頁面會話期間可用 | 除非數據被清除,否則一直存在 |
| 存放數據大小 | 4K左右(因為每次HTTP請求都會攜帶cookie) | 一般5M或更大 | |
| 與服務器通信 | 由對服務器的請求來傳遞,都會攜帶在HTTP頭中,如果使用cookie保存過多數據將會帶來性能問題 | 數據不是由每個服務器請求傳遞的,而是只有在請求時使用數據,不參與和服務器的通信 | |
| 易用性 | cookie需要自己封裝setCookie、getCookie | 可以用原生接口,也可再次封裝對Object和Array有更好的支持 | |
| 共同點 | 都是保存在瀏覽器端,與服務器端的session機制不同 |
CSS
1. 行内元素和塊級元素的區別?兼容性使用?
行内元素:
(1) 水平方向排列;
(2) 不能包含塊級元素;
(3) 設置width/height/margin/padding無效;
塊級元素:
(1) 各占據一行;
(2) 垂直方向排列;
(3) 從新行開始結束接著一個斷行;
2. 清除浮動的方式
.clearfix:after {
content: ".";
display: block;
clear: both;
visibility: hidden;
line-height: 0;
height: 0;
}
.clearfix {
display: inline-block;
}
.clearfix {
overflow: auto;
zoom: 1;
}
3. box-sizing常用屬性有哪些?
設置或檢索對象的盒模型組成模式。
box-sizing:content-box; 寬度和高度分別對應到元素的内容框。在寬度和高度之外繪製元素的内邊距和邊框(默認);
box-sizing:border-box; 元素制定的任何内邊距和邊框都將在已設定的寬度和高度内進行繪製。通過從已設定的寬度和高度分別減去邊框和内邊距才能得到内容的寬度和高度。
4. 使用link和@import的區別
link:
(1) 屬於XHTML標簽;
(2) 不僅可以加載CSS,還能用於定義RSS、rel連接屬性等作用;
(3) 頁面加載時,會被同時加載;
(4) 無兼容問題;
@import
(1) CSS提供的,衹能用於加載CSS;
(2) 等到頁面被加載完才會加載;
(3) CSS2.1提出,IE5以上才能識別;
(4) 不利于後期修改和優化;
5.解释下浮动和它的工作原理。
關於浮動,我們需要了解,浮動的框可以向左或向右移動,直到它的外邊緣碰到包含框或另一個浮動框的邊框為止。要想使元素浮動,必須為元素設置一個寬度。雖然浮動元素不是文檔流之中,但是它浮動后所處的位置依然是在浮動之前的水平方向上。由於浮動框不在文檔的普通流中,所以文檔的普通流中的塊框表現得就像浮動框不存在一樣,下面的元素填補原來的位置。有些元素會在浮動元素的下方,但是這些元素的內容并不一定會被浮動元素所遮蓋。
對內聯元素進行定位時,這些元素會考慮浮動元素的邊界,會圍繞著浮動元素放置,可以把浮動元素想象成被塊元素忽略的元素,而內聯元素會關注浮動元素。
JavaScript
1.事件委託是什麼?
事件委託就是利用事件冒泡,只指定一個事件處理程序,就可以管理某一類型的所有事件。
優點:減少DOM操作,優化性能,減少內存佔用。
2.閉包
簡單地說,閉包就是一個函數在創建時允許該自身函數訪問并操作該自身函數之外的變量時所創建的作用域。
3.阻止事件冒泡/默認事件
event.stopPropagation()
這是阻止事件冒泡的方法,不讓事件向document上蔓延,但是默認事件仍然會執行,當你用這個方法的時候,如果是點擊一個鏈接,這個連接仍然會被打開。
event.preventDefault()
這是阻止默認事件的方法,調用此方法后,鏈接不會被打開,但是會發生冒泡,冒泡會傳遞到上一層父元素。
return false
這個方法將會同時阻止事件冒泡和默認事件,鏈接不會被打開,事件也不會被傳遞到上一層。
4.解釋下JavaScript中的this是如何工作的
this永遠指向函數運行時所在的對象,而不是函數被創建時所在的對象。
匿名函數或不處於任何對象中的函數指向window。
如果是call、apply、with,指定的this是誰,就是誰。
普通函數調用,函數被誰調用,this就是誰。
5.call和apply的區別是什麼?
