神经网络
神经网络最开始是受生物神经系统的启发,为了模拟生物神经系统而出现的。大脑最基本的计算单元是神经元,人类的神经系统中大概有86亿的神经元,它们之间通过1014-1015的突触相连接。每个神经元从它的树突(dendrites)接受输入信号,沿着唯一的轴突(axon)产生输出信号,而轴突通过分支(branches of axon),通过突触(synapses)连接到其他神经元的树突,神经元之间就这通过这样的连接,进行传递。如下图。

链式法则
先来回顾一下链式法则,这是反向传播算法的推导基础。

人工神经网络

人工神经网络其实就是按照一定规则模拟生物神经网络连接起来的多个神经元,也就是感知机。
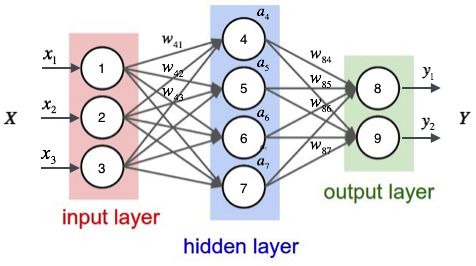
上图展示了一个全连接(full connected, FC)神经网络,一个全连接的网络要按照层来进行布局。
1.最左边的层叫做输入层,负责接收输入数据。
2.最右边的层叫输出层,我们可以从这层获取神经网络输出数据。
3.输入层和输出层之间的层叫做隐藏层,因为它们对于外部来说是不可见的。
4.同一层的神经元之间没有连接。
上图中,第N层的每个神经元和第N-1层的所有神经元相连(这就是full connected的含义),第N-1层神经元的输出就是第N层神经元的输入。并且每个连接都有一个权值。
这也就是全连接神经网络的结构。
事实上还存在很多其它结构的神经网络,比如卷积神经网络(CNN)、循环神经网络(RNN),他们都具有不同的连接规则。
神经元
神经网络上的激活函数为(并不是全部,还有其他的激活函数):

sigmoid函数的定义如下:
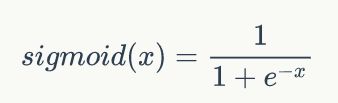
即:

图像表达为:

可以看出函数的取值范围为(0,1)。
当然为了计算方便,我们还要关注一下它的导数:

可以看出它的导数和它本身的数值相关。
工作原理
神经网络的作用就是简单的说,就是将输入的x,转化成输出的y。当然其中还要包括许多的处理。包括先从前往后,求取值,再从后往前更新权值。
下面以监督学习为例:
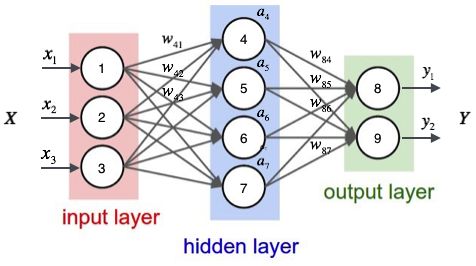
已知输入向量X,获取输 出向量Y。当然对于监督学习来说,我们会有许多的样本(X,Y),这里面的Y值是已知的,但是我们还要求得实际的Y值,来算取得本次样本数据的误差。
这就需要向前传播。
向前传播
从输入层到隐藏层:
对隐藏层的节点4来说,它的输出值a4为:
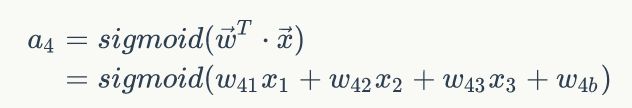
同理求得节点5,6,7的输出值a5,a6,a7。
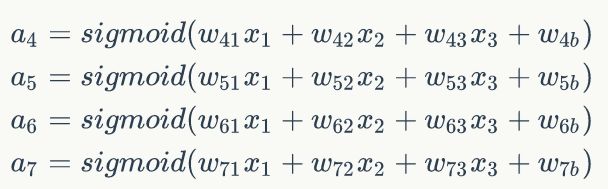
从隐藏层到输出层:
对于节点8来说,其输出值y1为:

同理y2:

