JavaSE——day14集合Set、Map及其分支
Set集合是一个不包含重复元素的集合,Set集合的代表就是hashSet集合。
Set集合不包含满足e1.equals(e2)的元素对e1,e2,并且最多包含一个null元素。不保证Set的迭代顺序恒久不变,即无序的(底层哈希表和hashcide支持),不允许元素重复。
Set的子实现类HashSet的遍历使出例子:
import java.util.HashSet;
import java.util.Set;
/**
* Set集合中存储虽然是无序的,但是并不是随机的,而是根据hash表和hash码的支持。
* @author malaganguo
*
*/
public class Test1 {
public static void main(String[] args) {
//创建Set集合对象HashSet
Set set = new HashSet() ;
set.add("hello") ;
set.add("world") ;
set.add("java") ;
set.add("!") ;
set.add("ALOHA") ;
System.out.println("Set输出1: ");
for(String str :set) {
System.out.print(str+" ");
}
//遍历
System.out.println("\nSet输出2: ");
for(String str : set) {
System.out.print(str+" ");
}
}
}
结果:
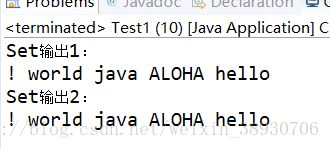 可与输入进行比较。
可与输入进行比较。
Set集合的HashSet集合的特点是按照我们看不见的哈希码和HashCode对元素进行存储,存储进去的就和我们输入的顺序不同了,而且会继承Set集合的特点:自动不保存重复元素。
LinkedHashSet
顾名思义:底层是一种链接列表和哈希表组成。
可以保证元素的唯一性,由哈希表决定(hashCode()和equals())。
可以保证元素的迭代顺序一致,存储和取出一致,由链表决定。
LinkedHashList集合具有可预知迭代顺序的Set接口的哈希表和链接列表的实现。此链接列表定义了迭代顺序,即按照将元素插入到 set 中的顺序进行迭代。注意:插入顺序不受在set中重新插入元素的影响。
此实现可以让客户免受未指定的、由HashSet提供的通常杂乱无章的操作。而又不至于引起与treeSet关联的成本增加。使用它可以生成一个与原来顺序相同的 set 副本,并且与原 set 的实现无关。
例子:
import java.util.LinkedHashSet;
public class Test2 {
public static void main(String[] args) {
LinkedHashSet lhs = new LinkedHashSet() ;
lhs.add(100);
lhs.add(10);
lhs.add(120);
lhs.add(14);
lhs.add(22);
lhs.add(22);
for(int a :lhs) {
System.out.print(a+ " ");
}
System.out.println();
}
}
结果:
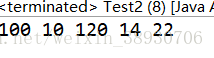 可见,我们已经删除了重复元素,并且元素的位置和我们输入的相同。
可见,我们已经删除了重复元素,并且元素的位置和我们输入的相同。
HashSet的add方法源码分析
inteface Collection{
}
interface Set extends Collection{
}
class HashSet implements Set{
private HashMap map;
//创建HashSet集合对象的时候,起始底层创建了一个HashMap集合对象
public HashSet() {
map = new HashMap<>();
}
public boolean add(E e) {
return map.put(e, PRESENT)==null; //add方法底层依赖于HashMap集合的
}
}
class HashMap implements Map{
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
//putVal方法
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node[] tab; Node p; int n, i; //Node是一种键值对对象
//判断哈希表示是为空,如果为空.有set集合元素的情况,哈希表不为空
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node e; K k; //k--->传入的元素
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
//一些判断,主要还是eqauls()方法
e = p; /e =p = key
else if (p instanceof TreeNode)
e = ((TreeNode)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key mapping:映射 (Servlet servlet-mapping)
V oldValue = e.value; //e.value=key ="hello" ,"world","java","world","java"
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue; //返回的oldValue:永远是第一次存储的哪个元素
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
}
哈希方法
static final int hash(Object key) { //传入的字符串元素 "hello","java","world" ,"hello"....
