持续更新中
一、sparksql和python的时序处理
https://www.cnblogs.com/feiyumo/p/8760846.html
https://www.runoob.com/python/python-date-time.html
https://zhuanlan.zhihu.com/p/96384066
python的时间包主要是time和datetime,datetime是对time的高级封装,下文中能用datetime处理的基本上就用datetime处理(虽然部分用time也可以处理),其次还有pandas自带的一些时间方法
1.1 格式化符号
- sql
yyyy-MM-dd HH:mm:ss - python
%y 两位数的年份表示(00-99)
%Y 四位数的年份表示(000-9999)
%m 月份(01-12)
%d 月内中的一天(0-31)
%H 24小时制小时数(0-23)
%I 12小时制小时数(01-12)
%M 分钟数(00-59)
%S 秒(00-59)
所以有两种格式化方法:
%Y-%m-%d %H:%M:%S
%y-%m-%d %I:%M:%S
1.2 获取当前时间
- 获取当前时间戳
SELECT unix_timestamp(); 1476884637
import time
from datetime import datetime
time.time() #time模块的时间戳是最直接的
datetime.now().timestamp() # datetime的时间戳要转换一下
- 获取当前日期
select current_date; 2018-04-09
python的时间存在元祖结构,下面三者时间是一样的
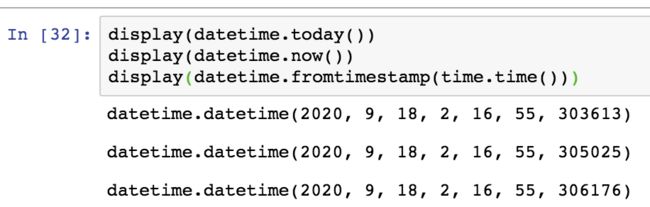

- 获取当前时间
select current_timestamp/now();2018-04-09 15:20:49.247

1.3 从日期中提取字段
- year,month,day/dayofmonth,hour,minute,second
select Examples:> SELECT day('2009-07-30'); 30
# datetime方法
datetime(2019,12,12,14,10,59).year #先构造元祖,再提取
datetime.strptime('2020-01-02 23:12:22','%Y-%m-%d %H:%M:%S').year #先将字符串转化为元祖,再提取
datetime.now().year #当前日期的元祖,再提取
# pandas方法
df = pd.DataFrame({'A':['2020-02-02','2019-11-03']},dtype='datetime64[ns]')
df.A.dt.year

- 其他
dayofweek\weekofyear
不常用,但是也有相关方法
1.4 日期时间转换
- 将时间戳转换为时间
SELECT from_unixtime(0, 'yyyy-MM-dd HH:mm:ss'); 1970-01-01 00:00:00
A=time.time() #时间戳
datetime.strftime(datetime.fromtimestamp(A),'%Y-%m-%d %H:%M:%S')
- 将时间转换为时间戳
SELECT to_unix_timestamp('2016-04-08', 'yyyy-MM-dd'); 1460041200
datetime(2019,10,11,23,12,12).timestamp()
- 字符串转换为特定时间格式(to_date和date_format的用法是一致的)
select to_date('2020-03-11 12:23:11', 'yyyy-MM-dd'); 2020-03-11
A='2020-03-11 12:23:11'
datetime.strftime(datetime.strptime(A,'%Y-%m-%d %H:%M:%S'),('%Y-%m-%d'))
python中的时间格式总是要经过转
1.5 日期计算
- 计算日期差(天)
SELECT datediff('2009-07-31', '2009-07-30'); 1
A = datetime(2020,1,1,12,23,23)
B = datetime(2020,1,2,12,23,45)
C=(B-A)
print(C.days)
print(C.total_seconds())
print(C.seconds)
进行日期运算会用到datetime.timedelta,timedelta最常用的三个方法就是days,seconds。。
- 日期加减
SELECT date_add('2016-07-30', 1); 2016-07-31
SELECT date_sub('2016-07-30', 1); 2016-07-29
from datetime import timedelta
A = datetime(2020,1,1,12,23,23)
delta = timedelta(days=1)
B = A+delta
print(B)
二、正则处理
https://www.runoob.com/python/python-reg-expressions.html#flags
https://github.com/ziishaned/learn-regex/blob/master/translations/README-cn.md
2.0 规范
- 表达式模式(列出了最主要的)
^: 匹配开头
$: 匹配结尾
.:匹配任意字符,除了换行符
[abd]: 匹配在[]中的字符
[^abd]: 匹配不在[]中的字符(这里就是非abc的字符,^有两种含义,在[]外表示匹配开头,在[]里面表示非)
*: 匹配0个或多个
?: 匹配0个或1个
{n}: 精确匹配n个
{n,}: 匹配至少n个
{n,m}: 匹配n~m个
a|b: 匹配a或b
(): 对匹配的文本进行分组
\w:匹配字母数字及下划线
\s:匹配任意空白字符,等价于 [ \t\n\r\f]
\d:匹配任意数字,等价于 [0-9].
- \t是tab,\n是换行,\r是回车,\f是换页,没有明确研究回车和换行的区别,一般情况下\t和\n使用比较多*
- 常用匹配实例
[0-9] :匹配任何数字。等价于\d
[a-zA-Z0-9] :匹配任何字母及数字
[^0-9] :匹配任何非数字。
2.1 匹配
先说一下常用标志位flag

