一直想用docker搭建一套Hadoop集群用于日常学习和实验,最近终于有时间弄了,希望能帮到学习的人少走弯路吧
各个官网
Hadoop官网
Hive官网
HBase官网
ZooKeeper官网
一、准备前期工作
1.从官网上面下载文件
2.解压重命名文件
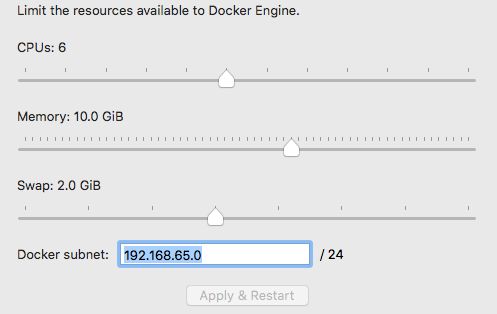
3.修改docker的可用内存,默认设置在2G,这里我修改成10G,修改完成记得点应用重启
4.拉取docker镜像
docker pull mamohr/centos-java
docker pull mysql
5.在自己电脑建立容器的映射文件,方便有时查看文件
6.开启3个集群容器和MySQL容器,并开放了集群的端口
# mysql hive的元数据
docker run --name hive-metadata -v /Volumes/data/docker/hadoop/mysql:/var/lib/mysql -e MYSQL_ROOT_PASSWORD=123456 -d mysql
docker run -d -i -t -p 9870:9870 -p 8088:8088 -p 16010:16010 -p 10000:10000 -p 2181:2181 -p 60000:60000 --privileged --name master --link hive-metadata:metadata -v /Volumes/data/docker/hadoop/master:/data mamohr/centos-java bin/bash
docker run -d -i -t --privileged --name slave1 -v /Volumes/data/docker/hadoop/slave1:/data mamohr/centos-java bin/bash
docker run -d -i -t --privileged --name slave2 -v /Volumes/data/docker/hadoop/slave2:/data mamohr/centos-java bin/bash
7.开启3个命令行窗口,分别进入3个集群的容器
docker attach master
docker attach slave1
docker attach slave2
8.集群的3个容器安装各种服务。在root用户下操作
yum install -y wget vim openssh-server openssh-clients net-tools
mkdir /var/run/sshd/
sed -i "s/UsePAM.*/UsePAM no/g" /etc/ssh/sshd_config
# 直接回车两次就行了
ssh-keygen -t rsa -f /etc/ssh/ssh_host_rsa_key
ssh-keygen -t ecdsa -f /etc/ssh/ssh_host_ecdsa_key
ssh-keygen -t ed25519 -f /etc/ssh/ssh_host_ed25519_key
#开启ssh服务
/usr/sbin/sshd -D &
#设置root用户密码,这里我填的是123456,连续两次输入
passwd
9.使用ifconfig查看每个容器的ip地址,并修改master的/etc/hosts添加下面内容
172.17.0.3 master
172.17.0.4 slave1
172.17.0.5 slave2
10.将hosts文件发往另外两台容器,因为root没做免密处理,所以需要输入root用户密码
scp /etc/hosts root@slave1:/etc/
scp /etc/hosts root@slave2:/etc/
11.将解压好的安装文件夹复制到master容器,在自己电脑上面执行
docker cp hadoop-3.2.1/ master:/opt
docker cp hive-3.1.2 master:/opt
docker cp mysql-connector-java-8.0.17.jar master:/opt/hive-3.1.2/lib
docker cp hbase-2.2.1/ master:/opt/
docker cp zookeeper-3.5.5/ master:/opt/
12.集群的3个容器都要添加hadoop用户
#添加用户
adduser hadoop
#设置hadoop用户密码,这里我填的是123456,连续两次输入
passwd hadoop
13.在master容器,修改文件夹拥有者为hadoop用户
chown -R hadoop:hadoop /opt/hadoop-3.2.1/
chown -R hadoop:hadoop /opt/hive-3.1.2
chown -R hadoop:hadoop /opt/hbase-2.2.1/
chown -R hadoop:hadoop /opt/zookeeper-3.5.5/
14.在master容器做免密SSH处理,在hadoop用户上进行
# 切换到hadoop用户
su hadoop
# 直接两次回车
ssh-keygen -t rsa
# 需要输入hadoop用户密码
ssh-copy-id -i /home/hadoop/.ssh/id_rsa.pub hadoop@master
ssh-copy-id -i /home/hadoop/.ssh/id_rsa.pub hadoop@slave1
ssh-copy-id -i /home/hadoop/.ssh/id_rsa.pub hadoop@slave2
15.在master容器上配置环境变量,在hadoop用户上进行。vim ~/.bash_profile
export JAVA_HOME=/usr/java/latest
export CLASSPATH=$JAVA_HOME/lib/
export PATH=$PATH:$JAVA_HOME/bin
export HADOOP_HOME=/opt/hadoop-3.2.1