int h; //哈希码值
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); //无符号右移
底层依赖于第一个方法hashCode()
计算机底层运算数据:补码
}
HashSet集合的add方法底层依赖于双列集合HashMap,它依赖于两个方法,HashCode()方法和equals()方法
先比较字符串的HashCode()码值一样,再比较equals()方法
如果hasCode码值一样,还要比较内容是否相同,由于存储String,重写了equals()方法。但是如果Set集合中存储的是非String元素,如我们自己创建的对象,那么,我们需要在对象中重写equals()方法和hashCode()方法,这样,程序就可以正常运行。
TreeSet集合
| TreeSet集合的排序方法 |
| 1、自然排序法 |
| 2、比较器排序法 |
TreeSet集合是一种红黑树结构(自平衡二叉树)。实现依赖于TreeMap结构的实现,红黑树结构将存储的第一个元素作为根节点,然后的每一个元素与根节点进行比较,如果比根节点小,将方在根节点的左后方,如果比根节点大,就放在根节点的右下方,如果和根节点相等,那么,我们的Set结合的特性不会将这个元素存入集合中。总之,红黑树结构就是在不断生成子跟节点和进行比较的过程 ,最后我们从左往右的顺序就是元素从小到大的顺序,排序完成。
注意: 自定义的类必须实现Comparable接口,如果比较对象是基本类型的话,可以正常比较。但是如果比较的是对象的话,对象类必须得实现compareTo()方法的重写,因为compareTo方法默认比较的是地址值,所以在自定义类实现了Comparable接口后java会要求重写compareTo()方法,否则编译时期不通过。

例子:(自然排序)
自然排序如果排序的对象是一个自定义类的话,那么我们需要实现Comparable接口并且被强制重写compareTo()方法。然后创建TreeSet对象,通过无参构造的形式创建对象。
import java.util.TreeSet;
public class Test4 {
public static void main(String[] args) {
TreeSet ts = new TreeSet() ;
Obj o = new Obj("zhangyifei", 22);
Obj o1 = new Obj("aloha",22) ;
Obj o2 = new Obj("zhangyifei", 23) ;
Obj o3 = new Obj("nihao",22) ;
ts.add(o);
ts.add(o1);
ts.add(o2);
ts.add(o3);
System.out.println("排序结果");
for(Obj s : ts) {
System.out.println(s.getName()+ "---"+ s.getAge());
}
System.out.println();
}
}
class Obj implements Comparable{
private String name ;
private int age ;
public Obj() {
super();
}
public Obj(String name, int age) {
super();
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public int compareTo(Obj o) {
int num = this.age - o.age ;
int num2 = num == 0 ? this.name.compareTo(o.getName()) : num ;
return num2;
}
}
例子:(比较器排序)
构造方式不同,比较排序方法不同,比较器排序分为两种方式:第一种:自定义一个类实现Comparator接口,自定义类重写compareTo()方法。 第二种:使用匿名内部类。
第二种(使用匿名内部类)例子:
import java.util.Comparator;
import java.util.TreeSet;
/**
* 匿名内部类的TreeSet比较器比较例子
*
* 比较顺序
* 首先名字长度最短的
* 然后安排名字值小的
* 然后安排年龄大小
* @author malaganguo
*
*/
public class Test1 {
public static void main(String[] args) {
//创建比较器对象
//构造方法的参数选择使用Comparator接口的匿名内部类
TreeSet ts = new TreeSet(new Comparator() {
//在匿名内部类中重写比较方法
@Override
public int compare(Student o1, Student o2) {
//按姓名长度进行比较
int num = o1.getName().length() - o2.getName().length() ;
//按姓名内容进行比较
int num2 = num == 0? o1.getName().compareTo(o2.getName()) : num ;
//按年龄进行比较
int num3 = num2 == 0 ? o1.getAge() - o2.getAge() : num2 ;
return num3;
}
});
//创建学生对象
Student s1 = new Student("aloha", 22);
Student s2 = new Student("nihao", 20);
Student s3 = new Student("sugarcane", 15);
Student s4 = new Student("live", 28);
Student s5 = new Student("constant", 22);
Student s6 = new Student("constant", 23);
//将对象加入集合
ts.add(s1) ;
ts.add(s2) ;
ts.add(s3) ;
ts.add(s4) ;
ts.add(s5) ;
ts.add(s6) ;
//遍历
for(Student s : ts) {
System.out.println(s.getName() + "---" + s.getAge() );
}
}
}
class Student {
private String name ;
private int age ;
public Student() {
super();
}
public Student(String name, int age) {
super();
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
} 匿名内部类的好处是,不需要创建一个单独的类来实现Comparator接口的功能,使程序简化。
Map集合
Map集合 ,键值的映射关系的一种集合(接口)。将键映射到值的对象。一个映射不能包含重复的键;每个键最多只能映射到一个值。Map
Map接口的功能:
V put(K key,V value) :添加功能:将指定的值和键关联起来
如果当前的这个键是一次存储,则返回值null
如果不是第一次存储,返回值是第一次对应的值,当前的值就把之前的键对应的值替换掉!
