RRDTool 是一套监测工具,可用于存储和展示被监测对象随时间的变化情况。比如,我们在 Windows 电脑上常见的内存和 CPU 使用情况:

RRD 全称是 Round Robin Database ,即「环型数据库」。顾名思义,它是一种循环使用存储空间的数据库,适用于存储和时间序列相关的数据。
RRD 数据库在被创建的时候就已经定义好了大小,当空间存储满了以后,又从头开始覆盖旧的数据,所以和其他线性增长的数据库不同,RRD 的大小可控且不用维护。
你可以把 RRD 理解为一个有时间刻度的圆环,每个刻度上可以存储一个数值,同时有一个从圆心指向最新存储值的指针。
可以想象,随着时间推移,指针会绕着圆心一直移动下去,当它指向下一个刻度后,就可以在那个位置上存储一个新的数值。但是,指针只能绕一个方向前进,假设你存储了时刻3的监测值,那就不能再存储时刻2的监测值了。如下图所示:
创建 RRD 基本语法
rrdtool create filename
[--start|-b start-time]
[--step|-s step]
[DS:ds-name:DST:dst-arguments]
[RRA:CF:xff:step:rows]
其中
rrdtool create filename
表示使用 rrdtool 命令 create 创建一个名为 filename 的数据库文件,通常 RRD 数据库文件的后缀为 .rrd ,但是你随便使用文件名也不会有影响。
--start|-b start-time
这个选项表示 RRD 数据库的起始 (start/begin) 时间点为 start-time,这是一个从 1970-01-01 00:00:00 开始计时,以秒为间隔的一个整数值。
如图所示:

A点是从 1970-01-01 00:00:00 开始经过0秒后到达的时间点;
B点是从 1970-01-01 00:00:00 开始经过658108920秒后到达的时间点 1990-11-09 00:02:00;
C点是从 1970-01-01 00:00:00 开始经过1458763813秒后到达的时间点 2016-03-23 20:10:13。
所以,start-time 是一个代表时间点的整数值,表示 RRD 数据库记录的监测值从这个时刻开始。
[--step|-s step]
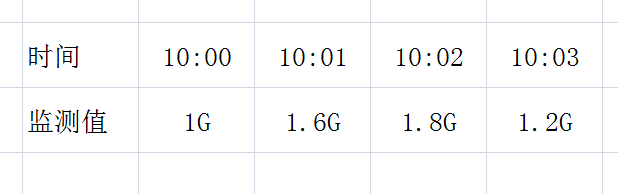
这个选项表示监测的时间间隔,即多久时间去获取一次被监测对象的数值,默认值为5分钟(300秒)。比如,我们可以从10:00开始每60秒去获取一次电脑内存的使用值,这个时候 step 就是 60,获取到的数值如下图所示:
[DS:ds-name:DST:dst-arguments]
这个选项用来定义数据源(Data Source)属性,包括数据源名称 ds-name,比如我们可以给监测内存使用率的数据源命名为 memory-rate。
还要定义数据源类型(Data Source Type),常用的有以下4种数据源类型,分别是:
1、GAUGE
实测值,RRD 将如实记录,比如温度变化曲线:

2、COUNTER
计数值,这是一个只增不减的正整数。比如,汽车行驶里程,从汽车第一次上路开始,里程就从0开始不断增长:

假设每隔30分钟监测一次汽车里程,当 RRD 收到 COUNTER 类型的数据时,并不会像 GAUGE 类型那样直接存储,而是计算变化率:
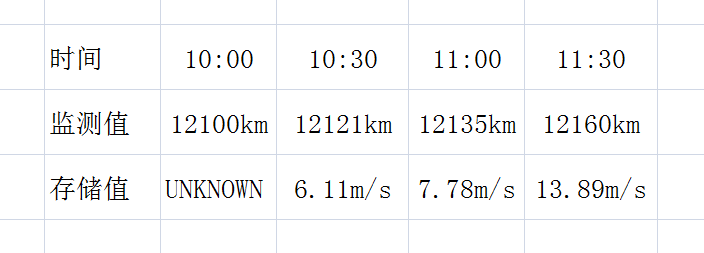
计算原理: (12121km - 12100km) / (10:30 - 10:00) = 11000m / 1800s = 6.11m/s
所以,RRD 对于 COUNTER 类型的数据源存储的是变化率,对于上述里程表而言就是行驶速度。
(注:第一个存储值为 UNKNOWN,因为没有更早的数据,所以没有变化可言)
3、ABSOLUTE
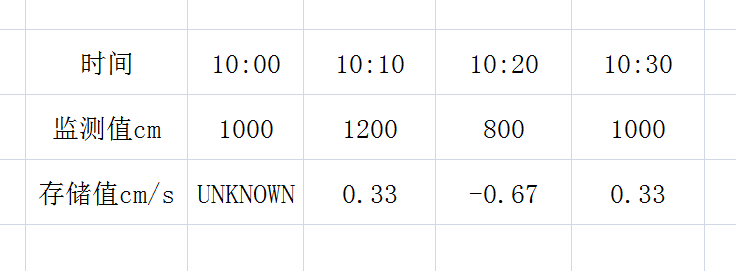
ABSOLUTE 类型存储的也是变化率,假设我们正在微信和好友聊天,每五分钟我们会看一下有没有新消息,如果有的话就立即处理,这样未读提醒就会变为0,然后下一个五分钟后继续看未读新消息数,会得到这样一个监测表:


计算原理:120条 / 300秒 = 0.4条/秒
这样我们就可以知道一段时间内聊天快慢的情况,数值越大表示5分钟内收到的未读消息越多,聊天也就越火热。
4、DERIVE
DERIVE 类型存储的也是变化率,和 COUNTER 类型不同的是,监测值可以增长也可以下降,例如水库的水位监测:
可以看到水位一时升高,一时降低,通过计算变化率能够监测某一时段水位正在升高还是降低,以及相应的速度。
[RRA:CF:xff:step:rows]
RRA (Round Robin Archive) 是用来定义 RRD 数据库归档模型,RRDTool 绘图展示监测情况的时候就从 RRA 中获取数据。
为什么不直接获取存储的原始数据来绘图呢?
这得从监测场景的实际需求出发,通常我们对最近一小时或一天的监测数据最关心,对于一个月或者一年以上的监测数据有个大概的认知就可以。
假设我们每秒监测一次某台服务器 CPU 使用率,那么一年后将获得:
1 x 60秒 x 60分钟 x 24小时 x 365天 = 31536000
个监测值。
如果这么多数据点在一张图表上展示,即使一个数据点只占一个像素,你也可以想象得多长的图片才能完整展示监测数据。
但是,如果我们把每60秒监测的60个原始数据点计算出一个平均值 AVERAGE(d1,d2,d3,...,d60) 的话,那么将有:
1 x 60分钟 x 24小时 x 365天 = 525600
个平均值。
这样数据量就比使用原始值降低了60倍!这种经过计算平均值后得到的数据称为归档值。
虽然丧失了一定的精度,但是并不影响我们观察一年来的变化趋势。
同理,如果我们把每小时监测的3600个原始数据点计算一个归档平均值的话,数据点就只有24 x 365 = 8760个了。这就是绘图展示监测情况的时候要使用 RRA 归档数据的原因。
RRD 提供的归档方法有4种,除了上述的计算平均值 AVERAGE 方法外,还有:
计算最大值 MAX(d1,d2,d3,...dn) = 最大的那个监测值
计算最小值 MIN(d1,d2,d3,...dn) = 最小的那个监测值
计算最后值 LAST(d1,d2,d3,...dn) = 最后的那个监测值
这里还涉及到两个基本概念:
PDP (Primary Data Point) 原始数据点
CDP (Consolidation Data Point) 归档数据点
由上述介绍可以知道:一个 CDP 由多个 PDP 经过归档函数计算得到。
在定义 RRA 的时候,一般的语法为:
RRA:CF:xff:steps:rows
表示使用{AVERAGE | MIN | MAX | LAST}中的一个归档函数 CF (Consolidation Function)。
xff 是 xfiles 因子(factor),表示超过多少比率的有效 PDP 才可以计算出 CDP,通常为0.5。
如果我们设置 xff 为 0.5,即有大于50%的有效监测值就可以在这些有效值上计算出归档值,否则这段时间内的归档值记为 UNKNOWN。
例如,我们监测的10个时间点中,因为某些原因其中4个无法获取监测值,即监测值为 UNKNOWN,那么还剩6个有效的监测值,这时候有效率为60%,所以可以获得归档值。
steps 表示多少个 PDP 计算出一个 CDP,例如,在每秒获取一个监测值的实例中,steps = 60 表示每60个原始数据计算一个归档数据,即一分钟一个数据点;steps = 3600 表示每3600个原始数据计算一个归档数据,即一小时一个数据点。
rows 表示多少个 CDP 组成一个 RRA。
通常一个 RRD 数据库可以有多个不同精度的 RRA,其中周期( steps * rows)最长的的 RRA 同时也规定了 RRD 的周期,这就是开头说的:RRD 数据库在创建的时候就已经定义好大小。
使用命令创建一个名为 test.rrd 的 RRD 数据库:
rrdtool create test.rrd
--step 300
DS:miles:COUNTER:600:0:1024
RRA:AVERAGE:0.5:2:8
RRA:AVERAGE:0.5:4:7

