SQL系列——LeetCode20道题解
175. 组合两个表
176. 第二高的薪水
# Write your MySQL query statement below SELECT max(Salary) as SecondHighestSalary FROM Employee WHERE Salary <(SELECT max(Salary) FROM Employee);
where max(salary),where条件中不能包含聚组函数总结rank、dense_rank、row_number
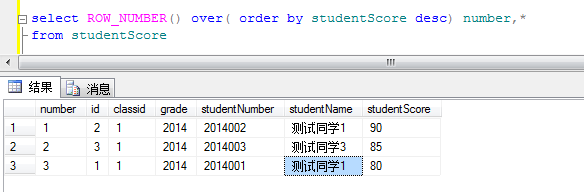
1.ROW_NUMBER()
语法:ROW_NUMBER() OVER()
定义:ROW_NUMBER()函数作用就是将select查询到的数据进行排序,每一条数据加一个序号,他不能用做于学生成绩的排名,一般多用于分页查询, row_number是连续的
比如查询前10个 查询10-100个学生。
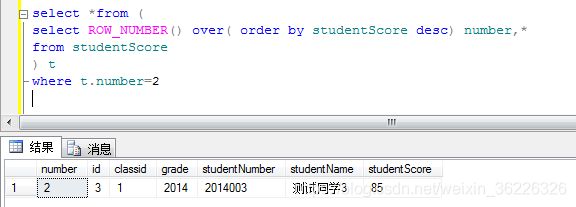
获取第二个同学的成绩信息:
这里用到的思想就是 分页查询的思想 在原sql外再套一层select
where t.number>=1 and t.number<=10 是不是就是获取前十个学生的成绩信息2.RANK()
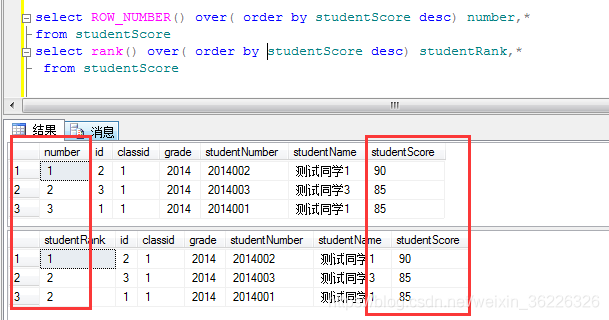
定义:RANK()函数,顾名思义排名函数,可以对某一个字段进行排名,这里为什么和ROW_NUMBER()不一样那,ROW_NUMBER()是排序,当存在相同成绩的学生时,ROW_NUMBER()会依次进行排序,他们序号不相同,而Rank()则不一样出现相同的,他们的排名是一样的。下面看例子:
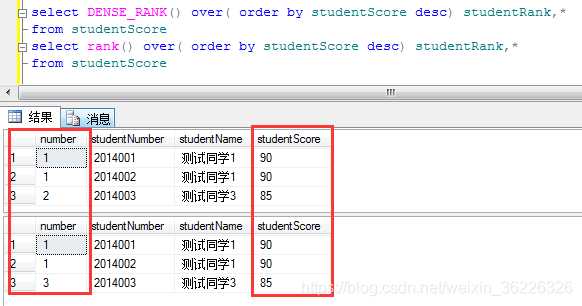
当出现两个学生成绩相同是里面出现变化。RANK()是 1 2 2,而ROW_NUMBER()则还是1 2 3,这就是RANK()和ROW_NUMBER()的区别了3.DENSE_RANK()
定义:DENSE_RANK()函数也是排名函数,和RANK()功能相似,也是对字段进行排名,那它和RANK()到底有什么不同那?看例子
177. 第N高的薪水
还是跟上一题求第二高薪水一样的思路,回顾一下MySQL的isfull 与limit的用法
ifnull(value1,value2)
1、如果value1不为空,结果返回value1。
2、如果value1为空,结果返回value2。
Limit x 返回多少条数据 limit x,y 从第X+1条开始,返回y条。然后对数据进行去重,用distinct,再对去重后的数据进行降序排序,用limit N-1,1 即从第N条开始,取一条数据,也就取到了第N高的薪水。
CREATE FUNCTION getNthHighestSalary(N INT) RETURNS INT BEGIN DECLARE P INT; SET P = N-1; RETURN ( # Write your MySQL query statement below. select ifnull ((select distinct Salary from Employee order by Salary desc limit P,1),null) as getNthHighestSalary ); END
178. 分数排名
select Score, dense_rank() over (order by Score desc) as `Rank` from Scores;leetcode上给出了创建变量进行denserank的方法,但是原方法有些问题,自己没搞懂为啥。
1、在第二行末尾+ 0,进行类型转换
2、分析其返回NULL的原因在于第三行WHEN @pre := Score THEN @rk := @rk + 1,
本意是对于所有不满足@pre = Score的记录,将其排行+1,且将新的Score赋值给@pre
在Score不为0的情况下,@pre := Score为真,但是在Score等于0的情况下,CASE语句不走任何分支,返回NULL
针对这种情况,打个补丁:因为此时@pre := Score语句已经执行,只是后半段@rk := @rk + 1没有执行。
所以,再加一行ELSE @rk := @rk + 1即可。作者:lava-4
链接:https://leetcode-cn.com/problems/rank-scores/solution/mysql-tian-jia-bian-liang-133ms-9873-by-lava-4/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。SELECT Score,CASE WHEN @sco=Score THEN @rn+0 WHEN @sco:= Score THEN @rn:=@rn+1 ELSE @rn:=@rn+1 #必须有ELSE END AS `Rank` #必须+ `` FROM Scores,(SELECT @rn:=0,@sco:=NULL) AS t ORDER BY Score DESC;#下边这种 执行起来特别慢
