base on open jdk 1.8
Java并发编程的艺术笔记
- 1.并发编程的挑战
- 2.Java并发机制的底层实现原理
- 3.Java内存模型
- 4.Java并发编程基础
- 5.Java中的锁的使用和实现介绍
- 6.Java并发容器和框架
- 7.Java中的12个原子操作类介绍
- 8.Java中的并发工具类
- 9.Java中的线程池
- 10.Executor框架
目录
ConcurrentHashMapConcureentLinkedQueueJava中的阻塞队列Fork / Join 框架小结
ConcurrentHashMap
为什么要使用 ConcurrentHashMap
原因有三:并发编程中HashMap会导致死循环;HashTable效率又非常低;ConcurrentHashMap的锁分段技术可有效提升并发访问率。
-
在并发编程使用
HashMap会导致死循环。
在多线程环境下,使用HashMap进行put操作会引起 死循环,导致CPU利用率接近100%,所以在并发情况下不能使用HashMap。
是因为多线程会导致HashMap的Entry链表形成 环形数据结构,一旦形成环形数据结构,Entry的next节点永远不为空,就会产生死循环获取Entry。
以下代码就会导致死循环(java se 5):public static void main(String[] args) throws InterruptedException { long time = System.currentTimeMillis(); HashMap 线程安全的
HashTable效率非常低。
HashTable容器使用synchronized来保证线程安全,但在线程竞争激烈的情况下HashTable的效率非常低下。因为当一个线程访问HashTable的同步方法,其他线程也访问HashTable的同步方法时,会进入阻塞或轮询状态。如线程1使用put进行元素添加,线程2不但不能使用put方法添加元素,也不能使用get方法来获取元素,所以竞争越激烈效率越低。ConcurrentHashMap的锁分段技术可有效提升并发访问率
HashTable容器在竞争激烈的并发环境下表现出效率低下的原因是 所有访问HashTable的线程都必须竞争同一把锁。
而ConcurrentHashMap所使用的锁分段技术将数据分成一段一段地存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据的时候,其他段的数据也能被其他线程访问。
基于 jdk_1.8.0_77 的介绍:ConcurrentHashMap源码解析
ConcureentLinkedQueue
在并发编程中,有时候需要使用线程安全的队列。
如果要实现一个线程安全的队列有两种方式:
- 使用阻塞算法:使用阻塞算法的队列可以用一个锁(入队和出队用同一把锁)或两个锁(入队和出队用不同的锁)等方式来实现。
- 使用非阻塞算法:非阻塞的实现方式则可以使用循环CAS的方式来实现。
ConcurrentLinkedQueue是一个基于链接节点的无界线程安全队列,它采用FIFO的规则对节点进行排序,当我们添加一个元素的时候,它会添加到队列的尾部;当我们获取一个元素时,它会返回队列头部的元素。它采用了“wait-free”算法(即CAS算法)来实现,该算法在Michael&Scott算法上进行了一些修改。
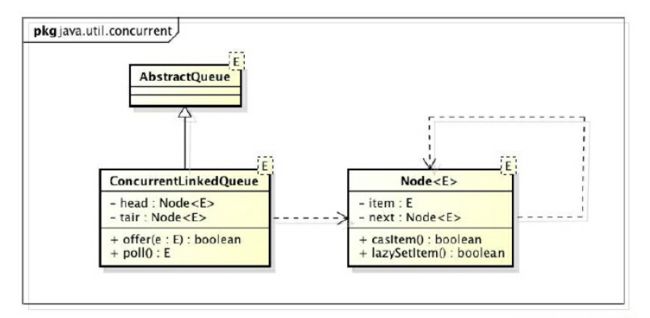
ConcurrentLinkedQueue由head节点和tail节点组成,每个节点Node由节点元素item和指向下一个节点next的引用组成,节点与节点之间就是通过这个next关联起来,从而组成一张链表结构的队列。