--step 300
表示监测时间间隔为5分钟。
DS:miles:COUNTER:600:0:1024
表示数据源的名称 为 miles,数据源类型(DST) 为 COUNTER,数据源的 heartbeat 周期为 600秒,如果一个 heartbeat 时间周期内监测数据还没有获取到,那么 RRD 自动将监测值设置为 UNKNOWN,数据源的最小值为0,最大值为1024,如果获得的监测值不在这个范围, RRD 自动将监测值设置为 UNKNOWN。
RRA:AVERAGE:0.5:2:8
定义了一个 RRA :归档函数是求平均值 AVERAGE,xff 因子是 0.5,每2个监测值 PDP 将计算一个归档值 CDP,总共存储 8 个 CDP,所以这个 RRA 的时间周期是 300s x 2 x 8 = 4800s。
如上图示例可知,CDP(RRA1-AVG) 的各项值为
(1+2)/2 = 1.5
(3+4)/2 = 3.5
......
RRA:AVERAGE:0.5:4:7
定义了一个 RRA :归档函数是求平均值 AVERAGE,xff 因子是 0.5,每4个监测值 PDP 将计算一个归档值 CDP,总共存储 7 个 CDP,所以这个 RRA 的时间周期是 300s x 4 x 7 = 8400s。
如上图示例可知,CDP(RRA2-AVG) 的各项值为
(1+2+3+4)/4 = 2.5
(5+6+7+8)/4 = 6.5
......
上述两个 RRA 中,最长时间周期为 8400s,由于 RRD 定义的监测周期为 300s,所以这个 RRD 将存储 8400/300 = 28个监测值。
因为 RRA 的长度 rows 也是定义好的,所以随着时间推移,监测值越来越多的时候,RRA 的内容也随之变化:

当 RRDTool 绘制监测图表的时候,会优先选取精度(solution)高的 RRA 数据,上图示例中,显然 RRA1-AVG 的精度要高于 RRA2-AVG,或者说更接近原始数据。
但是,一个前提条件是所选的 RRA 能够覆盖我们希望图表展示的时间周期,上图示例中 RRA1-AVG 只覆盖了 第5-20个监测点,所以当我们希望看到从第1-20个监测点的数据时,只能选择 RRA2-AVG 了,虽然它精度不如 RRA1-AVG,但至少它覆盖到了我们希望看到的时间周期。
所以,在实际应用场景中,我们通常会定义多个 RRA,覆盖时间周期短的精度高,比如最近一天的监测值;覆盖时间周期长的精度低,比如最近一年的监测值。
以上是 RRD 数据库的内部存储原理,那么如何更新它的存储值呢?
通常,我们会借用外部程序,如 Shell、Python、Ruby等脚本语言,获取被监测对象的数值,然后使用 RRDTool update 命令存储监测值,例如:
rrdtool update test.rrd 920804700:12345 920805000:12357 920805300:12363 ......
表示时间点920804700时,被监测对象数值为12345
表示时间点920805000时,被监测对象数值为12357
表示时间点920805300时,被监测对象数值为12363
......
最后,要展示监测数据了,RRDTool 内置了绘图表功能,你可以直接使用类似以下的命令行输出一张 png 图片:
rrdtool graph myrouter-day.png --start -86400
DEF:inoctets=myrouter.rrd:input:AVERAGE
DEF:outoctets=myrouter.rrd:output:AVERAGE
AREA:inoctets#00FF00:"In traffic"
LINE1:outoctets#0000FF:"Out traffic"
上述命令表示:创建一张名为 myrouter-day.png 的图片,监测时间从一天前(60x60x24=86400)开始的路由器进出流量统计。其中流进流量使用区域图(AREA),颜色为绿色(#00FF00);流出流量使用一个像素宽的曲线图(LINE1),颜色为蓝色(#0000FF)。
但是,RRDTool 也可以将数值输出,然后我们使用第三方的绘图工具,绘制监测图,这样可以在 WEB 上更灵活的展示监测数值。
如下图所示,就是 Open-Falcon 使用 RRDTool 存储监测数据,然后获取监测数据在网页上绘制趋势图:

综上,就是 RRDTool 的原理简介,如果你没有看懂的话,请随意吐槽。
作者微博/微信 @Ceelog,转载请注明出处 ;)