Out-of-Distribution Detection for Generalized Zero-Shot Action Recognition
Abstract
Generalized zero-shot action recognition is a challenging problem, where the task is to recognize new action categories that are unavailable during the training stage, in addition to the seen action categories. Existing approaches suffer from the inherent bias of the learned classifier towards the seen action categories. As a consequence, un- seen category samples are incorrectly classified as belonging to one of the seen action categories. In this paper, we set out to tackle this issue by arguing for a separate treatment of seen and unseen action categories in generalized zero- shot action recognition. We introduce an out-of-distribution detector that determines whether the video features belong to a seen or unseen action category. To train our out-of- distribution detector, video features for unseen action categories are synthesized using generative adversarial net-works trained on seen action category features. To the best of our knowledge, we are the first to propose an out- of-distribution detector based GZSL framework for action recognition in videos. Experiments are performed on three action recognition datasets: Olympic Sports, HMDB51 and UCF101. For generalized zero-shot action recognition, our proposed approach outperforms the baseline [33] with absolute gains (in classification accuracy) of7.0%, 3.4%, and 4.9%, respectively, on these datasets.
广义零样本动作识别是一个具有挑战性的问题,其任务是识别在训练阶段不可用的新动作类别,以及所见的动作类别。现有方法受到学习分类器对所见行动类别的固有偏见的影响。因此,未见类别样本被错误地归类为属于所见行动类别之一。在本文中,我们通过争论对广义零样本动作识别中的已知和看不见的动作类别进行单独处理来着手解决这个问题。我们引入了一个分布式检测器,用于确定视频功能是属于看见或看不见的动作类别。为了训练我们的分布式探测器,使用在看到的动作类别特征上训练的生成对抗网络来合成用于看不见的动作类别的视频特征。据我们所知,我们是第一个提出基于GZSL框架的分布式探测器,用于视频中的动作识别。实验在三个动作识别数据集上进行:奥林匹克运动,HMDB51和UCF101。对于广义零射击动作识别,我们提出的方法优于基线[33],这些数据集的绝对增益(分类精度)分别为7.0%,3.4%和4.9%。
1. Introduction
Zero-shot learning (ZSL) is a challenging problem,where the task is to classify images or videos into new categories that are unavailable during the training stage. Generalized zero-shot learning (GZSL), introduced in [34], differs from ZSL in that the test samples can belong to the seen or unseen categories. The task of GZSL is therefore harder than ZSL due to the inherent bias of the learned classifier towards the seen categories. In this paper, we focus on the problem of generalized zero-shot action recognition in videos and treat ZSL as a special case of GZSL.
零样本学习(ZSL)是一个具有挑战性的问题,其任务是将图像或视频分类为在训练阶段不可用的新类别。 在[34]中引入的通用零样本学习(GZSL)与ZSL的不同之处在于测试样本可以属于看见或看不见的类别。 因此,GZSL的任务比ZSL更难,因为学习的分类器对所见类别的固有偏见。 在本文中,我们关注视频中广义零样本动作识别的问题,并将ZSL视为GZSL的一个特例。
Most existing approaches [14, 12, 31, 6] tackle the problem of action recognition in videos in a fully-supervised set- ting. In such a setting, all the action categories that occur during testing are known a priori, and instances from all action categories are available during training. However, the fully-supervised problem setting is unrealistic for many real-world applications (e.g., automatic tagging of actions in web videos), where information regarding some action categories is not available during training. Therefore, in this work we tackle the problem of action recognition under zero-shot settings.
大多数现有方法[14,12,31,6]解决了全监督设置中视频中动作识别的问题。 在这样的设置中,在测试期间发生的所有动作类别是先验已知的,并且在训练期间可以获得来自所有动作类别的实例。 然而,对于许多现实世界的应用(例如,网络视频中的动作的自动标记),完全监督的问题设置是不现实的,其中关于一些动作类别的信息在训练期间不可用。 因此,在这项工作中,我们解决了零样本设置下的动作识别问题。
Contrary to action recognition in videos, extensive research efforts have been dedicated to zero-shot image classification. Most earlier ZSL approaches are based on attribute mapping [2, 15]. On the other hand, a few recent works [10, 18] tackle the problem in a transductive manner, by assuming access to the full set of unlabelled testing data. This helps in decreasing the domain shift problem, in ZSL, caused due to disjoint categories in training and testing. Similar transductive strategies have also been explored for action recognition in videos [36, 24] to reduce the bias towards seen action categories. However, these approaches require unlabelled testing data for fine-tuning the parameters. Further, the bias still exists due to the similar treatment of both seen and unseen categories (see Fig. 1(a)). Instead, we propose a GZSL framework to separate the classification step for the seen and unseen action classes by introducing an out-of-distribution (OD) detector. As a result, the inherently-learned bias towards the seen classes in the action classifier is reduced (see Fig. 1(b)).
与视频中的动作识别相反,广泛的研究工作致力于零样本图像分类。大多数早期的ZSL方法都基于属性映射[2,15]。另一方面,最近的一些工作[10,18]通过假设访问全套未标记的测试数据来以转换方式解决问题。这有助于减少由于训练和测试中的不相交类别而导致的ZSL中的域移位问题。类似的转换策略也被用于视频[36,24]中的动作识别,以减少对所见行动类别的偏见。但是,这些方法需要未标记的测试数据来微调参数。此外,由于对所见和未见类别的类似处理,偏差仍然存在(见图1(a))。相反,我们提出了一个GZSL框架,通过引入分布式(OD)检测器来分离所见和未看到的动作类的分类步骤。结果,减少了对动作分类器中所见类别的固有学习偏差(见图1(b))。
Figure 1. Illustration of the bias reduction achieved by the pro- posed framework on a random test split of the HMDB51 dataset. On the left: t-SNE scatter plot for baseline generalized zero-shot action recognition framework [33]. On the right: t-SNE scatter plot for our approach based on an OD detector. Action categories are grouped into seen and unseen classes for illustration. The base- line GZSL [33] incorrectly classifies several unseen category fea- tures (denoted by ’FN Unseen’) into seen action categories. Our approach significantly reduces the bias towards seen categories, resulting in accurate action recognition. Best viewed in color.
通过所提出的框架对HMDB51数据集的随机测试分割实现的偏差减少的图示。 左侧:基线广义零射击动作识别框架的t-SNE散点图[33]。 在右边:基于OD检测器的我们方法的t-SNE散点图。 操作类别分为可见和未看到的类以供说明。 基线GZSL [33]错误地将几个看不见的类别特征(由'FN Unseen'表示)分类为看到的动作类别。 我们的方法显着降低了对所见类别的偏见,从而实现了准确的行动识别。颜色分明。
In our approach, the out-of-distribution (OD) detector is learned to produce a non-uniform distribution with an emphasis (peaks) for seen categories and a uniformly distributed output for the unseen categories. This is achieived by utilizing an entropy loss to train our OD detector for maximizing the entropy of the output for unseen action category features. During inference, the entropy of the detector’s output is compared to a specified threshold for determining whether the test feature belongs to a seen or unseen action category. Consequently, the test feature is dynamically routed to either of the two classifiers explicitly trained over seen and unseen classes, respectively, for final classification. Entropy loss has previously been used [30] to train generative adversarial networks [11] (GAN) for image synthesis, in both unsupervised and semi-supervised settings. However, to the best of our knowledge, we are the first to propose the use of entropy loss in the construction of an OD detector for generalized zero-shot action recognition.
在我们的方法中,学习了分布外(OD)检测器以产生非均匀分布,其中对于看到的类别具有强调(峰值)并且对于看不见的类别具有均匀分布的输出。这是通过利用熵损失来训练我们的OD检测器以最大化输出的熵以实现看不见的动作类别特征来实现的。在推理期间,将检测器输出的熵与指定阈值进行比较,以确定测试特征是否属于看见或看不见的动作类别。因此,测试特征被动态地路由到分别针对已见和未见过的类显式训练的两个分类器中的任何一个,以进行最终分类。先前已经使用熵损失[30]来训练生成对抗网络[11](GAN)的图像合成,无人监督和半监督设置。然而,据我们所知,我们是第一个提出在构造用于广义零射击动作识别的OD探测器中使用熵损失的人。
The proposed OD detector requires features from both seen and unseen action classes to avoid an assumption on the prior data distribution. However, unseen action features are not available during training. Thus, we propose to synthesize unseen action features, to train our OD detector, by adapting a conditional Wasserstein GAN [4] (WGAN) with additional terms: cosine embedding and cycle-consistency losses. The additional loss terms aid in improving the feature generation process for a diverse set of action categories. In our work, both the generator and discriminator of the WGAN are conditioned on the category-specific auxiliary descriptions, called class-embeddings or attributes1, to synthesize class-specific action features. Consequently, our OD detector and the two action classifiers (seen and unseen) are trained using real and synthesized features from seen and unseen categories, respectively.
