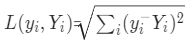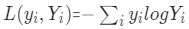- 模型的秘密武器:利用注意力改善长上下文推理能力
步子哥
人工智能自然语言处理深度学习语言模型
【导语】在大语言模型(LLM)不断刷新各项任务记录的今天,很多模型宣称能处理超长上下文内容,但在实际推理过程中,复杂问题往往因隐性事实的遗漏而败下阵来。今天,我们就以《AttentionRevealsMoreThanTokens:Training-FreeLong-ContextReasoningwithAttention-guidedRetrieval》为蓝本,带大家通俗解读如何利用Transf
- Windows下工作组架构和域架构
weixin_33728708
数据库系统架构
工作组架构的网络工作组架构网络也被称为对等网络(peertopeer)域架构网络工作组架构网络域架构网络网络内每台计算机地位平等,资源和管理分散在各个计算机上网络内分为域控制器和成员服务器,如果有多台域控制器,则域控制器之间地位平等每台计算机都有一个本地安全账户管理器(SecurityAccountsManager,SAM)数据库,存储本地账户域内计算机共享一个集中的目录数据库(Directory
- 利用A、G、DL、P策略来管理网络资源访问权限
lyuharvey
问题描述:如现在某个企业是通过域来管理的。在域中,有三台打印机,其中,销售部门只能够访问打印机A;管理部门只能够使用打印机B;财务部门可以访问打印机C,当打印机C不能够使用时,则可以使用打印机B。在域中,还有三个共享文件夹,其中文件夹甲是销售部门专用文件夹,只有销售员工以及销售总监与财务总监可以访问;文件夹乙是财务专用文件夹,只有财务部门以及财务总监帐户可以访问;文件夹丙是一个公共文件夹,任何部门
- OpenAI 团队组织架构和研发技术栈
AI天才研究院
ChatGPT人工智能
OpenAI是一家致力于推动人工智能技术发展的公司,成立于2015年。其目标是确保人工智能技术造福全人类。为了实现这一目标,OpenAI采用了多种先进的技术和组织架构来推动其研发工作。目录OpenAI组织架构和研发技术栈概述1OpenAI团队的世界顶尖科学家IlyaSutskever:Ilya是OpenAI的联合创始人之一,也是深度学习领域的先驱。他在神经网络和深度学习方面的研究具有重要影响,曾与
- 物联网(IoT)架构中,平台层的应用与技术
小赖同学啊
智能硬件物联网架构
在物联网(IoT)架构中,平台层是连接物理设备(感知层)和应用服务(应用层)的核心部分。它负责数据的采集、处理、存储、分析以及设备管理等功能,是物联网系统的“大脑”。以下是平台层的主要功能及其技术实现手段:平台层的主要功能设备管理:功能:管理物联网设备的注册、配置、监控、维护和故障诊断。技术手段:设备注册与认证:使用MQTT、CoAP等协议实现设备接入,结合OAuth、X.509证书等技术进行设备
- 六十天前端强化训练之第十七天React Hooks 入门:useState 深度解析
编程星辰海
#前端前端react.jsjavascript
=====欢迎来到编程星辰海的博客讲解======看完可以给一个免费的三连吗,谢谢大佬!目录一、知识讲解1.Hooks是什么?2.useState的作用3.基本语法解析4.工作原理5.参数详解a)初始值设置方式b)更新函数特性6.注意事项7.类组件对比8.常见问题解答二、核心代码示例三、实现效果四、学习要点总结五、扩展阅读推荐官方文档优质文章推荐学习路径进阶资源六、实践步骤一、表单输入控制二、动态
- 【Kubernetes】Kubernetes 容器集群管理系统概述
码农鑫哥的日常
kubernetes容器云原生1024程序员节