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export HIVE_HOME=/opt/hive-3.1.2
export PATH=$PATH:$HIVE_HOME/bin
export HIVE_CONF_DIR=$HIVE_HOME/conf
export HIVE_AUX_JARS_PATH=$HIVE_HOME/lib
export ZOOKEEPER_HOME=/opt/zookeeper-3.5.5
export PATH=$PATH:$ZOOKEEPER_HOME/bin
export HBASE_HOME=/opt/hbase-2.2.1
export PATH=$PATH:$HBASE_HOME/bin
16.在master容器下将环境变量发往slave1和slave2
scp ~/.bash_profile hadoop@slave1:~
scp ~/.bash_profile hadoop@slave2:~
17.在master容器下使变量生效
source ~/.bash_profile
ssh hadoop@slave1 'source ~/.bash_profile'
ssh hadoop@slave2 'source ~/.bash_profile'
二、配置Hadoop
1.在master容器下,进入/opt/hadoop-3.2.1/etc/hadoop目录下修改配置文件
hadoop-env.sh
export JAVA_HOME=/usr/java/latest
core-site.xml
fs.defaultFS
hdfs://master:9000
hadoop.tmp.dir
/data/tmp
hdfs-site.xml
dfs.namenode.name.dir
/data/nameNode
dfs.datanode.data.dir
/data/dataNode
dfs.replication
2
dfs.namenode.secondary.http-address
slave1:9001
dfs.webhdfs.enabled
true
dfs.permissions
false
mapred-site.xml
mapreduce.framework.name
yarn
yarn.app.mapreduce.am.env
HADOOP_MAPRED_HOME=/opt/hadoop-3.2.1/
mapreduce.map.env
HADOOP_MAPRED_HOME=/opt/hadoop-3.2.1/
mapreduce.reduce.env
HADOOP_MAPRED_HOME=/opt/hadoop-3.2.1/
yarn-site.xm
yarn.resourcemanager.hostname
master
yarn.nodemanager.aux-services
mapreduce_shuffle
workers
master
slave1
slave2
2.配置好Hadoop之后,将Hadoop发往slave1和slave2
scp -r /opt/hadoop-3.2.1/ root@slave1:/opt/
scp -r /opt/hadoop-3.2.1/ root@slave2:/opt/
3.修改文件权限,这里要输入root密码
ssh root@slave1 'chown -R hadoop:hadoop /opt/hadoop-3.2.1/'
ssh root@slave2 'chown -R hadoop:hadoop /opt/hadoop-3.2.1/'
4.开启hadoop服务
hdfs namenode -format
start-all.sh
# 查看NameNode,DataNode服务是否开启
jps
5.校验MapReduce是否可以运行
hdfs dfs -mkdir /input/
hdfs dfs -put /opt/hadoop-3.2.1/LICENSE.txt /input/
hadoop jar /opt/hadoop-3.2.1/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar wordcount /input /output
三、配置Hive
在maser容器下的hadoop用户下,进入/opt/hive-3.1.2/conf目录下配置
1.创建hive的配置文件
cp hive-log4j2.properties.template hive-log4j2.properties
hive-site.xml
system:java.io.tmpdir
/data/tmpdir
system:user.name
hadoop
javax.jdo.option.ConnectionUserName
root
javax.jdo.option.ConnectionPassword
123456
javax.jdo.option.ConnectionURL
jdbc:mysql://metadata:3306/hive?createDatabaseIfNotExist=true
javax.jdo.option.ConnectionDriverName
com.mysql.cj.jdbc.Driver
2.修改hive-log4j2.properties
#修改日志文件地址
property.hive.log.dir = /opt/hive-3.1.2/logs
3.Hive元数据初始化
schematool -dbType mysql -initSchema
发现下面问题,这个hive下面的guava冲突了,改成使用hadoop的guava
Exception in thread "main" java.lang.NoSuchMethodError: com.google.common.base.Preconditions.checkArgument(ZLjava/lang/String;Ljava/lang/Object;)V
at org.apache.hadoop.conf.Configuration.set(Configuration.java:1357)
