WAF绕过-信息收集之反爬虫延时代理池技术
WAF拦截会出现在安全测试的各个层面,掌握各个层面的分析和绕过技术最为关键。

演示案例

1.Safedog-未开CC时
CC就是DDOS攻击的一种,默认是不开启的。
判断有没有WAF可以直接在路径上报错显示。
可以用目录扫描工具扫
 此时发现扫描的目录结果都是误报
此时发现扫描的目录结果都是误报
通过本地的抓包工具抓取扫描器发送的数据包与通过网站访问的数据包进行对比

将http请求方式修改为GET 重新扫描
重新扫描

2.当Safedog-开启CC时
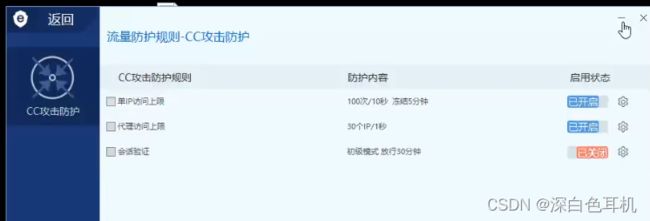 再次使用工具扫描,因为工具扫描对网站访问的频率太高,所以ip被安全狗拉入黑名单了
再次使用工具扫描,因为工具扫描对网站访问的频率太高,所以ip被安全狗拉入黑名单了

可以通过这里设置访问的间隔时间,从而不被安全狗判定为工具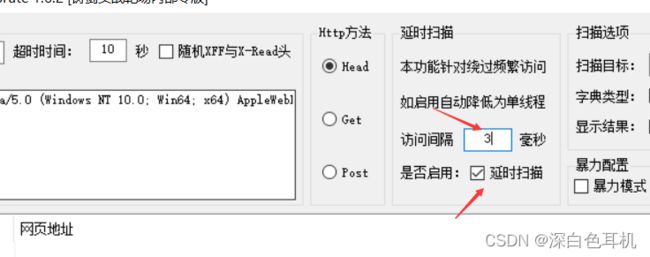
黑白名单机制
HTTP检测-黑名单:任何操作都被禁止
HTTP检测-白名单:任何操作都被允许(一般用于网站内部人员)
如果既不是黑名单也不是白名单,就按照规则来

我们可以通过伪造user-agent用工具对网站进行扫描,因为当安全狗发现你的user-agent是百度谷歌等,为了让网站正常被此类搜素引擎访问爬取,就有可能不会对你的请求进行拦截。
 此时更换完user-agent后发现并没有任何结果。
此时更换完user-agent后发现并没有任何结果。
因为单单只修改了user-agent,如果对方对你请求包的内容进行检测的话,还是会被发现是工具进行的访问。
1.可以使用python脚本自定义请求包来访问
可以通过python自定义来模拟正常用户的请求数据包,以及更改为百度谷歌等搜素引擎的user-agent来对网站进行访问请求,此时对方不会拦截

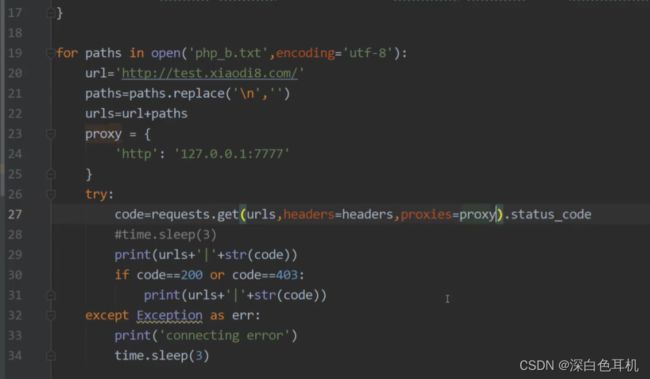 php_b.txt是一个字典
php_b.txt是一个字典
import requests
import time
#headers为自定义的头部请求数据包
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'Cookie': 'PHPSESSID=4d6f9bc8de5e7456fd24d60d2dfd5e5a',
'sec-ch-ua': '"Chromium";v="92", " Not A;Brand";v="99", "Microsoft Edge";v="92"',
'sec-ch-ua-mobile': '?0',
'Sec-Fetch-Dest': 'document',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-Site': 'none',
'Sec-Fetch-User': '?1',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (compatible; Baiduspider-render/2.0; +http://www.baidu.com/search/spider.html)'
}
for paths in open('php_b.txt', encoding='utf-8'):
url = "http://127.0.0.1/pikachu"
paths = paths.replace('\n', '')
urls = url + paths
proxy = {
'http': '127.0.0.1:7777'
}
try:
code = requests.get(urls, headers=headers, proxies=proxy).status_code
# time.sleep(3)
print(urls + '|' + str(code))
except Exception as err:
print('connect error')
time.sleep(3)
抓包分析:
此处为python脚本自定义的请求数据包

如果不使用自定义的请求数据包:

2.代理池
可通过python写的脚本不停更换代理ip访问进行测试
宝塔
宝塔里的日志:

规则:当宝塔检测出你的ip在规定时间内对敏感文件尝试进行了多次访问,则会把你拉入黑名单
可以优化字典,因为宝塔检测的是一分钟内对敏感文件进行的访问。
比如说code.php.bak 可以优化成code.php.bak .访问的还是原来的,还不会被匹配规则匹配到。
总结
安全狗:开启cc时可通过修改请求包绕过
阿里:延迟和代理池
宝塔:当有付费插件时用延迟和代理,使用延迟时并且需要优化字典,不能触发在60秒内,超过累计6次恶意请求的规则
