超赞Transformer+CNN=SOTA!
点上方计算机视觉联盟获取更多干货
仅作学术分享,不代表本公众号立场,侵权联系删除
转载于:新智元
AI博士笔记系列推荐
周志华《机器学习》手推笔记正式开源!可打印版本附pdf下载链接
CNN更关注局部特征,需要的数据量更小,但能达到的sota性能更低;Transformer更关注全局特征,需要更多的数据来训练,但最近CV领域的sota模型都是基于Transformer的ViT。两个看似水火不相容的模型,如何各取所长?Facebook AI也许能告诉你。
不管是CNN还是Transformer,他们都不是「完美」的模型,一个重视局部特征,一个关注全局特征。
但如果把他们合并起来会发生什么?

Facebook AI Research在法国的分部最近提出了一种新的计算机视觉模型 ConViT,它结合了这两种常用的模型——卷积神经网络(CNNs)和Transformer,以克服它们各自的局限性。
通过利用这两种技术,这种基于视觉Transformer的模型的性能优于现有的模型架构,特别是在数据量比较少的情况下,同时大规模数据的情况下可以产生相似的性能,ICML 2021已经发表。

卷积架构已被证明在视觉任务方面非常成功,它能够对特征进行硬性(hard)归纳从而使样本学习变得十分高效,但代价是可能降低性能上限。
Vision Transformer (ViT) 依赖于更灵活的自注意力层,并且最近在图像分类方面的表现优于 CNN。然而,它们需要对大型外部数据集进行预训练或从预训练的卷积网络中提取特征。
AI研究人员在建立新的机器学习模型和训练范式时,往往使用一组特定的假设,通常称为归纳偏差(induction bias),因为它可以帮助模型从较少的数据中学习到更普遍的解决方案。CNN已被证明在视觉任务中非常成功,它依赖于模型本身内置的两种归纳偏差: 相邻的像素是相关的(局部性) ,以及图像的不同部分不管其绝对位置(权重分担)都应该进行相同的处理。
相比之下,基于自注意的视觉模型(如Data-efficient image Transformers和Detection Transformers)具有最小的归纳偏差。当在大型数据集上训练时,这些模型已经匹配成功,有时甚至超过 CNN 的性能。但是当他们训练时只接收小型数据集的时候,他们经常很难学到有意义的表示。
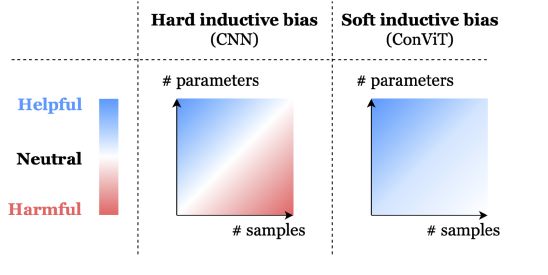
因此 AI 研究人员面临着一种权衡: CNN 强大的归纳偏差使它们即使只有最少的数据(下限很高)也能达到高性能,然而这些同样的归纳偏差可能会在存在大量数据(上限很低)时限制这些模型。
相比之下,Transformer具有最小的归纳偏差,这可以证明限制在小的数据设置(低下限) ,但这同样的灵活性使变压器在大的数据体制(高上限)中胜过 CNN。
在这篇论文中,研究人员主要解决了一个问题,即是否可以结合这两种架构的优势,同时避免它们各自的局限性?
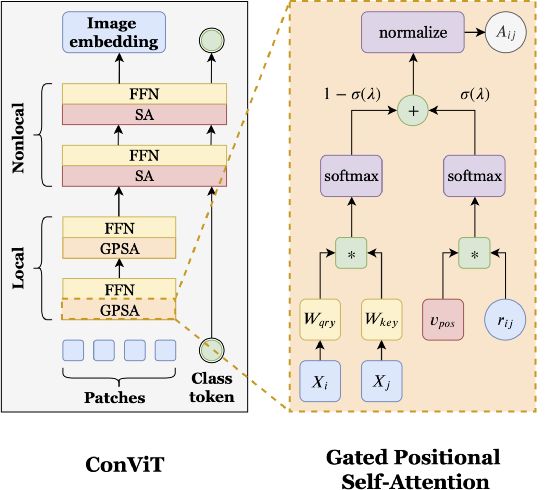
基于这个想法,文中提出了一个类似卷积的 ViT 架构的模型 ConViT 在 ImageNet 上优于之前的工作 DeiT,同时大大地提高了样本的学习效率。ConViT 的目的是修改视觉Transformer,增加一个软卷积感应偏置,增强网络卷积行为,但关键的是,允许模型自己决定是否使用卷积。
ConViT 引入了一个门控位置自注意力(gated position self-attention, GPSA),这是一种位置自注意力的形式,可以配备“软”卷积归纳偏置。初始化 GPSA 层以模拟卷积层的局部性,然后通过调整调节对位置与内容信息的注意力的门控参数 λ 来控制标准的基于内容的自我注意和卷积初始化的位置自我注意之间的平衡,让每个注意力头可以随意地跳出局部特征。
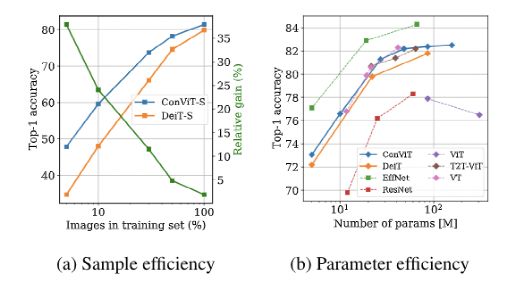
数据效率图像变压器(Data-efficient image Transformers, DeiT)模型的等效尺寸和浮点运算要比ConViT高。例如,ConViT-S + 的性能略优于 DeiT-B (82.2% 对81.8%) ,而使用的参数只有原来的一半多一点(48M 对86M)。
然而,在有限的数据体系中,软卷积感应偏置起着更大的作用,因此 ConViT 的改进是最引人注目的。例如,当只使用5% 的训练数据时,ConViT 的性能明显优于 DeiT (47.8% 对34.8%)。
除了 ConViT 的性能优势之外,门控参数还提供了一种简单的方法来理解训练后每一层卷积的程度。在所有层次中,研究人员发现 ConViT 在训练过程中对复杂位置注意的关注逐渐减少。对于后面几层,门控参数最终收敛到接近0,表明卷积感应偏置几乎被忽略。然而,对于早期的层次,许多注意力头保持较高的门控值,这表明网络使用早期层次的卷积归纳偏差来帮助训练。
在以往ViT的研究中,抛弃CNN,而只采用Transformer的全局特征,文章中重点研究了局部性(locality)的重要性,和ConViT如何在局部特征中受益。

