1.hdfs的特征
1.1大规模数据分布存储能力
1.2高并发访问能力
1.3强大的容错能力
1.4顺序式文件访问
1.5简单的一致性模型
1.6数据块存储方式
2.hdfs的基本组成结构与访问过程
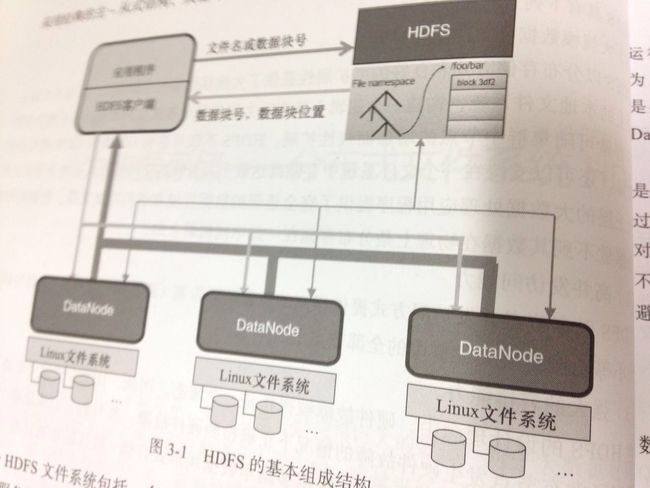
hdfs的基本文件访问过程:
2.1首先,用户的应用程序通过hdfs的客户端程序将文件名发送至NameNode。
2.2NameNode接收到文件名之后,在hdfs的目录中检索文件名对应的数据块,再根据数据块的信息找到保存数据块的DataNode地址,将这些地址回送到客户端。
2.3客户端接收到这些DataNode地址后,与这些DataNode并行地进行数据传输操作,同时将操作结果的相关日志(比如是否成功,修改后的数据块信息等)提交到NameNode。
数据块 命名空间 通信协议 客户端
3.hdfs可靠性设计
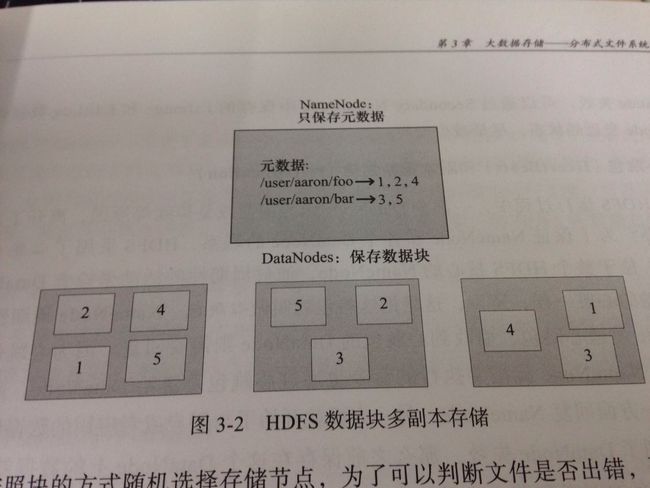
安全模式、SecondaryNameNode、心跳包和副本重新创建、数据一致性(数据校验)、租约、回滚
4.hdfs文件存储组织和读写
4.1文件数据的存储组织
1.NameNode的目录结构
2.DataNode的目录结构
3.CheckPointNode
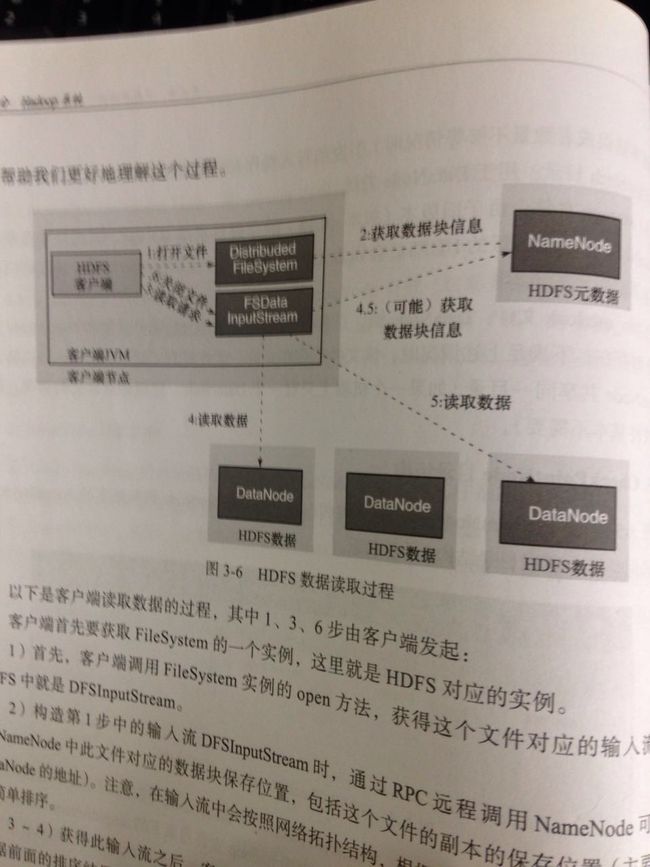
5.数据的读写过程
1.读取
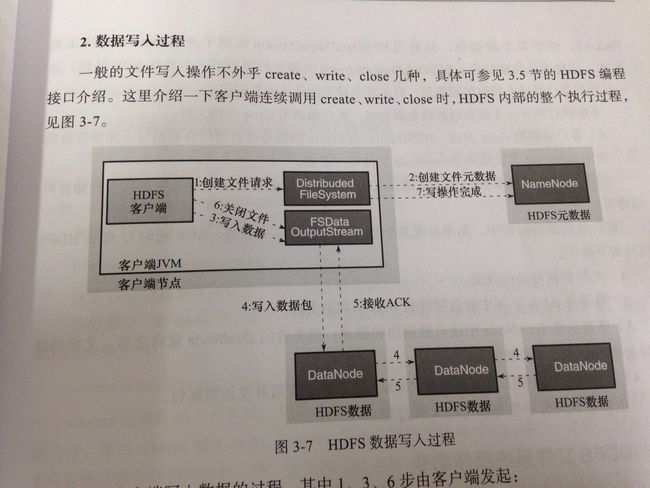
2.写入
6.hdfs文件操作系统操作命令
hdfs文件操作命令
查看文件:hadoop dfs -put Downloads/train.csv hdfs://localhost:9000/user/hadoop
hadoop dfs -cat hdfs://localhost:9000/user/hadoop/train.csv
改变文件所属用户组:chgrp
改变文件权限:chmod
改变用户的所属用户:chown
上传到hdfs:put
下载到本地:get
统计目录下目录数、文件数、字节数:count
hadoop dfs -count hdfs://localhost:9000/user/hadoop
结果:
3 11 87933 hdfs://localhost:9000/user/hadoop
将文件拷贝到目标路径
hadoop dfs -cp hdfs://localhost:9000/user/hadoop/output hdfs://localhost:9000/user/hadoop/input
显示目录下文件及大小
hadoop dfs -du /user/hadoop/input
累加大小:hadoop dfs -du -s /user/hadoop/input
易于阅读:hadoop dfs -du -h /user/hadoop/input
清空回收站
hadoop dfs -expunge
将文件拷贝到本地
hadoop dfs -get /user/hadoop/input/output/_SUCCESS /home/hadoop
将文件夹合并到本地文件夹下
hadoop dfs -get /user/hadoop/input/output/ /home/hadoop/merge_test
返回文件状态
hadoop dfs -ls
返回递归的文件状态
hadoop dfs -lsr
创建文件夹