所提出的OD检测器需要来自已见和未见动作类的特征,以避免对先前数据分布的假设。 但是,在培训期间无法使用看不见的操作功能。 因此,我们建议合成看不见的动作特征,训练我们的OD探测器,通过调整条件Wasserstein GAN [4](WGAN)和附加项:余弦嵌入和循环一致性损失。 额外的损失条款有助于改进各种行动类别的特征生成过程。 在我们的工作中,WGAN的生成器和鉴别器都以特定于类别的辅助描述(称为类嵌入或属性)为条件,以合成特定于类的动作特征。 因此,我们的OD探测器和两个动作分类器(可见和未看到)分别使用来自已见和未见类别的真实和合成特征进行训练。
Contributions: We introduce a novel generalized zero- shot action recognition framework based on an out-of- distribution (OD) detector. Our OD detector is designed to reduce the effect of the inherent bias towards the seen action classes generally present in the standard GZSL framework. To synthesize unseen features for our OD detector training, we adapt the conditional Wasserstein GAN with additional loss terms. To the best of our knowledge, we are the first to introduce a GZSL action recognition framework based on an OD detector trained using real features from seen ac- tion categories and synthesized features from unseen action classes. Our OD detector efficiently discriminates the se- mantically similar seen and unseen action categories, lead- ing to improved action classification. Our approach sets a new state-of-the-art for generalized zero-shot action recog- nition on three benchmarks.
贡献:我们引入了一种基于分布外(OD)检测器的新型广义零射击动作识别框架。 我们的OD检测器旨在降低固有偏差对标准GZSL框架中常见的动作类别的影响。 为了合成我们的OD探测器训练中看不见的特征,我们使条件Wasserstein GAN适应额外的损耗项。 据我们所知,我们是第一个引入基于OD探测器的GZSL动作识别框架,该探测器使用来自所见动作类别的真实特征和来自未见动作类的综合特征进行训练。 我们的OD探测器有效地区分了相似的看见和看不见的动作类别,从而改进了动作分类。 我们的方法在三个基准测试中为广义零射击动作识别设定了新的先进技术。
2. Related Work
ZSL and GZSL have gained considerable attention in recent years since they can deal with challenging real-world problems, such as automatic tagging of images and videos with new categories previously unseen during training. Earlier approaches [2, 15, 16] for ZSL in images were based on direct or indirect attribute mapping between instances and their class attributes. Alternatively, several more recent works [26, 7, 1] determine the unseen classes based on the weighted combination of seen classes. In GZSL, obtaining realistic and discriminative training data for unseen classes to overcome the classifier’s bias towards the seen classes is a challenge. Synthesizing visual features of unseen instances through an embedding-based matrix mapping to convert the ZSL problem to a typical supervised problem was explored in [20, 21]. Approaches such as [5, 33, 9] have used different variants of GANs [11] to generate synthetic unseen class features for the task of GZSL. Similar to [33, 9], we adapt the conditional WGAN [4] in our framework for generalized zero-shot action recognition.
ZSL和GZSL近年来得到了相当多的关注,因为它们可以应对具有挑战性的现实问题,例如在训练期间以前未见过的新类别的图像和视频的自动标记。图像中ZSL的早期方法[2,15,16]基于实例与其类属性之间的直接或间接属性映射。或者,最近的几个作品[26,7,1]根据所见类的加权组合确定看不见的类。在GZSL中,为看不见的课程获得现实和有辨别力的训练数据,以克服分类者对所见课程的偏见是一项挑战。在[20,21]中探讨了通过基于嵌入的矩阵映射来合成看不见的实例的视觉特征,以将ZSL问题转换为典型的监督问题。诸如[5,33,9]之类的方法使用了不同的GAN变体[11]来为GZSL的任务生成合成的看不见的类特征。类似于[33,9],我们在我们的广义零射击动作识别框架中调整了条件WGAN [4]。
In contrast to image classification, the problem of ZSL and GZSL for action recognition in videos has received less attention. Existing works pose the problem of ZSL and GZSL action recognition in the transductive setting, where unlabelled test data is also used during training [36, 13, 24]. A generative approach using Gaussians was used to synthesize unseen class data in [24], where each action is represented as a probability distribution in the visual space. These works do not treat seen and unseen action classes separately, as proposed in this work. Further, these methods use unlabelled real features from the unseen classes to rectify the bias of the learned parameters towards the seen classes. Unlike these approaches, we do not use any unlabelled real features from unseen action classes in the training stage of our model. In [37], action recognition under ZSL was addressed using a Fisher vector representation of traditional features and two-stream deep features with GloVE [27] class embedding. However, the more challenging problem of GZSL action recognition was not addressed. A one-to-one comparison using different features, such as C3D [31], I3D [6], also remains unexplored in the context of GZSL in these approaches.
与图像分类相比,用于视频中的动作识别的ZSL和GZSL的问题受到较少关注。现有的工作在转换设置中引起了ZSL和GZSL动作识别的问题,其中在训练期间也使用未标记的测试数据[36,13,24]。使用高斯的生成方法被用于合成[24]中看不见的类数据,其中每个动作表示为视觉空间中的概率分布。这些工作不会像本工作中提出的那样单独处理看不见的和看不见的动作类。此外,这些方法使用来自看不见的类的未标记的真实特征来纠正学习参数对所见类的偏差。与这些方法不同,我们不会在模型的训练阶段使用任何未标记的动作类中未标记的真实特征。在[37]中,ZSL下的动作识别使用传统特征的Fisher矢量表示和Glove [27]类嵌入的双流深度特征来解决。然而,没有解决GZSL行动认可的更具挑战性的问题。在这些方法中,使用不同特征的一对一比较,例如C3D [31],I3D [6],在GZSL的背景下仍然未被探索。
Out-of-distribution detectors [17, 8] have been investigated in the context of image classification via cross-dataset evaluation. In [17], instances that appear to be at the boundary of the data manifold were used as out-of-distribution examples during training while [8] used the misclassified in-distribution samples as a proxy for out-of- distribution samples to calibrate the detector. However, in our approach, no such prior data distribution assumptions are made. Further, these detectors [17, 8] consider in-distribution samples from one image classification dataset and out-of-distribution samples from a different dataset, while our detector aims to distinguish between the seen and unseen class features of the same dataset.
已经通过交叉数据集评估在图像分类的背景下研究了分布外检测器[17,18]。 在[17]中,似乎位于数据流形边界的实例在训练期间被用作分布式示例,而[8]使用错误分类的分布中样本作为分布式样本的代理来校准探测器。 但是,在我们的方法中,没有做出此类先前的数据分布假设。 此外,这些检测器[17,18]考虑来自一个图像分类数据集的分布中样本和来自不同数据集的分布外样本,而我们的检测器旨在区分同一数据集的已见和未看到的类特征。
Our approach: Different to the aforementioned works, an out-of-distribution detector is trained, with entropy loss, using GAN generated features of unseen action categories (as out-of-distribution samples) to recognize whether a feature sample belongs to either the seen or unseen group. Our method assumes no prior data distribution of the seen and unseen categories. The GAN itself is trained using the real features of seen categories, conditioned on the associated class-attributes of seen classes. During inference, based on the out-of-distribution detector’s decision, features from a test instance are input to one of the two classifiers explicitly trained over seen and unseen action categories, respectively.
我们的方法:与上述工作不同,使用GAN生成的看不见的动作类别的特征(作为分布外样本)训练分布式检测器,使用熵损失来识别特征样本是否属于 看见或看不见的群体。 我们的方法假设没有看到和看不见的类别的先前数据分布。 GAN本身使用所见类别的真实特征进行训练,条件取决于所见类的相关类属性。 在推断期间,基于分布式检测器的决定,来自测试实例的特征被输入到分别在已见和未看到的动作类别上明确训练的两个分类器之一。
3. Proposed Approach
The proposed framework for GZSL is detailed in this section. The framework is divided into two parts: synthetic video feature generation for unseen classes using GANs (Sec. 3.1) and out-of-distribution (OD) classifier learning (Sec. 3.2). The illustration of the overall pipeline is shown in Fig. 2.
