JavaSE——深入集合
目录
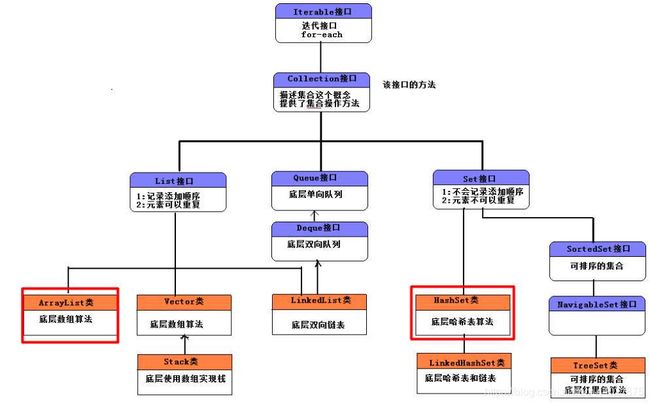
一、集合框架体系
1.单列集合
2. 双列集合(键值对 K-V 形式)
二、单列集合接口
1.Collection接口
1)特点
2)遍历元素的方式——Iterator(foreach)
2.List接口
1)特点
2)遍历方式
3)ArrayList实现类
4)LinkedList实现类
5)LinkedList和ArrayList的比较(※)
3.Set接口
1)特点
2)遍历方式
3)HashSet实现类(⭐⭐)
4)LinkedHashSet实现类
5)TreeSet实现类
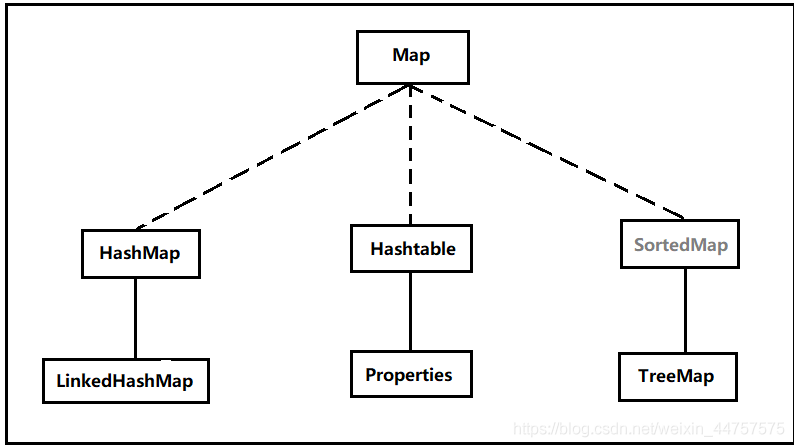
三、双列集合的接口
1.Map接口(⭐)
1)特点(jdk8)
2)遍历方式
2. HashMap实现类
1)底层机制
2)源码剖析
3.HashTable实现类
1)底层机制
2)源码解析
3)HashMap与HashTable的对比
4.properties实现类
5.TreeMap实现类(⭐)
1)底层机制
2)源码解析
一、集合框架体系
1.单列集合
2. 双列集合(键值对 K-V 形式)
二、单列集合接口
1.Collection接口
1)特点
①Collection实现子类可以存放多个元素,每个元素可以是Object。
②有些Collection的实现类可以存放重复的元素,有些不行。
③有些Collection的实现类,是有序的,也有的是无序的。
④Collection接口没有直接的实现子类,是通过他的子接口Set和List来实现的。
2)遍历元素的方式——Iterator(foreach)
①Iterator对象称为迭代器对象,主要用于遍历Collection集合中的元素,
②所有实现了Collection接口的集合类都有一个iterator()方法,该方法用于返回一个实现了Iterator接口的对象,它只用于遍历集合,本身并不存放对象。
③Iterator对象的实现类主要有如下方法:

他的运行原理图如下:

注意:在调用iterator.next()方法之前必须要调用iterator.hasNext()进行检测,如果不调用,且下一条记录无效,会抛出异常。
2.List接口
1)特点
List集合类有如下特点:
①List集合类中元素有序(添加顺序和取出顺序一致),可重复。
②List集合中的每个元素都有对应的顺序索引。(从0开始)
③List容器中的元素都对应一个整数型的序号记载在容器的位置,可根据序号存取容器中元素。
④它的实现类有ArrayList,LinkedList,Vector等。
2)遍历方式
①使用.iterator()拿到当前集合迭代器,使用迭代器进行遍历
②使用for循环或foreach进行遍历
3)ArrayList实现类
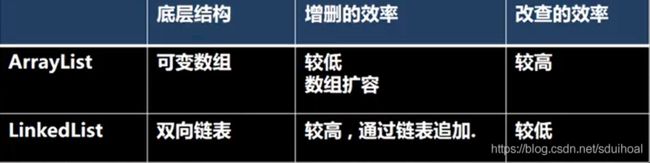
特点:Arraylisti底层使用数组来实现数据储存,ArrayList基本等同与Vector,但是ArrayList是线程不安全的,多线程的情况下不建议使用。
Ⅰ. 底层机制:
关于扩容机制
①ArrayList中维护了一个Object类型的数组elementData。 transient Object[ ] elementData(transient 关键词表示该属性不会被序列化)
②当创建ArrayList对象时,如果使用无参构造器,则初始化elementData容量为0,第一次添加,扩容elementData为10,如果需要再次扩容,则扩容为他的1.5倍。
③如果是指定大小的构造器,则初始化elementData容量为指定大小,如需要扩容则直接扩容1.5倍。
④扩容底层(grow()) 调用的是Arrays.copyOf(T[] t,int a)方法。
⑤每次调用 add() 方法,都会检查是否需要扩容。
Ⅱ. 常用方法的复杂度:
add(E e):添加元素到末尾,平均时间复杂度为O(1)。
add(int index, E element):添加元素到指定位置,平均时间复杂度为O(n)。
get(int index):获取指定索引位置的元素,时间复杂度为O(1)。
remove(int index):删除指定索引位置的元素,时间复杂度为O(n)。