call方法:
語法:call(thisObj,Object)
定義:調用一個對象的一個方法,以另一個對象替換當前對象。
說明:call方法可以用來代替另一個對象調用一個方法。call方法可以將一個函數的對象上下文從初始的上下文改變為由thisObj指定的新對象。如果沒有提供thisObj參數,那麼Global對象被用作thisObj。
apply方法:
語法:apply(thisObj,[argArray])
定義:應用某一對象的一個方法,用另一個對象替換當前對象。
說明:如果argArray不是一個有效的數組或者不是arguments對象,那麼將導致一個TypeError,如果沒有提供argArray和thisObj任何一個參數,那麼Global對象將被用作thisObj,並且無法被傳遞任何參數。
對於call和apply兩者在作用上是相同的,但兩者在參數上有以下區別:
對於第一個參數意義都一樣,但對第二個參數:apply傳入的是一個參數數組,也就是將多個參數組合成為一個數組傳入,而call則作為call的參數傳入(從第二個參數開始)。如func.call(func1,var1,var2,var3)對應的apply寫法為:func.apply(func1,[var1,var2,var3]),同時使用apply的好處是可以直接將當前函數的arguments對象作為apply的第二個參數傳入。
6.綜合題
function Foo() {
getName = function () { alert (1); };
return this;
}
Foo.getName = function () { alert (2);};
Foo.prototype.getName = function () { alert (3);};
getName = function () { alert (4);};
function getName() { alert (5); }
// 問:
Foo.getName();
getName();
Foo().getName();
getName();
new Foo.getName();
new Foo().getName();
new new Foo().getName();
// 正確執行順序:
function Foo() {
getName = function () { alert (1); };
return this; // this 指向window
}
var getName;
function getName() { alert (5); }
Foo.getName = function () { alert (2);};
Foo.prototype.getName = function () { alert (3);};
getName = function () { alert (4);};
// 結果
Foo.getName(); //2
getName(); //4
Foo().getName(); //1
getName(); //1
new Foo.getName(); //2 new (Foo.getName)();
new Foo().getName(); //3 (new Foo()).getName()
new new Foo().getName(); //3 new ((new Foo()).getName)();
7.實現函數isInteger(x)來判斷x是否是整數?
可以將x轉換成10進制,判斷和本身是不是相等即可:
function isInteger(x) {
return parseInt(x, 10) === x;
}
8.寫一個少於80字符的函數,判斷一個字符串是否是回文字符串
回文字符串:即字符串從前往後讀和從後往前讀字符順序是一致的。
function isPalindrome(str) {
str = str.replace(/\W/g, '').toLowerCase();
return (str == str.split('').reverse().join(''));
}
9.下面的代碼會輸出什麼?為什麼?
var arr1 = "john".split('');
var arr2 = arr1.reverse();
var arr3 = "jones".split('');
arr2.push(arr3);
console.log("array 1: length=" + arr1.length + " last=" + arr1.slice(-1));
console.log("array 2: length=" + arr2.length + " last=" + arr2.slice(-1));
MDN 上對於 reverse() 的解釋:
Description
The reverse method transposes the elements of the calling array object in place, mutating the array, and returning a reference to the array.
也就是說,reverse()會改變數組本身,並且返回原數組的引用。
所以在arr2 = arr1.reverse()時,arr1已經改變了。
10.解釋下面代碼的輸出
var a={},
b={key:'b'},
c={key:'c'};
a[b]=123;
a[c]=456;
console.log(a[b]);
// 結果
無論是a[b]或a[c],都會打印出456
原文解釋是:
The reason for this is as follows: When setting an object property, JavaScript will implicitly stringify the parameter value. In this case, since b and c are both objects, they will both be converted to “[object Object]”. As a result, a[b] anda[c] are both equivalent to a[“[object Object]”] and can be used interchangeably. Therefore, setting or referencing a[c] is precisely the same as setting or referencing a[b].
簡單來說,就是對象屬性訪問中,' [ ] '中括號的訪問方式,會做一個隱式的toString(),這時候就把b轉化為[object object],而c也被轉化為[object object],它們的鍵值都一樣,所以a[b]和a[c]的結果都是一樣的。
11.IE和標準下有哪些兼容性的寫法?