获取功能
Set
Set
int size()返回此映射中的键-值映射关系数
删除功能
void clear():删除所有映射关系
V remove(Object key)如果存在一个键的映射关系,则将其从此映射中移除
判断功能:
boolean containsKey(Object key)如果此映射包含指定键的映射关系,则返回 true
boolean containsValue(Object value):映射关系中是否包含指定的值
boolean isEmpty():判断映射关系是否为空
代码区(模块化):
添加功能:
//创建集合
HashMap hm = new HashMap() ;
//添加功能:将指定的值和键关联起来
//我们创建一个hm型变量来保存一下第一次存储的返回值,存储不同的键值对返回值为null
String firstReturn = hm.put("1", "one");
hm.put("3", "three");
hm.put("5", "five");
hm.put("4", "four");
hm.put("2", "two");
//那么,存储相同键值对呢? 返回的是上一次存储元素的值
String resaveReturn = hm.put("1", "我重新存了一遍!") ;
System.out.println("firstReturn = "+ firstReturn);
System.out.println("resaveReturn = "+ resaveReturn);
获取功能1:
//获取功能(和遍历有关)
//获取所有键值对对象
Set> entrySet = hm.entrySet();
//遍历
for(Map.Entry map : entrySet) {
String key = map.getKey() ;
String value = map.getValue() ;
System.out.println(key + "=" + value );
}
获取功能2:
//获取功能2
//获取键值对集合
Set setKey = hm.keySet() ;
//遍历
for(String key : setKey) {
String value = hm.get(key) ;//得到键对应的值
System.out.println(key+ "=" + value );
}
删除功能:
//删除功能:返回该键对应的值
System.out.println("删除结果: "+hm.remove("1") );
暴力删除功能:clear不做演示了
获取键值映射关系数:
//获取键值映射关系数
int num = hm.size() ;
System.out.println("键值映射关系数: "+ num );
判断功能:
//判断功能
boolean isEmpty = hm.isEmpty() ;
System.out.println("是空的吗? "+ isEmpty);
boolean containsKey = hm.containsKey("1");
System.out.println("包含1键值吗? " +containsKey);
boolean containsValue1 = hm.containsValue("four") ;
System.out.println("包含five这个值吗? " + containsValue1);
boolean containsValue2 = hm.containsValue("six") ;
System.out.println("包含six这个值吗? " + containsValue2);
结果:

HashMap集合
HashMap集合基于哈希表,可以保证键的唯一性。哈希表:依赖于hashCode()和equals()方法。
格式: HashMap
例子:(部分代码)
@Test
public void hashmap() {
HashMap hm = new HashMap() ;
hm.put("A001", "aloha") ;
hm.put("A002", "你好") ;
hm.put("A005", "hello") ;
hm.put("A003", "hi") ;
hm.put("A001", "ALOHA") ;
Set keySet = hm.keySet();
for(String key : keySet) {
String value = hm.get(key) ;
System.out.println(key + "---"+value);
}
} 运行结果:
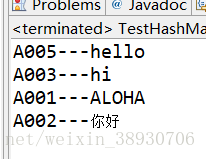
因为底层是哈希表支持的,所以根据哈希表的存储特点该集合的存储也是看似无序的,HashMap集合保证了键值的唯一性,所以后面的A001的键值对覆盖了前面的A001的键值对,就出现了上面的结果。
Map集合可以用普通包装类型作为键或者值,也可以使用自定义类型作为键或者值,下面是自定义对象Student作为键的部分代码:
public void hashmap() {
//创建对象
HashMap hm = new HashMap() ;
Student s1 = new Student("A001", "ALOHA");
Student s2 = new Student("A002", "你好");
Student s3 = new Student("A005", "hello");
Student s4 = new Student("A003", "hi");
Student s5 = new Student("A001", "ALOHA");
//添加键值对
hm.put(s1,"1") ;
hm.put(s2,"2") ;
hm.put(s3,"3") ;
hm.put(s4,"4") ;
hm.put(s5,"1") ;
//遍历
Set keySet = hm.keySet();
for(Student key : keySet) {
String value = hm.get(key) ;
System.out.println(key.getNum()+ "---"+key.getName() + "---"+value);
}
} 结果:

可以看到,我们用对象作为键时,虽然对象s1和s5的内容是一样的,但是他们却是不同的对象。因为对象作为键没有重复的写入到HashMap集合中,所以是可以输出两个A001---ALOHA---1的。