at org.apache.hadoop.conf.Configuration.set(Configuration.java:1338)
at org.apache.hadoop.mapred.JobConf.setJar(JobConf.java:536)
at org.apache.hadoop.mapred.JobConf.setJarByClass(JobConf.java:554)
at org.apache.hadoop.mapred.JobConf.(JobConf.java:448)
at org.apache.hadoop.hive.conf.HiveConf.initialize(HiveConf.java:4045)
at org.apache.hadoop.hive.conf.HiveConf.(HiveConf.java:4008)
at org.apache.hive.beeline.HiveSchemaTool.(HiveSchemaTool.java:82)
at org.apache.hive.beeline.HiveSchemaTool.main(HiveSchemaTool.java:1117)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hadoop.util.RunJar.run(RunJar.java:323)
at org.apache.hadoop.util.RunJar.main(RunJar.java:236)
解决方案
删除apache-hive-3.1.2/lib/guava-14.0.1.jar,复制hadoop的过来
rm /opt/hive-3.1.2/lib/guava-19.0.jar
cp /opt/hadoop-3.2.1/share/hadoop/common/lib/guava-27.0-jre.jar /opt/hive-3.1.2/lib/
4.启动hiveserver
nohup hive --service hiveserver2 > /opt/hive-3.1.2/logs/hiveserver2.log&
四、配置zookeeper
在maser容器下的hadoop用户下,进入/opt/zookeeper-3.5.5/conf目录下配置
cp zoo_sample.cfg zoo.cfg
1.配置zoo.cfg
dataDir=/data/zookeeper/data
dataLogDir=/opt/zookeeper-3.5.5/logs/
server.1=master:2888:3888
server.2=slave1:2888:3888
server.3=slave2:2888:3888
2.创建文件夹,在hadoop用户下进行
mkdir /data/zookeeper/
mkdir /data/zookeeper/data
ssh hadoop@slave1 'mkdir /data/zookeeper/'
ssh hadoop@slave1 'mkdir /data/zookeeper/data'
ssh hadoop@slave2 'mkdir /data/zookeeper'
ssh hadoop@slave2 'mkdir /data/zookeeper/data'
3.创建myid文件
echo "1" > /data/zookeeper/data/myid
ssh hadoop@slave1 'echo "2" > /data/zookeeper/data/myid'
ssh hadoop@slave2 'echo "3" > /data/zookeeper/data/myid'
4.将zookeeper发给其他容器
scp -r /opt/zookeeper-3.5.5/ root@slave1:/opt/
scp -r /opt/zookeeper-3.5.5/ root@slave2:/opt/
5.修改所属用户
ssh root@slave1 'chown -R hadoop:hadoop /opt/zookeeper-3.5.5'
ssh root@slave2 'chown -R hadoop:hadoop /opt/zookeeper-3.5.5'
8.启动zookeeper
zkServer.sh start
ssh hadoop@slave1 '/opt/zookeeper-3.5.5/bin/zkServer.sh start'
ssh hadoop@slave2 '/opt/zookeeper-3.5.5/bin/zkServer.sh start'
五、配置HBase
1.在maser容器下的hadoop用户下,进入/opt/hbase-2.2.1/conf目录下配置
hbase-env.sh
export JAVA_HOME=/usr/java/latest
export HBASE_CLASSPATH=/opt/hadoop-3.2.1/etc/hadoop/
hbase-site.xml
hbase.unsafe.stream.capability.enforce
false
hbase.rootdir
hdfs://master:9000/hbase
hbase.cluster.distributed
true
hbase.tmp.dir
/data/tmp
hbase.zookeeper.quorum
master,slave1,slave2
regionservers
slave1
slave2
2.将hbase发给其他容器
scp -r /opt/hbase-2.2.1 root@slave1:/opt/
scp -r /opt/hbase-2.2.1 root@slave2:/opt/
3.修改所属用户
ssh root@slave1 'chown -R hadoop:hadoop /opt/hbase-2.2.1'
ssh root@slave2 'chown -R hadoop:hadoop /opt/hbase-2.2.1'
4.启动HBase
start-hbase.sh