淘系高级算法专家:MIND - 基于动态路由的用户多向量召回
本文内容来自于由阿里巴巴达摩院领航举办的3月20日向量检索专场Meetup讲师演讲内容
讲师介绍 睿德
阿里巴巴淘系技术部,高级算法专家。从事推荐技术召回,排序算法的开发。
内容概述:
手淘首页的推荐面临着两个极具挑战性的问题:一是业务数据量巨大,包括十亿级的用户和商品; 二是首页开屏即现,对算法的响应时间有严格要求。在实际实践中,我们将推荐系统拆分为召回与排序两个子系统。其中,召回系统从海量的候选商品中挑选出与用户兴趣相关的商品集合,排序系统对该商品集合中的每一个商品依据业务目标进行打分,打分较高的商品作为推荐结果展示给用户。推荐算法的效果同时受到两个子系统的影响,召回作为算法的前置环节,更是决定了整个系统的效果上限。本次分享中,我们将分享 MIND 召回算法及其系统架构设计。
问题背景
▐ 应用场景
在一个典型的推荐场景中,推荐算法的任务是将一个经过筛选排序的,贴近用户兴趣的商品列表推荐给用户。下面两张图片展示了手机淘宝两个比较典型的推荐场景,分别是首页的信息流场景和微详情页场景。正如场景名字猜你喜欢所表达的,推荐算法的目标是使得推荐结果尽可能贴合用户的兴趣,满足用户的需求。
在实际的场景中,淘宝的数据体量相对较大,面对的是亿级的用户与亿级的商品。在这样体量的工业场景中,我们通常将整个推荐系统拆分为多个环节,其中召回(Match) 与排序 (Rank)是其中两个比较典型的环节。MIND 算法是我们团队针对召回环节的一项工作。
▐ 召回
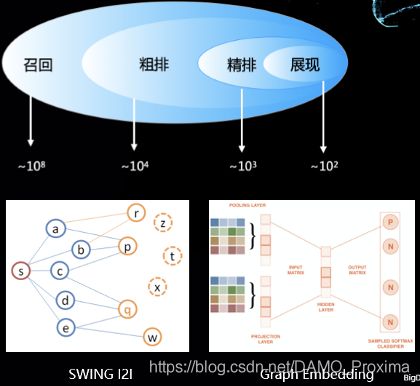
召回系统负责从海量的候选商品中挑选出与用户兴趣相关的商品集合。它作为推荐算法的第一环,直接决定了整个系统的效果上限。与此同时,面临亿级别的候选集合,也就要求所使用的召回算法在计算上足够地高效。通常计算效率上的要求是通过建立索引的方式来达到。
很长一段时间,协同过滤,尤其是 Item-based 的协同过虑都是业界主要使用的一种召回算法,例如图中的基于图的算法和基于 graph embedding 的算法。线上服务时,它使用键值索引,简单,高效,时效性强,往往能达到比较不错的效果。但它也受限于索引形式,表达能力有限,并且不能做到端到端的优化,这就对我们提出了新的算法要求。
近些年,向量检索技术的普及使得用户与商品能以向量的形式进行表征,增强了数据的表达能力,也给我们算法设计带来了新的可能。
▐ 电商场景特点 – 数据多峰分布
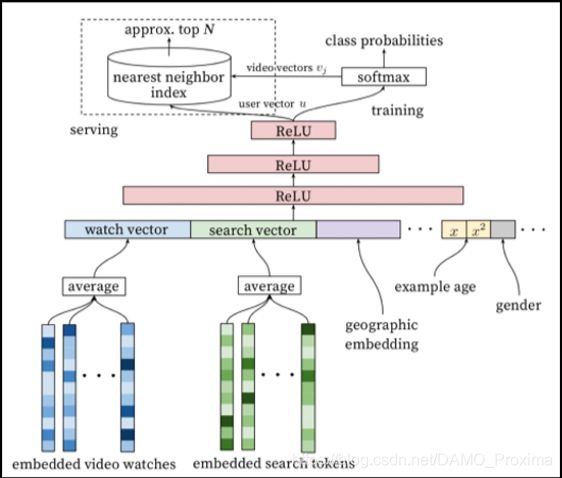
提到向量召回算法,图中谷歌 YouTube 提出的这个向量召回模型是早期一个具有代表性的模型。但是在我们场景直接使用该模型上线,却并没有拿到非常令人满意的效果。
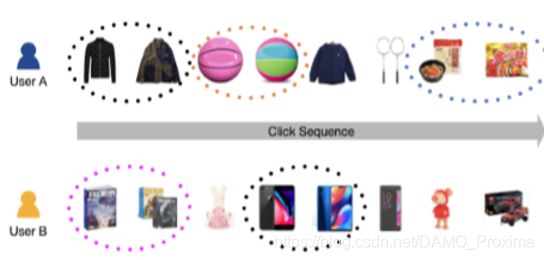
