1 数据离散化
1.1 为什么要离散化
连续属性离散化的目的是为了简化数据结构,数据离散化技术可以用来减少给定连续属性值的个数。离散化方法经常作为数据挖掘的工具。
1.2 什么是数据的离散化
连续属性的离散化就是在连续属性的值域上,将值域划分为若干个离散的区间,最后用不同的符号或整数 值代表落在每个子区间中的属性值。
离散化有很多种方法,下面距离一种最简单的方式去操作。
- 原始人的身高数据:165,174,160,180,159,163,192,184
- 假设按照身高分几个区间段:150-165,165-180,180~195
这样我们将数据分到了三个区间段,我可以对应的标记为矮、中、高三个类别,最终要处理成一个"哑变量"矩阵。
1.3 举例股票的涨跌幅离散化
下面对股票每日的涨跌幅度进行离散化
1.3.1 读取股票的数据
先读取股票的数据,筛选出涨跌幅度的数据
data = pd.read_csv("./data/stock_day.csv")
p_change= data['p_change']
1.3.2 将股票涨跌幅数据进行分组
使用的api:
- pd.qcut(data, q):对数据进行分组将数据分组,一般会与value_counts搭配使用,统计每组的个数
- series.value_counts():统计分组次数
自定义区间分组:
pd.cut(data, bins)
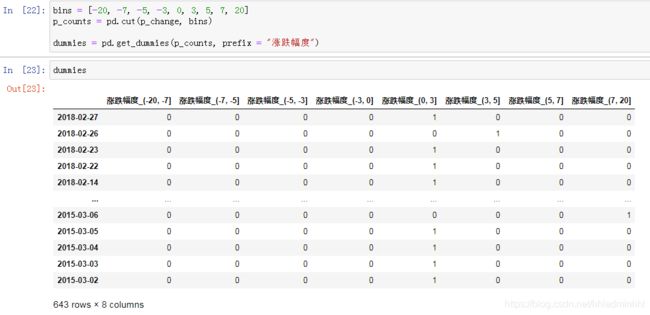
# 自己指定分组区间 bins = [-20, -7, -5, -3, 0, 3, 5, 7, 20] p_counts = pd.cut(p_change, bins)
1.3.3 股票涨跌幅分组数据变成one-hot编码
什么是one-hot编码
把每个类别生成一个布尔列,这些列中只有一列可以为这个样本取值为1.其又被称为热编码。
pandas.get_dummies(data, prefix=None)
- data:array-like, Series, or DataFrame
- prefix:分组名字
bins = [-20, -7, -5, -3, 0, 3, 5, 7, 20] p_counts = pd.cut(p_change, bins) # 得出one-hot编码矩阵 dummies = pd.get_dummies(p_counts, prefix = "涨跌幅度")
2 数据合并
如果你的数据由多张表组成,那么有时候需要将不同的内容合并在一起分析。
2.1 pd.concat实现数据合并
pd.concat([data1, data2], axis=1)
按照行或列进行合并,axis=0为列索引,axis=1为行索引
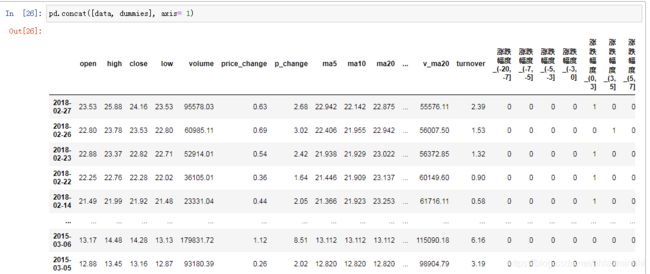
比如我们将刚才处理好的one-hot编码与原数据合并
# 按照行索引进行 pd.concat([data, dummies], axis=1)
2.2 pd.merge
pd.merge(left, right, how=‘inner’, on=None)
- 可以指定按照两组数据的共同键值对合并或者左右各自
- left: DataFrame
- right: 另一个DataFrame
- on: 指定的共同键
- how:按照什么方式连接,连接方式和数据库类似分为内连接,外连接,左连接,右连接
2.2.1 pd.merge合并
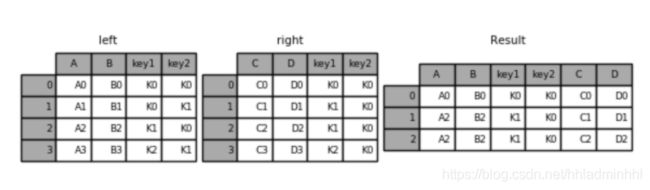
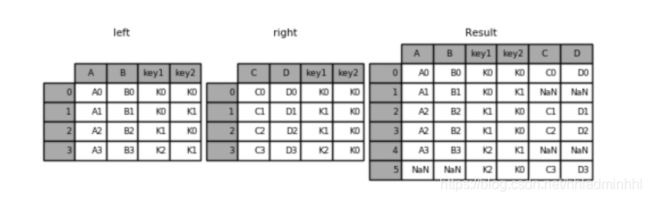
left = pd.DataFrame({'key1': ['K0', 'K0', 'K1', 'K2'],
'key2': ['K0', 'K1', 'K0', 'K1'],
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']})
right = pd.DataFrame({'key1': ['K0', 'K1', 'K1', 'K2'],
'key2': ['K0', 'K0', 'K0', 'K0'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})
# 默认内连接
result = pd.merge(left, right, on=['key1', 'key2'])
左连接
result = pd.merge(left, right, how='left', on=['key1', 'key2'])

右连接
result = pd.merge(left, right, how='right', on=['key1', 'key2'])
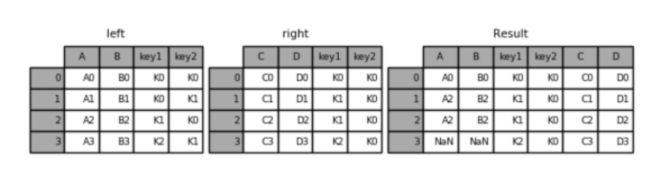
外链接
result = pd.merge(left, right, how='outer', on=['key1', 'key2'])
到此这篇关于Python Pandas学习之数据离散化与合并详解的文章就介绍到这了,更多相关Python Pandas内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!