目录前言什么是云原生?容器编排介绍云原生容器云容器编排云平台SRE一、Kubernetes概述1.1K8S是什么?1.1.1作用1.2为什么要用K8S?1.2.1K8s目标1.2.2K8s对于docker的优势1.2.3K8s功能1.2.4K8s特性1.2.4.1弹性伸缩1.2.4.2自我修复1.2.4.3服务发现和负载均衡1.2.4.4自动发布(默认滚动发布模式)和回滚1.2.4.5集中化配置管
- QEMU 调试 TF-A开发环境建立(使用 QEMU 调试 TF-A (Trusted Firmware-A) 之二)
robin861109
使用QEMU调试TF-A硬件架构iot物联网
文章目录前言1`TF-A(TrustedFirmware-A)`概述2`Cortex-A57`3`ARMFVP`基板4GDB调试环境介绍4.1GDB简介4.2设置GDB调试环境4.3使用GDB5、配置QEMU调试TF-A开发环境5.1安装交叉工具链5.2安装其他必需的依赖项5.3克隆TF-A源代码5.4编译TF-A(TrustedFirmware-A)6、仿真调试过程7、实际调试过程举例前言QEM
- 深入解析React 18核心特性:构建未来级Web应用的全面指南
斯~内克
react知识点前端react.js前端框架
一、React18的里程碑意义React18作为近年来最具革命性的版本更新,标志着前端开发正式进入并发渲染时代。这个版本不仅带来了底层架构的革新,更重新定义了现代Web应用的性能标准与开发范式。根据npm官方统计,React18发布首周下载量突破1800万次,GitHub星标数新增3.4万,充分展现了开发者社区对其技术价值的认可。二、架构革命:并发模式深度解析2.1并发渲染原理//传统同步渲染模式
- 机器学习中的梯度到底是什么?(chat-gpt问答)
湫怿
机器学习gpt人工智能梯度
1、梯度是对损失函数求导吗?是的,梯度是对损失函数(或目标函数)求导数值化后的结果。梯度告诉我们目标函数在某个点上的方向性和变化率,这些信息是优化算法推进参数评估和更新的重要指标。在机器学习中,我们通过不断调整参数,使目标函数达到最小值,从而实现模型的训练和学习。2、为什么梯度要求偏导来求解?梯度是一个向量,它的方向指向函数值增加最快的方向,其大小表示函数值的变化率。为了确定梯度的方向和大小,需要
- Android Jetpack
qq_39892855
AndroidJetpack翻译Jetpack是一套让开发者更容易开发出完美安卓应用的组件。这个组件帮助你遵循最好的实践,让你减少写一些模板代码,简化复杂的task任务,能让你更加专注自己的业务代码。Jetpack使用的是androidx.*包名,与旧的android.*分开。这意味着它提供向后兼容性并且他会更频繁地更新,确保您始终可以访问最新和最好的Jetpack组件版本。特点加速开发组件可以单
- 红蓝对抗之Windows内网渗透实战
wespten
网络安全AI+渗透测试代码审计等保全栈网络安全开发windows
无论是渗透测试,还是红蓝对抗,目的都是暴露风险,促进提升安全水平。企业往往在外网布置重兵把守,而内网防护相对来说千疮百孔,所以渗透高手往往通过攻击员工电脑、外网服务、职场WiFi等方式进入内网,然后发起内网渗透。而国内外红蓝对抗服务和开源攻击工具大多数以攻击Windows域为主,主要原因是域控拥有上帝能力,可以控制域内所有员工电脑,进而利用员工的合法权限获取目标权限和数据,达成渗透目的。以蓝军攻击
- 如何用爬虫根据关键词获取商品列表:一份简单易懂的代码示例
API小爬虫
爬虫
在当今数字化时代,网络爬虫已经成为数据收集和分析的强大工具。无论是市场调研、价格监控还是产品分析,爬虫都能帮助我们快速获取大量有价值的信息。今天,我们就来探讨如何通过编写一个简单的爬虫程序,根据关键词获取商品列表。以下是一个基于Python语言的代码示例,适合初学者学习和实践。一、准备工作在开始编写爬虫之前,我们需要准备以下工具和库:Python环境:确保你的电脑上安装了Python。推荐使用Py