本节详细介绍了提出的GZSL框架。 该框架分为两部分:使用GAN(第3.1节)和分发外(OD)分类器学习(第3.2节)的不可见类的合成视频特征生成。 整个管道的图示如图2所示
Let ![]() be the training set for seen classes, where
be the training set for seen classes, where ![]() denotes the spatio-temporal CNN features, y denotes the class labels in
denotes the spatio-temporal CNN features, y denotes the class labels in ![]() with S seen classes and
with S seen classes and![]() denotes the category-specific embedding that models the semantic relationship between the classes. Additionally,
denotes the category-specific embedding that models the semantic relationship between the classes. Additionally, ![]() is available during training, where u is a class from a disjoint label set
is available during training, where u is a class from a disjoint label set  of U labels, and the corresponding videos or features are not available. The task in GZSL is to learn a classifier
of U labels, and the corresponding videos or features are not available. The task in GZSL is to learn a classifier ![]() :
: ![]() . Using the OD detector, this task can be reformulated into learning 3 classifiers:the out-of-distribution classifier
. Using the OD detector, this task can be reformulated into learning 3 classifiers:the out-of-distribution classifier ![]() :
: ![]() and the seen and unseen classifiers
and the seen and unseen classifiers  :
: ![]() and
and ![]() :
: ![]() , respectively. The classifier fod will determine if the feature is an in-distribution or out-of-distribution feature and route it to either or
, respectively. The classifier fod will determine if the feature is an in-distribution or out-of-distribution feature and route it to either or ![]() to determine the class.
to determine the class.
令![]() 为所见类的训练集,其中
为所见类的训练集,其中![]() 表示时空CNN特征,y 表示
表示时空CNN特征,y 表示![]() 中的类标签,其中可见类S和
中的类标签,其中可见类S和![]() 表示类别特定的嵌入,它模拟类之间的语义关系。另外,
表示类别特定的嵌入,它模拟类之间的语义关系。另外,![]() 在训练期间可用,其中u是来自U标签的不相交标签集的类,以及相应的视频 GZSL中的任务是学习分类器
在训练期间可用,其中u是来自U标签的不相交标签集的类,以及相应的视频 GZSL中的任务是学习分类器![]() :
:![]() 。使用OD检测器,可以将此任务重新构造为学习3分类器:分布式分类器
。使用OD检测器,可以将此任务重新构造为学习3分类器:分布式分类器![]() :
:![]() 和看见和看不见的分类器:
和看见和看不见的分类器:![]() 和
和![]() :
:![]() 。 分类器
。 分类器![]() 将确定该特征是分布式还是分布式特征,并将其路由到或
将确定该特征是分布式还是分布式特征,并将其路由到或![]() 以确定该类。
以确定该类。
3.1. Generating unseen class features Given
Given the training data of seen classes, , the goal is to synthesize features belonging to unseen classes,
, the goal is to synthesize features belonging to unseen classes,  , using the class attributes,
, using the class attributes,![]() . To this end, a generative adversarial network (GAN) is learned using the seen class features,
. To this end, a generative adversarial network (GAN) is learned using the seen class features,  , and the corresponding class embedding,
, and the corresponding class embedding, ![]() . A GAN [11] consists of a generator G and a discriminator D, which compete against each other in a two player min-imax game. In the context of generating video features, D attempts to accurately distinguish real-video features from synthetically generated features, while G attempts to fool the discriminator by generating video features that are semantically close to real features. Since we need to synthesize features specific to unseen action categories, we use the conditional GAN [23] by conditioning both G and D on the embedding, e(y). A conditional generator
. A GAN [11] consists of a generator G and a discriminator D, which compete against each other in a two player min-imax game. In the context of generating video features, D attempts to accurately distinguish real-video features from synthetically generated features, while G attempts to fool the discriminator by generating video features that are semantically close to real features. Since we need to synthesize features specific to unseen action categories, we use the conditional GAN [23] by conditioning both G and D on the embedding, e(y). A conditional generator  :
:![]() takes a random Gaussian noise
takes a random Gaussian noise 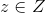 and a class embedding
and a class embedding ![]() . Once the generator is learned, it is used to synthesize the video features of unseen classes,
. Once the generator is learned, it is used to synthesize the video features of unseen classes,  , by conditioning on the unseen class embedding,
, by conditioning on the unseen class embedding,![]() . Further, we use the Wasserstein GAN [4] for the proposed framework due to its more stable training and recent success in [33, 9] for zero-shot image classification.
. Further, we use the Wasserstein GAN [4] for the proposed framework due to its more stable training and recent success in [33, 9] for zero-shot image classification.
给定可见类的训练数据,目标是使用类属性![]() 来合成属于看不见的类的特征 。为此,使用所见的类特征x和相应的类嵌入
来合成属于看不见的类的特征 。为此,使用所见的类特征x和相应的类嵌入![]() 来学习生成的广告网络(GAN)。 GAN [11]由发生器G和鉴别器D组成,它们在双人游戏min-imax游戏中相互竞争。在生成视频特征的背景下,D尝试准确地区分真实视频特征与合成生成的特征,而G试图通过生成在语义上接近真实特征的视频特征来欺骗鉴别器。由于我们需要合成特定于看不见的动作类别的特征,我们通过在嵌入
来学习生成的广告网络(GAN)。 GAN [11]由发生器G和鉴别器D组成,它们在双人游戏min-imax游戏中相互竞争。在生成视频特征的背景下,D尝试准确地区分真实视频特征与合成生成的特征,而G试图通过生成在语义上接近真实特征的视频特征来欺骗鉴别器。由于我们需要合成特定于看不见的动作类别的特征,我们通过在嵌入![]() 上调节G和D来使用条件GAN [23]。条件生成器G:Z
上调节G和D来使用条件GAN [23]。条件生成器G:Z![]() 采用随机高斯噪声和嵌入
采用随机高斯噪声和嵌入![]() 类。一旦学习了生成器,它就被用来合成看不见的类的视频特征,u通过调整看不见的类嵌入
类。一旦学习了生成器,它就被用来合成看不见的类的视频特征,u通过调整看不见的类嵌入![]() 。此外,我们使用Wasserstein GAN [4]作为所提出的框架,因为它更加稳定的训练和最近在[33,9]中对零射击图像分类的成功。
。此外,我们使用Wasserstein GAN [4]作为所提出的框架,因为它更加稳定的训练和最近在[33,9]中对零射击图像分类的成功。
A conditional WGAN [4], conditioned on the embedding ![]() , is learned to synthesize the video features , given the corresponding class embedding,
, is learned to synthesize the video features , given the corresponding class embedding, ![]() . The conditional WGAN loss is given by
. The conditional WGAN loss is given by
![]() (1)
(1)
在给定相应的类嵌入![]() 的情况下,以嵌入
的情况下,以嵌入![]() 为条件的条件WGAN [4]被学习以合成视频特征。有条件的WGAN损失由下式给出
为条件的条件WGAN [4]被学习以合成视频特征。有条件的WGAN损失由下式给出
![]() (1)
(1)
where ![]() ,
,  is a convex combination of x and ,
is a convex combination of x and ,  is the penalty coefficient and E is the expectation. The first two terms approximate the Wasserstein distance in equation 1, with the third term being the penalty for constraining the gradient of D to have unit norm along the convex combination of real and generated pairs. Additionally, we expect the generated features to be sufficiently discrim- inative such that the class embedding that generated them can be reconstructed back using the same features [38]. To this end, similar to [9], a decoder is used to reconstruct the class embedding
is the penalty coefficient and E is the expectation. The first two terms approximate the Wasserstein distance in equation 1, with the third term being the penalty for constraining the gradient of D to have unit norm along the convex combination of real and generated pairs. Additionally, we expect the generated features to be sufficiently discrim- inative such that the class embedding that generated them can be reconstructed back using the same features [38]. To this end, similar to [9], a decoder is used to reconstruct the class embedding ![]() from the synthesized features . Hence, a cycle-consistency loss is added to the loss formulation, which is given by,
from the synthesized features . Hence, a cycle-consistency loss is added to the loss formulation, which is given by,
![]() (2)
(2)
其中![]() ,是x和的凸组合,是罚分系数,E是期望。 等式1中的前两个项近似于Wasserstein距离,第三项是对D的梯度进行约束以在实对和生成对的转换组合中具有单位范数的惩罚。 此外,我们期望生成的特征具有足够的辨别力,以便可以使用相同的特征重建生成它们的类嵌入[38]。 为此,类似于[9],使用解码器从合成特征重建类嵌入
,是x和的凸组合,是罚分系数,E是期望。 等式1中的前两个项近似于Wasserstein距离,第三项是对D的梯度进行约束以在实对和生成对的转换组合中具有单位范数的惩罚。 此外,我们期望生成的特征具有足够的辨别力,以便可以使用相同的特征重建生成它们的类嵌入[38]。 为此,类似于[9],使用解码器从合成特征重建类嵌入![]() 。 因此,循环一致性损失被添加到损失公式中,由下式给出:
。 因此,循环一致性损失被添加到损失公式中,由下式给出:
![]() (2)
(2)
where ![]() is the reconstructed embedding. Further, the synthesized features of a particular class
is the reconstructed embedding. Further, the synthesized features of a particular class  should be similar to the real features of the same class and dissimilar to the features of other classes
should be similar to the real features of the same class and dissimilar to the features of other classes  (for
