本篇是学习SkipGram算法,对论文内容进行概括,方便查阅和总结
1 介绍
传统的N-Gram方法在很多任务具有其局限性,比如,用于自动演讲识别中域数据量是有限的,而这部分的性能通常以高质量转录的语音数据的大小为主。在机器翻译中,现存的许多语言的预料库仅仅有数以十亿的词汇或者更少。因此,简单地把这种基本方法扩大并不会在一些场景带来显著的进步,我们需要关注更加先进的技术。
1.1 本文目标
本文的主要目标是介绍可以用于从数以十亿单词的巨大数据集学习高质量单词向量。就目前来说,没有一种模型可以成功地训练超过数亿有着50-100维的词汇。
我们使用最近提出的方法去测量向量表示的质量,希望相似的单词不仅彼此相距较近,而且有不同维度的相似性。比如,名词可以有多个词尾,如果我们在原始的向量空间巡展相似的单词,可能会发现这些单词有相同的结尾。有点出人意料的是,据发现单词表示相似度超越了简单的合成规则。运用字偏移技术,对词向量进行简单代数运算,结果显示,向量-向量+向量接近于单词的向量表示。
在本文中,我们试图通过开发新的模型结构来保持单词之间的线性规律,来最大化这些向量操作的精度。我们设计了一个测量语法和语义规则的新的测试集。进一步,我们讨论了训练时间和准确率(accuracy)如何依赖于训练数据集大小与单词向量维度。
2 模型框架
在本文,我们关注通过神经网络学习单词的分布式表示。
与[18]的工作相似,为了计算不同模型框架的复杂度,我们定义了一个模型的计算复杂度是由训练这个模型所需要获得参数数量决定的。然后,我们会尝试最大化准确度,同时最小化计算的复杂度。
对于接下来的模型,训练的复杂度与下式成比例:
其中,是训练的次数,是训练集的单词数,是需要每个模型来决定。一般来说,,最大为十亿。所有的模型使用随机梯度下降和后向传播。
3 新对数线性模型
对于之前的模型,复杂度主要来源于模型中非线性的隐藏层。尽管这部分使神经网络如此迷人,我们决定探索不想神经网络表示地准确但是相对简单的模型,不过可以通过在很多数据集上进行训练使之变得好用。?(吴恩达的机器学习中有讲,对于欠拟合的模型,增加数据反而会使准确度变差。)
这个模型的框架与我们之前所做的工作相关,我们发现神经网络语言模型可以成功地在两步进行训练:首先,通过简单模型学习获得连续的词向量,然后,在这些分布的词表示之前对N-Gram进行训练。然而后来有大量的工作集中在学习向量表示上,我们认为之前[13]所提出的是一个最简单的方法。
3.1 连续词袋模型
第一个提出的方法与前馈神经网络语言模型有些类似,它把非线性的隐藏层去掉,然后映射层是对所有词共享的。因此,所有的词被映射到相同的位置。我们之所以称之为词袋是在因为历史单词的顺序不影响后面的映射。更进一步,我们还使用了将来的单词。训练的复杂度为我们把这个模型的改进版称为CBOW,与标准的词袋模型不同,它使用内容的连续分布表示。另外,输入和投影层之间的权重矩阵是为所有词共享的,这一点与NNLM相同。
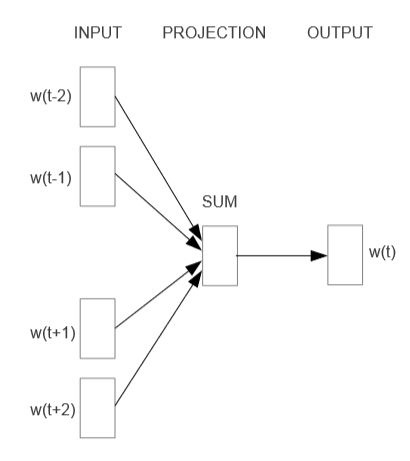
3.2 连续Skip-gram模型
Skip-gram模型不是基于上下文去预测当前词,而是通过在相同句子的另一个单词最大化一个词的分类。更准确的说,我们把每一个当前词作为一个拥有连续映射层的对数线性模型的输入,然后预测当前词上下文一定范围内出现的单词。我们发现增加这个范围会提高结果向量的质量,但是会增加计算的复杂度。因为距离最远的单词通常比距离较近的单词与当前词的关联程度低,我们通过在训练样本中抽取较少那些单词给予距离远的单词较小的权重。
这里是否可以这样理解,距离就已经考虑到一部分权重问题,因为距离越近的越容易出现在上下文,而距离较远的很少出现在上下文。
这个模型的训练复杂度与下式成比例:
其中,是最大距离。因此,如果我们选择,对于每个训练的单词,我们会从随机选择一个数字,然后从当前词之前挑选个单词,从当前此之后挑选个单词作为正确的标签。这会需要我们去做个单词的分类,输入时当前词,每个单词作为输出。
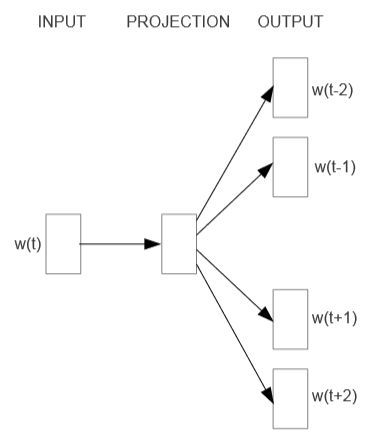
通过对比可以发现,词袋模型是通过上下文预测当前词,而Skip-gram模型是通过当前词预测上下文。现在问题的关键是,如何进行映射?这个映射结果有什么意义?