- 打造高性能的react
大鸡腿最好吃
react.js
根本目的就是减少重复渲染使用使用shouldComponentUpdate规避冗余的更新逻辑shouldComponentUpdate触发的条件是只要父组件更新了,就会被触发,在里面判断传入的pros是否改变,不变则返回falsePureComponent+Immutable.jsPureComponent其实就是内置了对shouldComponentUpdate的实现,不过其对props的比对是
- 计算机视觉算法实战——驾驶员玩手机检测(主页有源码)
喵了个AI
计算机视觉实战项目计算机视觉算法智能手机
✨个人主页欢迎您的访问✨期待您的三连✨✨个人主页欢迎您的访问✨期待您的三连✨✨个人主页欢迎您的访问✨期待您的三连✨1.领域简介:玩手机检测的重要性与技术挑战驾驶员玩手机检测是智能交通安全领域的核心课题。根据NHTSA数据,美国每年因手机使用导致的交通事故超过3000起,中国公安部的统计显示开车使用手机的事故率是正常驾驶的23倍。该技术通过实时监测驾驶员手部动作和视线方向,识别非法使用手机行为,在以
- 【Python】构建Web应用的首选:Flask框架基础与实战
萧鼎
python基础到进阶教程python前端flask
构建Web应用的首选:Flask框架基础与实战在Python的Web开发生态中,Flask框架以其轻量、灵活和易用的特性成为构建Web应用的首选之一。无论是快速搭建一个小型应用原型,还是构建复杂的后端服务,Flask都提供了便捷的接口和丰富的扩展支持。本博客将介绍Flask的基础知识和核心概念,并通过一个简单的实例展示如何用Flask构建Web应用。一、Flask框架简介Flask是由ArminR
- 安全测试数据的分析、报告及业务应用
蚂蚁质量
安全测试质量体系安全网络web安全
一、安全测试指标与测量目标在风险分析和管理流程中,有效运用安全测试数据的前提是准确定义安全测试指标和测量目标。例如,通过统计安全测试中发现的漏洞总数,能够量化应用程序的安全状态,还可据此设定软件安全测试的目标,如在应用程序投入生产环境前,将漏洞数量降低至可接受的最低限度。另一个具有管理价值的目标是将应用程序的安全状态与安全基线进行对比,以此评估应用安全流程的改进情况。假设安全指标基线对应的是仅完成
- Android Jetpack介绍
Gary.Mi
Android
1.文档背景本文是Jetpack介绍系列文档的开篇,是对Jetpack整体的介绍,后续会对其中的各个组件分别单独说明。2.官方简介Jetpack是一套库、工具和指南,可帮助开发者更轻松地编写优质应用。使用这些组件,可帮助开发者遵循最佳实践,摆脱编写样板代码的工作并简化复杂任务,使开发者将精力集中放在所需的代码上。Jetpack包含与平台API解除捆绑的androidx.*软件包库。这意味着,它可以
- linux清空文件夹的命令
getapi
linuxgithubgit
在Linux系统中,清空文件夹(即删除文件夹中的所有内容,但保留文件夹本身)可以通过多种方法实现。以下是几种常见的命令和操作方式:方法1:使用rm命令rm是一个强大的命令,用于删除文件和目录。要清空文件夹的内容,可以使用以下命令:rm-rf/path/to/folder/*解释:rm:删除命令。-r:递归删除,用于处理目录及其子目录。-f:强制删除,无需确认。/path/to/folder/*:指
- 深入解析 Vue 3 Teleport:原理、应用与最佳实践
赵大仁
前端Vue.js技术vue.jsjavascript前端