(for 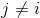 ). To this end, we first pair the real and synthesized features in a mini-batch to generate matched (same classes) and unmatched (different classes) pairs. Then, we minimize and maximize the distance between the matched and unmatched features, respectively, using the cosine embedding loss, as given by,
). To this end, we first pair the real and synthesized features in a mini-batch to generate matched (same classes) and unmatched (different classes) pairs. Then, we minimize and maximize the distance between the matched and unmatched features, respectively, using the cosine embedding loss, as given by,
![L_{emb} = E_m[1-cos(x,\widehat{x})]+E_{um}[max(0, cos(x,\widehat{x}))]](http://img.e-com-net.com/image/info8/0345875c45fc49ffb1f0e89eaa793a52.gif) (3)
(3)
其中![]() 是重建的嵌入。 此外,特定类的合成特征应该类似于同一类的真实特征,并且与其他类的特征不同(对于)。 为此,我们首先将小批量中的真实特征和合成特征配对,以生成匹配(相同类)和不匹配(不同类)对。 然后,我们分别使用余弦嵌入损耗最小化和最大化匹配和不匹配特征之间的距离,如下所示:
是重建的嵌入。 此外,特定类的合成特征应该类似于同一类的真实特征,并且与其他类的特征不同(对于)。 为此,我们首先将小批量中的真实特征和合成特征配对,以生成匹配(相同类)和不匹配(不同类)对。 然后,我们分别使用余弦嵌入损耗最小化和最大化匹配和不匹配特征之间的距离,如下所示:
(3)
where the respective expectations are over the matched (m) and unmatched (um) pair distributions. While the other losses (![]() and
and  ) train the network by emphasizing the similarity between real and generated features of a particular class, the embedding loss also trains the net-work by emphasizing how the generated features of an action class should be dissimilar to the other class features. The final objective for training the GAN, using β and γ as hyper-parameters for weighting the respective losses, is given by
) train the network by emphasizing the similarity between real and generated features of a particular class, the embedding loss also trains the net-work by emphasizing how the generated features of an action class should be dissimilar to the other class features. The final objective for training the GAN, using β and γ as hyper-parameters for weighting the respective losses, is given by
![]() (4)
(4)
其中各自的期望超过匹配的(m)和不匹配的(um)对分布。 虽然其他损失(![]() 和)通过强调特定类的实际特征和生成特征之间的相似性来训练网络,但嵌入损失也通过强调动作类的生成特征应该如何与不同的类似来训练网络。 其他课程特色。 训练GAN的最终目标是使用β和γ作为超参数来加权各自的损失,由下式给出
和)通过强调特定类的实际特征和生成特征之间的相似性来训练网络,但嵌入损失也通过强调动作类的生成特征应该如何与不同的类似来训练网络。 其他课程特色。 训练GAN的最终目标是使用β和γ作为超参数来加权各自的损失,由下式给出
![]() (4)
(4)

Figure 2. Illustration of the proposed GZSL approach: A conditional WGAN is trained to synthesize video features , conditioned on the class embedding e(y) via the losses ![]() , and
, and ![]() . A spatio-temporal CNN computes the real features x for the seen class videos. During post-training, the generator, conditioned on the unseen class embedding
. A spatio-temporal CNN computes the real features x for the seen class videos. During post-training, the generator, conditioned on the unseen class embedding ![]() , synthesizes unseen class features
, synthesizes unseen class features ![]() , which, along with real features
, which, along with real features ![]() , are used to learn the three classifiers
, are used to learn the three classifiers ![]() ,
,  and
and ![]() . The expected outputs of fod for seen and unseen class features are also portrayed. Cuboids with dashed borders denote synthesized features. Dashed arrows indicate their corresponding path.
. The expected outputs of fod for seen and unseen class features are also portrayed. Cuboids with dashed borders denote synthesized features. Dashed arrows indicate their corresponding path.
3.2. Out-of-distribution detector for unseen class
An out-of-distribution detector is proposed for differentiating between the features belonging to the seen classes and those belonging to unseen classes. After training the GAN using the training data S, the generator (G) is used to synthesize features,![]() for the unseen categories
for the unseen categories ![]() . A training set of generated features,
. A training set of generated features,![]() is obtained by generating sufficient features for all the unseen action categories.
is obtained by generating sufficient features for all the unseen action categories.
提出了一种分布式检测器,用于区分属于所见类的特征和属于看不见的类的特征。 在使用训练数据S训练GAN之后,生成器(G)用于合成对于看不见的类别![]() 的特征,
的特征,![]() 。 通过为所有不可见的动作类别生成足够的特征来获得生成的特征的训练集合
。 通过为所有不可见的动作类别生成足够的特征来获得生成的特征的训练集合 ![]() 。
。
The real features of the seen classes, ![]() and the generated features of the unseen classes,
and the generated features of the unseen classes, ![]() , are used to train the out-of-distribution detector. Approaches in [17, 8] learn anOD detector with a prior data distribution assumption of the seen class features. However, using generated samples of the unseen classes can help to better learn the boundaries between the seen and unseen categories, without assuming any prior data distribution. The detector is a fully-connected network with the dimension of the output layer the same as the number of seen classes, S. As shown in Sec. 4.2, a binary classifier is insufficient to learn this task due to the complex boundaries between the many seen and unseen classes. Instead of attempting to directly predict whether the input is from a seen or unseen class, we use the concept of entropy to learn an embedding that projects the features of the seen and unseen classes far apart in the entropy space. The network is trained with entropy loss, Lent, as given by
, are used to train the out-of-distribution detector. Approaches in [17, 8] learn anOD detector with a prior data distribution assumption of the seen class features. However, using generated samples of the unseen classes can help to better learn the boundaries between the seen and unseen categories, without assuming any prior data distribution. The detector is a fully-connected network with the dimension of the output layer the same as the number of seen classes, S. As shown in Sec. 4.2, a binary classifier is insufficient to learn this task due to the complex boundaries between the many seen and unseen classes. Instead of attempting to directly predict whether the input is from a seen or unseen class, we use the concept of entropy to learn an embedding that projects the features of the seen and unseen classes far apart in the entropy space. The network is trained with entropy loss, Lent, as given by
![]() (5)
(5)
所见类的真实特征![]() 和未见类的生成特征
和未见类的生成特征![]() 用于训练分布外检测器。 [17,8]中的方法学习了具有所见类特征的先验数据分布假设的anOD检测器。但是,使用生成的看不见类的样本有助于更好地了解看到和看不见的类别之间的界限,而无需假设任何先前的数据分布。探测器是一个全连接的网络,输出层的尺寸与看到的类的数量S相同。如第2节所示。 4.2,二元分类器不足以学习这个任务,因为可见类和不可见类之间的边界复杂。我们不是试图直接预测输入是来自看到的还是看不见的类,而是使用熵的概念来学习嵌入,该嵌入在熵空间中将看到和看不见的类的特征投射得很远。网络训练有熵损失,
用于训练分布外检测器。 [17,8]中的方法学习了具有所见类特征的先验数据分布假设的anOD检测器。但是,使用生成的看不见类的样本有助于更好地了解看到和看不见的类别之间的界限,而无需假设任何先前的数据分布。探测器是一个全连接的网络,输出层的尺寸与看到的类的数量S相同。如第2节所示。 4.2,二元分类器不足以学习这个任务,因为可见类和不可见类之间的边界复杂。我们不是试图直接预测输入是来自看到的还是看不见的类,而是使用熵的概念来学习嵌入,该嵌入在熵空间中将看到和看不见的类的特征投射得很远。网络训练有熵损失,![]() ,如下所示
,如下所示
![]() (5)
(5)
where ![]() is the entropy of p, and
is the entropy of p, and ![]() and
and ![]() are the predictions of the network for the seen and unseen features
are the predictions of the network for the seen and unseen features ![]() and
and ![]() , respectively. Further, a negative log-likelihood term
, respectively. Further, a negative log-likelihood term ![]() , where
, where  is the class label of
is the class label of ![]() , is added to Eq. 5 for faster convergence. This type of loss formulation models the output of the network such that its entropy is minimum and maximum for the input features of seen and unseen classes, respectively. The higher the entropy, the higher the uncertainty. Thus, a seen class feature input will have a non-uniformly distributed output (with an emphasis on seen classes). Similarly, an unseen class feature will have a near-uniform distribution as its output. The expected output of the classifier,
, is added to Eq. 5 for faster convergence. This type of loss formulation models the output of the network such that its entropy is minimum and maximum for the input features of seen and unseen classes, respectively. The higher the entropy, the higher the uncertainty. Thus, a seen class feature input will have a non-uniformly distributed output (with an emphasis on seen classes). Similarly, an unseen class feature will have a near-uniform distribution as its output. The expected output of the classifier, ![]() , for the seen and unseen class features is illustrated in the far-right side of Fig. 2.