SELECT score,(SELECT COUNT(DISTINCT score) FROM scores WHERE score >=t.score ) AS `RANK` FROM scores as t ORDER BY Score DESC;
180. 连续出现的数字
自连接
# Write your MySQL query statement below SELECT DISTINCT(tb1.Num) AS ConsecutiveNums FROM Logs AS tb1, Logs AS tb2,Logs AS tb3 WHERE tb1.Num = tb2.Num AND tb2.Num = tb3.Num AND tb1.Id + 1 = tb2.Id AND tb2.Id + 1 = tb3.Id;
181. 超过经理收入的员工
182. 查找重复的电子邮箱
183. 从不订购的客户
184. 部门工资最高的员工
出错原因:WHERE里使用了 tb1.Id Salary, IN (SELECT tb1.Id,MAX(Salary))
GROUP BY DepartmentId,在SELECT DepartmentId 和 MAX(Salary)是对Department下求最大Salary,建议看一下GROUP BY
示例5:求各组平均值
select 类别, avg(数量) AS 平均值 from A group by 类别;示例6:求各组记录数目
select 类别, count(*) AS 记录数 from A group by 类别;示例7:求各组记录数目
SELECT tb2.Name AS `Department`,tb1.Name AS `Employee`,tb1.Salary AS Salary FROM Employee AS tb1 JOIN Department AS tb2 ON tb1.DepartmentId = tb2.Id WHERE ( (tb1.DepartmentId,tb1.Salary) IN (SELECT DepartmentId,MAX(Salary) FROM Employee GROUP BY DepartmentId) )
185. 部门工资前三高的所有员工
SELECT tb2.Name AS Department,tb1.Name AS Employee, tb1.Salary AS Salary FROM Employee AS tb1 INNER JOIN Department AS tb2 ON tb1.DepartmentId = tb2.Id WHERE( SELECT COUNT(DISTINCT Salary) FROM Employee AS tb3 WHERE tb3.DepartmentId = tb1.DepartmentId AND tb3.Salary > tb1.Salary) < 3;
197. 上升的温度
一、时间差函数:timestampdiff
语法:timestampdiff(interval, datetime1,datetime2)
结果:返回(时间2-时间1)的时间差,结果单位由interval参数给出。
- frac_second 毫秒(低版本不支持,用second,再除于1000)
- second 秒
- minute 分钟
- hour 小时
- day 天
- week 周
- month 月
- quarter 季度
- year 年
二、时间差函数:datediff
语法:传入两个日期参数,比较DAY天数,第一个参数减去第二个参数的天数值。
SELECT DATEDIFF('2013-01-13','2012-10-01'); # 104
三、时间差函数:timediff
语法:timediff(time1,time2)
结果:返回两个时间相减得到的差值,time1-time2
SELECT TIMEDIFF('2018-05-21 14:51:43','2018-05-19 12:54:43'); # 49:57:00
262. 行程和用户
ROUND# Write your MySQL query statement below SELECT tb1.Request_at as Day,ROUND(SUM(CASE WHEN tb1.Status = 'completed' THEN 0 ELSE 1 END)/COUNT(*),2) AS 'Cancellation Rate' FROM Trips as tb1 JOIN Users as tb2 ON tb1.Client_Id = tb2.Users_Id AND tb2.Banned = "NO" JOIN Users as tb3 ON tb1.Driver_Id = tb3.Users_Id AND tb3.Banned = "No" WHERE tb1.Request_at BETWEEN "2013-10-01" AND "2013-10-03" GROUP BY tb1.Request_at ORDER BY Day;