默认情况下head节点存储的元素为空,tail节点等于head节点。
transient volatile Node head;
private transient volatile Node tail;
入队列
入队列就是将入队节点添加到队列的尾部。
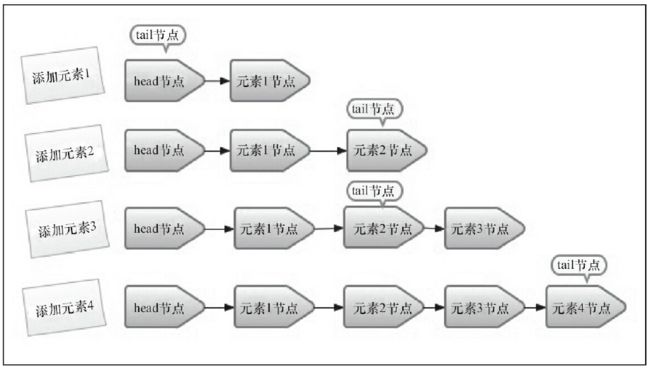
-
添加元素1:队列更新head节点的next节点为元素1节点。又因为tail节点默认情况下等于head节点,所以它们的next节点都指向元素1节点。 -
添加元素2:队列首先设置元素1节点的next节点为元素2节点,然后更新tail节点指向元素2节点。 -
添加元素3:设置tail节点的next节点为元素3节点。 -
添加元素4:设置元素3的next节点为元素4节点,然后将tail节点指向元素4节点。
通过上图我们发现,入队主要做两件事情:
- 将入队节点设置成当前队列尾节点的下一个节点
- 更新
tail节点,如果tail节点的next节点不为空,则将入队节点设置成tail节点,如果tail节点的next节点为空,则将入队节点设置成tail的next节点,所以tail节点不总是尾节点
以下是入队列的源码:
public boolean add(E e) {
return offer(e);
}
public boolean offer(E e) {
final Node newNode = newNode(Objects.requireNonNull(e));
for (Node t = tail, p = t;;) {
Node q = p.next;
if (q == null) {
// p is last node
if (casNext(p, null, newNode)) {
if (p != t) // hop two nodes at a time
casTail(t, newNode); // Failure is OK.
return true;
}
}
else if (p == q)
p = (t != (t = tail)) ? t : head;
else
// Check for tail updates after two hops.
p = (p != t && t != (t = tail)) ? t : q;
}
}
- 构建了一个新的节点
newNode - 如果
tail节点的next节点为空,则通过CAS将newNode设置为tail的next节点,设置成功之后,在更新tail为newNode节点。 - 否则继续重试上一步。
出队列
出队列的就是从队列里返回一个节点元素,并清空该节点对元素的引用。

以下是出队列的源码:
public E poll() {
restartFromHead:
for (;;) {
for (Node h = head, p = h, q;;) {
E item = p.item;
if (item != null && casItem(p, item, null)) {
if (p != h) // hop two nodes at a time
updateHead(h, ((q = p.next) != null) ? q : p);
return item;
}
else if ((q = p.next) == null) {
updateHead(h, p);
return null;
}
else if (p == q)
continue restartFromHead;
else
p = q;
}
}
}
首先获取head节点的元素item,然后判断是否为空?