下图可以看到,自注意层试图变得更关注局部,GPSA 层逃离局部。绘制了方程中定义的非局部性度量,对一批 1024 张图像进行平均:越高代表注意力头离查询像素越远。我们在 ImageNet 上训练了 DeiT-S 和 ConViT-S 300 个epoch。DeiTTi/ConViT-Ti 和 DeiT-B/ConViT-B 也有类似结果。

在ConViT中,由于卷积初始化,在GPSA层的训练开始时,强局部性被施加。在上图右侧中可以观察到,随着非局部性度量在所有GPSA层中增长,这种局部配置在整个训练过程中被转义。然而,训练结束时的非局部性低于DeiT所能达到的非局部性,表明在整个训练过程中保留了一些关于初始化的信息。有趣的是,最后的非定域性并不像神那样在整个层中单调地增加。第一层和最后一层强烈逃避局部性,而中间层(特别是第二层)保持更局部性。
为了进一步更多的理解,作者还检查了下图中的选通参数的动态性。
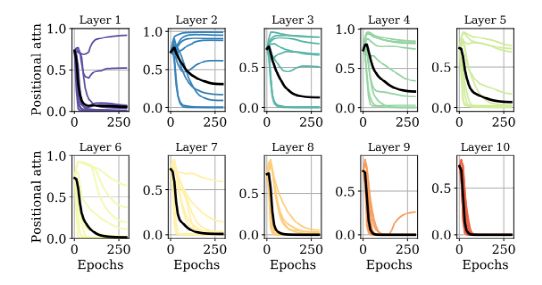
可以发现,在所有层中,平均门控参数Ehσ(λh)(黑色)在整个训练过程中下降,它反映了对位置信息和内容的平均关注量。
这个值在第6-10层中达到0,这意味着位置信息实际上被忽略。然而,在1-5层中,一些注意头保持较高的σ(λh),因此利用了位置信息。有趣的是,ConViT-Ti只在第4层使用位置信息,而ConViT-B在第6层使用位置信息(见App。D) ,这表明更大的模型-更具体-受益于更多的卷积先验知识。这些观察结果突出了选通参数在可解释性方面的有用性
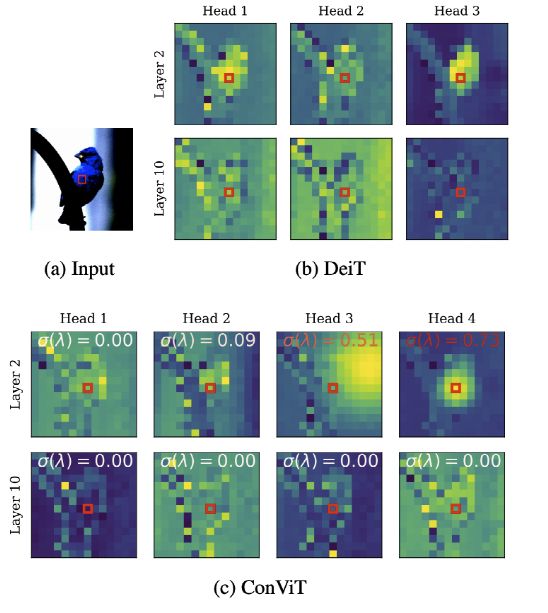
下面的注意力图进一步揭示了 ConViT 的内部工作原理,该图是通过通过层传播嵌入的输入图像并选择图像中心的查询块获得的。
在第 10 层中,DeiT 和 ConViT 的注意力图看起来性质相似:它们都执行基于内容的注意力。然而,在第 2 层,ConViT 的注意力图更加多样化:一些 head 关注内容(head 1 和 2),而另一些则主要关注位置(head3 和 4)。在关注位置的头部中,一些保持高度局部化(head 4),而另一些则扩大了他们的注意力范围(head 3)。
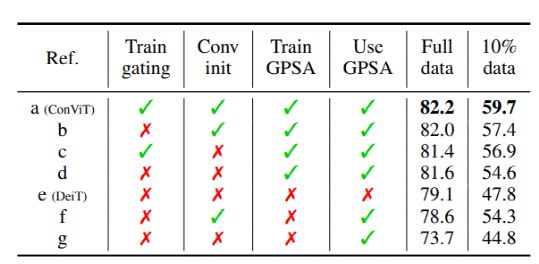
最后文中进一步研究了局部性在学习中的作用,并展示了各种消融实验以更好地了解 ConViT 成功的原因。代码和模型在GitHub上公开发布,目前已有一百多个stars,代码使用pyTorch编写。

