Python爬虫学习笔记_DAY_27_Python爬虫之requests库实战_绕过古诗文网登录页面及验证码的破解方法【Python爬虫】
p.s.高产量博主,点个关注不迷路!
目录
I.实战需求确定
II.抓取古诗文网登录接口
III.难点分析
IV.隐藏域的解决方法
V.验证码的破解办法:
V.I 手动输入
V.II 图像识别
V.III 打码平台:超级鹰打码
VI.完整源码
I.实战需求确定
本次实战主要的目的是复习requests库的基本语法,同时介绍一些新的内容:登录接口的抓取方式、session的使用、隐藏域问题的解决、验证码的破解方法等。
需求是这样的:首先,我们可以打开古诗文网:
接线来点击一下 我的 选项:

此时我们需要登录后,才能看到个人下面的个人信息页:

但是我们本次实战的需求是,无需登录(绕过登录),获取个人页面的源码信息。
II.抓取古诗文网登录接口
确定了需求后,我们可以简单分析一下我们的实现思路:首先,我们需要抓取相关的登录接口,接下来把接口放入代码中,获取相关参数、搭配相关的参数,实现绕过登录的目的。
于是先进行第一步:抓取古诗文网的登录接口:
1️⃣ 回到刚才的古诗文网登录页面:
我们按F12,解析网页:

此时在Network中的Name栏第一项login.aspx很类似我们需要的接口,然而当我们查看它的具体内容后发现,这并不是真正的登录接口,理由有两个:
首先是因为我们的登录信息是放在input文本框中的,因此接口应该是POST请求,而这个接口是GET请求;
其次是我们在Headers中找不到相关的登录参数,例如用户名、密码和验证码。
于是有一个获取登录接口的小技巧:输入一组错误的用户名或密码或验证码,之后我们就能在Network中找到真正的登录接口:

上面的操作中,记得先按F12,而后不要关闭F12,而是输入一组错误的信息,之后也不要点网页提示的 确定 按钮,否则接口会消失。
找到接口之后,我们保存接口的url,同时点击Payload,查看POST请求的参数(一些谷歌浏览器版本的参数在Headers项的下面,其他的版本在Payload里):
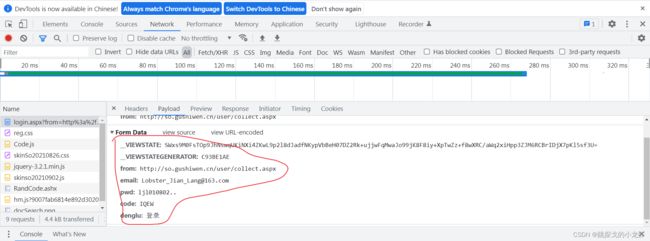
此时我们了解到,参数有 __VIEWSTATE 、__VIEWSTATEGENERATOR、from、email、pwd、code、denglu 这七个参数,而且其中的 from、email、pwd、denglu 这四个参数是我们已知的或者固定的,其他四个是未知的。
III.难点分析
接口和参数抓到之后,接下来分析一下我们的难点:解决 __VIEWSTATE 、__VIEWSTATEGENERATOR、code 三个参数。
前两个参数 __VIEWSTATE、__VIEWSTATEGENERATOR 是一种叫隐藏域的技术手段,它是一种反爬虫的手段,我们需要一些方法去解决这两个参数。
最后一个参数code,即验证码,需要我们采取一些必要的方法去解决(获取)。
IV.隐藏域的解决方法
首先解决隐藏域问题:
隐藏域是什么意思呢?我们的POST请求提交的参数是由input表单域发起的,因此按照传统的思维方法,所有的参数都应该在网页中有对应的input文本框,但是有一些参数没有对应的input文本框,这些参数被隐藏了,这类问题称为隐藏域问题。
隐藏域问题常见的解决方法是在网页源码中搜寻参数的踪迹:
我们回到古诗文网的登录页面,并按F12解析源码:
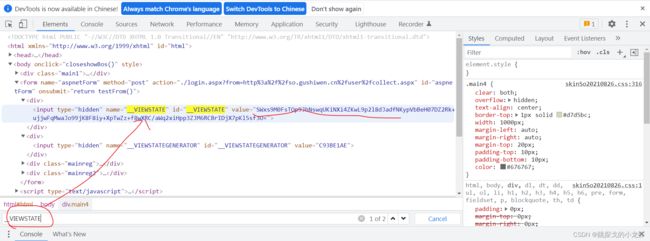

可以看到,当我们按Ctrl + f,并分别输入__VIEWSTATE、__VIEWSTATEGENERATOR进行查询时,果然在它的源码中找到了这两个参数,于是这个参数问题解决了。
V.验证码的破解办法:
最后我们着手解决一下验证码的问题,之前的实战中,这个问题是手动输入的,这次会介绍另外的两种方式:图像识别、打码平台破解。
V.I 手动输入
首先回顾一下手动输入法,这种方法就是我们通过把验证码对应的图片下载下来,而后看到图片上的验证码内容,通过python的input函数,读入验证码。

但是这种方式,并没有实现真正的全自动,因此我们探索另外两种方法。
V.II 图像识别
第二种方法是图像识别,下面进行介绍:
首先,我们安装一下图像识别需要的插件和库:
1️⃣ 下载插件:Tesseract-OCR,并放到任意的目录下(但是要记住这个位置,后面会用到),这里提供Tesseract-OCR的下载链接(提取码:dxzj)
2️⃣ 安装pytesseract和Pillow库。
首先查看自己的python interpret的路径,找到里面的Scripts文件夹,打开终端,用终端进入这个文件夹:



执行安装指令:
pip install pytesseract
pip install Pillow之后我们还差一步:修改pytesseract.py文件中的一句代码:
首先,我们先找到pytesseract.py文件:它的路径在python安装目录下的Lib文件夹里的set-packages文件夹,进入set-packages文件夹,找到一个叫pytesseract的文件夹,里面有pytesseract.py文件。


打开这文件,把画红圈这行代码的内容换成刚才安装Tesseract-OCR的安装路径(要定位到tesseract.exe)
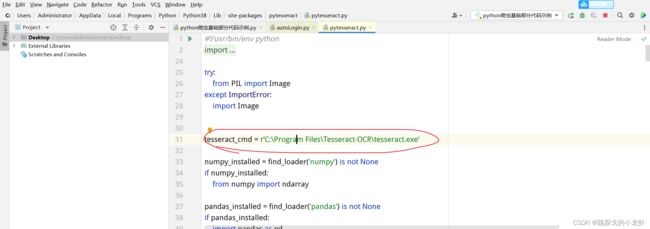
最后我们就可以顺利在代码中导入图像识别库,并调用相关代码做图像识别:
from PIL import Image
import pytesseract
text = pytesseract.image_to_string(Image.open(r'demo.png'))
print(text)我们在识别图像时,直接复制上面的代码,把Image.open函数中,换成对应的图像的路径即可。
V.III 打码平台:超级鹰打码
最后一种方式是使用打码平台,我们以超级鹰打码为例:
我们进入它的官网,点击开发文档,选择python:

之后点击下载:

之后会下载下来一个压缩包,我们只需要里面的一个叫chaojiying.py的文件:

上面的步骤如果懒得走,可以直接点我的分享链接下载chaojiying.py文件(提取码:dxzj)
之后我们打开这个py文件,滑到最下面,if__name=='__main': 这里面是我们需要自己修改的部分(其他的内容不要改动!!!) :

这部分首先我们需要把print函数加一个括号,改成print(),之后我们观察这部分代码,需要自定义的有两个地方:im和chaojiying.PostPic()这两部分:
im这部分,我们把需要识别的图像路径传入即可;
PostPic()函数的第一个参数就是im,第二个参数是需要我们在超级鹰平台自己的账号下获取的:
我们返回超级鹰官网,注册一个自己的账号,而后进入自己的账号:

选择 软件ID:

之后我们点击生成一个软件ID,填写信息,名称随便起一个,说明不需要填写,而后点击提交即可。

之后可以看到我们刚才创建的软件ID值:

此时我们把这个id作为参数传入刚才的chaojiying.PostPic()函数中作为第二个参数即可。
补充:此时我们还无法真正识别图像,原因是我们没有充值money,我们可以这样充值:


作为学习的目的,我们选择其他金额,充值1元玩一玩即可。
在这个页面,可以看到我们充值的金额与打码收费标准:验证码类型与价格表-超级鹰验证码识别
VI.完整源码
最后,附上本次实战的源码:
import requests
# 登录页面的url接口地址
url = 'https://so.gushiwen.cn/user/login.aspx?from=http://so.gushiwen.cn/user/collect.aspx'
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36'
}
response = requests.get(url = url,headers = headers)
content = response.text
# print(content)
# 解析源码,获取__VIEWSTATE __VIEWSTATEGENERATOR
from bs4 import BeautifulSoup
soup = BeautifulSoup(content,'lxml')
# 获取 __VIEWSTATE 的value值
__VIEWSTATE = soup.select('#__VIEWSTATE')[0].attrs.get('value')
# 获取__VIEWSTATEGENERATOR的value属性值
__VIEWSTATEGENERATOR = soup.select('#__VIEWSTATEGENERATOR')[0].attrs.get('value')
print(__VIEWSTATEGENERATOR)
print(__VIEWSTATE)
# 获取验证码的图片
basic_url = 'https://so.gushiwen.cn'
code_url = basic_url + soup.select('#imgCode')[0].attrs.get('src')
# session:验证码的一致性,requests库里有一个session方法,
# session的返回值,能够使请求变成一个对象
session = requests.session()
# 验证码的url的内容
response_code = session.get(code_url)
# 此时要使用二进制数据,因为我们要使用的是图片的下载,图片转二进制下载
content_code = response_code.content
# wb的模式是将二进制数据写入文件
with open('code.jpg','wb') as fp:
fp.write(content_code)
# 获取验证码的图片,下载到本地,观察它的内容:
# 控制台,输入验证码:
code_name = input('请输入你的验证码:')
#
# 点击登录
url_post = 'https://so.gushiwen.cn/user/login.aspx?from=http%3a%2f%2fso.gushiwen.cn%2fuser%2fcollect.aspx'
data_post = {
'__VIEWSTATE' : __VIEWSTATE,
'__VIEWSTATEGENERATOR' : __VIEWSTATEGENERATOR,
'from' : 'http://so.gushiwen.cn/user/collect.aspx',
'email': '[email protected]',
'pwd': 'ljl010802',
'code': code_name,
'denglu': '登录'
}
response_post = session.post(url = url_post,headers = headers,data = data_post)
content_post = response_post.text
with open('gushiwen.html','w',encoding = 'utf-8') as fp:
fp.write(content_post)
# 第二种验证码方式:图像识别
# from PIL import Image
# import pytesseract
#
# code_name = pytesseract.image_to_string(Image.open(r'code.jpg'))以上是本次实战的完整博文!