, for the seen and unseen class features is illustrated in the far-right side of Fig. 2.
其中![]() 是p的熵,
是p的熵,![]() 和
和![]() 是分别可见和不可见的特征
是分别可见和不可见的特征![]() 和
和![]() 的预测。 此外,负对数似然项
的预测。 此外,负对数似然项![]() ,其中是
,其中是![]() 的类标签,被添加到等式5用于更快的收敛。 这种类型的损失公式对网络的输出进行建模,使得其熵分别对于看到和未看到的类的输入特征是最小和最大的。 熵越高,不确定性越高。 因此,可见类特征输入将具有非均匀分布的输出(强调所见的类)。 类似地,看不见的类特征将具有接近均匀的分布作为其输出。 分类器的预期输出
的类标签,被添加到等式5用于更快的收敛。 这种类型的损失公式对网络的输出进行建模,使得其熵分别对于看到和未看到的类的输入特征是最小和最大的。 熵越高,不确定性越高。 因此,可见类特征输入将具有非均匀分布的输出(强调所见的类)。 类似地,看不见的类特征将具有接近均匀的分布作为其输出。 分类器的预期输出![]() ,用于可见和不可见的类特征,如图2的最右侧所示。
,用于可见和不可见的类特征,如图2的最右侧所示。
Seen and unseen classifiers: Alongside the OD detector training, we also train two separate classifiers, one for the seen classes and one for the unseen classes. The two clas- sifiers ![]() and are trained on real features of seen classes
and are trained on real features of seen classes ![]() and generated features of unseen classes
and generated features of unseen classes ![]() , respectively. During inference, the test video is passed through a spatio-temporal CNN to compute the real features xtest and then sent to the OD detector. If the entropy of the output
, respectively. During inference, the test video is passed through a spatio-temporal CNN to compute the real features xtest and then sent to the OD detector. If the entropy of the output ![]() is less than a threshold
is less than a threshold ![]() , the feature
, the feature  is passed through the seen-classes classifier in order to predict the label of the test video. If the entropy of
is passed through the seen-classes classifier in order to predict the label of the test video. If the entropy of ![]() greater than
greater than ![]() , then the label is predicted using the unseen-classes classifier
, then the label is predicted using the unseen-classes classifier ![]() . In ZSL, where the test samples are restricted to belonging to unseen classes, only the unseen-classes classifier
. In ZSL, where the test samples are restricted to belonging to unseen classes, only the unseen-classes classifier ![]() is required to predict the category of the video. In summary, the OD detector separates the classification of seen and unseen categories and reduces the bias towards seen categories.
is required to predict the category of the video. In summary, the OD detector separates the classification of seen and unseen categories and reduces the bias towards seen categories.
除了OD探测器训练之外,我们还训练了两个独立的分类器,一个用于可见类,一个用于不可见类。两个分类器![]() 和分别训练了所见类
和分别训练了所见类![]() 的真实特征,并分别生成了看不见的类
的真实特征,并分别生成了看不见的类![]() 的特征。在推理期间,测试视频通过时空CNN来计算真实特征,然后发送到OD检测器。如果输出
的特征。在推理期间,测试视频通过时空CNN来计算真实特征,然后发送到OD检测器。如果输出![]() 的熵小于阈值
的熵小于阈值![]() ,则特征xtest通过可见类分类器以预测测试视频的标签。如果
,则特征xtest通过可见类分类器以预测测试视频的标签。如果![]() 的熵大于
的熵大于![]() ,则使用不可见类分类器
,则使用不可见类分类器![]() 预测标签。在ZSL中,测试样本仅限于属于看不见的类,只需要看不见的类分类器来预测视频的类别。总之,OD检测器分离了已见和未见类别的分类,并减少了对所见类别的偏见。
预测标签。在ZSL中,测试样本仅限于属于看不见的类,只需要看不见的类分类器来预测视频的类别。总之,OD检测器分离了已见和未见类别的分类,并减少了对所见类别的偏见。
4. Experiments
4.1. Experimental setup
Video features: Two types of video features, I3D [6] (In- flated 3D) and C3D [31] (Convolution 3D), designed for generic action recognition, are used for evaluation. The appearance and flow I3D features are extracted from the Mixed 5c layer output of the RGB and flow I3D networks, respectively. Both networks are pretrained on the Kinetics dataset [6]. For an input video, the Mixed 5c output of both networks are averaged across the temporal dimension and pooled by 4 in the spatial dimension and then flattened to obtain a vector, of size 4096, representing the appearance and flow features, respectively. The appearance and flow features are concatenated to obtain video features of size 8192. We use the C3D model, pre-trained on the Sports-1M dataset [12], to extract the C3D features for representing the actions in a video. A video is divided into non-overlapping 16-frame clips and the mean of the fc6 layer outputs, of size 4096, is taken as the video feature for the action.
视频特征:两种类型的视频特征,I3D [6](虚拟3D)和C3D [31](卷积3D),专为通用动作识别而设计,用于评估。 外观和流程I3D特征分别从RGB和流I3D网络的Mixed 5c层输出中提取。 这两个网络都是在Kinetics数据集上预先训练的[6]。 对于输入视频,两个网络的Mixed 5c输出在时间维度上平均,并在空间维度中由4维卷积核池化合并,然后展平以获得大小为4096的向量,分别表示外观和流动特征。 连接外观和流程特征以获得大小为8192的视频特征。我们使用在Sports-1M数据集[12]上预先训练的C3D模型来提取C3D特征以表示视频中的动作。 视频被分成非重叠的16帧剪辑,大小为4096的fc6层输出的平均值被视为动作的视频特征。
Network architecture: The generator G is a three-layer fully-connected (FC) network with an output layer dimension equal to the size of the video feature. The hidden layers are of size 4096. The decoder is also a three-layer FC network with an output size equal to the class-embedding size and a hidden size equal to 4096. The discriminator D is a two-layer FC network with the output size equal to 1 and a hidden size equal to 4096. The individual classifiers and ![]() are single-layer FC networks with an input size equal to the video feature size and output sizes equal to the number of seen and unseen classes, respectively. The OD detector
are single-layer FC networks with an input size equal to the video feature size and output sizes equal to the number of seen and unseen classes, respectively. The OD detector ![]() is a three-layer FC network with output and hidden layer sizes equal to the number of seen classes and 512, respectively. The parameters β and γ are set to 0.01 and 0.1, respectively, for all the datasets. The threshold value entth is chosen to be the average of the prediction entropies of the seen class features in the training data. All the modules are trained using the Adam optimizer with a
is a three-layer FC network with output and hidden layer sizes equal to the number of seen classes and 512, respectively. The parameters β and γ are set to 0.01 and 0.1, respectively, for all the datasets. The threshold value entth is chosen to be the average of the prediction entropies of the seen class features in the training data. All the modules are trained using the Adam optimizer with a  learning rate.
learning rate.