深入解析Vue3Teleport:原理、应用与最佳实践1.引言Vue3引入了Teleport组件,它可以让我们将组件的渲染位置从当前组件层级移动到DOM的其他位置,而不影响Vue的响应式和组件状态管理。在开发中,我们经常遇到模态框、通知、弹窗、工具提示(Tooltip)等UI组件,这些组件通常需要被渲染到body或特定DOM节点,以避免z-index层级问题。Vue3的Teleport解决了这个问
- 大型语言模型与强化学习的融合:迈向通用人工智能的新范式——基于基础复现的实验平台构建
(initial)
大模型科普人工智能强化学习
1.引言大型语言模型(LLM)在自然语言处理领域的突破,展现了强大的知识存储、推理和生成能力,为人工智能带来了新的可能性。强化学习(RL)作为一种通过与环境交互学习最优策略的方法,在智能体训练中发挥着重要作用。本文旨在探索LLM与RL的深度融合,分析LLM如何赋能RL,并阐述这种融合对于迈向通用人工智能(AGI)的意义。为了更好地理解这一融合的潜力,我们基于“LargeLanguageModela
- 深入解析 React Diff 算法:原理、优化与实践
赵大仁
前端技术jsreact.js前端前端框架
深入解析ReactDiff算法:原理、优化与实践1.引言React作为前端领域的标杆框架,采用虚拟DOM(VirtualDOM)来提升UI更新性能。React的Diff算法(Reconciliation)是虚拟DOM运行机制的核心,它决定了如何高效地对比新旧DOM并执行最少的操作来更新UI。本篇文章将深入探讨ReactDiff算法的原理、优化策略,并通过生动的示例解析其工作方式,让你能够更直观地理
- 目标检测中衡量模型速度和精度的指标:FPS和mAP
asdfg1258963
目标检测_ai目标检测人工智能
“FPS”和“mAP”分别衡量了模型的速度和精度。FPS(FramesPerSecond)定义:FPS是“每秒传输帧数”的缩写,用于衡量计算机视觉系统(如目标检测、图像识别等)的实时性能。它表示系统每秒钟能够处理的图像或视频帧的数量。重要性:在实时应用中,如自动驾驶、视频监控等,FPS是一个关键指标。高FPS意味着系统能够快速处理输入的图像数据,实现实时响应。计算方式:FPS可以通过以下公式计算:
- 准确率(Precision)和召回率(Recall)
asdfg1258963
目标检测_ai机器学习算法人工智能
准确率(Precision)定义:准确率是指在模型预测为正的样本中,真正为正的样本所占的比例。它关注的是模型预测的准确性。计算公式:Precision=TPTP+FP\text{Precision}=\frac{\text{TP}}{\text{TP}+\text{FP}}Precision=TP+FPTP其中:TP(TruePositive):真正例,模型正确预测为正的样本数。FP(FalseP
- 强化学习-Chapter2-贝尔曼方程
Rsbs
算法机器学习概率论
强化学习-Chapter2-贝尔曼方程贝尔曼方程推导继续展开贝尔曼方程的矩阵形式状态值的求解动作价值函数与状态价值函数的关系贝尔曼方程推导Vπ(s)=E[Gt∣St=s]=E[rt+1+(γrt+2+…)∣St=s]=E[rt+1+γGt+1∣St=s]=∑a∈Aπ(s,a)∑s′∈SPs→s′a⋅(Rs→s′a+γE[Gt+1∣St+1=s′])=∑a∈Aπ(s,a)∑s′∈SPs→s′a⋅(R
- 太速科技-基于3U VPX的 Jetson Xavier NX GPU计算主板
北京太速科技股份有限公司
人工智能
基于3UVPX的JetsonXavierNXGPU计算主板一、产品概述基于3UVPX的JetsonXavierNXGPU计算主板,是AI人工智能的低功耗计算平台,是LINUX环境下软件开发等的理想工具,拥有VPX标准连接器和特性的接口。二、板卡原理框图三、板卡外扩功能P0接口电源输入+12V,板卡总功耗60W以内P1接口1路RS422接口,一路GigabitEthernet前面板接口MICROUS
- C语言字符相加得到什么?字符串相加呢?