所以对于实际输出向量Y来说,它和输入向量X的关系就是:
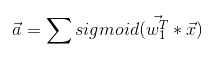
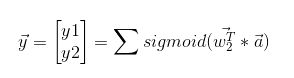
向后传播
获得实际的输出值后,我们就要来计算误差。
误差的计算方式:

将一次样本期望输出的向量值T(因为是神经网络,所以输出值为向量),减去实际输出的向量Y。其中d代表样本编号。
当然此时涉及到两层的权值向量的更改,就不能仅仅是向线性单元那样计算了,不过大致的思想是一直的,都是采用梯度下降的思想,不过这时候还要使用链式法则。
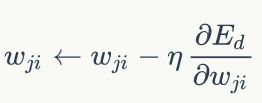
其中的i和j表示,从i节点指向j节点。
根据这种方式来求取对每个节点的权值的更新,当然这也有个问题,就是因为网络是多层的,无法直接的求得每一层的对权重的改变。

这就需要使用链式法则:

(来自零基础入门深度学习(3) - 神经网络和反向传播算法)
对输出层来说:
其中j代表第j个节点。
所以根据链式法则:
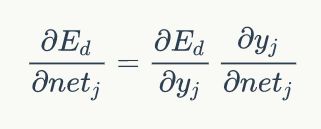
只考虑第一项:

只考虑第二项:

这里设定一个betal值:

及:
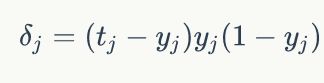
所以最后得到输出层的权重改变公式:
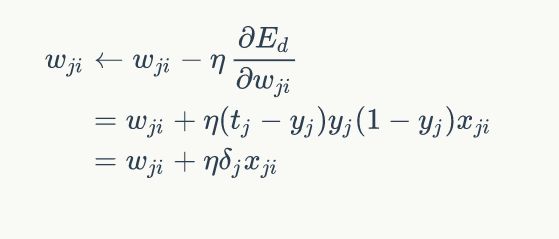
再考虑隐藏层:
对隐藏层来说,它对结果的改变主要是通过影响输出层的输入值来响应最后的输出结果。
这个就需要分开来考虑。
比如节点4,它的输出值可以分别影响到y1和y2.
所以对误差E来说,节点4的输出值a4对其的影响,可以写成:

扩展开来,也就是链式法则的全导数:
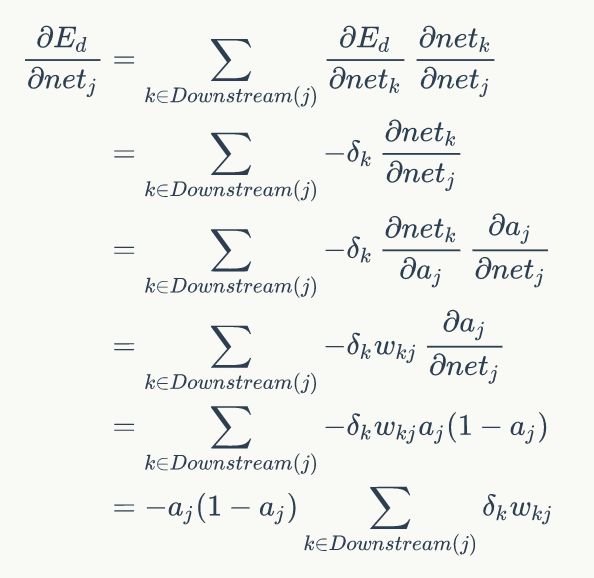
其中Downstream(j)代表所有j的下游节点的集合(比如节点4,它的下游节点为8,9),netk就表示下游节点的输入数据。
最后求得:
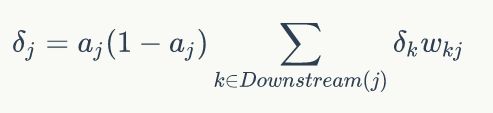
大功告成,根据以上的公式就可以来推断一下权值的更新了,下面举个例子来实践一下。(知行合一才是硬道理O(∩_∩)O哈哈~)
同时也感谢大神@hanbingtao的文章,让我这个小白理解了神经网络。感谢。
神经网络解决异或
异或问题在感知器的时候已经知道,因为它是非线性的所以无法用感知器来解决。不过可以使用神经网络尝试一下。
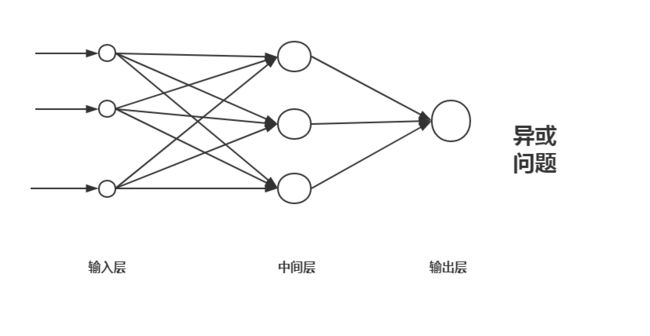
首先先构建神经网络,本次的网络构建如图所示。
代码
# coding=utf-8
# numpy 支持高级大量的维度数组与矩阵运算
import numpy as np
#定义坐标,设定5组输入数据,每组为(x0,x1,x2)
X=np.array([[1,0,0],
[1,0,1],
[1,1,0],
[1,1,1]]);
#设定输入向量的期待输出值
Y=np.array([0,1,1,0]);
#设定权值向量(V,W)
#输入层和隐藏层之间的权值
V = np.array([[0,0.1,0.7],
[0.5,0.2,0.1],
[0.1,0.1,0.3]]);
#隐藏层和输出层之间的权值
W = np.array([[0.2,0.1,0.3]]);
#设定学习率
lr = 0.5;
#sigmoid函数
def sigmoid(x):
return 1/(1+np.exp(-x));
#对sigmoid函数求导
def sigmoid_daoshu(x):
return x*(1-x);
def updateW():
global X,Y,V,W,lr,n;
#权值向量修正记录
W_C = np.array([[0,0,0]]);
V_C = np.array([[0,0,0],
[0,0,0],
[0,0,0]]);
#4个样本分别计算
for i in range(0,4):
##第一层(矩阵3*1)
layer_1_input = np.dot(V,np.array([X[i]]).T); ## V*X
layer_1_output = sigmoid(layer_1_input); ## a=f(V*X)
##第二层(矩阵1*1)
layer_2_input = np.dot(W,layer_1_output);
layer_2_output = sigmoid(layer_2_input);
#第二层的误差(矩阵1*1)
E_2 = Y[i] - layer_2_output.T;
## 输出层的detal(矩阵1*1)
layer_2_detal = E_2*sigmoid_daoshu(layer_2_output);
##隐藏层的误差(矩阵3*1)
E_1 = np.dot(W.T,layer_2_detal);
## 隐藏层的detal(矩阵3*1)
layer_1_detal = E_1*sigmoid_daoshu(layer_1_output);
##所有的W向量增加数值
W_C = W_C + np.dot(layer_2_detal, layer_1_output.T);
##所有的V向量增加数值
V_C = V_C + np.dot(layer_1_detal, np.array([X[i]]));
#求出平均数
W_d = W_C/4.0;
V_d = V_C/4.0;
#修改权值
W = W + lr*W_d;
V = V + lr*V_d;
if __name__ == '__main__':
output = [0,0,0,0];
#设置迭代次数
for index in range (10000):
updateW();
if index==0 or index==(10000-1):
#计算出结果
for i in range(0,4):
layer_1_input = np.dot(V,np.array([X[i]]).T);
layer_1_output = sigmoid(layer_1_input);
layer_2_input = np.dot(W,layer_1_output);
layer_2_output = sigmoid(layer_2_input);
output[i] = layer_2_output[0][0];
print output
运行结果

可以看出,经过10000次迭代,结果已经很接近了。
大功告成!!
回去吃大餐!
参考
神经网络基础介绍
https://blog.csdn.net/wq2610115/article/details/68928368
一文搞懂反向传播算法
https://www.jianshu.com/p/964345dddb70
零基础入门深度学习(3) - 神经网络和反向传播算法
https://www.zybuluo.com/hanbingtao/note/476663