网络架构:生成器G是三层全连接(FC)网络,其输出层尺寸等于视频特征的大小。隐藏层的大小为4096.解码器也是一个三层FC网络,输出大小等于类嵌入大小,隐藏大小等于4096.鉴别器D是一个带输出的双层FC网络大小等于1,隐藏大小等于4096.单个分类器和![]() 是单层FC网络,其输入大小等于视频特征大小,输出大小分别等于看到和看不见的类的数量。 OD检测器
是单层FC网络,其输入大小等于视频特征大小,输出大小分别等于看到和看不见的类的数量。 OD检测器![]() 是一个三层FC网络,其输出和隐藏层大小分别等于所见类的数量和512。对于所有数据集,参数β和γ分别设置为0.01和0.1。阈值entth被选择为训练数据中所见类特征的预测熵的平均值。所有模块都使用Adam优化器进行训练,学习率为。
是一个三层FC网络,其输出和隐藏层大小分别等于所见类的数量和512。对于所有数据集,参数β和γ分别设置为0.01和0.1。阈值entth被选择为训练数据中所见类特征的预测熵的平均值。所有模块都使用Adam优化器进行训练,学习率为。
Datasets: Three challenging video action datasets (Olympic Sports [25], HMDB51 [14] and UCF101 [29]), widely used as benchmarks for GZSL and ZSL, are used for evaluating the performance of the proposed technique. The details of the three datasets are given in Tab. 1. The mean per-class accuracy averaged over 30 independent test runs is reported along with the standard deviation. Each test run is carried out on a random split of the seen and unseen classes in the dataset. For GZSL, we also report the mean accuracy for the seen classes, mean accuracy of the unseen classes and the harmonic mean of the two. For the GZSL setting, the test data consists of all the videos belonging to unseen classes and a random subset of 20% videos from seen class categories.
数据集:三个具有挑战性的视频动作数据集(Olympic Sports [25],HMDB51 [14]和UCF101 [29]),广泛用作GZSL和ZSL的基准,用于评估所提出技术的性能。 表1中给出了三个数据集的详细信息。 1.表示了平均超过30次独立测试运行的平均每类精度以及标准偏差。 每个测试运行都是对数据集中已查看和未看到的类的随机拆分执行的。 对于GZSL,我们还了所表示出了可见类的平均准确度,看不见的类的平均准确度以及两者的调和平均值。 对于GZSL设置,测试数据包括属于看不见的类的所有视频以及来自所见类类别的20%视频的随机子集。
Class-embedding: We use two types of class-embedding to semantically represent the classes: the human annotated attributes and word vectors [22]. The UCF101 and Olympic Sports datasets also have manually-annotated class attributes of sizes 40 and 115, respectively. A skip-gram model, trained on the news text corpus provided by Google, is used to generate the action class-specific word vector representations of size 300 using the action category names as input. The HMDB51 dataset does not have any associated manual attributes.
我们使用两种类型的嵌入来语义地表示类:人类注释属性和单词向量[22]。 UCF101和Olympic Sports数据集也分别具有大小为40和115的手动注释类属性。 在Google提供的新闻文本语料库上训练的skip-gram模型用于使用动作类别名称作为输入生成大小为300的动作类特定的单词向量表示。 HMDB51数据集没有任何关联的手动属性。
4.2. Baseline comparison
The proposed framework is compared with the baseline by evaluating on the generalized zero-shot action recognition task using I3D concatenated features. Since our GAN framework for synthesizing features also uses the WGAN [4], we choose f-CLSWGAN [33], originally designed for zero-shot image classification, as the baseline. The performance comparison for the three datasets is shown in Tab. 2. We also compare our GZSL framework with and without the OD detector (denoted as CEWGAN-OD and CEWGAN, respectively, in Tab. 2). Further, to quantify the effectiveness of our OD detector, we also combine CEWGAN with a binary OD classifier, ODbin. The classifi- cation accuracy for the seen and unseen categories and their harmonic mean are denoted by s, u and H , respectively.
通过使用I3D级联特征评估广义零样本动作识别任务,将所提出的框架与基线进行比较。 由于我们用于合成特征的GAN框架也使用WGAN [4],我们选择最初设计用于零样本图像分类的f-CLSWGAN [33]作为基线。 三个数据集的性能比较显示在表格中2,我们还比较了有和没有OD检测器的GZSL框架(分别在表2中表示为CEWGAN-OD和CEWGAN)。 此外,为了量化我们的OD检测器的有效性,我们还将CEWGAN与二元OD分类器ODbin组合。 所见和未见类别及其调和平均值的分类精度分别用s,u和H表示。
The proposed OD detector (![]() ) always outperforms the binary OD detector (
) always outperforms the binary OD detector (![]() ) (see Tab. 2), proving that a binary classifier is not sufficient for learning the task. The
) (see Tab. 2), proving that a binary classifier is not sufficient for learning the task. The ![]() requires generated features for seen and unseen classes to achieve reasonable performance and it still fares, generally, worse than CEWGAN. It only yields better results than CEWGAN for the Olympic Sports dataset. The main reason is that Olympic Sports has only eight seen and unseen classes. Hence, it is easier to separate the corresponding test features. As the number of classes increases, ODbin fails to accurately separate the seen and unseen category features.
requires generated features for seen and unseen classes to achieve reasonable performance and it still fares, generally, worse than CEWGAN. It only yields better results than CEWGAN for the Olympic Sports dataset. The main reason is that Olympic Sports has only eight seen and unseen classes. Hence, it is easier to separate the corresponding test features. As the number of classes increases, ODbin fails to accurately separate the seen and unseen category features.
提出的OD检测器(![]() )总是优于二进制OD检测器(
)总是优于二进制OD检测器(![]() )(见表2),证明二元分类器不足以学习任务。
)(见表2),证明二元分类器不足以学习任务。 ![]() 需要为看到和看不见的类生成特征以实现合理的性能,并且它仍然比CEWGAN更糟糕。对于奥林匹克运动数据集,它只比CEWGAN产生更好的结果。主要原因是奥林匹克体育只有八个看过和看不见的类别。因此,更容易分离相应的测试特征。随着类别数量的增加,
需要为看到和看不见的类生成特征以实现合理的性能,并且它仍然比CEWGAN更糟糕。对于奥林匹克运动数据集,它只比CEWGAN产生更好的结果。主要原因是奥林匹克体育只有八个看过和看不见的类别。因此,更容易分离相应的测试特征。随着类别数量的增加,![]() 无法准确地分离出看见和看不见的类别特征。
无法准确地分离出看见和看不见的类别特征。
Importantly, we see that the proposed GAN (CEWGAN) performs better than the baseline approach (f-CLSWGAN) on all combinations of datasets and attributes. Integrating the proposed OD detector (![]() ) with CEWGAN further improves the performance across datasets. Average gains of 7.0%, 3.4%, and 4.9% (in terms of accuracy) are achieved over f-CLSWGAN [33] for the Olympic Sports, HMDB51 and UCF101 datasets, respectively, using word2vec. Achieving a considerable gain on a difficult dataset, such as HMDB51, shows the promise of our framework for generalized zero-shot action recognition.
) with CEWGAN further improves the performance across datasets. Average gains of 7.0%, 3.4%, and 4.9% (in terms of accuracy) are achieved over f-CLSWGAN [33] for the Olympic Sports, HMDB51 and UCF101 datasets, respectively, using word2vec. Achieving a considerable gain on a difficult dataset, such as HMDB51, shows the promise of our framework for generalized zero-shot action recognition.