回到我们的电商场景中,电商的数据是很有自身的特点的。通常来说,一个用户的行为是比较丰富的,用户的购物行为和浏览兴趣往往横跨多个类目,并且常常体现出内在的聚集性,也就是数据的多峰分布。因此我们认为,在向量维度有限的情况下,像 YouTube 召回模型中单个用户向量的表达范式是有改进优化空间的。
算法思路
▐ 如何表达用户的多个兴趣
前面提到单个向量对用户的刻画可能存在不足,一个很直接的想法就是使用多个向量来对用户进行表征。通过丰富的用户行为产生用户的几个隶属于某些方面的兴趣的方法,容易联想到可以通过聚类的方式来将用户丰富的行为集合聚合成几个比较具体的兴趣。
在算法设计之初,端到端的优化是我们纳入考虑的一个点,我们期望聚类的过程能够很好地嵌入到深度模型结构中。从训练的成本上来看, 我们也希望这个过程能比较快地收敛,不会带来太多额外的开销。胶囊网络中的动态路由算法正符合我们的算法设计需求。
▐ 如何学习用户的多个兴趣
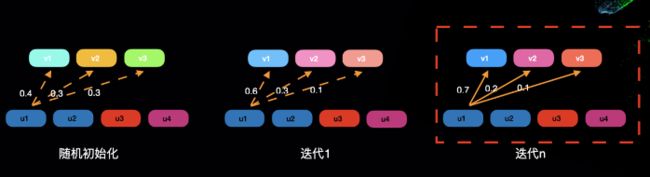
如图所示,动态路由算法处理的是两层向量之间的关系,其中每个元素都代表一个向量,即所谓的胶囊。下层的特征表达是固定的,而上层胶囊在开始阶段是未知的。
最开始我们随机得到一个初始连接权重,得到上层胶囊的一个初始的表达。接下来在迭代过程中,上层的胶囊会和下层的胶囊进行相似度的计算,并根据相似度来进行权重的重新分配,重新计算上层胶囊的表达。重复几轮这样的迭代,最终这个权重会倾向于收敛到一组具体的值。从计算过程来看,动态路由算法的迭代的过程和 Kmeans 聚类是一个非常相似的过程。
因此,可以将用户的行为序列看作下层的胶囊,将要抽取的用户兴趣向量表达看作是上层的胶囊,进行用户多兴趣的抽取。
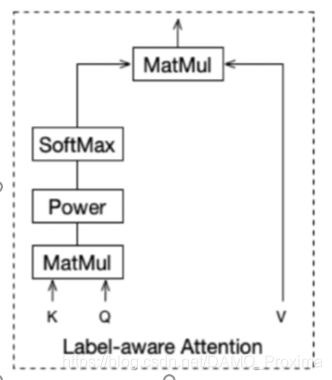
将用户的行为序列表达成多个兴趣向量,同时也引入了一个新的问题: 在训练过程中,抽取出来的多个兴趣对应了一个具体行为,如何进行求解。具体来说, 问题可以表述为对于每条训练样本,使用用户的哪个兴趣进行训练。我们认为, 用户某次具体的行为,是其多个兴趣其中一个的具体表现。因此,在每次训练中,我们根据用户后续的实际行为,在多个兴趣中挑选与后续行为最相关的兴趣,进行训练。这个根据 label 来挑选具体兴趣的训练机制,我们称之为 Label-aware Attention。
▐ MIND
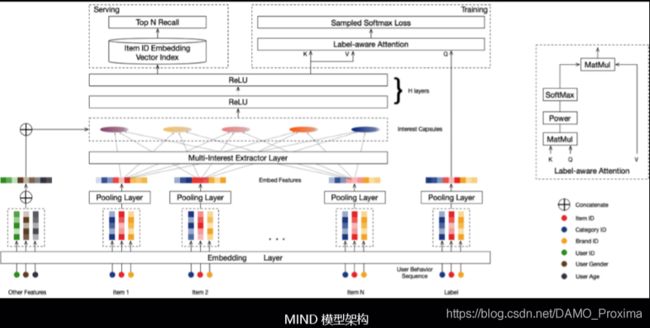
上图是 MIND 模型的整体结构。模型最下层是模型的输入层,首先,通过 Embedding 层,对 id 类特征进行了向量化,并通过 pooling 层对将商品 id 及其他商品侧特征进行了信息融合,引入了除商品 id 外的其他更多的特征,来更好地描述这个商品。
接下来就是我们的兴趣抽取层。这一层我们使用了动态路由算法对用户的行为进行了兴趣表达的抽取。在抽取出用户的多个兴趣表达之后,我们将用户的兴趣向量与用户的画像特征进行了一个拼接的操作,即在每个兴趣特征表达上加上用户画像的表达。然后通过若干层全连接层将用户的表达与兴趣的表达进行融合。