GKDf1sh
c语言javaservlet开发语言
#include int main(void){ char d = '1'+'2'; printf("%c",d);//输出结果为c,ASSII码的099恰好是c printf("%d\n",d);//输出结果为99,即ASCII码的十进制数相加(49+50),得出结论两个字符相加的结果为ASCII码相加的结果 //字符串相加的结果又是什么呢? cha
- 本月之后,华为再无Windows PC,微软亲自“扶鸿蒙上马”
佳晓晓
pygamescikit-learn网络iphonevue.js
在当前中美博弈的复杂大环境下,华为这一科技巨头一直备受关注,近期更是传出重磅消息:微软对华为的Windows系统供货许可本月即将到期,且并无续约迹象。这意味着此后华为PC将无法再使用Windows系统,被迫全面转向国产方案,而鸿蒙PC系统则有望借此契机正式登上舞台。华为PC的现状与转变契机自去年8月华为上架MateBookGT14后,已有长达7个月的时间没有新品PC推出。这期间,华为PC的销量也受
- Android 架构MVC MVP MVVM+实例
2401_89284222
android架构mvc
1.View接收用户交互请求2.View将请求转交给ViewModel3.ViewModel操作Model数据更新4.Model更新完数据,通知ViewModel数据发生变化5.ViewModel更新View数据View/Model的变动,只要改其中一方,另一方都能够及时更新到MVVM的优点1.提高可维护性。DataBinding可以实现双向的交互,使得视图和控制层之间的耦合程度进一步降低,分离更
- Java基础编程 找素数
是盈盈啊
笔记
说明:除了1和它本身以外,不能被其他正整数整除,就叫素数。方法是否需要接收数据进行处理?需要接收101以及200,以便找该区间中的素数。方法是否需要返回数据?需要返回找到的素数个数。方法内部的实现逻辑:使用for循环来产生如101到200之间的每个数;每拿到一个数,判断该数是否是素数;判断规则是:从2开始遍历到该数的一半的数据,看是否有数据可以整除它,有则不是素数,没有则是素数;根据判
- github中多个平台共存
jackyrong
github
在个人电脑上,如何分别链接比如oschina,github等库呢,一般教程之列的,默认
ssh链接一个托管的而已,下面讲解如何放两个文件
1) 设置用户名和邮件地址
$ git config --global user.name "xx"
$ git config --global user.email "
[email protected]"
- ip地址与整数的相互转换(javascript)
alxw4616
JavaScript
//IP转成整型
function ip2int(ip){
var num = 0;
ip = ip.split(".");
num = Number(ip[0]) * 256 * 256 * 256 + Number(ip[1]) * 256 * 256 + Number(ip[2]) * 256 + Number(ip[3]);
n
- 读书笔记-jquey+数据库+css
chengxuyuancsdn
htmljqueryoracle
1、grouping ,group by rollup, GROUP BY GROUPING SETS区别
2、$("#totalTable tbody>tr td:nth-child(" + i + ")").css({"width":tdWidth, "margin":"0px", &q
- javaSE javaEE javaME == API下载
Array_06
java
oracle下载各种API文档:
http://www.oracle.com/technetwork/java/embedded/javame/embed-me/documentation/javame-embedded-apis-2181154.html
JavaSE文档:
http://docs.oracle.com/javase/8/docs/api/
JavaEE文档:
ht
- shiro入门学习
cugfy
javaWeb框架
声明本文只适合初学者,本人也是刚接触而已,经过一段时间的研究小有收获,特来分享下希望和大家互相交流学习。
首先配置我们的web.xml代码如下,固定格式,记死就成
<filter>
<filter-name>shiroFilter</filter-name>
&nbs
- Array添加删除方法
357029540
js
刚才做项目前台删除数组的固定下标值时,删除得不是很完整,所以在网上查了下,发现一个不错的方法,也提供给需要的同学。
//给数组添加删除
Array.prototype.del = function(n){
- navigation bar 更改颜色
张亚雄
IO
今天郁闷了一下午,就因为objective-c默认语言是英文,我写的中文全是一些乱七八糟的样子,到不是乱码,但是,前两个自字是粗体,后两个字正常体,这可郁闷死我了,问了问大牛,人家告诉我说更改一下字体就好啦,比如改成黑体,哇塞,茅塞顿开。
翻书看,发现,书上有介绍怎么更改表格中文字字体的,代码如下
- unicode转换成中文
adminjun
unicode编码转换
在Java程序中总会出现\u6b22\u8fce\u63d0\u4ea4\u5fae\u535a\u641c\u7d22\u4f7f\u7528\u53cd\u9988\uff0c\u8bf7\u76f4\u63a5这个的字符,这是unicode编码,使用时有时候不会自动转换成中文就需要自己转换了使用下面的方法转换一下即可。