重要的是,我们看到所提出的GAN(CEWGAN)在数据集和属性的所有组合上比基线方法(f-CLSWGAN)表现更好。将提出的OD检测器(![]() )与CEWGAN集成可进一步提高数据集的性能。使用word2vec分别对于奥林匹克运动,HMDB51和UCF101数据集的f-CLSWGAN [33]平均获得了7.0%,3.4%和4.9%(在准确性方面)的平均增益。在诸如HMDB51之类的困难数据集上获得可观的收益,显示了我们用于广义零样本动作识别的框架的前景。
)与CEWGAN集成可进一步提高数据集的性能。使用word2vec分别对于奥林匹克运动,HMDB51和UCF101数据集的f-CLSWGAN [33]平均获得了7.0%,3.4%和4.9%(在准确性方面)的平均增益。在诸如HMDB51之类的困难数据集上获得可观的收益,显示了我们用于广义零样本动作识别的框架的前景。
表2.使用用于GZSL动作识别的级联I3D特征的基线f-CLSWGAN * [33](* - 采用的实现方法)的建议方法的比较。 CEWGAN-OD和CEWGAN分别表示具有和不具有分布外(OD)检测器的所提出的框架。 ![]() 和
和![]() 分别表示二元分类器和建议的OD检测器。 越高越好。 HMDB51无法使用手动属性。 s,u和H分别表示看到和看不见的类及其调和平均值的准确性。 CEWGAN在所有数据集上都优于基线f-CLSWGAN。 将
分别表示二元分类器和建议的OD检测器。 越高越好。 HMDB51无法使用手动属性。 s,u和H分别表示看到和看不见的类及其调和平均值的准确性。 CEWGAN在所有数据集上都优于基线f-CLSWGAN。 将![]() 与CEWGAN集成可以获得进一步的收益。
与CEWGAN集成可以获得进一步的收益。
4.3. State-of-the-art comparison
In this section, a comparison of our proposed framework against the other approaches for the tasks of ZSL and GZSL in action recognition is given. Since our aim is reducing the bias of the classifier towards seen classes in generalized zero-shot action recognition, we first compare the GZSL performance (Tab. 3), and then the ZSL performance (Tab. 4), with the other approaches in literature. In both the tables, we report the performance of our approach trained using the I3D (appearance + flow) features. The performance of our approach using other features is given as an ablation study in Sec. 4.6
在本节中,我们给出了我们提出的框架与ZSL和GZSL在行动识别中的任务的其他方法的比较。 由于我们的目标是在广义零样本动作识别中减少分类器对所见类别的偏差,我们首先将GZSL性能(表3)和ZSL性能(表4)与文献中的其他方法进行比较。 在这两个表中,我们报告了使用I3D(外观+流量)功能训练的方法的性能。 使用其他特征的方法的表现作为第4.6中消融研究给出。
GZSL performance comparison: The proposed out-of-distribution detector is applicable only in the GZSL framework. The comparison of our proposed approach with the other approaches on the GZSL task is reported in Tab. 3. The best results for each dataset and attribute combination are in boldface. The standard deviation from the mean is also reported. We see that the proposed approach, CEWGAN-OD, outperforms the other approaches (fewer approaches compared to the ZSL task) on all datasets. The results for CLSWGAN [33] are obtained by adapting the author’s implementation for our GZSL action recognition task. This is denoted by the superscript ’*’ in Tab. 3. Both CLSWGAN and the proposed approach are trained using the I3D features. The best existing approach for GZSL action recognition, GGM [24], employs a generative approach to synthesize unseen class data and utilizes unlabelled real features (C3D) from the unseen classes to rectify the bias of the learned parameters towards seen classes. Particularly, for the UCF101 dataset and manual attributes combination, the proposed approach, CEWGAN-OD, achieves gains of 5.1% and 25.8% (in terms of accuracy) over the CLSWGAN [33] and GGM [24], respectively. Further, for the word2vec embedding, the proposed CEWGAN-OD achieves gains of 16% and 19.8% over the best existing approach, GGM [24], for the HMDB51 and UCF101 datasets, respectively.
提出的分布式检测器仅适用于GZSL框架。 Tab3中报告了我们提出的方法与GZSL任务上的其他方法的比较。 每个数据集和属性组合的最佳结果以粗体显示。还报告了与平均值的标准偏差。我们看到,所提出的方法CEWGAN-OD在所有数据集上都优于其他方法(与ZSL任务相比较少的方法)。 CLSWGAN [33]的结果是通过调整作者对GZSL行动识别任务的实现来获得的。这由Tab 3中的上标'*'表示。 CLSWGAN和提议的方法都使用I3D功能进行训练。 GZSL行动识别的最佳现有方法GGM [24]采用生成方法来合成看不见的类数据,并利用未看到的类中未标记的真实特征(C3D)来纠正学习参数对所见类的偏差。特别是,对于UCF101数据集和手动属性组合,所提出的方法CEWGAN-OD分别比CLSWGAN [33]和GGM [24]实现了5.1%和25.8%(就准确性而言)的增益。此外,对于word2vec嵌入,建议的CEWGAN-OD分别比HMDB51和UCF101数据集的最佳现有方法GGM [24]实现了16%和19.8%的增益。
ZSL performance comparison: In Tab. 4, the proposed approach trained using the I3D (appearance + flow) features is denoted by CEWGAN. Here, the suffix OD (used in Tab. 3) is dropped since the out-of-distribution detector is applicable only in the GZSL task. From Tab. 4, we see that our approach outperforms the other approaches in the zero-shot action recognition task for all combinations of datasets and attributes. The proposed approach, CEWGAN, in general, has less or comparable deviation as the other approaches. This shows that the proposed approach consistently improves across the splits. All the other approaches use either the word2vec or manually-annotated embedding (denoted by w and m, respectively) except MICC [37], which uses GloVE [27], an embedding similar to word2vec. The proposed approach using I3D features and the word2vec embedding has absolute gains of 6.6%,4.9% and 1.5% (in terms of accuracy) over the best existing ZSL results on the Olympic Sports, HMDB51 and UCF101 datasets, respectively. Further, for the word2vec embedding, we observe that the proposed CEWGAN achieves gains of 1.2%, 1.1% and 1.1% over the CLSWGAN [33] for the same datasets, respectively. Generally, for both GZSL and ZSL tasks, using the same features but learning with manual attributes (instead of word2vec) results in better performance across different approaches.
在表4中,使用I3D(外观+流量)特征训练的所提出的方法由CEWGAN表示。这里,后缀OD(在表3中使用)被丢弃,因为分布外检测器仅适用于GZSL任务。从表4中,我们看到我们的方法在数据集和属性的所有组合的零样本动作识别任务中优于其他方法。一般而言,所提出的方法CEWGAN与其他方法的偏差较小或相当。这表明所提出的方法在分裂中始终得到改善。所有其他方法都使用word2vec或手动注释嵌入(分别用w和m表示),MICC [37]除外,它使用Glove [27],类似于word2vec的嵌入。使用I3D功能和word2vec嵌入的建议方法相对于奥林匹克运动,HMDB51和UCF101数据集的最佳现有ZSL结果分别具有6.6%,4.9%和1.5%(就准确性而言)的绝对增益。此外,对于word2vec嵌入,我们观察到相对于相同的数据集,所提出的CEWGAN分别比CLSWGAN [33]实现了1.2%,1.1%和1.1%的增益。通常,对于GZSL和ZSL任务,使用相同的功能但使用手动属性(而不是word2vec)学习可以在不同方法中获得更好的性能。


4.4. Bias towards seen categories Tab
Tab. 5 quantifies the bias reduction due to the proposed framework, CEWGAN-OD, for the three datasets, using the word2vec embedding. For this experiment, we consider all the features of unseen categories as one class and the remaining features from seen categories as another. A feature sample is said to be wrongly classified if the predicted class is not the same as the ground-truth class, regardless of whether the feature was classified as belonging to the correct category within each class or not. This allows us to quantify the bias reduction achieved by the standalone OD detector. We observe that CEWGAN-OD reduces the bias towards the seen categories and achieves better classification for the unseen class features. Specifically, the proposed CEWGAN-OD achieves gains of 6.2% and 10.1% over CEWGAN for the HMDB51 and UCF101 datasets, respectively, using the word2vec embedding.
图5中显示了使用word2vec嵌入的框架量化三个数据集CEWGAN-OD导致的偏差减少量。 对于此实验,我们将看不见的类别的所有功能视为一个类,将剩余的特征视为另一个类别。 如果预测的类别与真实类别不同,则称特征样本被错误地分类,而不管该特征是否被归类为属于每个类别中的正确类别。 这使我们能够量化独立OD检测器实现的偏差降低。 我们观察到CEWGAN-OD减少了对所见类别的偏差,并实现了对看不见的类特征的更好分类。 具体而言,使用word2vec嵌入,建议的CEWGAN-OD分别对于HMDB51和UCF101数据集实现了超过CEWGAN的6.2%和10.1%的增益。

Fig. 3 shows a comparison, in terms of the classification accuracy, between our two frameworks: CEWGAN and CEWGAN-OD. The comparison is shown for random test splits of HMDB51 and UCF101. The x-axis denotes the number of unseen class feature instances in a test split. The unseen class feature instances are sorted (high to low) according to the confidence scores of the respective classifiers (CEWGAN and CEWGAN-OD). The plot shows that integrating the proposed OD detector in the GZSL framework results in a significant improvement in performance for both datasets (denoted by green and red curves in Fig. 3). The number of unseen class feature instances incorrectly classified (into a seen class) is reduced with the integration of the proposed OD dectector. This improvement in classification performance for unseen action categories leads to a significant reduction in bias towards seen classes.