- 如果为空,表示另外一个线程已经进行了一次出队操作将该节点的元素取走。
- 如果不为空,则使用
CAS的方式将头节点的引用设置成null,如果CAS成功,则直接返回头节点的元素item,如果不成功,表示另外一个线程已经进行了一次出队操作更新了head节点,导致元素发生了变化,需要重新获取头节点。
Java中的阻塞队列
什么是阻塞队列
阻塞队列(BlockingQueue)是一个支持以下两个附加操作的队列:
- 支持阻塞的插入方法:当队列满时,队列会阻塞插入元素的线程,直到队列不满。
- 支持阻塞的移除方法:在队列为空时,获取元素的线程会等待队列变为非空。
阻塞队列常用于生产者和消费者的场景,生产者是向队列里添加元素的线程,消费者是从队列里取元素的线程。阻塞队列就是生产者用来存放元素、消费者用来获取元素的容器。
在阻塞队列不可用时,这两个附加操作提供了以下4种处理方式:
| 方法/处理方式 | 抛出异常 | 返回特殊值 | 一直阻塞 | 超时退出 |
|---|---|---|---|---|
| 插入方法 | add(e) |
offer(e) |
put(e) |
offer(e, time, unit) |
| 移除方法 | remove() |
poll() |
take() |
poll(time, unit) |
| 检查方法 | element() |
peek() |
不可用 | 不可用 |
- 抛出异常:队列满时,再添加元素,会抛出
IllegalStateException("Queue full")异常;当队列为空时,从队列里获取元素会抛出NoSuchElementException异常。 - 返回特殊值:往队列插入元素时,返回
ture表示插入成功。从队列里移除元素,即取出元素,如果没有则返回null。 - 一直阻塞:当阻塞队列满时,如果生产者线程往队列里
put元素,队列会一直阻塞生产者线程,直到队列可用或者响应中断退出。当队列空时,如果消费者线程从队列里take元素,队列会阻塞住消费者线程,直到队列不为空。 - 超时退出:当阻塞队列满时,如果生产者线程往队列里插入元素,队列会阻塞生产者线程一段时间,如果超过了指定的时间
time,生产者线程就会退出。
如果是无界阻塞队列,队列不可能会出现满的情况,所以使用
put或offer方法永远不会被阻塞,而且使用offer方法时,该方法永远返回true。
Java里的阻塞队列
-
ArrayBlockingQueue:一个由 数组 结构组成的 有界 阻塞队列。
按照FIFO的原则对元素进行排序。
默认情况下不保证线程公平的访问队列。
公平访问 队列是指阻塞的线程,可以 按照阻塞的先后顺序访问队列,即先阻塞线程先访问队列。
非公平性是对先等待的线程是非公平的,当队列可用时,阻塞的线程都有争夺访问队列的资格,有可能先阻塞的线程最后才访问队列。
为了保证公平性,通常会降低吞吐量。我们可以使用以下代码创建一个公平的阻塞队列:ArrayBlockingQueue fairQueue = new ArrayBlockingQueue(1000,true); public ArrayBlockingQueue(int capacity, boolean fair) { if (capacity <= 0) throw new IllegalArgumentException(); this.items = new Object[capacity]; lock = new ReentrantLock(fair); notEmpty = lock.newCondition(); notFull = lock.newCondition(); }访问者的公平性是使用 可重入锁 实现的。
LinkedBlockingQueue:一个由 链表 结构组成的 有界 阻塞队列。
此队列的默认和最大长度为Integer.MAX_VALUE。此队列按照FIFO的原则对元素进行排序。PriorityBlockingQueue:一个支持优先级排序的 无界 阻塞队列。
默认情况下元素采取 自然顺序升序排列。
也可以自定义类实现compareTo()方法来指定元素排序规则,或者初始化PriorityBlockingQueue时,指定构造参数Comparator来对元素进行排序。需要注意的是不能保证同优先级元素的顺序。-
DelayQueue:一个使用优先级队列实现的 无界 阻塞队列。
DelayQueue是一个支持 延时获取元素 的 无界 阻塞队列。
队列使用PriorityQueue来实现。队列中的元素必须实现Delayed接口,在创建元素时可以指定多久才能从队列中获取当前元素。只有在延迟期满时才能从队列中提取元素。
可以将DelayQueue运用在以下应用场景:- 缓存系统的设计:可以用
DelayQueue保存缓存元素的有效期,使用一个线程循环查询DelayQueue,一旦能从DelayQueue中获取元素时,表示缓存有效期到了。 - 定时任务调度:使用
DelayQueue保存当天将会执行的任务和执行时间,一旦从DelayQueue中获取到任务就开始执行,比如TimerQueue就是使用DelayQueue实现的。
DelayQueue的使用,可以参考ScheduledThreadPoolExecutor里ScheduledFutureTask类的实现:- 在对象创建的时候,初始化基本数据。
private static final AtomicLong sequencer = new AtomicLong(); ScheduledFutureTask(Runnable r, V result, long ns, long period) { super(r, result); this.time = ns; this.period = period; this.sequenceNumber = sequencer.getAndIncrement(); }- 实现
getDelay方法,该方法返回当前元素还需要延时多长时间,单位是纳秒。
public long getDelay(TimeUnit unit) { return unit.convert(time - now(), TimeUnit.NANOSECONDS); }- 实现
compareTo方法来指定元素的顺序。
public int compareTo(Delayed other) { if (other == this) { // compare zero ONLY if same object return 0; } if (other instanceof ScheduledFutureTask) { ScheduledFutureTask x = (ScheduledFutureTask) other; long diff = time - x.time; if (diff < 0L) { return -1; } else if (diff > 0L) { return 1; } else { return sequenceNumber < x.sequenceNumber ? -1 : 1; } } else { long d = getDelay(TimeUnit.NANOSECONDS) - other.getDelay(TimeUnit.NANOSECONDS); return Long.compare(d, 0L); } }如何实现延时阻塞队列?