/**
* unicode 转换成 中文
- 一站式 Java Web 框架 firefly
aijuans
Java Web
Firefly是一个高性能一站式Web框架。 涵盖了web开发的主要技术栈。 包含Template engine、IOC、MVC framework、HTTP Server、Common tools、Log、Json parser等模块。
firefly-2.0_07修复了模版压缩对javascript单行注释的影响,并新增了自定义错误页面功能。
更新日志:
增加自定义系统错误页面功能
- 设计模式——单例模式
ayaoxinchao
设计模式
定义
Java中单例模式定义:“一个类有且仅有一个实例,并且自行实例化向整个系统提供。”
分析
从定义中可以看出单例的要点有三个:一是某个类只能有一个实例;二是必须自行创建这个实例;三是必须自行向系统提供这个实例。
&nb
- Javascript 多浏览器兼容性问题及解决方案
BigBird2012
JavaScript
不论是网站应用还是学习js,大家很注重ie与firefox等浏览器的兼容性问题,毕竟这两中浏览器是占了绝大多数。
一、document.formName.item(”itemName”) 问题
问题说明:IE下,可以使用 document.formName.item(”itemName”) 或 document.formName.elements ["elementName&quo
- JUnit-4.11使用报java.lang.NoClassDefFoundError: org/hamcrest/SelfDescribing错误
bijian1013
junit4.11单元测试
下载了最新的JUnit版本,是4.11,结果尝试使用发现总是报java.lang.NoClassDefFoundError: org/hamcrest/SelfDescribing这样的错误,上网查了一下,一般的解决方案是,换一个低一点的版本就好了。还有人说,是缺少hamcrest的包。去官网看了一下,如下发现:
- [Zookeeper学习笔记之二]Zookeeper部署脚本
bit1129
zookeeper
Zookeeper伪分布式安装脚本(此脚本在一台机器上创建Zookeeper三个进程,即创建具有三个节点的Zookeeper集群。这个脚本和zookeeper的tar包放在同一个目录下,脚本中指定的名字是zookeeper的3.4.6版本,需要根据实际情况修改):
#!/bin/bash
#!!!Change the name!!!
#The zookeepe
- 【Spark八十】Spark RDD API二
bit1129
spark
coGroup
package spark.examples.rddapi
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.SparkContext._
object CoGroupTest_05 {
def main(args: Array[String]) {
v
- Linux中编译apache服务器modules文件夹缺少模块(.so)的问题
ronin47
modules
在modules目录中只有httpd.exp,那些so文件呢?
我尝试在fedora core 3中安装apache 2. 当我解压了apache 2.0.54后使用configure工具并且加入了 --enable-so 或者 --enable-modules=so (两个我都试过了)
去make并且make install了。我希望在/apache2/modules/目录里有各种模块,
- Java基础-克隆
BrokenDreams
java基础
Java中怎么拷贝一个对象呢?可以通过调用这个对象类型的构造器构造一个新对象,然后将要拷贝对象的属性设置到新对象里面。Java中也有另一种不通过构造器来拷贝对象的方式,这种方式称为
克隆。
Java提供了java.lang.
- 读《研磨设计模式》-代码笔记-适配器模式-Adapter
bylijinnan
java设计模式
声明: 本文只为方便我个人查阅和理解,详细的分析以及源代码请移步 原作者的博客http://chjavach.iteye.com/
package design.pattern;
/*
* 适配器模式解决的主要问题是,现有的方法接口与客户要求的方法接口不一致
* 可以这样想,我们要写这样一个类(Adapter):
* 1.这个类要符合客户的要求 ---> 那显然要
- HDR图像PS教程集锦&心得
cherishLC
PS
HDR是指高动态范围的图像,主要原理为提高图像的局部对比度。
软件有photomatix和nik hdr efex。
一、教程
叶明在知乎上的回答:
http://www.zhihu.com/question/27418267/answer/37317792
大意是修完后直方图最好是等值直方图,方法是HDR软件调一遍,再结合不透明度和蒙版细调。
二、心得
1、去除阴影部分的
- maven-3.3.3 mvn archetype 列表
crabdave
ArcheType
maven-3.3.3 mvn archetype 列表
可以参考最新的:http://repo1.maven.org/maven2/archetype-catalog.xml
[INFO] Scanning for projects...