人工智能模型的性能在很大程度上取决于它们所受训练的数据类型和数量。在研究中,甚至在现实应用中常常受到可用数据的限制。
ConViT,或者更广泛地说,施加软归纳偏差的想法,模型学会忽略是建立更灵活的人工智能系统的重要一步,这种系统可以很好地处理所提供的任何数据。
参考资料:
https://ai.facebook.com/blog/computer-vision-combining-transformers-and-convolutional-neural-networks
https://github.com/facebookresearch/convit
-------------------
END
--------------------
我是王博Kings,985AI博士,华为云专家、CSDN博客专家(人工智能领域优质作者)。单个AI开源项目现在已经获得了2100+标星。现在在做AI相关内容,欢迎一起交流学习、生活各方面的问题,一起加油进步!
我们微信交流群涵盖以下方向(但并不局限于以下内容):人工智能,计算机视觉,自然语言处理,目标检测,语义分割,自动驾驶,GAN,强化学习,SLAM,人脸检测,最新算法,最新论文,OpenCV,TensorFlow,PyTorch,开源框架,学习方法...
这是我的私人微信,位置有限,一起进步!

王博的公众号,欢迎关注,干货多多
王博Kings的系列手推笔记(附高清PDF下载):
博士笔记 | 周志华《机器学习》手推笔记第一章思维导图
博士笔记 | 周志华《机器学习》手推笔记第二章“模型评估与选择”
博士笔记 | 周志华《机器学习》手推笔记第三章“线性模型”
博士笔记 | 周志华《机器学习》手推笔记第四章“决策树”
博士笔记 | 周志华《机器学习》手推笔记第五章“神经网络”
博士笔记 | 周志华《机器学习》手推笔记第六章支持向量机(上)
博士笔记 | 周志华《机器学习》手推笔记第六章支持向量机(下)
博士笔记 | 周志华《机器学习》手推笔记第七章贝叶斯分类(上)
博士笔记 | 周志华《机器学习》手推笔记第七章贝叶斯分类(下)
博士笔记 | 周志华《机器学习》手推笔记第八章集成学习(上)
博士笔记 | 周志华《机器学习》手推笔记第八章集成学习(下)
博士笔记 | 周志华《机器学习》手推笔记第九章聚类
博士笔记 | 周志华《机器学习》手推笔记第十章降维与度量学习
博士笔记 | 周志华《机器学习》手推笔记第十一章稀疏学习
博士笔记 | 周志华《机器学习》手推笔记第十二章计算学习理论
博士笔记 | 周志华《机器学习》手推笔记第十三章半监督学习
博士笔记 | 周志华《机器学习》手推笔记第十四章概率图模型
![]()
点分享
![]()
点收藏
![]()
点点赞
![]()
点在看