hadoop dfs -mkdir /user/hadoop/hdfs
上传或下载后删除源文件
moveFromLocal
moveToLocal
移动数据
mv(不可跨文件系统)
put
上传,可以从标准输入中读取,用-表示本地文件。
hadoop dfs -put - /user/hadoop/hdfs/a.txt
rm、rmr
删除文件
setrep
更改副本数
stat
返回对应路径的状态信息
hadoop dfs -stat /user/hadoop/hdfs
tail
在标准输出中显示文件末尾1KB的数据
hadoop dfs -tail /user/hadoop/input/hdfs-site.xml
test
判断文件信息
hadoop dfs -test -e[-z或-d]
text
将文本文件或某些格式的非文本文件通过文本格式输出
touchz
创建一个大小为0的文件
hadoop dfs -touch
hdfs高级功能
archive(存在问题)
hadoop archive -archiveName hdfs.har -p /user/hadoop/input /outputdir
balancer
hadoop balancer [-threshold
distcp2
dfsadmin
6.hdfs实例
找出目录下所有包含hadoop文字的行,输入到本地文本中。
import java.util.Scanner;
import java.io.IOException;
import java.io.File;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
public class resultFilter {
public static void main(String[] args) throws IOException {
// TODO Auto-generated method stub
Configuration conf=new Configuration();
FileSystem hdfs=FileSystem.get(conf);
FileSystem local=FileSystem.getLocal(conf);
System.out.println(args.length);
Path inputDir,localFile;
FileStatus[] inputFiles;
FSDataOutputStream out=null;
FSDataInputStream in=null;
Scanner scan;
String str;
byte[] buf;
int singleFileLines;
int numLines,numFiles,i;
if(args.length!=4){
System.err.println("usage resultFilter "+"");
return;
}
inputDir=new Path(args[0]);
singleFileLines=Integer.parseInt(args[3]);
try{
inputFiles=hdfs.listStatus(inputDir);
numLines=0;
numFiles=1;
localFile=new Path(args[1]);
if(local.exists(localFile))
local.delete(localFile,true);
for(i=0;i