4 结果
去比较不同版本之间词向量的质量,之前文章的典型做法是使用一张表显示关键词和它们最相似的单词,然后从直觉上理解它们。虽然显示单词和单词是很容易的,但是当把这些向量进行更复杂的相似任务时可能会面临更多挑战。我们通过之前的观察发现单词之间存在许多种不同种类的相似性,例如单词和是相似的,同时和是相似的。另一种形式可能是单词对和。我们然后把拥有相同关系的两对单词作为一个问题,然后问:“什么单词与更接近,就像和更接近一样。”
令人惊奇的是,这些问题可以对词向量进行通过简单的线性操作来回答。去寻找与更相似,就像和相似一样,我们可以简单的计算。然后我们在向量空间寻找与在余弦距离和最接近的单词,然后用它来回答这个问题(我们把这个问题的输入单词在搜索过程种舍弃了)。当这个词向量被很好地训练的时候,可能用这个方法发现正确的答案(单词)。
最终,我们发现,当我们在大规模数据集上训练高纬词向量的时候,所得到的向量可以用来回答单词之间非常微妙的语义关系。例如一个城市和这个城市所属的国家。例如法国对巴黎相似于德国对柏林。有这种语义关系的词向量可以用来提高现在的许多NLP应用,例如机器翻译,信息提取和问答系统,还有可能促使一些应用被发明。
本文没有对两种模型进行详细的阐述,是因为这个模型太简单了吗?
更新:2018年11月9日 11点04分
找到了一个外国学者对这篇文章的评价,可以参考一下。
This paper introduces the Continuous Bag of Words (CBOW) and Skip-Gram models. However, don’t expect a particularly thorough description of these models in this paper…
I believe the reason for this is that these two new models are presented more as modifications to previously existing models for learning word vectors. Some of the terminology and concepts in this Word2Vec paper come from these past papers and are not redifined in Google’s paper.
A good example are the labels “projection layer” and “hidden layer” which come from the “NNLM” model. The term “projection layer” is used to refer to a middle layer of the neural network with no activation function, whereas “hidden layer” implies a non-linear activation.
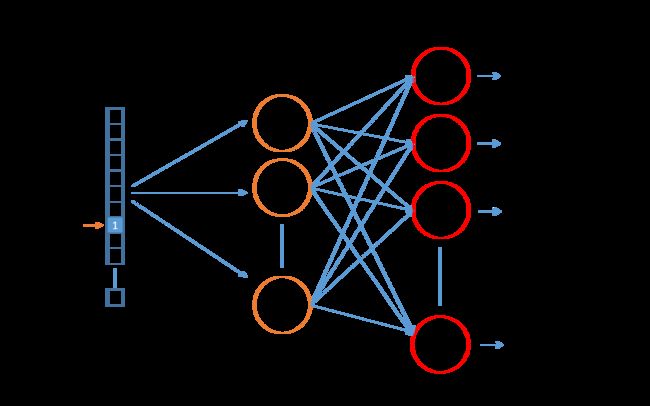
输入向量为单词“ants”的one-hot表示,然后通过隐藏层进行降维,获得300维度的词表示,最后通过输出层,输出与每个单词的相似度。

参考文献:
[1]Mikolov T, Chen K, Corrado G, et al. Efficient estimation of word representations in vector space[J]. arXiv preprint arXiv:1301.3781, 2013.
[2]Word2Vec Tutorial - The Skip-Gram Model