remove(Object o):删除指定元素值的元素,时间复杂度为O(n)。
4)LinkedList实现类
特点:它底层实现了双向链表和双端队列特点,可以添加任意元素,LinkedList也是线程不安全的。
Ⅰ. 底层机制:
①LinkedList中维护了两个属性first和last分别指向双向链表的首节点和尾节点
②LinkedList元素的添加和删除,而是操作节点的next和prev,不是通过数组完成的,所以效率较高。
Ⅱ.常用方法时间复杂度
get() :获取第几个元素,依次遍历,复杂度O(n)
add(E) :添加到末尾,复杂度O(1)
add(index, E): 添加第几个元素之后,需要先查找到第几个元素,直接指针指向操作,复杂度O(n)
remove():删除元素,默认删除链表头,复杂度O(1)
5)LinkedList和ArrayList的比较(※)
3.Set接口
1)特点
①Set接口是无序的,所以没有索引。
②他不允许重复的元素(看地址),索引最多包含一个null。
③与List接口相同他两都是Collection的子接口,所以常用方法和Collection接口一样。
2)遍历方式
①因为是Collection的子接口,所以可以用迭代器遍历。
②可以用增强循环foreach。
3)HashSet实现类(⭐⭐)
特点:①HashSet 底层是HashMap,HashMap的底层是 数组+链表+红黑树。②HashSet不保证元素是有序的(即不保证存放元素顺序和取出顺序一致)。③因为HashMap不是线程安全的,所以HashSet也是线程不安全的。
Ⅰ. add()——添加的底层源码
①底层机制:
先执行HashSet的类构造器,生成一个HashMap;
添加一个元素时先得到该元素的hash值,然后转化为table(数组)索引值;
找到存储数据的table(数组),检查该索引位置是否已经存放元素;
如果没有直接加入,如果有调用equals方法进行比较,如果相同则放弃添加,如果不同则添加在最后;
如果一条链表的元素个数达到TREEIFY_THRESHOLD(默认8),且table(数组的大小)的大小大于MIN_TREEIFY_CAPACITY(默认64),就会进行树化(变成红黑树)。

②源码剖析:
以如下代码为例:
public static void main(String[] args) {
HashSet set = new HashSet();
set.add("java");
set.add("php");
set.add("java");
System.out.println(set);
}Step1:执行Hashset类构造器,创建一个HashMap map。
public HashSet() {
map = new HashMap<>();
}Step2:执行Hashset的add()。
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}Step3:执行map的put()方法,在此之前会执行hash(key)方法,得到一个key对应的hash值(注意,该hash值是hashCode经过右移16位得到的,目的是防止哈希冲突)。K是要存入的值 V是静态的共享值,占位的,不太重要。
public V put(K key, V value) { key:"java" value:Object@562
return putVal(hash(key), key, value, false, true);
}Step4:执行putVal()方法。
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node[] tab; Node p; int n, i; //定义辅助变量
//该table就是Hashmap的属性(存放节点的数组),类型是Node[]
//if语句表示如果该table是null,或长度为0,就进行第一次扩容到16
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//(1)根据key得到的hash值计算该key应该存放到table表的哪个索引位置,并把这个位置
// 的对象;赋值给辅助变量p。
//(2)判断p是否为null