public E take() throws InterruptedException { final ReentrantLock lock = this.lock; lock.lockInterruptibly(); try { for (;;) { E first = q.peek(); if (first == null) available.await(); else { long delay = first.getDelay(NANOSECONDS); if (delay <= 0L) return q.poll(); first = null; // don't retain ref while waiting if (leader != null)//变量leader是一个等待获取队列头部元素的线程 available.await(); else { Thread thisThread = Thread.currentThread(); leader = thisThread; try { available.awaitNanos(delay); } finally { if (leader == thisThread) leader = null; } } } } } finally { if (leader == null && q.peek() != null) available.signal(); lock.unlock(); } }变量
leader是一个等待获取队列头部元素的线程。
如果leader != null,表示已经有线程在等待获取队列的头元素。所以,使用await()方法让当前线程等待信号。
如果leader == null,则把当前线程设置成leader,并使用awaitNanos()方法让当前线程等待接收信号或等待delay时间。 - 缓存系统的设计:可以用
-
SynchronousQueue:一个 不存储 元素的阻塞队列。
每一个put操作必须等待一个take操作,否则不能继续添加元素。
使用以下构造方法的fair来创建是否公平性访问的SynchronousQueue,如果设置为true,则等待的线程会采用FIFO的顺序访问队列。public SynchronousQueue(boolean fair) { transferer = fair ? new TransferQueue() : new TransferStack (); } SynchronousQueue可以看成是一个传球手,负责把生产者线程处理的数据直接传递给消费者线程。
队列本身并不存储任何元素,非常适合传递性场景。
SynchronousQueue的吞吐量高于LinkedBlockingQueue和ArrayBlockingQueue。 -
LinkedTransferQueue:一个由 链表 结构组成的 无界 阻塞队列。
相对于其他阻塞队列,LinkedTransferQueue多了tryTransfer和transfer方法。-
transfer
如果当前有消费者正在等待接收元素(take()或poll(long timeout, TimeUnit unit)),transfer方法可以把生产者传入的元素立刻transfer(传输)给消费者。
如果没有消费者在等待接收元素,transfer方法会将元素存放在队列的tail节点,并等到该元素被消费者消费了才返回。
transfer方法的关键代码如下:
Node pred = tryAppend(s, haveData); ... return awaitMatch(s, pred, e, (how == TIMED), nanos);第一行代码是试图把存放当前元素的
s节点作为tail节点。
第二行代码是让CPU自旋等待消费者消费元素。因为自旋会消耗CPU,所以自旋一定的次数后使用Thread.yield()方法来暂停当前正在执行的线程,并执行其他线程。-
tryTransfer
tryTransfer(E e)方法是用来试探生产者传入的元素是否能直接传给消费者。如果没有消费者等待接收元素,则返回false。
和transfer方法的区别是tryTransfer(E e)方法无论消费者是否接收,方法立即返回,而transfer方法是必须等到消费者消费了才返回。
对于带有时间限制的tryTransfer(E e, long timeout, TimeUnit unit)方法,相当于在timeout时间内进行tryTransfer(E e),如果超时还没消费元素,则返回false,如果在超时时间内消费了元素,则返回true。
-
LinkedBlockingDeque:一个由 链表 结构组成的 双向 阻塞队列。
所谓双向队列指的是可以从队列的两端插入和移出元素。双向队列因为多了一个操作队列的入口,在多线程同时入队时,也就减少了一半的竞争。
相比其他的阻塞队列,LinkedBlockingDeque多了addFirst、addLast、offerFirst、offerLast、peekFirst和peekLast等方法。
以First单词结尾的方法,表示插入、获取(peek)或移除双端队列的 第一个元素。
以Last单词结尾的方法,表示插入、获取或移除双端队列的 最后一个元素。
阻塞队列的实现原理
即为使用 通知模式 实现。就是当生产者往满的队列里添加元素时会阻塞住生产者,当消费者消费了一个队列中的元素后,会通知生产者当前队列可用。
以下是ArrayBlockingQueue的相关代码,我们可以看到它是用Condition来实现的:
public ArrayBlockingQueue(int capacity, boolean fair) {
...