HashMap集合的键如果是自定义类对象的话,如果我们需要体现HashMap集合的特性,需要重写hashCode()和equals()方法。这样就不会有重读的键值了。
重写以后的结果:

LinkedHashMap集合
顾名思义,此集合即是Map接口基于哈希表和Linked链接链表实现的——保证键值唯一性和元素的有序性。
TreeMap集合
基于红黑树的Map接口的实现类,可以实现按需排序去重的功能。
例子:
import java.util.Comparator;
import java.util.Set;
import java.util.TreeMap;
import org.junit.Test;
/**
*TreeMap存储自定义类型
*TreeMap
* 主要条件:年龄从小到大
*
*/
public class TestTreeMap {
@Test
public void treemap() {
//创建TreeMap集合对象
TreeMap tm = new TreeMap(new Comparator() {
@Override
public int compare(DemoClass o1, DemoClass o2) {
int num = o1.getAge() - o2.getAge() ;
int num2 = num == 0? o1.getName().compareTo(o2.getName()) : num ;
return num2;
}
});
//创建DemoClass对象
DemoClass dc1 = new DemoClass("aloha" , 25) ;
DemoClass dc2 = new DemoClass("nihao" , 23) ;
DemoClass dc3 = new DemoClass("hello" , 22) ;
DemoClass dc4 = new DemoClass("hi" , 21) ;
DemoClass dc5 = new DemoClass("你好" , 27) ;
tm.put(dc1, "1");
tm.put(dc2, "2");
tm.put(dc3, "3");
tm.put(dc4, "4");
tm.put(dc5, "5");
System.out.println("name\tage\tString\n");
Set keySet = tm.keySet();
for(DemoClass key : keySet) {
String value = tm.get(key) ;
System.out.println(key.getName()+"\t"+key.getAge()+"\t"+value);
}
}
}
//创建DemoClass内部类
class DemoClass{
private String name ;
private int age ;
public DemoClass() {
super();
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public DemoClass(String name, int age) {
super();
this.name = name;
this.age = age;
}
} 拓展:
关于集合的嵌套,我们可以使用集合的嵌套得到我们需要的大集合包含小集合的关系。比如ArrayList集合中嵌套ArrayList集合,HashMap集合中嵌套HashMap集合等等等等,可以实现拓展功能。
HashMap和Hashtable的区别:
共同点:都是map接口的实现类,都是基于哈希表的实现类
不同点:1、 HashMap线程不安全,不同步,执行效率高允许K和V是null。
2、 Hashtable线程安全,同步,执行效率低,不允许K和V为null。
综合应用
package com.day15.mapApplication;
import java.util.HashMap;
import java.util.Scanner;
import java.util.Set;
/**
* 练习:手动输入一个字符串,求字符串中每个字符出现的次数以 字符(次数)字符(次数)...的格式输出出来
* @author malaganguo
*
*/
public class TestApplication {
public static void main(String[] args) {
//创建键盘录入对象
Scanner sc = new Scanner(System.in) ;
System.out.print("请输入一个待分析字符串:\n");
String input = sc.nextLine() ;
//将字符串转换为字符数组
char[] charArray = input.toCharArray();
/**
* 需求分析:
* 因为统计重复字符的个数,所以我们可以创建一个Map接口的子实现类,这个实现类的K为Character类型,是待统计的字符
* V为Integer类型,是这个Key出现的次数
* 保证唯一性,使用HashMap集合存储
*
* 遍历,将字符和出现次数获取出来
*/
//创建集合容器
HashMap hm = new HashMap() ;
//遍历获取需要的信息
for(char ch : charArray) {
Integer i = hm.get(ch) ;//得到每一个字符的值。
hm.put(ch, i) ;
if(i == null ) {//如果是第一次存储
hm.put(ch, 1) ;
}else {
i++;
hm.put(ch, i) ;
}
}
//创建StringBuffer单线程字符串缓冲池
StringBuilder sb = new StringBuilder() ;
//遍历集合并
Set keySet = hm.keySet();
for(char key :keySet) {
//因为HashMap集合不会存储重复的键,所以我们遍历的是键值对是 字符---出现次数
sb.append(key).append("(").append(hm.get(key)).append(")") ;
}
//将StringBuilder加入转换成string并输出
String string = sb.toString();
System.out.println(string);
}
}