图3显示了我们的两个框架:CEWGAN和CEWGAN-OD之间在分类准确性方面的比较。 显示了HMDB51和UCF101的随机测试分裂的比较。 x轴表示测试拆分中未见过的类功能实例的数量。 根据各个分类器(CEWGAN和CEWGAN-OD)的置信度得分对未看到的类特征实例进行排序(从高到低)。 该图显示将所提出的OD检测器集成在GZSL框架中导致两个数据集的性能的显着改善(在图3中用绿色和红色曲线表示)。 通过集成提出的OD检测器,减少了错误分类(进入看到的类)的未见类功能实例的数量。 对看不见的行动类别的分类表现的这种改进导致对所见类别的偏见显着减少。

4.5. Transferring word representations
As mentioned previously in Sec. 4.1, manual attributes are not available for the HMDB51 dataset. While word2vec representations give a good measure of the semantic representations of the classes, learning with manual attributes always results in better performance, as can be seen from the results in Sec. 4.3 and 4.2. Here, we learn to generate the manual attributes from the word2vec embedding to show that using the transformed class embedding achieves better generation of features, resulting in better performance compared to the word2vec embedding. We use the class embeddings of the UCF101 dataset to learn the transformation using a two-layer FC network. To generate a sufficient number of samples for training, the video features are concatenated with their respective word2vec and used as input. The trained model is then used to transform word2vec representations into manual attribute embeddings.
如前面第二节所述。 4.1,HMDB51数据集无法获得手动属性。 虽然word2vec表示可以很好地衡量类的语义表示,但使用手动属性进行学习总能获得更好的性能,这可以从Sec 4.3和4.2中的结果中看出。 在这里,我们学习如何从word2vec嵌入生成手动属性,以表明使用变换后的类嵌入可以实现更好的特征生成,从而与word2vec嵌入相比具有更好的性能。 我们使用UCF101数据集的类嵌入来学习使用双层FC网络的转换。 为了生成足够数量的样本用于训练,视频特征与它们各自的word2vec连接并用作输入。 然后使用训练的模型将word2vec表示转换为手动属性嵌入。
To comply with the ZSL paradigm of not using any video features from the unseen classes, we use the generated features for the HMDB51 unseen classes as input for the embedding transformation network. Here, the generator is learned using the word2vec embedding and the seen class features of the HMDB51 dataset. The learned attributes for HMDB51 are the same size as the manual attributes of UCF101, i.e., 115. The performance of the proposed framework under ZSL and GZSL settings for the HMDB51 dataset using the transferred attributes (denoted by m) and different features is reported in Tab. 6. The results show that the transferred attributes for HMDB51 achieve better performance than the word2vec. Hence, synthesizing features using transferred attributes, for datasets without manually-annotated attributes, achieves better performance compared to synthesizing using the standard word2vec embedding.
为了遵守不使用来自看不见的类的任何视频特性的ZSL范例,我们使用HMDB51看不见的类的生成特征作为嵌入转换网络的输入。 在这里,使用word2vec嵌入和HMDB51数据集的所见类特征来学习生成器。 HMDB51的学习属性与UCF101的手动属性大小相同,即115.在ZSL和GZSL设置下使用传输属性(由m表示)和不同特征的HMDB51数据集的性能,在表6.结果中表明,HMDB51的传递属性比word2vec具有更好的性能。 因此,与使用标准word2vec嵌入进行合成相比,对于没有手动注释属性的数据集,使用传输属性合成要素可实现更好的性能。
4.6. Comparison of video features
Here, we give a performance comparison of the different video features for the tasks of ZSL and GZSL. The features that are used for comparison are C3D, ![]() (appearance),
(appearance), ![]() (flow) and
(flow) and ![]() (appearance and flow). The features are evaluated on the HMDB51 and UCF101 datasets using both the manual attributes and word2vec embedding. The manual attributes for HMDB51 refer to the transformed attributes, as described in Sec. 4.5. The entire setup remains the same except for the input or output layers, which depend on the video feature dimensions. The results are reported in Tab. 6. In general, we see that the I3Da features perform better than the C3D and I3Df features. The I3Df features are still better than the C3D features, while the best performance is achieved when the appearance and flow features are combined. This is in line with the performance of the features in the task of fully-supervised action recognition, as noted in [6]. This also indicates that our framework can be used with new and improved features as and when they are designed and a corresponding improvement in GZSL action recognition can be expected. The results in Tab. 3 and 4 for CEWGAN-OD and CEWGAN, respecively, use the combined features, I3Daf.
(appearance and flow). The features are evaluated on the HMDB51 and UCF101 datasets using both the manual attributes and word2vec embedding. The manual attributes for HMDB51 refer to the transformed attributes, as described in Sec. 4.5. The entire setup remains the same except for the input or output layers, which depend on the video feature dimensions. The results are reported in Tab. 6. In general, we see that the I3Da features perform better than the C3D and I3Df features. The I3Df features are still better than the C3D features, while the best performance is achieved when the appearance and flow features are combined. This is in line with the performance of the features in the task of fully-supervised action recognition, as noted in [6]. This also indicates that our framework can be used with new and improved features as and when they are designed and a corresponding improvement in GZSL action recognition can be expected. The results in Tab. 3 and 4 for CEWGAN-OD and CEWGAN, respecively, use the combined features, I3Daf.
在这里,我们给出了ZSL和GZSL任务的不同视频特性的性能比较。用于比较的特征是C3D,![]() (外观),
(外观),![]() (流动)和
(流动)和![]() (外观和光流)。使用手动属性和word2vec嵌入在HMDB51和UCF101数据集上评估要素。 HMDB51的手动属性是指转换后的属性,如第4.5节中所述。除输入或输出层外,整个设置保持不变,这取决于视频要素尺寸。结果报告在表格中6.一般来说,我们看到
(外观和光流)。使用手动属性和word2vec嵌入在HMDB51和UCF101数据集上评估要素。 HMDB51的手动属性是指转换后的属性,如第4.5节中所述。除输入或输出层外,整个设置保持不变,这取决于视频要素尺寸。结果报告在表格中6.一般来说,我们看到![]() 功能的性能优于C3D和
功能的性能优于C3D和![]() 特征。
特征。 ![]() 特征仍然优于C3D功能,而外观和光流特征组合时可实现最佳性能。如[6]中所述,这与完全监督的动作识别任务中的特征的表现一致。这也表明我们的框架可以在设计时与新的和改进的功能一起使用,并且可以预期GZSL动作识别的相应改进。 Tab3、4中的结果,CEWGAN-OD和CEWGAN分别使用组合特征
特征仍然优于C3D功能,而外观和光流特征组合时可实现最佳性能。如[6]中所述,这与完全监督的动作识别任务中的特征的表现一致。这也表明我们的框架可以在设计时与新的和改进的功能一起使用,并且可以预期GZSL动作识别的相应改进。 Tab3、4中的结果,CEWGAN-OD和CEWGAN分别使用组合特征![]() 。
。
5. Conclusion
In this work, we proposed a novel out-of-distribution detector integrated into the generalized zero-shot learning action recognition framework. An out-of-distribution detector was learned to detect unseen category features as out-of- distribution samples. It was trained using real and GAN- generated features from seen and unseen categories, respectively. The use of an out-of-distribution detector enabled the classification of the seen and unseen categories to be separated and hence, reduced the bias towards seen classes that is present in the baseline approaches. The approach was evaluated on three human action video datasets, using different types of embedding and video features. The proposed approach outperformed the baseline [33] in generalized zero-shot action recognition using word2vec, with absolute gains of 7.0%, 3.4% and 4.9% on the Olympic Sports, HMDB51 and UCF101 datasets, respectively.
在这项工作中,我们提出了一种新的分布式检测器,它集成在广义零样本学习动作识别框架中。 学习了一个分布式检测器来检测不可见的类别特征作为分布式样本。 它分别使用来自已见和未见类别的真实和GAN生成的特征进行训练。 使用分布外检测器使得所看到和未见类别的分类能够被分离,因此减少了对基线方法中存在的所见类的偏差。 该方法使用不同类型的嵌入和视频功能在三个人类动作视频数据集上进行评估。 在使用word2vec的广义零样本动作识别中,所提出的方法优于基线[33],奥林匹克运动,HMDB51和UCF101数据集的绝对增益分别为7.0%,3.4%和4.9%。