notEmpty = lock.newCondition();
notFull = lock.newCondition();
}
public void put(E e) throws InterruptedException {
Objects.requireNonNull(e);
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
while (count == items.length)
notFull.await();
enqueue(e);
} finally {
lock.unlock();
}
}
public E take() throws InterruptedException {
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
while (count == 0)
notEmpty.await();
return dequeue();
} finally {
lock.unlock();
}
}
private void enqueue(E x) {
// assert lock.getHoldCount() == 1;
// assert items[putIndex] == null;
final Object[] items = this.items;
items[putIndex] = x;
if (++putIndex == items.length) putIndex = 0;
count++;
notEmpty.signal();
}
private E dequeue() {
// assert lock.getHoldCount() == 1;
// assert items[takeIndex] != null;
final Object[] items = this.items;
@SuppressWarnings("unchecked")
E x = (E) items[takeIndex];
items[takeIndex] = null;
if (++takeIndex == items.length) takeIndex = 0;
count--;
if (itrs != null)
itrs.elementDequeued();
notFull.signal();
return x;
}
Fork / Join 框架
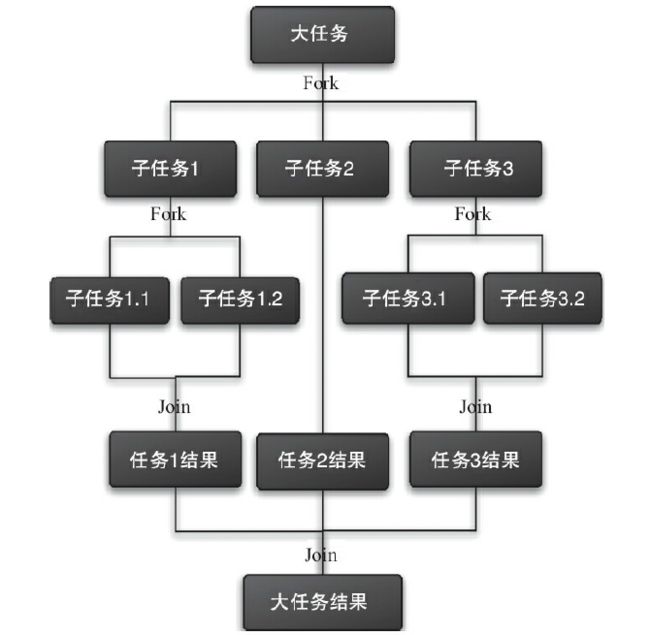
Fork/Join框架是 Java 7提供的一个用于并行执行任务的框架,是一个 把大任务分割成若干个小任务,最终汇总每个小任务结果后得到大任务结果 的框架。
比如计算1+2+…+10000;可以分割成10个子任务,每个子任务分别对1000个数进行求和,最终汇总这10个子任务的结果。
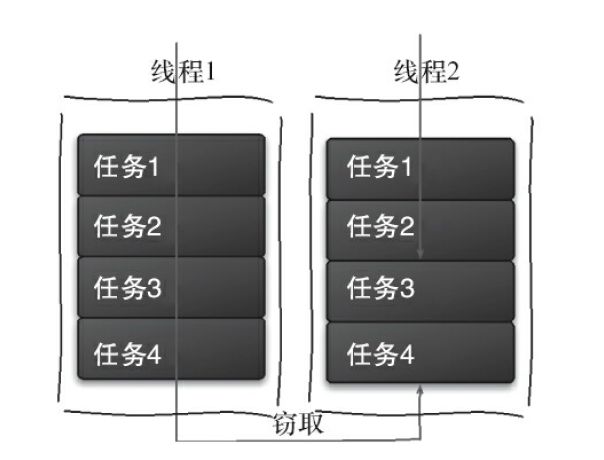
工作窃取算法
工作窃取(work-stealing)算法是指某个线程从其他队列里窃取任务来执行。
比如 我们把一个大任务分成 10 个小任务 让 10个线程分别执行一个任务,可能线程1执行的任务很快就完成了,线程2 执行的比较慢,这时候线程1就可以去线程2的任务队列里面去取任务来继续工作,以提高效率。
工作窃取算法的优缺点:
- 优点:充分利用线程进行并行计算,减少了线程间的竞争。
- 缺点:在某些情况下还是存在竞争,比如双端队列里只有一个任务时。并且该算法会消耗了更多的系统资源,比如创建多个线程和多个双端队列。
Fork/Join框架的设计
- 分割任务
- 执行任务并合并结果
Fork/Join使用以下两个类来完成以上两件事情:
-
ForkJoinTask
我们要使用ForkJoin框架,必须首先创建一个ForkJoin任务。
它提供在任务中执行fork()和join()操作的机制。
通常情况下,我们不需要直接继承ForkJoinTask类,只需要继承它的子类,Fork/Join框架提供了以下两个子类:-
RecursiveAction:用于没有返回结果的任务。 -
RecursiveTask:用于有返回结果的任务。
-
ForkJoinPool
ForkJoinTask需要通过ForkJoinPool来执行。
任务分割出的子任务会添加到当前工作线程所维护的双端队列中,进入队列的头部。
当一个工作线程的队列里暂时没有任务时,它会随机从其他工作线程的队列的尾部获取一个任务。
使用Fork/Join框架
以下示例为使用Fork/Join框架计算 1+2+3+4 ,设置的分割的阈值是2,即1+2+3+4会被分割为1+2 和 3+4两个任务,因为有返回结果,所以我们需要使用RecursiceTask:
public class TestRecursiveTask extends RecursiveTask {
/**
* 阈值
*/
private static final int THRESHOLD = 2;
private int start;
private int end;
public TestRecursiveTask(int start, int end) {