[INFO]
- linux shell 中文件编码查看及转换方法
daizj
shell中文乱码vim文件编码
一、查看文件编码。
在打开文件的时候输入:set fileencoding
即可显示文件编码格式。
二、文件编码转换
1、在Vim中直接进行转换文件编码,比如将一个文件转换成utf-8格式
&
- MySQL--binlog日志恢复数据
dcj3sjt126com
binlog
恢复数据的重要命令如下 mysql> flush logs; 默认的日志是mysql-bin.000001,现在刷新了重新开启一个就多了一个mysql-bin.000002
- 数据库中数据表数据迁移方法
dcj3sjt126com
sql
刚开始想想好像挺麻烦的,后来找到一种方法了,就SQL中的 INSERT 语句,不过内容是现从另外的表中查出来的,其实就是 MySQL中INSERT INTO SELECT的使用
下面看看如何使用
语法:MySQL中INSERT INTO SELECT的使用
1. 语法介绍
有三张表a、b、c,现在需要从表b
- Java反转字符串
dyy_gusi
java反转字符串
前几天看见一篇文章,说使用Java能用几种方式反转一个字符串。首先要明白什么叫反转字符串,就是将一个字符串到过来啦,比如"倒过来念的是小狗"反转过来就是”狗小是的念来过倒“。接下来就把自己能想到的所有方式记录下来了。
1、第一个念头就是直接使用String类的反转方法,对不起,这样是不行的,因为Stri
- UI设计中我们为什么需要设计动效
gcq511120594
UIlinux
随着国际大品牌苹果和谷歌的引领,最近越来越多的国内公司开始关注动效设计了,越来越多的团队已经意识到动效在产品用户体验中的重要性了,更多的UI设计师们也开始投身动效设计领域。
但是说到底,我们到底为什么需要动效设计?或者说我们到底需要什么样的动效?做动效设计也有段时间了,于是尝试用一些案例,从产品本身出发来说说我所思考的动效设计。
一、加强体验舒适度
嗯,就是让用户更加爽更加爽的用
- JBOSS服务部署端口冲突问题
HogwartsRow
java应用服务器jbossserverEJB3
服务端口冲突问题的解决方法,一般修改如下三个文件中的部分端口就可以了。
1、jboss5/server/default/conf/bindingservice.beans/META-INF/bindings-jboss-beans.xml
2、./server/default/deploy/jbossweb.sar/server.xml
3、.
- 第三章 Redis/SSDB+Twemproxy安装与使用
jinnianshilongnian
ssdbreidstwemproxy
目前对于互联网公司不使用Redis的很少,Redis不仅仅可以作为key-value缓存,而且提供了丰富的数据结果如set、list、map等,可以实现很多复杂的功能;但是Redis本身主要用作内存缓存,不适合做持久化存储,因此目前有如SSDB、ARDB等,还有如京东的JIMDB,它们都支持Redis协议,可以支持Redis客户端直接访问;而这些持久化存储大多数使用了如LevelDB、RocksD
- ZooKeeper原理及使用
liyonghui160com
ZooKeeper是Hadoop Ecosystem中非常重要的组件,它的主要功能是为分布式系统提供一致性协调(Coordination)服务,与之对应的Google的类似服务叫Chubby。今天这篇文章分为三个部分来介绍ZooKeeper,第一部分介绍ZooKeeper的基本原理,第二部分介绍ZooKeeper
- 程序员解决问题的60个策略
pda158
框架工作单元测试
根本的指导方针
1. 首先写代码的时候最好不要有缺陷。最好的修复方法就是让 bug 胎死腹中。
良好的单元测试
强制数据库约束
使用输入验证框架
避免未实现的“else”条件
在应用到主程序之前知道如何在孤立的情况下使用
日志
2. print 语句。往往额外输出个一两行将有助于隔离问题。
3. 切换至详细的日志记录。详细的日
- Create the Google Play Account
sillycat
Google
Create the Google Play Account
Having a Google account, pay 25$, then you get your google developer account.
References:
http://developer.android.com/distribute/googleplay/start.html
https://p
- JSP三大指令
vikingwei
jsp
JSP三大指令
一个jsp页面中,可以有0~N个指令的定义!
1. page --> 最复杂:<%@page language="java" info="xxx"...%>
* pageEncoding和contentType:
> pageEncoding:它