re.I是最常用的
- re.search
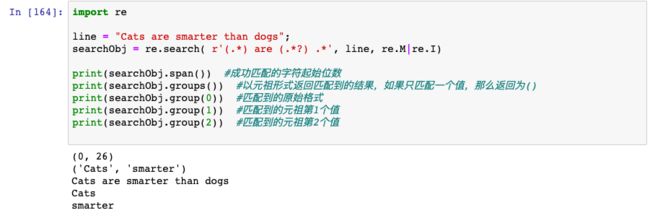
import re
line = "Cats are smarter than dogs";
searchObj = re.search( r'(.*) are (.*?) .*', line, re.M|re.I)
print(searchObj.span()) #成功匹配的字符起始位数
print(searchObj.groups()) #以元祖形式返回匹配到的结果,如果只匹配一个值,那么返回为()
print(searchObj.group(0)) #匹配到的原始格式
print(searchObj.group(1)) #匹配到的元祖第1个值
print(searchObj.group(2)) #匹配到的元祖第2个值
- re.match
和search的区别在于是从开头进行匹配,开头不能匹配则返回None -
re.findall
 image.png
image.png
findall是匹配所有结果,把每一次的结果(每一次相当于一次search,结果是一个元祖)加在列表里面,最终结果也直接返回一个列表(相当于多个search),不用group来取值
- .* 和.?的区别
.是贪婪匹配,每一次会尽可能的匹配更长的值,只匹配一次,.*?是懒惰匹配,每一次匹配更少的值,但是会匹配完,结果会有多个值
import re
line = "Cats are smarter than dogs";
searchObj1 = re.search( r'(.*) are (.*?) .*', line, re.M|re.I)
print(searchObj1.groups())
searchObj2 = re.search( r'(.*) are (.*) .*', line, re.M|re.I)
print(searchObj2.groups())

2.2 sub和split
字符串主要有4大功能,替换、拼接、分裂以及匹配,单纯的str方法可以实现replace、拼接(字符串相加就可以)split,此外依托于re还可以实现sub(正则替换)、split(正则拼接)和匹配
-
re.sub
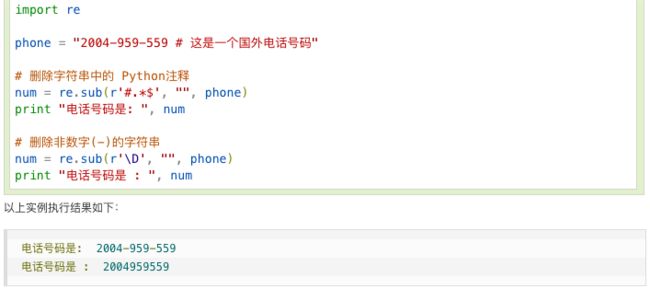 image.png
image.png -
re.split
 image.png
image.png
此外,还有re.compile的方法可以对正则进行先编译后匹配,但是感觉对于一般的处理,不用搞得那么麻烦(当然也不麻烦,只是要多掌握一种方法)