this.start = start;
this.end = end;
}
public static void main(String[] args) {
ForkJoinPool forkJoinPool = new ForkJoinPool();
// 生成一个计算任务,负责计算1+2+3+4
TestRecursiveTask task = new TestRecursiveTask(1, 4);
// 执行一个任务
Future result = forkJoinPool.submit(task);
try {
System.out.println(result.get());
} catch (Exception e) {
e.printStackTrace();
}
}
@Override
protected Integer compute() {
int sum = 0;
// 如果任务足够小就计算任务
boolean canCompute = (end - start) <= THRESHOLD;
System.out.println(start + "---" + end);
if (canCompute) {
for (int i = start; i <= end; i++) {
sum += i;
}
} else {
// 如果任务大于阈值,就分裂成两个子任务计算
int middle = (start + end) / 2;
TestRecursiveTask leftTask = new TestRecursiveTask(start, middle);
TestRecursiveTask rightTask = new TestRecursiveTask(middle + 1, end);
// 执行子任务
leftTask.fork();
rightTask.fork();
// 等待子任务执行完,并得到其结果
int leftResult = leftTask.join();
int rightResult = rightTask.join();
// 合并子任务
sum = leftResult + rightResult;
}
return sum;
}
}
输出结果:
1---4
1---2
3---4
10
通过这个例子,我们进一步了解ForkJoinTask,ForkJoinTask与一般任务的主要区别在于它需要实现compute方法,在这个方法里,首先需要判断任务是否足够小,如果足够小就直接执行任务。如果不足够小,就必须分割成两个子任务,每个子任务在调用fork方法时,又会进入compute方法,看看当前子任务是否需要继续分割成子任务,如果不需要继续分割,则执行当前子任务并返回结果。使用join方法会等待子任务执行完并得到其结果。
Fork/Join框架的异常处理
ForkJoinTask在执行的时候可能会抛出异常,但是我们没办法在主线程里直接捕获异常,所以ForkJoinTask提供了isCompletedAbnormally()方法来检查任务是否已经抛出异常或已经被取消了,并且可以通过ForkJoinTask的getException方法获取异常。
代码如下:
if (task.isCompletedAbnormally()) {
System.out.println(task.getException());
}
getException方法返回Throwable对象,如果任务被取消了则返回CancellationException。如果任务没有完成或者没有抛出异常则返回null。
Fork/Join框架的实现原理
ForkJoinPool由ForkJoinTask数组和ForkJoinWorkerThread数组组成,ForkJoinTask数组负责将存放程序提交给ForkJoinPool的任务,而ForkJoinWorkerThread数组负责执行这些任务。
-
ForkJoinTask的fork方法实现原理:public final ForkJoinTaskfork() { Thread t; if ((t = Thread.currentThread()) instanceof ForkJoinWorkerThread) ((ForkJoinWorkerThread)t).workQueue.push(this); else ForkJoinPool.common.externalPush(this); return this; } workQueue.push方法源码:- 通过
a[(al - 1) & s] = task;把任务存入数组里 - 然后通过
p.signalWork();来唤醒一个工作线程来执行任务
final void push(ForkJoinTask task) { U.storeFence(); // ensure safe publication int s = top, al, d; ForkJoinTask[] a; if ((a = array) != null && (al = a.length) > 0) { a[(al - 1) & s] = task; // relaxed writes OK top = s + 1; ForkJoinPool p = pool; if ((d = base - s) == 0 && p != null) { U.fullFence(); p.signalWork(); } else if (al + d == 1) growArray(); } }common.externalPush方法源码:- 通过