//(2.1)如果p为null,代表还没有存放过元素,那就创建一个node(key:"java",val:PRESENT)
//(2.2)放在该位置tab[i]= newNode(hash,key,value,null)
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {//如果p不为null
Node e; K k;//辅助变量
//如果当前索引位置链表的第一个元素与插入元素的hash值相同
//并满足 下面两个条件之一:
//(1)插入元素的key 和 p指向的Node节点的key是同一个对象。
//(2)不是同一个元素,但是内容(重写equals方法后)比较相同。
//则插入失败
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
//如果p是一颗红黑树,调用putTreeVal添加元素
else if (p instanceof TreeNode)
e = ((TreeNode)p).putTreeVal(this, tab, hash, key, value);
//如果table对应的索引位置已经是一个链表了,使用for循环比较:
//(1)依次与该链表的每一个元素比较后都不相同,将插入元素尾插到链表。
注意:在将元素往链表添加后,立即判断该链表是否已经到达8个结点
如果已经8个了,对当前链表进行树化。
//(2)依次比较的过程中如果有相同的,直接break,插入失败
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1)
//在树化时还会对map进行判断,如果table数组小于64那就进行扩容;
如果大于等于64进行树化。
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
//当key存在对应的value时走这里(HashMap用)
//因为HashSet的K对应的V是PRESENT=null所以不走这里
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;//表示该map的次数
//检查当前map的元素个数是否超过临界,如果超过,就扩容。
if (++size > threshold)
resize();
//留给HashMap的子类去实现的方法,对于HashMap来说这是个空方法。
afterNodeInsertion(evict);
return null;
} Ⅱ. resize()——扩容的底层了解(※)
底层机制:
①第一次添加时,table数组扩容到16,临界值= 16*负载因子(默认为0.75) 为12。
②如果向table中添加元素的个数达到了临界值,数组的容量会2倍扩容为32,进而新的临界值也随之改变为24;
③在Java8中,如果链表的元素个数到达了8,同时table表容量大于64,链表会进行树化(链表Node直接变成红黑树TreeNode),否则仍然采用数组扩容机制。
4)LinkedHashSet实现类
特点:①他是HashSet的子类,它的底层是一个LinkedHashMap,底层维护 一个 数组+双向链表。②它根据插入元素的HashCode决定元素存储位置,同时使用双向链表维护元素的次序,使得元素看起来是以插入顺序保存的。③不允许插入重复元素
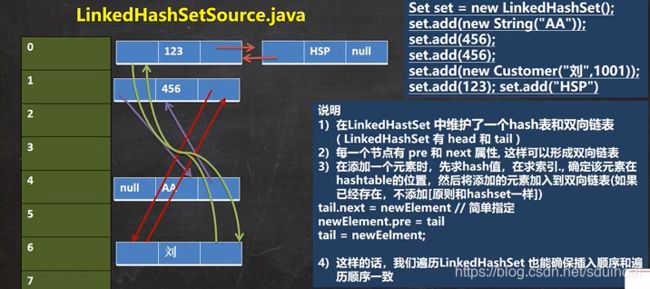
它的添加与扩容用的同样是Hashset的那一套。
5)TreeSet实现类
特点:TreeSet底层是TreeMap,只不过TreeSet的Entry节点的Val是PRESENT,TreeMap是实际的值。TreeSet或TreeMap主要关注传入的比较器中的比较规则。
Ⅰ.比较器
①底层机制
当使用无参构造器创建TreeSet时,数据仍然是无序的。
当使用TreeSet提供的构造器,可以传入一个比较器(new Comparator(),重写compare方法),并指定排序规则。
②源码解析
1 构造器把传入的比较器对象,赋给了TreeSet底层TreeMap的属性this.comparator
public TreeSet(Comparator comparator) {
this(new TreeMap<>(comparator));