在这些全连接层之后,我们就得到了用户的多个最终表达向量,每个向量代表了用户一方面的兴趣。
训练过程中我们使用 label-aware attention 机制进行训练。而在线服务时,我们直接使用全连接层抽取出来的多个用户的表达向量,并行地在选品池中进行向量检索,将每个用户兴趣向量检索出来的结果合并之后,得到模型的最终召回结果。
▐ 效果展示

这里是一个简单的效果展示。左边是demo的用户行为序列,可以看到它有服饰、游戏等相关的行为。在右侧是我们根据模型抽取出的4个兴趣,分别用这4个向量进行召回得到一些结果。我们可以看到这几个向量很好地刻画表达了用户不同方面的兴趣,并且在最终的召回中也召回了相关的商品。
MIND 方式所生成的用户表达,除了直接进行商品召回,还能做有意思的扩展,比如说通过用户的实时表达,去找到与当前用户相似的用户,做一些 U2U 的召回。
系统架构
▐ 流程
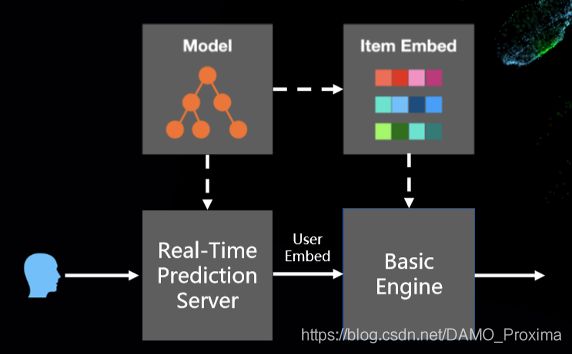
在离线流程中,模型每天使用新增数据进行增量训练。在训练完成后,导出最新的商品向量表示,并分别将模型与商品向量回流到线上系统。在线服务时,用户请求打分服务,得到用户多组向量,并使用这些用户向量请求召回服务,得到召回结果。
▐ 引擎
在线系统使用的是阿里自研的 Proxima 向量检索引擎,支持 fp16,int8 多种量化,支持异构计算,并支持商品索引的实时更新。MIND 模型结构决定了每个用户是一个多向量的请求模式,因此在实践中我们工程团队使用了 GPU对向量检索引擎进行加速。优化后单次用户查询 9 个向量,线上延迟在 5ms 以内。
▐ 全图化架构
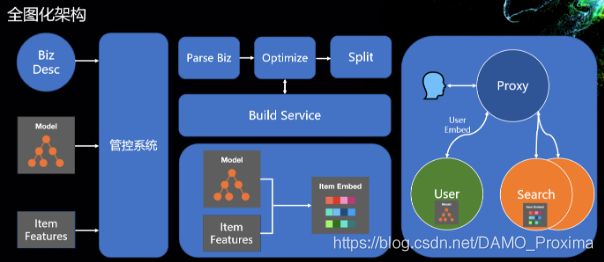
前面介绍的流程中,模型和商品向量索引分别部署在两个不同的系统上,很难保证两边模型和数据版本切换的一致性。因此我们的工程团队提出了全图化的系统架构,其核心是把用户向量的生成步骤,从原来离线完成转移到在线完成。每当线上模型发生更新了之后,会自动触发线上优化过程,使用最新的模型直接生成商品的向量表征,同时进行向量索引的构建。在向量索引构建完成之后,管控系统统一地将模型和商品索引同步进行更新切换。通过这种方式,一方面简化了离线流程,保证了在线模型与数据的一致性,另一方面也对商品索引的增量构建更为友好。
总结
MIND 模型在手淘多个核心场景全量上线,并取得10%+的效果提升。目前 MIND 召回是手淘首页信息流线上流量占比最高的一路召回。线上的 CASE 与效果都表明了模型的有效性: 既表达了用户多样的兴趣,又展现出了一定的发现性。通过对用户行为的扩展,MIND 模型也可以同时表达用户的搜索兴趣与购买兴趣,更好地对用户兴趣进行刻画与表达。
关注由阿里达摩院创办的“AI 检索技术博客“ 公众号
第一时间获取搜索领域Meetup资讯
以及精彩技术文章!