var e = e || window.event
document.documentElement.clientWidth || document.body.clientWidth
var target = e.srcElement || e.target
12.Ajax請求時,如何解釋Json數據
有兩個方法,eval()方法和JSON.parse(),但推薦使用JSON.parse(),因為eval()方法解析的時候不會去判斷字符串是否合法,而且Json對象中的JS方法也會被執行,這是非常危險的。
eval的全稱是evaluate,就是求值的意思。parse字義上就是解析,從方法名稱中就能看出區別。
13.DOM結構——兩個節點之間可能存在哪些關係以及如何在節點之間任意移動

DOM中兩個節點存在的關係無非三種:
(1)包含與被包含的關係
- IE率先引入了
contains()方法可檢測,例如A.contains(B),即檢查節點B是否是節點A的子節點,返回布爾值。 - DOM3級規範引入
compareDocumentPosition(),確定節點之間的關係,返回值為一個表示關係的位掩碼的合,通過按位操作符“&”可確定關係。
例如:節點A()在節點B()前——位掩碼為4,且節點A包含節點B——位掩碼為16,則返回值20,通過“!!(20&16)”這種方式即可返回一個布爾值,“20&16”返回16證明節點A包含節點B(即:16),通過!!取得16的布爾值true。
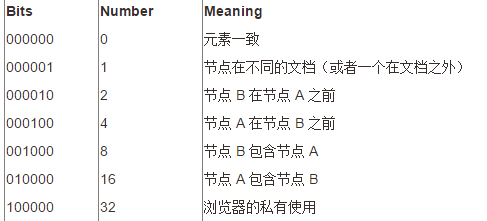 位掩碼
位掩碼
(2)父與子
獲取父節點:node.parentNode、node.parentElement,兩者的區別在於後者只能獲取元素。
 兩者的區別
兩者的區別
(3)同輩(兄弟節點)
nextSibling、previousSibling
(4)Element Travel API給DOM添加的屬性
childElementCount、firstElementChild、lastElementChild、nextElementSibling、previousElementSibling,他們與之前的方法之間的區別在於多了Element,保證只返回元素節點,而之前的方法,普通的文本節點及注釋節點也會被返回。
並且,之前的方法在非IE瀏覽器中還會把元素間的空白符當文本節點返回。
(5)children属性(IE9以後)
與childNodes不同的地方在於,children只包含元素子節點(IE8及之前的版本可能會包含注釋節點)。
14.DOM操作——怎樣添加、移除、移動、複製、創建和查找節點
(1)創建新節點
createDocumentFragment() // 創建一個DOM片段createElement() // 創建一個具體的元素-
createTextNode() //創建一個文本節點
(2)添加、移除、替換、插入 -
appendChild()
用於向childNodes列表的末尾添加一個節點,返回要添加的元素節點,appendChild()方法還可以添加已經存在的元素,會將元素從原來的位置移到新的位置。 removeChild()replaceChild()-
insertBefore()
如果不是在末尾插入節點,而是想要放在特定的位置上,用這個方法即可,該方法接受兩個參數,第一個是要插入的節點,第二個是參照節點,返回要添加的元素節點。
(3)查找 getElementByTagName() // 通過標籤名稱getElementsByTagName() // Elements加了s,選出來是數組getElementByName() // 通過元素的Name屬性的值getElementsByName() // Elements加了s,選出來是數組getElementByClassName() // 通過元素的類名- ``getElementsByClassName() // Elements加了s,選出來是數組,IE9以下不支持
getElementById() // 通過元素ID,唯一性
15.事件——怎樣使用事件以及IE和DOM事件模型之間存在哪些主要差別
(1)關於事件
IE的事件流:事件冒泡
由事件的目標(event.srcElement)接受事件,然後逐級向上,直到文檔節點document。
其他瀏覽器:事件捕獲
與事件冒泡正好相反,文檔節點document先監聽到事件,然後把事件逐級向下傳遞事件,直到目標節點event.target。
(2)DOM事件流
DOM2級事件規範的事件流綜合了以上兩種,把事件流分為了以下三個階段:
1.事件捕獲階段
不涉及事件目標,或者說這個階段在目標之前就結束了;
2.處於目標階段
被看做冒泡階段的一部分,所以可以在冒泡階段在目標事件上操作事件;
3.事件冒泡階段
** 規範和瀏覽器實現的差別:(1)DOM2級事件規範的捕獲階段,事件從文檔節點document開始傳播,現代瀏覽器大多數都是從window對象開始傳播事件。(2)DOM2級事件規範捕獲階段不涉及事件目標,現代瀏覽器大多數在這個階段包含事件目標。
16.XMLHttpRequest——這是什麼、怎樣完整地執行一次GET請求、怎樣檢測錯誤
https://segmentfault.com/a/1190000004322487
17.JSON——它是什麼、為什麼應該使用它、到底該怎麼使用它,說出實現細節來
是一種輕量級的數據交換格式,易於人的閱讀和編寫,同時也易於機器解析和生成。
JSON建構于兩種結構:
- “名稱/值”對的集合(A collection of name/value pairs)。不同語言中,它被理解為對象(object)、記錄(record)、結構(struct)、字典(dictionary)、哈希表(hash table)、有鍵列表(keyed list),或者關聯數組(associative array)。
- 值得有序列表(An ordered list of values)。在大部分語言中,它被理解為數組(array)。
以上是自己平時記不住的題目,存下來多看幾遍。
待補充.....