q.sharedPush(task)把任务存入数组 - 然后通过
signalWork();来唤醒一个工作线程来执行任务
final void externalPush(ForkJoinTask task) { ... for (;;) { WorkQueue q; int wl, k, stat; int rs = runState; WorkQueue[] ws = workQueues; if (rs <= 0 || ws == null || (wl = ws.length) <= 0) tryInitialize(true); else if ((q = ws[k = (wl - 1) & r & SQMASK]) == null) tryCreateExternalQueue(k); else if ((stat = q.sharedPush(task)) < 0) break; else if (stat == 0) { signalWork(); break; } else // move if busy r = ThreadLocalRandom.advanceProbe(r); } } final int sharedPush(ForkJoinTask task) { int stat; if (U.compareAndSwapInt(this, QLOCK, 0, 1)) { int b = base, s = top, al, d; ForkJoinTask[] a; if ((a = array) != null && (al = a.length) > 0 && al - 1 + (d = b - s) > 0) { a[(al - 1) & s] = task; top = s + 1; // relaxed writes OK here qlock = 0; stat = (d < 0 && b == base) ? d : 0; } else { growAndSharedPush(task); stat = 0; } } else stat = 1; return stat; }-
ForkJoinTask的join方法实现原理
任务是已完成状态的话就返回子类重写的getRawResult()的值。
public final V join() { int s; if ((s = doJoin() & DONE_MASK) != NORMAL) reportException(s); return getRawResult(); } private void reportException(int s) { if (s == CANCELLED) throw new CancellationException(); if (s == EXCEPTIONAL) rethrow(getThrowableException()); } public abstract V getRawResult();通过
doJoin()获取任务的状态。static final int NORMAL = 0xf0000000; // must be negative 已完成 static final int CANCELLED = 0xc0000000; // must be < NORMAL 被取消 static final int EXCEPTIONAL = 0x80000000; // must be < CANCELLED 信号 static final int SIGNAL = 0x00010000; // must be >= 1 << 16 出现异常 private int doJoin() { int s; Thread t; ForkJoinWorkerThread wt; ForkJoinPool.WorkQueue w; s = status; if (s < 0) { return s; } else { if ((t = Thread.currentThread()) instanceof ForkJoinWorkerThread) { wt = (ForkJoinWorkerThread) t; w = wt.workQueuq; s = doExec(); if (w.tryUnpush(this) && s < 0) { return s; } else { return wt.pool.awaitJoin(w, this, 0L); } } else { return externalAwaitDone(); } } } - 通过
小结
-
ConcurrentHashMap和ConcurrentLinkedQueue - 介绍了
Java中的阻塞队列以及如何实现阻塞 - 通过
Fork/Join框架 使用和实现原理介绍
以上