}2在调用treeSet.add()时,treeMap会执行put方法,put底层会执行如下逻辑,使用到我们传入的比较器
//cpr就是传入的比较器,这里会动态绑定到我们重写的compare方法
if (cpr != null) {
do {
parent = t;
cmp = cpr.compare(key, t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value);
} while (t != null);
}三、双列集合的接口
1.Map接口(⭐)
Map用于保存具有映射关系的数据,K-V。Map的key不允许重复,原因同HashSet。但val可以有重复值
1)特点(jdk8)
①Map实际存放数据的key-value的示意图如下图左,一对k-v存放在一个Node(HashMap$Node)中。
//1 k-v的存放
HashMap$Node node = newNode(hash,key,value,null);②为了方便程序员遍历,创建了如图右形式 的集合——EntrySet,该集合存放的是Entry对象,而Entry对象包含k,v。
//2 entrySet
Set> entrySet; ③entrySet中,定义的类型是Map.Entry,但实际存放的还是HashMap$Node,这是因为 HashMap$Node implements Map.Entry
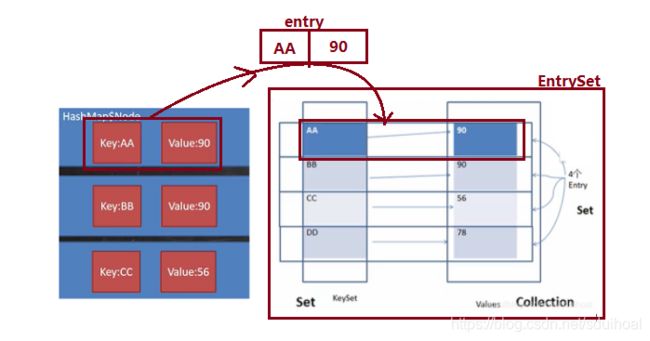
因为EntrySet中的Entry存放的是K-V数据的引用所以,可以某种情况下可以通过Entry对K,V进行操作。

④当把HashMap$Node对象存放到entrySet就方便了遍历,因为Map.Entry提供了重要的方法 K getKey()、V getValue()。
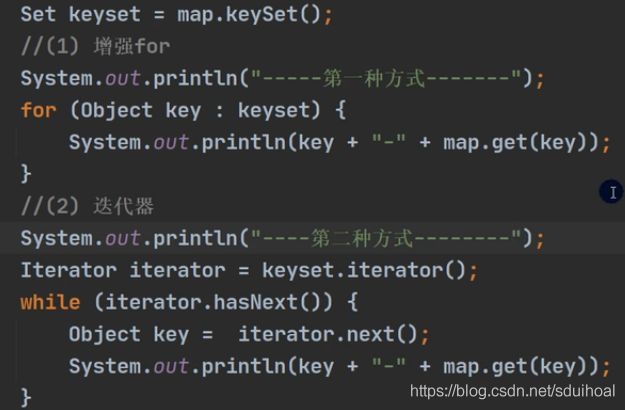
2)遍历方式
① 先取出所有的key——拿到map.keySet( ),通过key取出所有的value
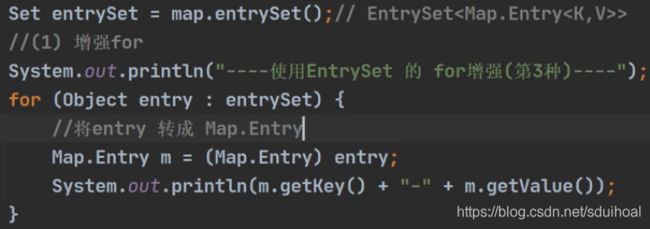
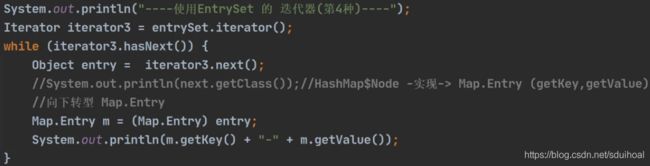
② 通过EntrySet获取K-V(※)
2. HashMap实现类
特点:①以键值对的形式存数据,底层是数组+链表+红黑树。②与HashSet一样不保证映射顺序(因为底层是hash表)。③HashMap没有实现同步,所以是线程不安全的。
1)底层机制
①示意图
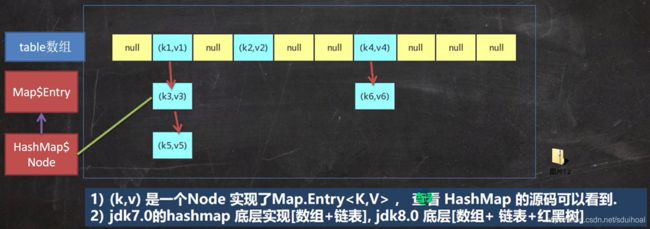
②扩容机制
省略
——————与HashSet相同———————
2)源码剖析
——————与HashSet相同———————
3.HashTable实现类
特点:①存放的元素是键值对。②hashTable的键和值都不能为null。 ③使用方法基本和HashMap一样 ④HashTable是线程安全的(put方法有sychronized),HashMap不是线程安全的。
1)底层机制
①底层有一个数组——Hashtable$Entry[ ],初始化大小为11,Entry数组中的entry存放 key和value。
②临界值 threshold = table数组长度*负载因子(0.75)。
③扩容机制:如果到达临界值,执行rehash()进行扩容,新数组容量 = 长度*2 + 1 。
④添加:执行方法addEntry(hash, key, value, index); 添加K-V键值对封装到Entry
2)源码解析
①负载因子和初始容量

①添加
private void addEntry(int hash, K key, V value, int index) {
modCount++;
//先拿到table数组
Entry tab[] = table;
//检查是否超过临界值
if (count >= threshold) {
// Rehash the table if the threshold is exceeded
rehash();
tab = table;
hash = key.hashCode();
index = (hash & 0x7FFFFFFF) % tab.length;
}
// Creates the new entry.
//在这里封装Entry
@SuppressWarnings("unchecked")
Entry e = (Entry) tab[index];
//将封装的Entry传入table 数组
tab[index] = new Entry<>(hash, key, value, e);
count++;
} ②扩容
protected void rehash() {
int oldCapacity = table.length;
Entry[] oldMap = table;
// 在这里定义性的容量
int newCapacity = (oldCapacity << 1) + 1;
if (newCapacity - MAX_ARRAY_SIZE > 0) {
if (oldCapacity == MAX_ARRAY_SIZE)
// Keep running with MAX_ARRAY_SIZE buckets
return;
newCapacity = MAX_ARRAY_SIZE;
}
//在这里进行真正的扩容
Entry[] newMap = new Entry[newCapacity];
modCount++;
threshold = (int)Math.min(newCapacity * loadFactor, MAX_ARRAY_SIZE + 1);
table = newMap;
for (int i = oldCapacity ; i-- > 0 ;) {
for (Entry old = (Entry)oldMap[i] ; old != null ; ) {
Entry e = old;
old = old.next;
int index = (e.hash & 0x7FFFFFFF) % newCapacity;
e.next = (Entry)newMap[index];
newMap[index] = e;
}
}
} 3)HashMap与HashTable的对比

4.properties实现类
特点:
①Properties类继承自Hashtable并实现了Map接口,它也是以一种键值对的形式保存数据。
②使用特点与Hashtable相似。
③Properties还可以用于从xxx.properties 配置文件中,加载到Properties类对象,进行读取和修改。
5.TreeMap实现类(⭐)
特点:TreeMap实现了Map接口,底层是红黑树,TreeMap通过构造方法传入比较器,他的键可以排序的。
1)底层机制
①TreeMap底层的Key和Val是Entry形式的。而不是与HashMap类似的Node。
② TreeMap.add添加时判断Key是否相等是比较器决定的,与HashMap不同(hashcode和equals)
②使用默认构造器创建的TreeMap还是无序的。
③也可以传入Comparator接口,定义比较规则。
2)源码解析
①构造器,把传入的实现了Comparator接口的匿名内部类,传给了TreeMap的Comparator属性

②put方法
public V put(K key, V value) {
Entry t = root;
//第一次添加,将k-v封装到entry对象中,放入到root
if (t == null) {
compare(key, key); // type (and possibly null) check
root = new Entry<>(key, value, null);
size = 1;
modCount++;
return null;
}
int cmp;
Entry parent;
// split comparator and comparable paths
Comparator cpr = comparator;
//root不为空,启用比较器的添加
if (cpr != null) {
//遍历整个数据,根据比较器寻找合适位置添加
do {
parent = t;
//动态绑定,使用比较器的compare方法
cmp = cpr.compare(key, t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
//如果遍历过程中,发现准备添加的key与当前已有的key相等,直接返回
else
return t.setValue(value);
} while (t != null);
}
else {
if (key == null)
throw new NullPointerException();
@SuppressWarnings("unchecked")
Comparable k = (Comparable) key;
do {
parent = t;
cmp = k.compareTo(t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value);
} while (t != null);
}
Entry e = new Entry<>(key, value, parent);
if (cmp < 0)
parent.left = e;
else
parent.right = e;
fixAfterInsertion(e);
size++;
modCount++;
return null;
}